Содержание
Robots.txt Tester: используйте бесплатный онлайн-инструмент для SEO
Файл robots.txt – это текстовый файл, размещаемый на веб-сайтах для информирования роботов поисковых систем (таких как Google), какие страницы в этом домене можно сканировать. . Если на вашем веб-сайте есть файл robots.txt, вы можете выполнить проверку с помощью нашего бесплатного генератора Robots.txt инструмента. Вы можете интегрировать ссылку на XML карту сайта в файл robots.txt.
Прежде чем боты поисковых систем просканируют ваш сайт, они сначала найдут файл robots.txt сайта. Таким образом, они увидят инструкции, какие страницы сайта можно индексировать, а какие не следует индексировать консолью поисковой системы.
С помощью этого простого файла вы можете настроить параметры сканирования и индексирования для роботов поисковых систем. И чтобы проверить, настроен ли на вашем сайте файл robots.txt, вы можете использовать наши бесплатные и простые инструменты для тестирования Robots. txt. В этой статье объясняется, как проверить файл с помощью этого инструмента и почему важно использовать Robots.txt Tester на своем сайте.
txt. В этой статье объясняется, как проверить файл с помощью этого инструмента и почему важно использовать Robots.txt Tester на своем сайте.
Использование средства проверки robots.txt: пошаговое руководство
Тестирование файла robots.txt поможет вам протестировать файл robots.txt в вашем домене или любом другом домене, который вы хотите проанализировать.
Средство проверки robots.txt быстро обнаружит ошибки в настройках файла robots.txt. Наш инструмент проверки очень прост в использовании и может помочь даже неопытному профессионалу или веб-мастеру проверить файл Robots.txt на своем сайте. Вы получите результаты через несколько минут.
Шаг 1. Вставьте URL-адрес
Чтобы начать сканирование, все, что вам нужно сделать, это ввести интересующий URL-адрес в пустую строку и нажать кнопку с синей стрелкой. Затем инструмент начнет сканирование и выдаст результаты. Вам не нужно регистрироваться на нашем сайте, чтобы использовать его.
В качестве примера мы решили проанализировать наш сайт https://sitechecker.pro. На приведенных ниже снимках экрана вы можете увидеть процесс сканирования в нашем инструменте веб-сайта.
Шаг 2. Интерпретация результатов тестера Robots.txt
Затем, когда сканирование завершится, вы увидите, разрешает ли файл Robots.txt сканирование и индексирование конкретной доступной страницы. Таким образом, вы можете проверить, будет ли ваша веб-страница получать трафик из поисковой системы. Здесь вы также можете получить несколько полезных советов по мониторингу.
Случаи, когда требуется проверка robots.txt
Проблемы с файлом robots.txt или его отсутствие могут негативно повлиять на ваш рейтинг в поисковых системах. Вы можете потерять рейтинговые очки в SERP. Анализ этого файла и его значения перед сканированием веб-сайта позволяет избежать проблем с сканированием. Кроме того, вы можете предотвратить добавление контента вашего веб-сайта на страницы исключения из индекса, которые вы не хотите сканировать. Используйте этот файл, чтобы ограничить доступ к определенным страницам вашего сайта. Если есть пустой файл, вы можете получить сообщение Robots.txt не найден в SEO-краулер.
Используйте этот файл, чтобы ограничить доступ к определенным страницам вашего сайта. Если есть пустой файл, вы можете получить сообщение Robots.txt не найден в SEO-краулер.
Вы можете создать файл с помощью простого текстового редактора. Во-первых, укажите пользовательский агент для выполнения инструкции и поместите директиву блокировки, например, disallow, noindex. После этого перечислите URL-адреса, для которых вы ограничиваете сканирование. Перед запуском файла убедитесь, что он правильный. Даже опечатка может привести к тому, что бот Googlebot проигнорирует ваши инструкции по проверке.
Какие инструменты проверки robots.txt могут помочь
Когда вы создаете файл robots.txt, вам необходимо проверить, не содержат ли они ошибок. Есть несколько инструментов, которые помогут вам справиться с этой задачей.
Консоль поиска Google
Теперь только в старой версии Google Search Console есть инструмент для тестирования файла robots. Войдите в учетную запись с текущим сайтом, подтвержденным на его платформе, и используйте этот путь, чтобы найти валидатор.
Войдите в учетную запись с текущим сайтом, подтвержденным на его платформе, и используйте этот путь, чтобы найти валидатор.
Старая версия Google Search Console > Сканировать > Тестер robots.txt
Этот тест robot.txt позволяет:
Веб-мастер Яндекса
Войдите в аккаунт Яндекс Вебмастер с текущим сайтом и подтвержден на своей платформе и используйте этот путь, чтобы найти инструмент.
Яндекс для веб-мастеров > Инструменты > Анализ robots.txt
Этот тестер предлагает почти такие же возможности для проверки, как и описанный выше. Разница заключается в:
 txt;
txt;Сканер проверки сайта
Это решение для массовой проверки, если вам нужно просканировать веб-сайт. Наш краулер помогает проверить весь сайт и определить, какие URL-адреса запрещены в robots.txt, а какие закрыты от индексации с помощью метатега noindex.
Внимание: для обнаружения запрещенных страниц необходимо просканировать веб-сайт с настройкой игнорировать robots.txt.
Обнаружение и анализ не только файла robots.txt, но и других проблем SEO на вашем сайте!
Проведите полный аудит, чтобы выяснить и исправить проблемы с вашим сайтом, чтобы улучшить результаты поисковой выдачи.
Часто задаваемые вопросы
Зачем мне проверять файл robots.txt?
Robots.txt показывает поисковым системам, какие URL-адреса на вашем сайте они могут сканировать и индексировать, в основном, чтобы не перегружать ваш сайт запросами. Проверка этого действительного файла рекомендуется, чтобы убедиться, что он работает правильно.
Проверка этого действительного файла рекомендуется, чтобы убедиться, что он работает правильно.
Является ли нарушение файла Robots.txt незаконным?
Сегодня нет закона, требующего строго следовать инструкциям в файле. Это не обязывающий договор между поисковыми системами и веб-сайтами.
Что делает файл robots.txt?
Robots.txt показывает агентам поисковых систем, какие страницы вашего сайта можно сканировать и индексировать, а какие страницы были исключены из просмотра. Разрешение поисковым системам сканировать и индексировать некоторые страницы вашего сайта — это возможность контролировать конфиденциальность некоторых страниц. Это необходимо для поисковой оптимизации вашего сайта.
Является ли Robot.txt безопасным?
Файл robots.txt не ставит под угрозу безопасность вашего сайта, поэтому его правильное использование может быть отличным способом защитить конфиденциальные страницы вашего сайта. Тем не менее, не ожидайте, что все сканеры поисковых систем будут следовать инструкциям в этом файле. Злоумышленники смогут отключать инструкции и сканировать запрещенные страницы.
Тем не менее, не ожидайте, что все сканеры поисковых систем будут следовать инструкциям в этом файле. Злоумышленники смогут отключать инструкции и сканировать запрещенные страницы.
Проверка Robot.txt 2023: БЕСПЛАТНЫЙ онлайн-инструмент
Это поле обязательно для заполнения
Неверный URL-адрес. Пожалуйста, убедитесь в правильности url-адреса!
Пример: www.websiteplanet.com/robots.txt
01
Легко использовать:
Легко использовать: Проверить правильность вашего файла robots.txt никогда не было так легко. Просто вставьте свой URL-адрес, используя /robots.txt, нажмите «Ввод», и ваш отчет будет готов мгновенно.
02
100% точность:
Мало того, что наш robots.txt checker сможет обнаружить ошибки, возникшие из-за опечаток, синтаксиса и «логики», он также даст вам полезные советы по оптимизации.
03
Точность:
Учитывая как Robots Exclusion Standard, так и специальные расширения для spider, наша программа robots. txt checker сгенерирует легко читаемый отчет, который поможет исправить любые ошибки, которые могут возникнуть в файле robots.txt.
txt checker сгенерирует легко читаемый отчет, который поможет исправить любые ошибки, которые могут возникнуть в файле robots.txt.
Что такое валидатор файла robots.txt?
Инструмент проверки Robots.txt создан для того, чтобы показать, правильно ли составлен ваш файл robots.txt, нет ли в нем ошибок. Robots.txt — этот файл, который является частью вашего веб-сайта и описывает правила индексации для роботов поисковых машин, чтобы веб-сайт индексировался правильно, и первыми на сайте индексировались самые важные данные (без каких-либо скрытых платежей).Это очень простой инструмент, который создает отчет уже через несколько секунд сканирования: вам просто ввести в поле URL своего веб-сайта, через слэш /robots.txt (например, yourwebsite.com/robots.txt), а затем нажать на кнопку “проверить”. Наш инструмент для тестирования файлов robots.txt находит все ошибки (опечатки, синтаксические и “логические”) и выдает советы по оптимизации файла robots.txt.
Зачем нужно проверять файл robots.
 txt?
txt?
Проблемы с файлом robots.txt или его отсутствие могут негативно отразиться на SEO-оптимизации сайта: ваш сайт может не выдаваться на странице результатов выдачи поисковых машин (SERP). Это происходит из-за того, что нерелевантный контент может обходиться до или вместо важного контента.Проверить свой файл перед тем, как обходить контент важно, чтобы вы смогли избежать проблем, когда весь контент на сайте индексируется, а не только самый релевантный. Например, вы хотите, чтобы доступ к основному контенту вашего веб-сайта пользователи получали только после того, как заполнят форму подписки или войдут в свою учетную запись, но вы не исключаете ее в правилах файла robot.txt, и поэтому она может проиндексироваться.
Что означают ошибки и предупреждения?
Есть определенный список ошибок, которые могут повлиять на эффективность файла robots.txt, а также вы можете увидеть при проверке файла список определенных рекомендаций. Это вещи, которые могут повлиять на SEO-оптимизацию сайта, и которые нужно исправить. Предупреждения менее критичны, и это просто советы о том, как улучшить ваш сайт robots.txt.Ошибки, которые вы можете увидеть:Invalid URL: эта ошибка сообщает о том, что файл robots.txt на сайте отсутствует.Potential wildcard error: технически это больше предупреждение, чем сообщение об ошибке. Это сообщение обычно означает, что в вашем файле robots.txt содержится символ (*) в поле Disallow (например, Disallow: /*.rss). Это проблема приемлемого использования синтаксиса: Google не запрещает использование символов в поле Disallow, но это не рекомендуется.Generic and specific user-agents in the same block of code: это синтаксическая ошибка в файле robots.txt, которую нужно исправить, чтобы избежать проблем с индексацией контента на вашем веб-сайте.Предупреждения, которые вы можете увидеть:Allow: / : порядок разрешения не повредит и не повлияет на ваш веб-сайт, но это не стандартная практика. Самые крупные поисковые машины, включая Google и Bing, примут эту директиву, но не все программы-кроулеры будут такими же неразборчивыми.
Предупреждения менее критичны, и это просто советы о том, как улучшить ваш сайт robots.txt.Ошибки, которые вы можете увидеть:Invalid URL: эта ошибка сообщает о том, что файл robots.txt на сайте отсутствует.Potential wildcard error: технически это больше предупреждение, чем сообщение об ошибке. Это сообщение обычно означает, что в вашем файле robots.txt содержится символ (*) в поле Disallow (например, Disallow: /*.rss). Это проблема приемлемого использования синтаксиса: Google не запрещает использование символов в поле Disallow, но это не рекомендуется.Generic and specific user-agents in the same block of code: это синтаксическая ошибка в файле robots.txt, которую нужно исправить, чтобы избежать проблем с индексацией контента на вашем веб-сайте.Предупреждения, которые вы можете увидеть:Allow: / : порядок разрешения не повредит и не повлияет на ваш веб-сайт, но это не стандартная практика. Самые крупные поисковые машины, включая Google и Bing, примут эту директиву, но не все программы-кроулеры будут такими же неразборчивыми. Если говорить начистоту, то всегда лучше сделать файл robots.txt совместимым со всеми программами-индексаторами, а не только с самыми популярными.Field name capitalization: несмотря на то, что имена полей не чувствительны к регистру, некоторые индексаторы могут требовать писать их заглавными буквами, так что хорошей идеей будет делать это по умолчанию — специально для самых привередливых программ.Sitemap support: во многих файлах robots.txt содержатся данные о карте сайта, но это не считается хорошим решением. Однако, Google и Bing поддерживают эту возможность.
Если говорить начистоту, то всегда лучше сделать файл robots.txt совместимым со всеми программами-индексаторами, а не только с самыми популярными.Field name capitalization: несмотря на то, что имена полей не чувствительны к регистру, некоторые индексаторы могут требовать писать их заглавными буквами, так что хорошей идеей будет делать это по умолчанию — специально для самых привередливых программ.Sitemap support: во многих файлах robots.txt содержатся данные о карте сайта, но это не считается хорошим решением. Однако, Google и Bing поддерживают эту возможность.
Как исправить ошибки в файле Robots.txt?
Насколько просто будет исправить ошибки в файле robots.txt? Зависит от платформы, которую вы используете. Если это WordPress, то лучше воспользоваться плагином типа WordPress Robots.txt Optimization или Robots.txt Editor. Если вы подключили свой веб-сайт к веб-службе Google Search Console, вы сможете редактировать свой файл robots.txt прямо в ней. Некоторые конструкторы веб-сайтов типа Wix не дают возможности редактировать файл robots.txt напрямую, но позволяют добавлять неиндексируемые теги для определенных страниц.
Некоторые конструкторы веб-сайтов типа Wix не дают возможности редактировать файл robots.txt напрямую, но позволяют добавлять неиндексируемые теги для определенных страниц.
49094
49094
Нравится этот инструмент? Оцените его!
4.7
(Проголосовало 990 пользователей)
Вы уже проголосовали! Отменить
Воспользуйтесь этим инструментом, чтобы оценить его
Это поле обязательно для заполнения
Maximal length of comment is equal 80000 chars
Минимальная длина комментария равна 10 символам
Требуется адрес электронной почты
Неверный адрес электронной почты
Как исправить ошибку «Заблокировано robots.txt» в Google Search Console? » Rank Math
Если вы когда-либо видели ошибку «Заблокировано robots.txt» в своей консоли поиска Google и в отчете о статусе индекса аналитики Rank Math, вы знаете, что это может быть довольно неприятно.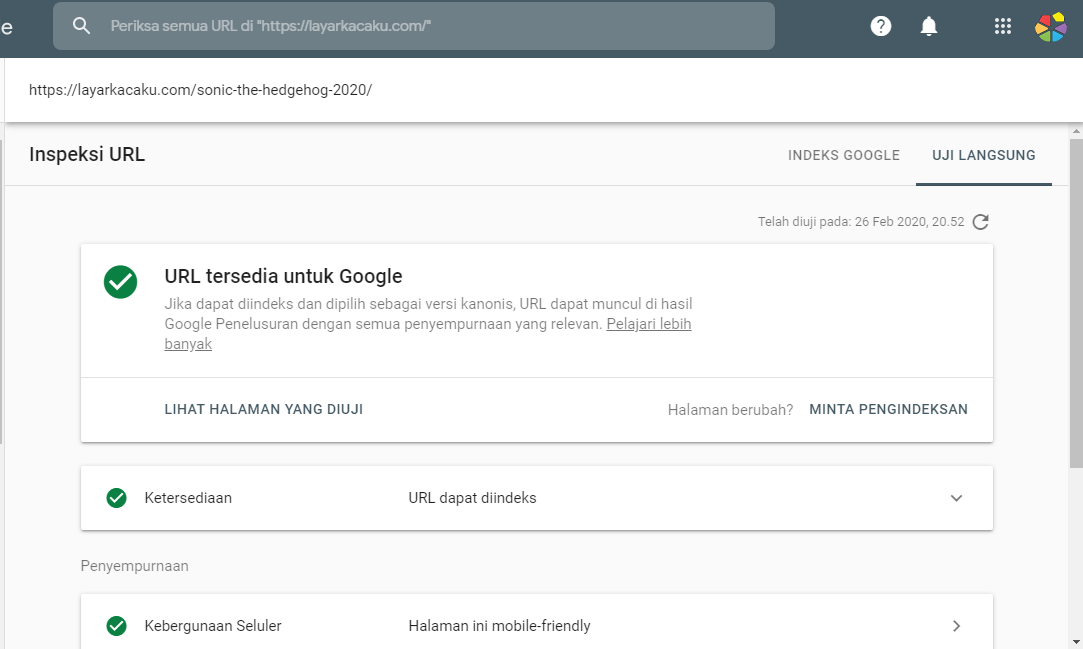 В конце концов, вы соблюдали все правила и позаботились о том, чтобы ваш сайт был оптимизирован для поисковых систем, таких как Google или Bing. Так почему это происходит?
В конце концов, вы соблюдали все правила и позаботились о том, чтобы ваш сайт был оптимизирован для поисковых систем, таких как Google или Bing. Так почему это происходит?
В этой статье базы знаний мы покажем вам, как исправить ошибку «Заблокировано robots.txt», а также объясним, что означает эта ошибка и как предотвратить ее повторение в будущем.
Начнем!
Содержание
- Что означает ошибка?
- Как найти ошибку «Заблокировано robots.txt»?
- Как исправить ошибку «Заблокировано robots.txt»?
- Как предотвратить повторение ошибки
- Заключение
1 Что означает ошибка?
Ошибка «Заблокировано robots.txt» означает, что файл robots.txt вашего веб-сайта блокирует сканирование страницы роботом Googlebot. Другими словами, Google пытается получить доступ к странице, но ему мешает файл robots.txt.
Это может произойти по ряду причин, но наиболее распространенной причиной является неправильная настройка файла robots. txt. Например, вы могли случайно заблокировать роботу Googlebot доступ к странице или включить директиву disallow в файл robots.txt, которая не позволяет роботу Googlebot сканировать страницу.
txt. Например, вы могли случайно заблокировать роботу Googlebot доступ к странице или включить директиву disallow в файл robots.txt, которая не позволяет роботу Googlebot сканировать страницу.
2 Как найти ошибку «Заблокировано robots.txt»?
К счастью, ошибку «Заблокировано robots.txt» довольно легко найти. Вы можете использовать консоль поиска Google или отчет о статусе индекса в аналитике Rank Math, чтобы найти эту ошибку.
2.1 Используйте Google Search Console для поиска ошибки
Чтобы проверить наличие этой ошибки в Google Search Console, просто перейдите на Pages и щелкните раздел Not indexed .
Затем нажмите на ошибку Blocked by robots.txt , как показано ниже:
Если вы нажмете на ошибку, вы увидите список страниц, заблокированных вашим файлом robots.txt.
2.2 Использование аналитики Rank Math для выявления проблемных страниц
Вы также можете использовать отчет о состоянии индекса в аналитике Rank Math, чтобы определить страницы с проблемой.
Для этого перейдите к Rank Math > Analytics на панели управления WordPress. Затем перейдите на вкладку Состояние индекса . На этой вкладке вы получите реальные данные/статус ваших страниц, а также их присутствие в Google.
Кроме того, вы можете отфильтровать статус индекса сообщения, используя раскрывающееся меню. Когда вы выберете определенный статус, скажем, «Заблокировано robot.txt», вы сможете увидеть все сообщения, которые имеют один и тот же статус индекса.
Получив список страниц, которые возвращают этот статус, вы можете приступить к устранению неполадок и устранению проблемы.
3 Как исправить ошибку «Заблокировано robots.txt»?
Чтобы исправить это, вам нужно убедиться, что файл robots.txt вашего веб-сайта настроен правильно. Вы можете использовать инструмент тестирования robots.txt от Google, чтобы проверить свой файл и убедиться, что нет никаких директив, которые блокируют доступ робота Googlebot к вашему сайту.
Если вы обнаружите, что в вашем файле robots.txt есть директивы, которые блокируют доступ робота Googlebot к вашему сайту, вам нужно будет удалить их или заменить более либеральными.
Давайте посмотрим, как вы можете протестировать файл robots.txt и убедиться, что никакие директивы не блокируют доступ робота Googlebot к вашему сайту.
3.1 Откройте тестер robots.txt
Сначала перейдите к тестеру robots.txt. Если ваша учетная запись Google Search Console связана с несколькими веб-сайтами, выберите свой веб-сайт из списка сайтов, показанного в правом верхнем углу. Теперь Google загрузит файл robots.txt вашего сайта.
Вот как это будет выглядеть.
3.2 Введите URL-адрес вашего сайта
В нижней части инструмента вы найдете возможность ввести URL-адрес вашего веб-сайта для тестирования.
3.3 Выберите агент пользователя
В раскрывающемся списке справа от текстового поля выберите агент пользователя, который вы хотите имитировать (в нашем случае Googlebot).
3.4 Проверить Robots.txt
Наконец, нажмите кнопку Проверить .
Сканер немедленно проверит, есть ли у него доступ к URL-адресу на основе конфигурации robots.txt, и, соответственно, тестовая кнопка окажется ПРИНЯТ или ЗАБЛОКИРОВАН .
Редактор кода, доступный в центре экрана, также выделит правило в файле robots.txt, которое блокирует доступ, как показано ниже.
3.5 Редактирование и отладка
Если тестер robots.txt обнаружит какое-либо правило, запрещающее доступ, вы можете попробовать отредактировать правило прямо в редакторе кода, а затем снова запустить тест.
Вы также можете обратиться к нашей специальной статье базы знаний о robots.txt, чтобы узнать больше о принятых правилах, и было бы полезно отредактировать правила здесь.
Если вам удастся исправить правило, то это здорово. Но обратите внимание, что это инструмент отладки, и любые внесенные вами изменения не будут отражены в robots. txt вашего веб-сайта, если вы не скопируете и не вставите содержимое в robots.txt своего веб-сайта.
txt вашего веб-сайта, если вы не скопируете и не вставите содержимое в robots.txt своего веб-сайта.
3.6 Редактирование файла robots.txt с помощью Rank Math
Для этого перейдите к файлу robots.txt в Rank Math, который находится в разделе Панель инструментов WordPress > Rank Math > Общие настройки > Редактировать robots.txt , как показано ниже:
Примечание: Если этот параметр недоступен для вас, убедитесь, что вы используете расширенный режим в Rank Math.
В редакторе кода, расположенном посередине экрана, вставьте код, скопированный из robots.txt. Tester, а затем нажмите кнопку Сохранить изменения , чтобы отразить изменения.
Предупреждение: Будьте осторожны, внося какие-либо существенные или незначительные изменения на свой веб-сайт с помощью файла robots.txt. Хотя эти изменения могут улучшить ваш поисковый трафик, они также могут принести больше вреда, чем пользы, если вы не будете осторожны.
Чтобы узнать больше, смотрите скриншоты ниже:
Вот и все! После внесения этих изменений Google сможет получить доступ к вашему веб-сайту, а ошибка «Заблокировано robots.txt» будет исправлена.
4 Как предотвратить повторное появление ошибки
Чтобы предотвратить повторение ошибки «Заблокировано robots.txt» в будущем, мы рекомендуем регулярно проверять файл robots.txt вашего веб-сайта. Это поможет убедиться, что все директивы точны и что ни одна страница не будет случайно заблокирована для сканирования роботом Googlebot.
Мы также рекомендуем использовать такие инструменты, как Инструменты Google для веб-мастеров, которые помогут вам управлять файлом robots.txt вашего веб-сайта. Инструменты для веб-мастеров позволят вам легко редактировать и обновлять файл robots.txt, а также отправлять страницы для индексации, просматривать ошибки сканирования и многое другое.
5 Заключение
В конце концов, мы надеемся, что эта статья помогла вам узнать, как исправить ошибку «Заблокировано robots. txt» в Google Search Console и в отчете о статусе индекса аналитики Rank Math. Если у вас есть какие-либо сомнения или вопросы, связанные с этим вопросом, пожалуйста, не стесняйтесь обращаться в нашу службу поддержки. Мы доступны 24×7, 365 дней в году и будем рады помочь вам с любыми проблемами, с которыми вы можете столкнуться.
txt» в Google Search Console и в отчете о статусе индекса аналитики Rank Math. Если у вас есть какие-либо сомнения или вопросы, связанные с этим вопросом, пожалуйста, не стесняйтесь обращаться в нашу службу поддержки. Мы доступны 24×7, 365 дней в году и будем рады помочь вам с любыми проблемами, с которыми вы можете столкнуться.
«Заблокировано robots.txt» и «Проиндексировано, но заблокировано robots.txt»
«Проиндексировано, но заблокировано robots.txt» и «Заблокировано robots.txt» — это статусы Google Search Console. Они указывают на то, что затронутые страницы не сканировались, поскольку вы заблокировали их в файле robots.txt.
Однако разница между этими двумя проблемами заключается в следующем:
- С «Заблокировано robots.txt» ваши URL-адреса не будут отображаться в Google,
- В свою очередь, с параметром «Проиндексировано, хотя и заблокировано robots.txt» вы можете видеть уязвимые URL-адреса в результатах поиска, даже если они заблокированы директивой Disallow в файле robots.
 txt. Другими словами, «Проиндексировано, хотя и заблокировано robots.txt» означает, что Google не сканировал ваш URL, но тем не менее проиндексировал его.
txt. Другими словами, «Проиндексировано, хотя и заблокировано robots.txt» означает, что Google не сканировал ваш URL, но тем не менее проиндексировал его.
 txt. Другими словами, «Проиндексировано, хотя и заблокировано robots.txt» означает, что Google не сканировал ваш URL, но тем не менее проиндексировал его.
txt. Другими словами, «Проиндексировано, хотя и заблокировано robots.txt» означает, что Google не сканировал ваш URL, но тем не менее проиндексировал его.Поскольку устранение этих проблем лежит в основе создания эффективной стратегии сканирования и индексации вашего веб-сайта, давайте проанализируем, когда и как их следует решать.
Какое отношение индексация имеет к файлу robots.txt?
Хотя взаимосвязь между файлом robots.txt и процессом индексирования может сбивать с толку, позвольте мне помочь вам глубже разобраться в этой теме. Это облегчит понимание окончательного решения.
Как работают обнаружение, сканирование и индексирование?
Прежде чем страница будет проиндексирована, роботы поисковых систем должны сначала обнаружить и просканировать ее.
На этапе обнаружения сканер узнает, что данный URL-адрес существует. Во время сканирования Googlebot посещает этот URL-адрес и собирает информацию о его содержании. Только после этого URL попадает в индекс и его можно найти среди других результатов поиска.
Псст. Этот процесс не всегда проходит гладко, но вы можете узнать, как помочь ему, прочитав наши статьи:
- Как исправить статус «Обнаружено – в настоящее время не проиндексировано» в GSC и
- Как исправить статус «Просканировано — пока не проиндексировано» в GSC.
Что такое robots.txt?
Robots.txt — это файл, который можно использовать для управления тем, как робот Googlebot сканирует ваш веб-сайт. Всякий раз, когда вы добавляете в него директиву Disallow, робот Googlebot знает, что не может посещать страницы, к которым применяется эта директива.
Но robots.txt не управляет индексацией.
Подробные инструкции по изменению и управлению файлом см. в нашем руководстве robots.txt.
Что вызывает сообщение «Проиндексировано, но заблокировано robots.txt» в Google Search Console?
Иногда Google решает проиндексировать обнаруженную страницу, несмотря на то, что не может ее просканировать и понять ее содержание.
В этом сценарии Google обычно мотивирован множеством ссылок, ведущих на страницу, заблокированную robots.txt.
Ссылки преобразуются в оценку PageRank. Google вычисляет его, чтобы оценить, насколько важна данная страница. Алгоритм PageRank учитывает как внутренние, так и внешние ссылки.
Когда в ваших ссылках беспорядок и Google видит, что запрещенная страница имеет высокое значение PageRank, он может решить, что страница достаточно значима, чтобы поместить ее в индекс.
Однако в индексе будет храниться только пустой URL-адрес без информации о содержимом, так как содержимое не было просканировано.
Почему «Проиндексировано, но заблокировано robots.txt» плохо для SEO?
Статус «Проиндексирован, но заблокирован robots.txt» — серьезная проблема. Это может показаться относительно безобидным, но это может саботировать вашу поисковую оптимизацию двумя важными способами.
Плохое отображение в поиске
Если вы заблокировали данную страницу по ошибке, то «Проиндексирована, но заблокирована robots. txt» не означает, что вам повезло, и Google исправил вашу ошибку.
txt» не означает, что вам повезло, и Google исправил вашу ошибку.
Страницы, проиндексированные без сканирования, не будут выглядеть привлекательно в результатах поиска. Google не сможет отобразить:
- Тег заголовка (вместо этого он автоматически сгенерирует заголовок из URL-адреса или информации, предоставленной страницами, которые ссылаются на вашу страницу),
- Мета-описание,
- Любая дополнительная информация в виде расширенных результатов.
Без этих элементов пользователи не будут знать, чего ожидать после входа на страницу, и могут выбрать конкурирующие веб-сайты, резко снизив ваш CTR.
Вот пример — один из собственных продуктов Google:
Google Jamboard заблокирован от сканирования, но с почти 20000 ссылок с других сайтов (по данным Ahrefs) Google все равно проиндексировал его.
Пока страница ранжируется, она отображается без какой-либо дополнительной информации. Это потому, что Google не смог просканировать его и собрать какую-либо информацию для отображения.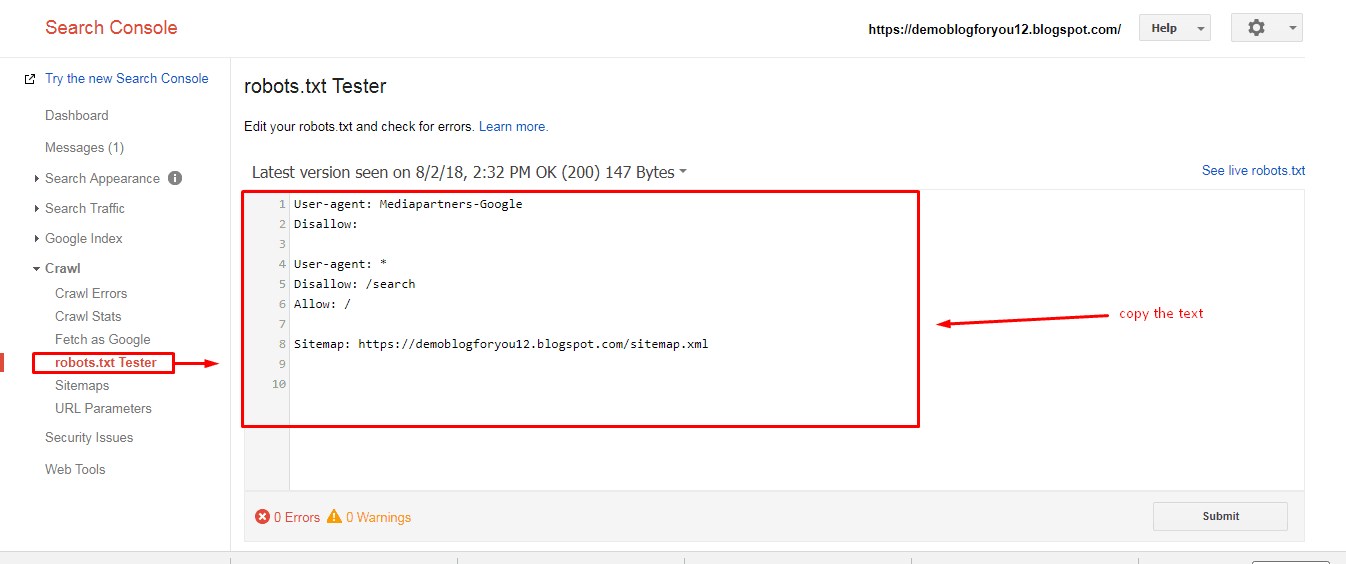 Он показывает только URL-адрес и основной заголовок, основанный на том, что Google нашел на других веб-сайтах, которые ссылаются на Jamboard.
Он показывает только URL-адрес и основной заголовок, основанный на том, что Google нашел на других веб-сайтах, которые ссылаются на Jamboard.
Чтобы узнать, есть ли на вашей странице та же проблема и есть ли «Индексировано, хотя и заблокировано robots.txt», перейдите в консоль поиска Google и проверьте ее в инструменте проверки URL.
Нежелательный трафик
Если вы намеренно использовали директиву Disallow в файле robots.txt для определенной страницы, вы не хотите, чтобы пользователи могли найти эту страницу в Google. Предположим, например, что вы все еще работаете над содержанием этой страницы, и оно еще не готово для всеобщего просмотра.
Но если страница будет проиндексирована, пользователи смогут найти ее, зайти на нее и сформировать отрицательное мнение о вашем сайте.
Как исправить «Проиндексировано, но заблокировано robots.txt?»
Во-первых, найдите статус «Проиндексировано, но заблокировано robots.txt» в нижней части отчета об индексировании страниц в вашей консоли поиска Google.
Там вы можете увидеть таблицу «Улучшить внешний вид страницы».
Нажав на статус, вы увидите список затронутых URL-адресов и диаграмму, показывающую, как их количество менялось с течением времени.
Список можно фильтровать по URL-адресу или URL-пути. Если у вас есть много URL-адресов, затронутых этой проблемой, и вы хотите просмотреть только некоторые части своего веб-сайта, используйте символ пирамиды с правой стороны.
Прежде чем приступить к устранению неполадок, подумайте, действительно ли URL-адреса в списке должны быть проиндексированы. Содержат ли они контент, который может быть полезен вашим посетителям?
Если вы хотите, чтобы страница была проиндексирована
Если страница была запрещена в robots.txt по ошибке, вам необходимо изменить файл.
После удаления директивы Disallow, блокирующей сканирование вашего URL-адреса, робот Googlebot, скорее всего, просканирует его при следующем посещении вашего веб-сайта.
Если вы хотите деиндексировать страницу
Если страница содержит информацию, которую вы не хотите показывать пользователям, посещающим вас через поисковую систему, вы должны сообщить Google, что не хотите индексировать страницу.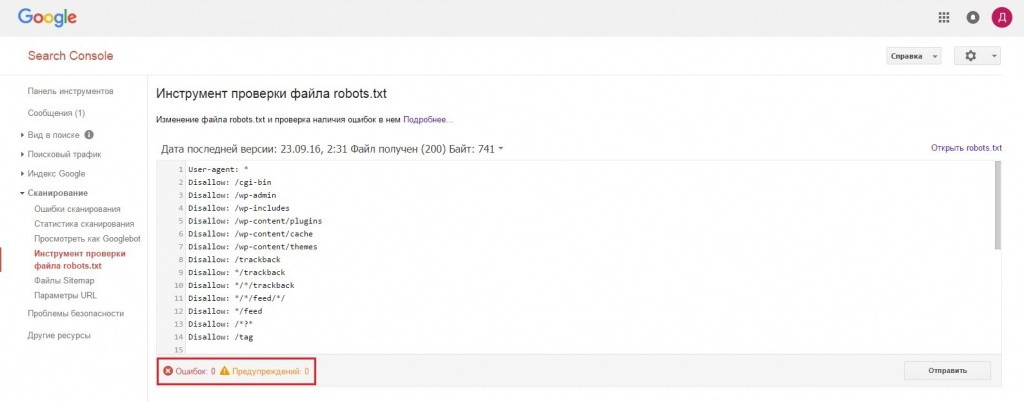
Robots.txt не следует использовать для управления индексацией. Этот файл блокирует сканирование Googlebot. Вместо этого используйте тег noindex.
Google всегда учитывает noindex, когда находит его на странице. Используя его, вы можете гарантировать, что Google не покажет вашу страницу в результатах поиска.
Вы можете найти подробные инструкции по его реализации на своих страницах в нашем руководстве по тегу noindex.
Не забудьте разрешить Google просканировать вашу страницу, чтобы обнаружить этот тег HTML. Это часть содержимого страницы.
Если вы добавите тег noindex, но оставите страницу заблокированной в файле robots.txt, Google не обнаружит этот тег. И страница останется «Проиндексирована, но заблокирована robots.txt».
Когда Google просканирует страницу и увидит тег noindex, она будет удалена из индекса. Консоль поиска Google отобразит другой статус индексации при проверке этого URL-адреса.
Имейте в виду, что если вы хотите скрыть какую-либо страницу от Google и ее пользователей, всегда будет самым безопасным выбором реализовать HTTP-аутентификацию на вашем сервере.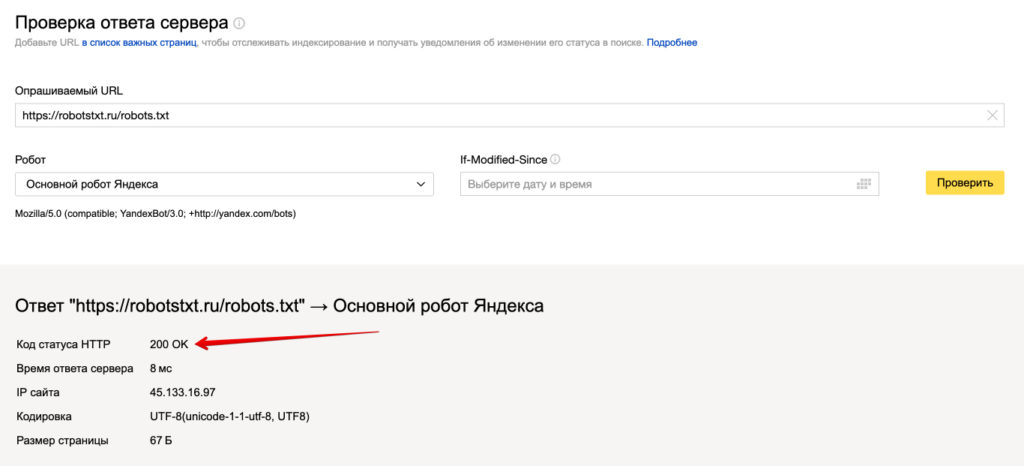 Таким образом, только пользователи, которые вошли в систему, могут получить к нему доступ. Это необходимо, например, если вы хотите защитить конфиденциальные данные.
Таким образом, только пользователи, которые вошли в систему, могут получить к нему доступ. Это необходимо, например, если вы хотите защитить конфиденциальные данные.
Если вам нужно долгосрочное решение
Приведенные выше решения помогут вам на некоторое время решить проблему «Проиндексирован, хотя и заблокирован robots.txt». Однако возможно, что в будущем он появится и на других страницах.
Такой статус указывает на то, что вашему веб-сайту может потребоваться тщательная проверка внутренних ссылок или проверка обратных ссылок.
Что означает «Заблокировано robots.txt» в Google Search Console?
«Заблокировано robots.txt» означает, что Google не просканировал ваш URL-адрес, потому что вы заблокировали его с помощью директивы Disallow в robots.txt. Это также означает, что URL-адрес не был проиндексирован.
Помните, что робот Googlebot не может сканировать некоторые URL-адреса, особенно если ваш сайт становится больше. Некоторые из них не актуальны для поисковых систем по разным причинам.
Некоторые из них не актуальны для поисковых систем по разным причинам.
Решение о том, какие страницы вашего веб-сайта следует и не следует сканировать, является обязательным шагом в создании надежной стратегии индексации вашего веб-сайта.
Как исправить «Заблокировано robots.txt?»
Во-первых, перейдите к таблице «Почему страницы не индексируются» под диаграммой в отчете об индексации страниц, чтобы разобраться с проблемами «Блокировано robots.txt.
Решение этой проблемы требует другого подхода в зависимости от того, заблокировали ли вы свою страницу по ошибке или намеренно.
Позвольте мне рассказать вам, как действовать в этих двух ситуациях:
Когда вы использовали директиву Disallow по ошибке
В этом случае, если вы хотите исправить «Заблокировано robots.txt», удалите блокировку директивы Disallow сканирование заданной страницы.
Благодаря этому робот Googlebot, скорее всего, просканирует ваш URL-адрес при следующем сканировании вашего веб-сайта. Без дальнейших проблем с этим URL Google также проиндексирует его.
Без дальнейших проблем с этим URL Google также проиндексирует его.
Если у вас много URL-адресов, затронутых этой проблемой, попробуйте отфильтровать их в GSC. Нажмите на статус и перейдите к символу перевернутой пирамиды над списком URL-адресов.
Вы можете отфильтровать все затронутые страницы по URL-адресу (или только части пути URL-адреса) и дате последнего обхода.
Если вы видите сообщение «Заблокировано robots.txt», это может также означать, что вы намеренно заблокировали весь каталог, но непреднамеренно включили страницу, которую хотите просканировать. Чтобы устранить эту проблему:
- Включите в директиву Disallow как можно больше фрагментов пути URL, чтобы избежать возможных ошибок или
- Используйте директиву Allow, чтобы разрешить ботам сканировать определенный URL-адрес в запрещенном каталоге.
При изменении файла robots.txt я предлагаю вам проверить свои директивы с помощью тестера robots.txt в Google Search Console.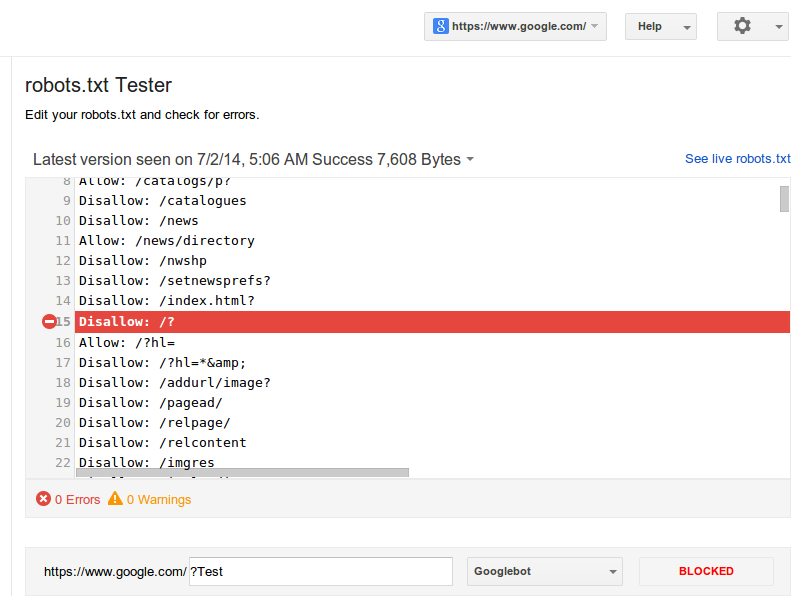 Инструмент загружает файл robots.txt для вашего веб-сайта и помогает вам проверить, правильно ли ваш файл robots.txt блокирует доступ к заданным URL-адресам.
Инструмент загружает файл robots.txt для вашего веб-сайта и помогает вам проверить, правильно ли ваш файл robots.txt блокирует доступ к заданным URL-адресам.
Тестер robots.txt также позволяет проверить, как ваши директивы влияют на конкретный URL-адрес в домене для данного агента пользователя, например, Googlebot. Благодаря этому вы можете поэкспериментировать с применением различных директив и посмотреть, заблокирован или принят URL-адрес.
Однако вы должны помнить, что инструмент не будет автоматически изменять ваш файл robots.txt. Поэтому, когда вы закончите тестирование директив, вам нужно вручную внести все изменения в свой файл.
Дополнительно я рекомендую использовать расширение Robots Exclusion Checker в Google Chrome. При просмотре любого домена инструмент позволяет обнаружить страницы, заблокированные файлом robots.txt. Он работает в режиме реального времени, поэтому поможет вам быстро реагировать, проверять и работать с заблокированными URL-адресами в вашем домене.
Посмотрите мою ветку в Твиттере, чтобы узнать, как я использую этот инструмент выше.
Что делать, если вы продолжаете блокировать важные страницы в robots.txt? Вы можете значительно ухудшить свою видимость в результатах поиска.
Когда вы намеренно использовали директиву Disallow
Вы можете игнорировать статус «Заблокировано robots.txt» в Google Search Console, если вы не запрещаете какие-либо ценные URL-адреса в файле robots.txt.
Помните, что запретить ботам сканировать низкокачественный или дублирующийся контент — это совершенно нормально.
Принятие решения о том, какие страницы должны и не должны сканировать боты, имеет решающее значение для:
- создания стратегии сканирования для вашего веб-сайта и
- Значительно поможет вам оптимизировать и сэкономить краулинговый бюджет.
СЛЕДУЮЩИЕ ШАГИ
Вот что вы можете сделать сейчас:
- Свяжитесь с нами.
- Получите от нас индивидуальный план решения ваших проблем.
