Содержание
Robots.txt — инструкция для SEO
28409 222
| SEO | – Читать 11 минут |
Прочитать позже
ЧЕК-ЛИСТ: ТЕХНИЧЕСКАЯ ЧАСТЬ — ROBOTS.TXT
Ильхом Чакканбаев
Автор блога Seopulses.ru
Файл robots.txt — это текстовый файл, в котором содержатся инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет. В данной статье рассмотрим, где можно найти robots.txt, как его редактировать и какие правила по его использовать в SEO-продвижении.
Содержание
1. Зачем robots.txt нужен на сайте
2. Где можно найти файл robots.txt и как его создать или редактировать
3. Как создать и редактировать robots.txt
4. Инструкция по работе с robots.txt
5. Синтаксис в robots.txt
6. Директивы в Robots.txt
— Disallow
— Allow
— Sitemap
— Crawl-delay
7. Как проверить работу файла robots.txt
— В Google Search Console
Заключение
Зачем robots. txt нужен на сайте
txt нужен на сайте
Командами robots.txt называются директивы, которые разрешают либо запрещают сканировать отдельные участки веб-ресурса. С помощью файла вы можете разрешать или ограничивать сканирование поисковыми роботами вашего веб-ресурса или его отдельных страниц, чем можете повлиять на позиции сайта. Пример того, как именно директивы будут работать для сайта:
На картинке видно, что доступ к определенным папкам, а иногда и отдельным файлам, не допускает к сканированию поисковыми роботами. Директивы в файле носят рекомендательный характер и могут быть проигнорированы поисковым роботом, но как правило, они учитывают данное указание. Техническая поддержка также предупреждает вебмастеров, что иногда требуются альтернативные методы для запрета индексирования:
Какие страницы нужно закрыть от индексации
| Читать |
Где можно найти файл robots.txt и как его создать или редактировать
Чтобы проверить файл robots. txt сайта, следует добавить к домену «/robots.txt», примеры:
txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.com/robots.txt
https://netpeak.net/robots.txt
Как провести анализ индексации сайта
| Читать |
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
Для 1С-Битрикс;
WordPress;
Для Opencart;
Webasyst.


Самые распространенные SEO-ошибки на сайте: инфографика
| Читать |
Инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
User-agent: Googlebot — в случае с краулером Google;
Обращения в robots.txt для Google:
Имена используемые для краулеров от Google:
Googlebot — краулер, индексирующий страницы веб-сайта;
Googlebot Image — сканирует изображения и картинки;
Googlebot Video — сканирует всю видео информацию;
AdsBot Google — анализирует качество размещенной рекламы на страницах для компьютеров;
AdsBot Google Mobile — анализирует качество рекламы мобильных версий сайта;
Googlebot News — оценивает страницы для использования в Google Новости;
AdsBot Google Mobile Apps — расценивает качество рекламы для приложений на андроиде, аналогично AdsBot.

Полный список роботов Google.
Синтаксис в robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
# — отвечает за комментирование;
* — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
$ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.
Почему сайт не индексируется или
как проверить индексацию сайта в Google и Яндекс
| Читать |
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category2/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
Следует указывать полный URL, когда относительный адрес использовать запрещено;
На нее не распространяются остальные правила в файле robots.
txt;XML-карта сайта должна иметь в URL-адресе домен сайта.
 txt;
txt;Пример
Sitemap.xml или карта сайта: как создать и настроить для Google
| Читать |
Crawl-delay
Важно! Данная директива не поддерживается в Google 1 сентября 2019 года, но работает с другими роботами.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Хотите узнать, как использовать Serpstat для поиска ошибок на сайте?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! 😉
| Оставить заявку! |
| Узнать подробнее! |
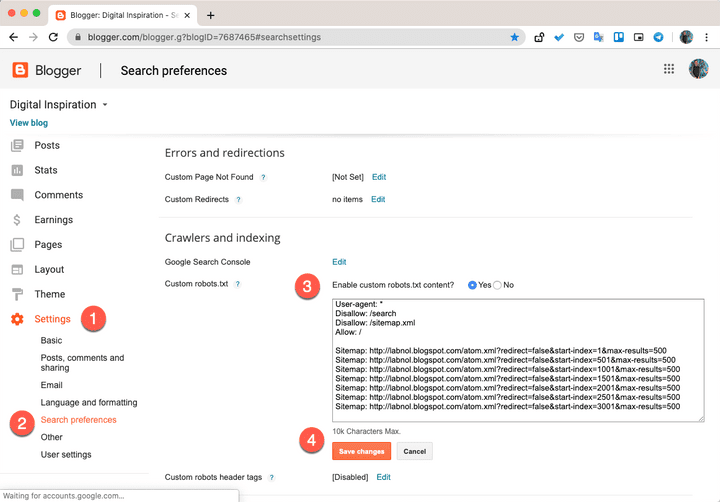
Как проверить работу файла robots. txt
txt
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
Сам файл;
Кнопку, открывающую его;
Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Заключение
Robots.txt необходим для ограничения сканирования определенных страниц вашего сайта, которые не нужно включать в индекс, так как они носят технический характер. Для создания такого документа можно воспользоваться Блокнотом или Notepad++.
Для создания такого документа можно воспользоваться Блокнотом или Notepad++.
Пропишите к каким поисковым роботам вы обращаетесь и дайте им команду, как описано выше.
Далее, проверьте его правильность через встроенные инструменты Google и Яндекс. Если не возникает ошибок, сохраните файл в корневую папку и еще раз проверьте его доступность, перейдя по ссылке http://yoursiteadress.com/robots.txt. Активная ссылка говорит о том, что все сделано правильно.
Помните, что директивы носят рекомендательный характер, а для того чтобы полностью запретить индексирование страницы нужно воспользоваться другими методами.
«Список задач» — готовый to-do лист, который поможет вести учет
о выполнении работ по конкретному проекту. Инструмент содержит готовые шаблоны с обширным списком параметров по развитию проекта, к которым также можно добавлять собственные пункты.
| Начать работу со «Списком задач» |
Оцените статью по 5-бальной шкале
4. 71 из 5 на основе 13 оценок
71 из 5 на основе 13 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Используйте лучшие SEO инструменты
Проверка обратных ссылок
Быстрая проверка обратных ссылок вашего сайта и конкурентов
API для SEO
Получите быстро большие объемы данных используя SЕО API
Анализ конкурентов
Сделайте полный анализ сайтов конкурентов для SEO и PPC
Мониторинг позиций
Отслеживайте изменение ранжирования запросов используя мониторинг позиций ключей
Рекомендуемые статьи
SEO
Анатолий Бондаренко
Основные ошибки в оптимизации сайта и как их выявить
SEO
Ilkhom Chakkanbaev
Идеальная оптимизация страницы сайта: наглядное руководство [Инфографика]
SEO
Анастасия Кочеткова
Краулинговый или рендеринговый бюджет: не вместо, а вместе
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Редактирование файла Robots.txt вашего сайта | Центр Поддержки
Файл robots.txt сообщает поисковым системам, какие страницы вашего сайта следует включать или пропускать в результатах поиска. Поисковые системы проверяют файл robots.txt вашего сайта при сканировании и индексировании вашего сайта. Это не гарантирует, что поисковые системы будут сканировать страницу или файл, но может помочь предотвратить менее точные попытки индексирования.
Если вы хотите повысить точность запросов на сканирование сайта, вы можете отредактировать файл robots.txt.
Содержание
Общее представление о файле robots.
 txt
txt
Файл robots.txt содержит инструкции, позволяющие разрешить или запретить определенные запросы от поисковых систем. Команда «разрешить» сообщает сканерам ссылки, по которым они могут переходить, в то время как команда «запретить» сообщает сканерам ссылки, по которым они не могут перейти. Он также включает URL-адрес файла карты сайта.
Вы можете просмотреть файл robots.txt своего сайта, добавив «/robots.txt» в корневой домен. Например, https://www.mystunningwebsite.com/robots.txt.
Редактирование файла robots.txt
Вы можете отредактировать файл robots.txt своего сайта с помощью редактора Robots.txt в панели SEO вашего сайта. Файл robots.txt сайта по умолчанию разрешает роботам поисковых систем доступ ко всем страницам вашего сайта. Боты могут не получить доступ к определенным страницам:
Прежде чем вносить изменения в файл robots.txt, мы рекомендуем ознакомиться с рекомендациями и ограничениями Google для файлов robot.txt.
Чтобы отредактировать файл robots.
 txt:
txt:
- Перейдите в панель управления SEO.
- Выберите Перейти в редактор Robots.txt в разделе Инструменты и настройки.
- Нажмите Смотреть индекс sitemap.
- Добавьте информацию о файле robots.txt, написав директивы в разделе Это ваш текущий файл.
- Нажмите Сохранить изменения.
- Нажмите Сохранить.
Сброс файла robots.txt
Если вы изменили файл robots.txt на своем сайте и хотите вернуть его обратно, вы можете сбросить его до состояния по умолчанию с помощью редактора Robots.txt в панели управления SEO вашего сайта.
Чтобы сбросить файл robots.txt:
- Перейдите в панель управления SEO.
- Выберите Перейти в редактор Robots.txt в разделе Инструменты и настройки.
- Нажмите Смотреть индекс sitemap.
- Нажмите Восстановить значения по умолчанию.
- Нажмите Сбросить (Reset).
Ошибка robots.txt в инструменте Проверка сайта Wix или Google Search Console
Иногда вы можете видеть ошибки, такие как Заблокировано файлом robots.txt в отчете Проверки сайта Wix или в аккаунте Google Search Console.
Если вы видите такую ошибку, вам не нужно редактировать файл robot.txt, особенно если вы никогда не редактировали его раньше. Вместо этого вам следует проверить свои страницы на наличие следующих настроек:
- Поисковым системам запрещено индексировать страницу в:
- Редакторе сайта
- Настройках SEO сайта для этого типа страниц
- Настройках SEO сайта
- Страница защищена паролем
- Страница предназначена только для пользователей
Если вам нужно обновить страницу, Wix автоматически обновит ваш robots.txt после публикации страницы. Если вы измените настройки сайта, файл robots.txt будет обновлен немедленно.
После того, как вы внесете изменения, поисковые системы обновят свою кэшированную версию файла robots.txt при следующем сканировании вашего сайта. Если вам нужно обновить его раньше, вы можете попробовать отправить свою домашнюю страницу в поисковые системы для переиндексации.
Robots.txt и SEO: полное руководство
Что такое Robots.txt?
Robots.txt — это файл, указывающий поисковым роботам не сканировать определенные страницы или разделы веб-сайта. Большинство основных поисковых систем (включая Google, Bing и Yahoo) распознают и выполняют запросы Robots.txt.
Почему файл robots.txt важен?
Большинству веб-сайтов не нужен файл robots.txt.
Это потому, что Google обычно может найти и проиндексировать все важные страницы вашего сайта.
И они автоматически НЕ будут индексировать страницы, которые не важны, или дублировать версии других страниц.
Тем не менее, есть 3 основные причины, по которым вы хотели бы использовать файл robots. txt.
txt.
Блокировать непубличные страницы. Иногда на вашем сайте есть страницы, которые вы не хотите индексировать. Например, у вас может быть промежуточная версия страницы. Или страница входа. Эти страницы должны существовать. Но вы же не хотите, чтобы на них попадали случайные люди. Это тот случай, когда вы должны использовать robots.txt, чтобы заблокировать эти страницы от сканеров поисковых систем и ботов.
Максимальный краулинговый бюджет. Если вам трудно проиндексировать все ваши страницы, у вас может быть проблема с краулинговым бюджетом. Блокируя неважные страницы с помощью файла robots.txt, робот Googlebot может тратить больше вашего краулингового бюджета на страницы, которые действительно важны.
Предотвращение индексации ресурсов: Использование мета-директив может работать так же хорошо, как Robots.txt для предотвращения индексации страниц. Однако метадирективы плохо работают с мультимедийными ресурсами, такими как PDF-файлы и изображения. Вот где в игру вступает robots.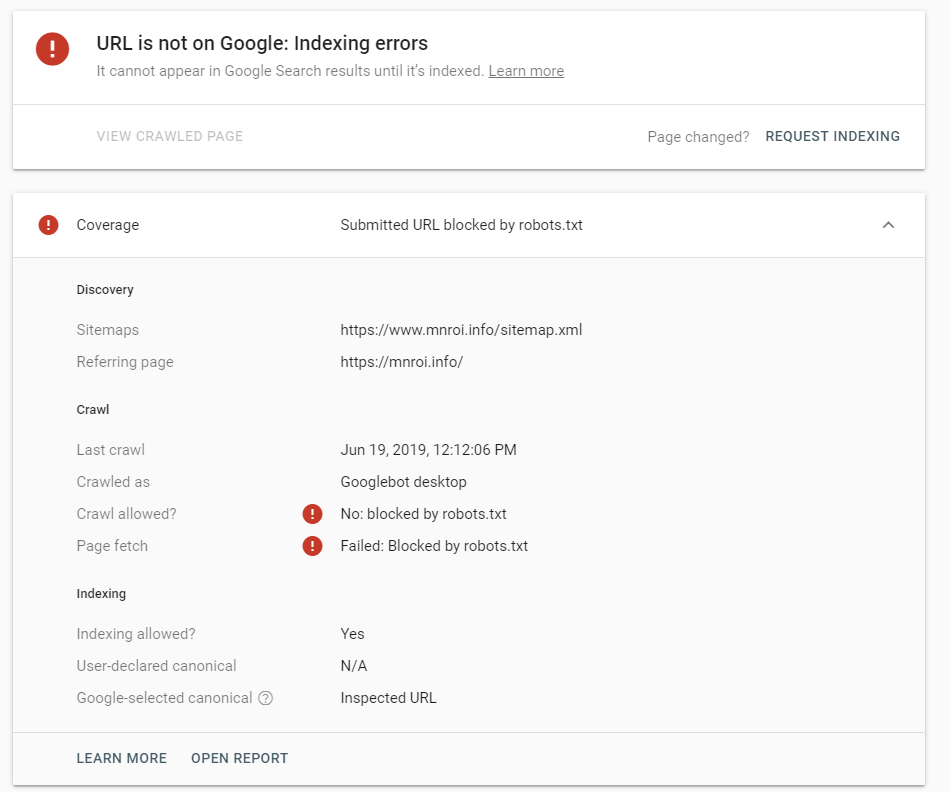 txt.
txt.
Суть? Robots.txt указывает поисковым роботам не сканировать определенные страницы вашего сайта.
Вы можете проверить, сколько страниц вы проиндексировали в Google Search Console.
Если число соответствует количеству страниц, которые вы хотите проиндексировать, вам не нужно возиться с файлом Robots.txt.
Но если это число больше, чем вы ожидали (и вы заметили проиндексированные URL-адреса, которые не должны быть проиндексированы), то пришло время создать файл robots.txt для вашего веб-сайта.
Передовой опыт
Создание файла robots.txt
Первым делом необходимо создать файл robots.txt.
Будучи текстовым файлом, вы можете создать его с помощью блокнота Windows.
И независимо от того, как вы в конечном итоге сделаете свой файл robots.txt, формат будет точно таким же:
User-agent: X
Disallow: Y
User-agent — это конкретный бот, которым вы Разговариваю с.
И все, что идет после «запретить», — это страницы или разделы, которые вы хотите заблокировать.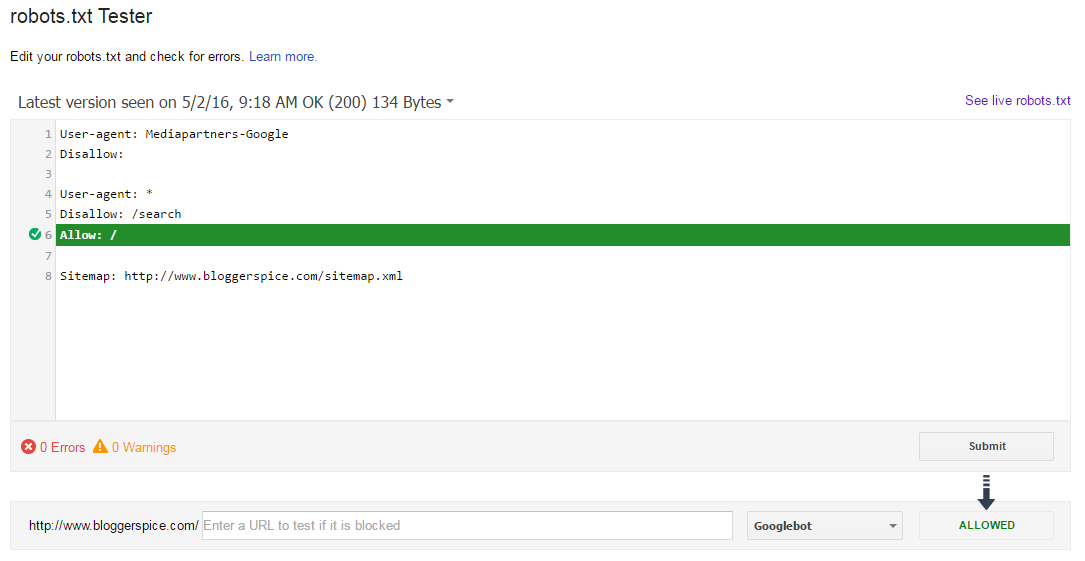
Вот пример:
User-agent: googlebot
Disallow: /images
Это правило предписывает роботу Googlebot не индексировать папку изображений вашего веб-сайта.
Вы также можете использовать звездочку (*), чтобы обратиться ко всем без исключения ботам, которые заходят на ваш сайт.
Вот пример:
User-agent: *
Disallow: /images
«*» указывает всем и каждому паукам НЕ сканировать вашу папку с изображениями.
Это лишь один из многих способов использования файла robots.txt. В этом полезном руководстве от Google содержится дополнительная информация о различных правилах, которые вы можете использовать, чтобы заблокировать или разрешить ботам сканировать разные страницы вашего сайта.
Сделайте так, чтобы ваш файл robots.txt было легко найти
Когда у вас есть файл robots.txt, пришло время запустить его.
Технически вы можете поместить файл robots.txt в любой основной каталог вашего сайта.
Но чтобы увеличить вероятность того, что ваш файл robots.txt будет найден, я рекомендую разместить его по адресу:
https://example.com/robots.txt
(Обратите внимание, что ваш файл robots.txt чувствителен к регистру , Поэтому обязательно используйте строчную букву «r» в имени файла)
Проверка на наличие ошибок и ошибок
ОЧЕНЬ важно, чтобы ваш файл robots.txt был настроен правильно. Одна ошибка, и весь ваш сайт может быть деиндексирован.
К счастью, вам не нужно надеяться, что ваш код настроен правильно. У Google есть отличный инструмент для тестирования роботов, который вы можете использовать:
Он показывает вам ваш файл robots.txt… и любые ошибки и предупреждения, которые он находит:
Как видите, мы блокируем пауков от сканирования нашей страницы администратора WP.
Мы также используем robots.txt, чтобы заблокировать сканирование страниц с автоматически сгенерированными тегами WordPress (для ограничения дублирования контента).
Robots.txt и метадирективы
Зачем вам использовать robots.txt, если вы можете блокировать страницы на уровне страницы с помощью метатега «noindex»?
Как я упоминал ранее, тег noindex сложно реализовать на мультимедийных ресурсах, таких как видео и PDF-файлы.
Кроме того, если у вас есть тысячи страниц, которые вы хотите заблокировать, иногда проще заблокировать весь раздел этого сайта с помощью robots.txt, чем вручную добавлять тег noindex к каждой отдельной странице.
Существуют также крайние случаи, когда вы не хотите тратить краулинговый бюджет на переход Google на страницы с тегом noindex.
При этом:
Помимо этих трех крайних случаев, я рекомендую использовать метадирективы вместо файла robots.txt. Их легче реализовать. И меньше вероятность катастрофы (например, блокировки всего вашего сайта).
Подробнее
Узнайте о файлах robots.txt: полезное руководство о том, как они используют и интерпретируют robots.txt.
Что такое файл robots. txt? (Обзор SEO + Key Insight): лаконичное видео о различных вариантах использования файла robots.txt.
txt? (Обзор SEO + Key Insight): лаконичное видео о различных вариантах использования файла robots.txt.
6 распространенных проблем с файлом robots.txt и способы их устранения
Robots.txt — это полезный и относительно мощный инструмент, который дает роботам поисковых систем указания о том, как вы хотите, чтобы они сканировали ваш веб-сайт.
Он не всемогущ (по словам Google, «это не механизм для защиты веб-страницы от Google»), но он может помочь предотвратить перегрузку вашего сайта или сервера запросами сканера.
Если на вашем сайте установлена эта блокировка сканирования, вы должны быть уверены, что она используется правильно.
Это особенно важно, если вы используете динамические URL-адреса или другие методы, которые теоретически генерируют бесконечное количество страниц.
В этом руководстве мы рассмотрим некоторые наиболее распространенные проблемы с файлом robots.txt, их влияние на ваш веб-сайт и ваше присутствие в поиске, а также способы устранения этих проблем, если вы считаете, что они возникли.
Но сначала давайте кратко рассмотрим файл robots.txt и его альтернативы.
Что такое robots.txt?
Robots.txt использует формат простого текстового файла и размещается в корневом каталоге вашего веб-сайта.
Он должен находиться в самом верхнем каталоге вашего сайта; если вы поместите его в подкаталог, поисковые системы просто проигнорируют его.
Несмотря на свои огромные возможности, robots.txt часто представляет собой относительно простой документ, и простой файл robots.txt можно создать за считанные секунды с помощью редактора, например Блокнота.
Существуют и другие способы достижения тех же целей, для которых обычно используется файл robots.txt.
Отдельные страницы могут включать метатег robots в самом коде страницы.
Вы также можете использовать HTTP-заголовок X-Robots-Tag, чтобы повлиять на то, как (и будет ли) отображаться контент в результатах поиска.
Что может robots.txt?
Robots.txt может дать различные результаты для различных типов контента:
Веб-страницы могут быть заблокированы от сканирования .
Они могут по-прежнему появляться в результатах поиска, но не будут иметь текстового описания. Содержимое страницы, отличное от HTML, также не будет сканироваться.
Медиафайлы могут быть заблокированы от появления в результатах поиска Google.
Сюда входят изображения, видео- и аудиофайлы.
Если файл является общедоступным, он по-прежнему будет «существовать» в Интернете, и его можно будет просмотреть и связать с ним, но этот частный контент не будет отображаться в результатах поиска Google.
Файлы ресурсов, такие как неважные внешние скрипты, могут быть заблокированы .
Но это означает, что если Google просканирует страницу, для загрузки которой требуется этот ресурс, робот Googlebot «увидит» версию страницы, как если бы этот ресурс не существовал, что может повлиять на индексацию.
Вы не можете использовать robots.txt, чтобы полностью заблокировать появление веб-страницы в результатах поиска Google.
Для этого необходимо использовать альтернативный метод, например добавить метатег noindex в заголовок страницы.
Насколько опасны ошибки robots.txt?
Ошибка в robots.txt может иметь непредвиденные последствия, но зачастую это не конец света.
Хорошая новость заключается в том, что, исправив файл robots.txt, вы сможете быстро и (как правило) полностью восстановиться после любых ошибок.
В руководстве Google для веб-разработчиков говорится об ошибках robots.txt:
«Веб-сканеры, как правило, очень гибкие и обычно не реагируют на незначительные ошибки в файле robots.txt. В общем, худшее, что может случиться, это то, что некорректные [или] неподдерживаемые директивы будут проигнорированы.
Помните, однако, что Google не может читать мысли при интерпретации файла robots.txt; мы должны интерпретировать полученный нами файл robots.txt. Тем не менее, если вы знаете о проблемах в файле robots.txt, их обычно легко исправить».

6 Распространенные ошибки в файле robots.txt
- Robots.txt не находится в корневом каталоге.
- Неправильное использование подстановочных знаков.
- Нет индекса в файле robots.txt.
- Заблокированные скрипты и таблицы стилей.
- Нет URL-адреса карты сайта.
- Доступ к сайтам разработки.
Если ваш веб-сайт ведет себя странно в результатах поиска, ваш файл robots.txt — это хорошее место для поиска любых ошибок, синтаксических ошибок и превышения правил.
Давайте рассмотрим каждую из вышеперечисленных ошибок более подробно и посмотрим, как убедиться, что у вас есть действительный файл robots.txt.
1. Robots.txt не находится в корневом каталоге
Поисковые роботы могут обнаружить файл только в том случае, если он находится в корневом каталоге.
Вот почему между .com (или эквивалентным доменом) вашего веб-сайта и именем файла robots.txt в URL-адресе вашего файла robots. txt должна быть только косая черта.
txt должна быть только косая черта.
Если там есть подпапка, ваш файл robots.txt, вероятно, не виден поисковым роботам, и ваш сайт, вероятно, ведет себя так, как будто файла robots.txt вообще нет.
Чтобы решить эту проблему, переместите файл robots.txt в корневой каталог.
Стоит отметить, что для этого вам потребуется root-доступ к вашему серверу.
Некоторые системы управления контентом по умолчанию загружают файлы в подкаталог «media» (или что-то подобное), поэтому вам может потребоваться обойти это, чтобы получить файл robots.txt в нужном месте.
2. Неправильное использование подстановочных знаков
Robots.txt поддерживает два подстановочных знака:
- Звездочка * , который представляет любые экземпляры допустимого символа, например Джокера в колоде карт.
- Знак доллара $ , обозначающий конец URL-адреса, что позволяет применять правила только к последней части URL-адреса, например к расширению типа файла.

Разумно применять минималистский подход к использованию подстановочных знаков, поскольку они могут налагать ограничения на гораздо более широкую часть вашего веб-сайта.
Также относительно легко заблокировать доступ роботов со всего вашего сайта с помощью неудачно расположенной звездочки.
Чтобы решить проблему с подстановочными знаками, вам нужно найти неправильный подстановочный знак и переместить или удалить его, чтобы файл robots.txt работал должным образом.
3. Noindex In Robots.txt
Этот вариант чаще встречается на веб-сайтах, которым больше нескольких лет.
Google перестал соблюдать правила noindex в файлах robots.txt с 1 сентября 2019 г. результаты поиска.
Решение этой проблемы заключается в реализации альтернативного метода noindex.
Одним из вариантов является метатег robots, который можно добавить в заголовок любой веб-страницы, которую вы хотите предотвратить от индексации Google.
4. Заблокированные сценарии и таблицы стилей
Может показаться логичным заблокировать доступ сканера к внешним сценариям JavaScript и каскадным таблицам стилей (CSS).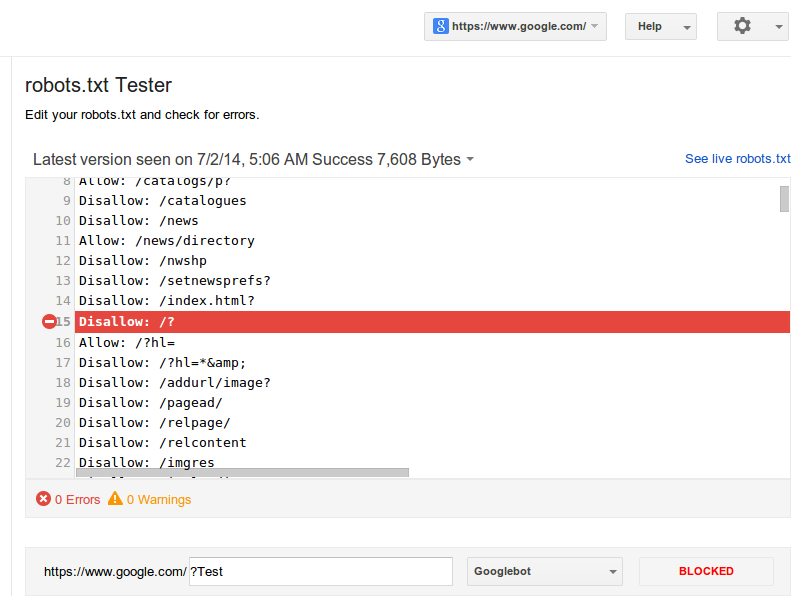
Однако помните, что роботу Googlebot требуется доступ к файлам CSS и JS, чтобы правильно «видеть» ваши HTML- и PHP-страницы.
Если ваши страницы странно отображаются в результатах Google или кажется, что Google не видит их правильно, проверьте, блокируете ли вы доступ сканера к необходимым внешним файлам.
Простое решение этой проблемы — удалить из файла robots.txt строку, блокирующую доступ.
Или, если у вас есть файлы, которые нужно заблокировать, вставьте исключение, которое восстанавливает доступ к необходимым CSS и JavaScript.
5. Нет URL карты сайта
Это больше касается SEO, чем что-либо еще.
Вы можете включить URL-адрес вашей карты сайта в файл robots.txt.
Поскольку это первое, на что обращает внимание робот Googlebot при сканировании вашего веб-сайта, это дает краулеру преимущество в знании структуры и основных страниц вашего сайта.
Хотя это не является строго ошибкой, так как отсутствие карты сайта не должно негативно влиять на фактическую основную функциональность и внешний вид вашего веб-сайта в результатах поиска, все же стоит добавить URL-адрес вашей карты сайта в robots. txt, если вы хотите дать свой SEO усилие.
txt, если вы хотите дать свой SEO усилие.
6. Доступ к сайтам разработки
Блокировать поисковые роботы на вашем действующем веб-сайте нельзя, как и разрешать им сканировать и индексировать ваши страницы, которые все еще находятся в стадии разработки.
Рекомендуется добавить инструкцию о запрете в файл robots.txt веб-сайта, находящегося в стадии разработки, чтобы широкая публика не увидела его, пока он не будет завершен.
В равной степени крайне важно удалить команду запрета при запуске готового веб-сайта.
Забыть удалить эту строку из robots.txt — одна из самых распространенных ошибок среди веб-разработчиков, которая может помешать правильному сканированию и индексированию всего вашего веб-сайта.
Если кажется, что ваш сайт разработки получает реальный трафик или ваш недавно запущенный веб-сайт совсем не работает в поиске, найдите универсальное правило запрета пользовательского агента в файле robots.txt:
User-Agent : *
Disallow: /
Если вы видите это, когда не должны (или не видите, когда должны), внесите необходимые изменения в файл robots. txt и убедитесь, что ваш сайт отображается в результатах поиска. обновления соответственно.
txt и убедитесь, что ваш сайт отображается в результатах поиска. обновления соответственно.
Как исправить ошибку robots.txt
Если ошибка в robots.txt оказывает нежелательное влияние на внешний вид вашего веб-сайта в результатах поиска, самым важным первым шагом является исправление файла robots.txt и проверка того, что новые правила имеют желаемое значение. эффект.
Некоторые инструменты SEO-сканирования могут помочь в этом, так что вам не придется ждать, пока поисковые системы снова просканируют ваш сайт.
Если вы уверены, что robots.txt ведет себя должным образом, вы можете попытаться повторно просканировать свой сайт как можно скорее.
Могут помочь такие платформы, как Google Search Console и Bing Webmaster Tools.
Отправьте обновленную карту сайта и запросите повторное сканирование любых страниц, которые были неправомерно удалены из списка.
К сожалению, вы попали в прихоть робота Google – нет никаких гарантий относительно того, сколько времени потребуется, чтобы отсутствующие страницы вновь появились в поисковом индексе Google.
Все, что вы можете сделать, это предпринять правильные действия, чтобы максимально сократить это время, и продолжать проверять, пока робот Googlebot не внедрит исправленный файл robots.txt.
Заключительные мысли
Когда речь идет об ошибках robots.txt, их предотвращение определенно лучше, чем их устранение.
На большом доходном веб-сайте случайный подстановочный знак, который удаляет весь ваш веб-сайт из Google, может немедленно повлиять на доход.
Изменения в robots.txt должны вноситься опытными разработчиками с осторожностью, дважды проверяться и, при необходимости, с учетом второго мнения.
Если возможно, протестируйте в редакторе песочницы перед запуском на реальный сервер, чтобы избежать непреднамеренного возникновения проблем с доступностью.
Помните, когда случается самое худшее, важно не паниковать.
Диагностируйте проблему, внесите необходимые исправления в файл robots.txt и повторно отправьте карту сайта для нового сканирования.