Содержание
техдиректор оставил заданий на пять лет вперед
01 августа 2013
13:04
В Москве сегодня прощаются с Ильей Сегаловичем, одним из основателей интернет-гиганта «Яндекс». На Троекуровское кладбище пришли родные, друзья, ученики и коллеги. Соболезнования выразил премьер-министр Дмитрий Медведев, который назвал смерть Сегаловича невосполнимой потерей для интернет-сообщества.
В Москве сегодня прощаются с Ильей Сегаловичем, одним из основателей интернет-гиганта «Яндекс». На Троекуровское кладбище пришли родные, друзья, ученики и коллеги. Соболезнования выразил премьер-министр Дмитрий Медведев, который назвал смерть Сегаловича невосполнимой потерей для интернет-сообщества. Илья Сегалович умер 27 июля в возрасте 48 лет.
Вся жизнь – в поиске: Илья Сегалович всегда смотрел в будущее на три года вперед, вспоминают его коллеги. Друзья со снователя «Яндекса» с трудом учатся говорить о нем в прошедшем времени. Программисту и новатору было всего 48. Близкие люди знали, что он борется с тяжелой болезнью. Долгое время, как казалось, лечение шло успешно, но в ночь на четверг случилось обострение, и спасти Илью Сегаловича — не удалось.
Программисту и новатору было всего 48. Близкие люди знали, что он борется с тяжелой болезнью. Долгое время, как казалось, лечение шло успешно, но в ночь на четверг случилось обострение, и спасти Илью Сегаловича — не удалось.
«Он сутками был здесь, он невероятно позитивный человек был. От него исходила буря эмоций постоянная. Это человек, который двигал нас вперед не только как технолог, но и просто в эмоциональном плане. Это был человек, который нас встряхивал, заставлял нас двигаться», — вспоминает директор по распространению технологий «Яндекса» Григорий Бакунов.
Основатели «Яндекса» Аркадий Волож и Илья Сегалович были друзьями с детства. Четыре года они просидели за одной партой. В конце 80-х программисты создали свою первую компанию. За 25 лет они прошли путь от кооператива, который по бартеру обменивал компьютеры на вагоны семечек, до IPO в несколько миллиардов долларов.
«Сначала мы предлагали разным инвесторам купить «Яндекс» за 15 тысяч долларов — они бы получили готовую компанию вместе с программистами, с разработчиками.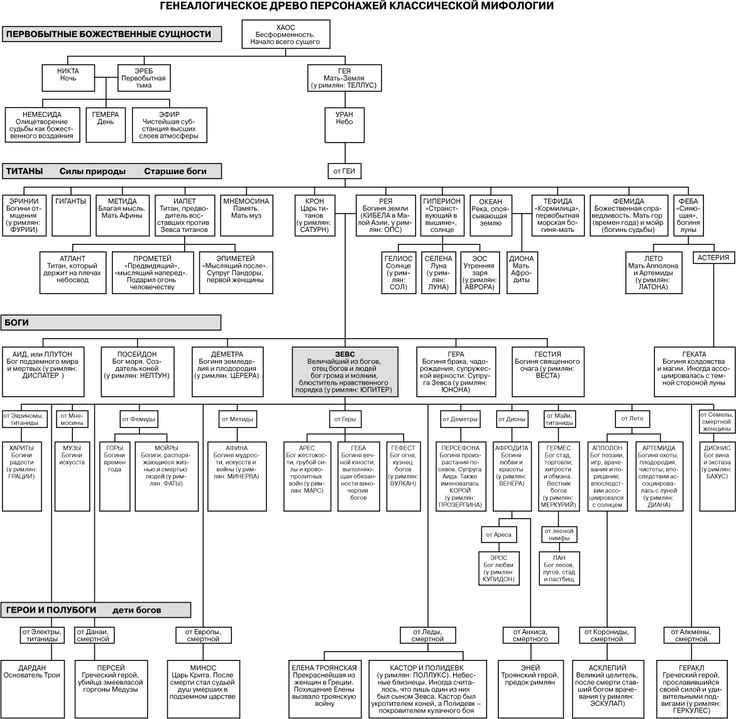 Но все говорили, мол, не-не-не, целых 15 тысяч долларов», — любил рассказывать Илья Сегалович.
Но все говорили, мол, не-не-не, целых 15 тысяч долларов», — любил рассказывать Илья Сегалович.
«Тут заходит Илья, комната переполнена, на проекторе презентация. И он не находит стула, где сесть, и просто ложится на ковролин. Вот так задирает руки за голову и смотрит всю презентацию. Это для меня был шок: как основатель компании, директор компании ложится на ковролин и смотрит презентацию лежа. На самом деле Илья был такой. Он абсолютно не заботился о таких вещах, ему не надо было уступать стул, все были равны и он был равен всем», — говорит руководитель направления мобильных и программных продуктов «Яндекса» Тигран Худавердян.
Источником успеха «Яндекса» стала оригинальная идея – поиск информации на русском языке. Зарубежные поисковики с этой целью справлялись плохо – не учитывали сложную грамматику. Модель навигации своего поисковика разработчики позаимствовали у Библии.
«Cтихи в Священном писании постоянно перекликаются между собой, ссылаются на параллельные места в повествовании. Можно вот, например, по слову «жених» найти все ссылки на это слово», — объяснял Илья Сегалович.
Можно вот, например, по слову «жених» найти все ссылки на это слово», — объяснял Илья Сегалович.
Название «Яндекс» придумал Илья Сегалович, расшифровав его как «Еще один индексатор». Долгое время он занимал в компании пост директора по технологиям. Это под его руководством развивались «Яндекс.Пробки», карты, словари, множество социальных сервисов.
«Он вкладывался в первую очередь в тех, кто работает, а не в железки, в алгоритмы или в код. Это всегда было все про людей. Он тащил за собой, делал человека немножко выше, немножко лучше», — говорит руководитель проектов направления поисковых сервисов «Яндекса» Елена Грунтова.
Интуиция и упорство создателей «Яндекса» позволило компании не только удержаться на плаву, но даже укрепить свои позиции в соперничестве с российскими конкурентами и таким гигантом, как Google.
«Илья делал, кажется, больше всех и так и не успел сделать все, что хотел. Но, слава Богу, здесь, в «Яндексе», у всех людей, которые с ним общались, остался список задач от Ильи на ближайшие черт знает сколько лет. Я вчера просмотрел все письма от Ильи — их там точно лет на пять хватит. Это просто какие-то его идеи», — говорит руководитель направления Антон Забанных.
Я вчера просмотрел все письма от Ильи — их там точно лет на пять хватит. Это просто какие-то его идеи», — говорит руководитель направления Антон Забанных.
Выступал на сцене Илья Сегалович тоже достаточно часто. Как эксперт он участвовал в международных конференциях, проводил семинары для веб-разработчиков. Продвигал не только «Яндекс», но российскую it-науку в целом.
«Пришлось доказывать, что российская наука что-то значит в мировом сообществе. Мы очень много стали писать статей в последние годы. Мы – я понимаю под этим и «Яндекс», и вообще российских исследователей. Наш вклад заметно вырос именно в области Computer Science. Мы получили какое-то определенное доверие, кредит уважения,» – сказал как-то Илья Сегалович.
«Без него сложно представить себе российский Интернет», — признает соучредитель, генеральный директор и председатель совета директоров Mail.Ru Group Дмитрий Гришин.
Друзья, ученики и конкуренты вспоминают одного из создателей «Яндекса» как человека, который очень любил жизнь. Много времени он посвящал благотворительности в фонде своей жены. Для развлечения больных малышей они привозили в клиники международную команду клоунов, в составе которой нередко выступал и технический директор «Яндекса». У самого Ильи Сегаловича осталось пятеро детей.
Много времени он посвящал благотворительности в фонде своей жены. Для развлечения больных малышей они привозили в клиники международную команду клоунов, в составе которой нередко выступал и технический директор «Яндекса». У самого Ильи Сегаловича осталось пятеро детей.
происшествия
новости
«Яндекс» открыл страничку воспоминаний о Сегаловиче
https://ria.ru/20130728/952596677.html
«Яндекс» открыл страничку воспоминаний о Сегаловиче
«Яндекс» открыл страничку воспоминаний о Сегаловиче — РИА Новости, 01.03.2020
«Яндекс» открыл страничку воспоминаний о Сегаловиче
Сегалович был директором компании по технологиям и разработке.
2013-07-28T18:15
2013-07-28T18:15
2020-03-01T12:06
/html/head/meta[@name=’og:title’]/@content
/html/head/meta[@name=’og:description’]/@content
https://cdnn21.img.ria.ru/images/sharing/article/952596677.jpg?9520163191583053597
москва
европа
центральный фо
весь мир
россия
РИА Новости
1
5
4. 7
7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
2013
РИА Новости
1
5
4.7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
Новости
ru-RU
https://ria.ru/docs/about/copyright.html
https://xn--c1acbl2abdlkab1og.xn--p1ai/
РИА Новости
1
5
4.7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
РИА Новости
1
5
4.7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
РИА Новости
1
5
4.7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og. xn--p1ai/awards/
xn--p1ai/awards/
общество, москва, илья сегалович, скончался сооснователь яндекса илья сегалович, прощание с ильей сегаловичем, яндекс, россия
Общество, Москва, Европа, Центральный ФО, Весь мир, Илья Сегалович, Скончался сооснователь Яндекса Илья Сегалович, Прощание с Ильей Сегаловичем, Яндекс, Россия
МОСКВА, 28 июл — РИА Новости. Компания «Яндекс» открыла страничку, где каждый может поделиться воспоминаниями о сооснователе компании Илье Сегаловиче, скончавшемся в Лондоне в субботу.
«Ему было интересно жить, интересно делать, интересно, чтобы получалось. Идея его захватывала полностью, и он так щедро делился этим с нами, тащил за собой, показывал прекрасные, новые миры, которые жили у него в голове, и готов был много часов спорить и ругаться, убеждать, рассказывать, восклицать, махать руками, рисовать и смешить, пока и нам наконец не удавалось уловить отблеск этого чудесного и восхитительного», — вспоминает Елена Грунтова, руководитель программы «Интентный поиск» «Яндекса».
25 июля 2013, 12:35
Биография Ильи СегаловичаРоссийский предприниматель, программист и общественный деятель, один из основателей компании «Яндекс» Илья Сегалович впал в кому в ночь на 25 июля 2013 года. 27 июля он был отключен от аппарата жизнеобеспечения.
«Уход Ильи — огромная потеря для всех нас, кому посчастливилось работать с ним вместе, учиться у него и заражаться его пламенным стремлением сделать жизнь вокруг лучше. Он всегда задавал высочайшую планку, рядом с Ильей всегда было понятно, кто мы и зачем мы: команда единомышленников, мечтающих создавать и совершенствовать нужные людям вещи. И Илья всегда бы впереди, звал за собой, не позволяя остановиться и самодовольно успокоиться на достигнутом», — написала менеджер проекта «Яндекс.Каталог» Галина Тихончук.
«Для того чтобы понять смысл идеи ему нужно было от 15 секунд до минуты. Если его глаза не загорались, становилось ясно — что-то не так. Мне кажется, он не был носителем фиксированных принципов, он был стрелкой компаса, даже острием этой стрелки, он указывал направление. И эта стрелка была одним из главных элементов корабля, который называется «Яндекс». Если он будет жить в каждом из нас, мы не собъемся», — отметил разработчик программы Punto Switcher Сергей Москалев.
И эта стрелка была одним из главных элементов корабля, который называется «Яндекс». Если он будет жить в каждом из нас, мы не собъемся», — отметил разработчик программы Punto Switcher Сергей Москалев.
На странице также размещен комментарий гендиректора «Яндекса» Аркадия Воложа.
«Не знаю, чем можно заменить его энциклопедичность в технологиях и чистое видение продукта. Но он оставил за собой целое новое поколение программистов, целую школу. А его этические стандарты задали уровень всем нам», — отметил он, в частности.
Чем известен Илья Сегалович
Илья Сегалович родился 13 сентября 1964 года. В 1993-1996 годы Аркадий Волож и Илья Сегалович на основе созданных ими классификаторов разработали технологию поиска неструктурированной информации с учетом русского языка, получившую название «Яndex». В 2000 году Сегалович стал одним из основателей компании «Яндекс». Он был директором компании по технологиям и разработке. В четверг, 25 июля, у Сегаловича была зафиксирована смерть головного мозга, он был подключен к аппарату искусственного жизнеобеспечения и в субботу скончался.
Так говорил Илья Сегалович
«Я никогда не боялся нанимать людей умнее себя».
«Поиск данных и поиск ископаемых безумно близки».
«Менеджмент — это то же самое программирование, где вместо кода вы используете людей, их психотипы».
Другие цитаты сооснователя «Яндекса» — в подборке РИА Новости >>
Что такое «Яндекс»
«Яндекс» – российская IT-компания, владеющая одноименной системой поиска в интернете и интернет-порталом. Официальный день рождения поисковой системы Yandex.ru – 23 сентября 1997 года. В этот день система была анонсирована на выставке Softool в Москве.
7 февраля 2013 года российская поисковая система «Яндекс» вышла на четвертое место в мире по числу обрабатываемых запросов, обогнав поисковый сервис компании Microsoft и уступая только поисковикам Google, Baidu и Yahoo.
Доля поиска Яндекса на российском рынке составляет 61,6% (LiveInternet, июнь 2013). Международная аудитория портала — 93,1 миллионов человек (comScore, май 2013). Об истории компании читайте подробнее в справке РИА Новости >>
Об истории компании читайте подробнее в справке РИА Новости >>
Яндекс понимает поисковые намерения пользователей
| Источник:
Яндекс Н.В.
Яндекс Н.В.
МОСКВА, 21 марта 2012 г. (GLOBE NEWSWIRE) — Яндекс (Nasdaq:YNDX) теперь предлагает уточнения поиска, чтобы помочь пользователям Интернета достичь своих целей поиска. Новая функциональность появляется прямо под строкой поиска Яндекса в ответ на неуказанные запросы, помогая пользователям мгновенно уточнять результаты поиска. Те, кто ищет «черника», например, могут искать рецепты черники или, возможно, заинтересоваться пользой для здоровья или питательной ценностью черники. Теперь они могут одним щелчком увидеть именно то, что ищут.
Неуказанные запросы в настоящее время составляют около 20% всех поисковых запросов на Яндексе. В ответ на эти неуказанные запросы поисковая система Яндекса теперь предлагает пользователям варианты на выбор. Пользователи, которые ищут, например, «Чарли Чаплин», должны будут нажать на один из вариантов уточнения поиска, предложенных Яндексом: биография, фото, видео, фильм или цитата.
В ответ на эти неуказанные запросы поисковая система Яндекса теперь предлагает пользователям варианты на выбор. Пользователи, которые ищут, например, «Чарли Чаплин», должны будут нажать на один из вариантов уточнения поиска, предложенных Яндексом: биография, фото, видео, фильм или цитата.
Поисковые уточнения основаны на собственной технологии Яндекса Spectrum, запущенной в декабре 2010 года. Эта технология позволяет поисковой системе Яндекса определять возможные поисковые цели пользователей и предлагать результаты, соответствующие каждой из этих целей. Spectrum включает в результаты поиска ссылки на веб-документы, принадлежащие к разным категориям пользовательских намерений, в зависимости от того, насколько эти категории популярны. Появление поисковых уточнений в поиске Яндекса — еще один шаг в развитии Спектрума.
«Любая поисковая система должна знать, что именно ищет пользователь, и помогать ему это найти», — говорит Елена Грунтова, руководитель программы поиска по намерениям в Яндексе. «Это то, чем Яндекс занимается последние пятнадцать лет, начиная с поисковой системы, чувствительной к словоформе, и заканчивая результатами вертикального поиска из наших собственных сервисов в 2000 году. Запуск поисковых уточнений — еще одна веха на этом пути».
«Это то, чем Яндекс занимается последние пятнадцать лет, начиная с поисковой системы, чувствительной к словоформе, и заканчивая результатами вертикального поиска из наших собственных сервисов в 2000 году. Запуск поисковых уточнений — еще одна веха на этом пути».
Поисковая система на основе намерений, понимающая потребности пользователей и помогающая им достичь своих целей, является одним из ключевых приоритетов Яндекса в 2012 году. В ближайшем будущем Яндекс намерен запустить другие продукты в рамках своей программы поиска на основе намерений.
О Яндексе
Яндекс (Nasdaq:YNDX) — ведущая интернет-компания в России, управляющая самой популярной в стране поисковой системой и самым посещаемым веб-сайтом. Яндекс также работает в Украине, Казахстане, Белоруссии и Турции. Миссия Яндекса — ответить на любой вопрос, который может возникнуть у пользователей интернета.
Логотип компании Яндекс доступен по адресу http://www.globenewswire.com/newsroom/prs/?pkgid=10933
.
ИНТЕРНЕТ
МЕЖДУНАРОДНЫЙ
Контактные данные
Отношения с инвесторами
Дмитрий Барсуков, Катя Жукова
Телефон: +7 495 739-7000
Электронная почта: [email protected]
Контакты для инвесторов из США
The Blueshirt Group, для Яндекса
Алекс Веллинс
Телефон: +1 415 217-5861
Электронная почта: [email protected]
Связи со СМИ
Очир Манджиков, Дина Литвинова
Телефон: +7 495 739-7000
Электронная почта: [email protected]
Контакт
Какой язык можно выучить, задавая вопросы поисковой системе? Мастерская Яндекса / Блог Яндекса / Хабр0001
На наших глазах появились языки, на которых пользователи интернет-поиска составляют свои поисковые запросы. Лексически они слабо отличимы от более привычных языков, например, русского или английского, и в начале своего существования совпадали с праязыками. Но языки поисковых запросов быстро отдалились от родительских и обзавелись собственными наборами идиом, синтаксисом и даже особыми «частями речи». Небольшой размер и простота их грамматик, а также возможность изучать все разнообразие предложений, генерируемых в таких языках, делают их идеальными объектами для тестирования моделей овладения языком.
Лексически они слабо отличимы от более привычных языков, например, русского или английского, и в начале своего существования совпадали с праязыками. Но языки поисковых запросов быстро отдалились от родительских и обзавелись собственными наборами идиом, синтаксисом и даже особыми «частями речи». Небольшой размер и простота их грамматик, а также возможность изучать все разнообразие предложений, генерируемых в таких языках, делают их идеальными объектами для тестирования моделей овладения языком.
Я провел небольшое исследование языка запросов, на котором пользователи обращаются к поиску Яндекса, и на его основе подготовил отчет. Как это часто бывает, вопросов больше, чем ответов. Однако результаты оказались довольно интересными.
Также хочу поблагодарить Елену Грунтову за одну из основных идей для исследования и помощь в подготовке отчета.
Начнем мы не совсем с языка поисковых запросов, а с проблемы овладения языком и почему он так важен для лингвистики, когнитивистики и может заинтересовать любого мыслящего человека. Проблема в том, что мы не до конца понимаем, как дети быстро осваивают довольно сложный понятийный и грамматический аппарат, увеличивают свой словарный запас на уровне, на котором мы еще не можем научить машину понимать естественный язык. Тайну процесса овладения языком люди осознали еще во времена Платона, а то и раньше. На протяжении всего этого времени в спорах доминировали два основных направления: нативизм и эмпиризм. Нативисты считают, что при овладении языком большая часть информации в нашем мозгу уже каким-то образом «зашита», а эмпирики утверждают, что
Проблема в том, что мы не до конца понимаем, как дети быстро осваивают довольно сложный понятийный и грамматический аппарат, увеличивают свой словарный запас на уровне, на котором мы еще не можем научить машину понимать естественный язык. Тайну процесса овладения языком люди осознали еще во времена Платона, а то и раньше. На протяжении всего этого времени в спорах доминировали два основных направления: нативизм и эмпиризм. Нативисты считают, что при овладении языком большая часть информации в нашем мозгу уже каким-то образом «зашита», а эмпирики утверждают, что
Одна из идей, присущих нативизму, заключается в том, что все естественные языки имеют одинаковый набор признаков — универсалий. Нативизм также настаивает на аргументе побудительной бедности, который призван объяснить, почему нельзя обойтись без большого количества врожденных знаний в овладении языком. Подсчитано, что к моменту поступления ребенка в школу его словарный запас насчитывает около двух тысяч слов. Это означает, что с момента своего рождения он учил одно или два новых слова в день. Каждое из них он слышит не более нескольких раз, но этого ему достаточно, чтобы понять, как эти слова видоизменяются, сочетаются друг с другом, отличать одушевленные предметы от неодушевленных и т. д.
Каждое из них он слышит не более нескольких раз, но этого ему достаточно, чтобы понять, как эти слова видоизменяются, сочетаются друг с другом, отличать одушевленные предметы от неодушевленных и т. д.
При попытке повторить это в машинном виде в виде какого-то алгоритма, который мог бы изучать языки хотя бы с такой же эффективностью, возникают некоторые трудности. Во-первых, такой решатель ограничен тем, что получает только положительные примеры, фразы, допустимые грамматикой языка, и не получает опровержений. Кроме того, на алгоритм, который может моделировать овладение языком, накладываются некоторые алгоритмические ограничения. В частности, мы не можем себе позволить пройтись по всем контекстно-свободным грамматикам, которым подошли бы все известные нам примеры, и выбрать самую простую. Нам это не разрешено, потому что такая задача является NP-полной.
Перейдем непосредственно к языку запросов. Моя идея в том, что это более простой лингвистический объект, чем полноценный естественный язык, а не тривиальный набор слов. Он имеет свою структуру, свою логику развития и логику изучения человеком этого языка чем-то напоминает логику изучения естественного языка.
Он имеет свою структуру, свою логику развития и логику изучения человеком этого языка чем-то напоминает логику изучения естественного языка.
Мы можем наблюдать, как постепенно меняются запросы человека, который только начал пользоваться поисковиком. Есть две стратегии: первые запросы могут состоять из называния одного предмета, либо это хорошо и грамматически правильно оформленная фраза на русском языке. Через некоторое время люди замечают, что определенные конструкции приводят их к коммуникативному успеху. Они видят, что машина их поняла, добиваются нужного результата. Другие схемы не работают. Например, длинные фразы, написанные координированным русским языком, часто остаются непонятыми машиной. Пользователь начинает доводить свои пожелания до удачных разработок, перенимать их у других пользователей (в том числе и через сест). Он отмечает, что если в конце запроса добавить волшебные слова «скачать бесплатно»,
Как принято в академической лингвистике, здесь и далее звездочками буду обозначать утверждения, неприемлемые с точки зрения грамматики изучаемого языка. Квадратные скобки традиционно включают поисковые запросы. Давайте рассмотрим три примера:
Квадратные скобки традиционно включают поисковые запросы. Давайте рассмотрим три примера:
- [восточная музыка слушать онлайн]
- [слушать восточную музыку онлайн]
- * [слушать восточную музыку онлайн]
Второй вариант действителен и в русском языке, и в языке запросов, первый действителен только в языке запросов, а третий не допускается ни в том, ни в другом, хотя согласование там лучше, чем в первом. У нас есть статистика распространенности запросов, и в тех случаях, когда мы ставим звездочку и говорим, что опция запрещена в языке запросов, подразумевается, что такие формы запросов встречаются крайне редко.
Русская версия языка запросов не совпадает с обычным русским языком, хотя лексический состав практически идентичен. Он возник примерно в 1997 году и с тех пор достаточно активно развивается. Если в самом начале средняя длина запроса составляла 1,2 слова, то к 2013 году этот показатель уже достиг 3,5 слова.
Еще одним аргументом в пользу восприятия языка запросов как полноценного лингвистического объекта является закон Ципфа. В естественных языках слово n-е по частоте употребления имеет частоту употребления примерно пропорциональную 1/n. И эта зависимость особенно хорошо видна, если мы расположим график в двойном логарифмическом масштабе. Мы видим, что слова в языке вопросов идеально лежат на прямой под углом 45 градусов, что по закону Ципфа является признаком естественного языка:
Если сравнить словарную энтропию (т.е. сколько бит нам в среднем нужно для описания вхождения каждого следующего слова) русского языка и языка запросов, то для первого этот показатель будет около 11 бит (например, тексты Л. Н. Толстого), а для второго — около 12. Т.е. словарный запас всех людей, задающих вопросы, примерно в 4 раза больше словарного запаса Толстого. В то же время очевидно, что язык запросов с точки зрения общения является довольно странным языком, поскольку с его помощью люди не общаются друг с другом, а обращаются к поисковой системе. Соответственно, прагматика высказываний всегда одинакова, поэтому доля некоторых конструкций будет заметно отличаться. Например, доля глаголов в языке запросов в языке запросов составляет 5,4 %, а в русском языке — 17,5 %. Дело в том, что они используются с другой функцией, обычно глаголами, отражающими намерение пользователя: «скачать», «посмотреть», «послушать». Так что если посмотреть на долю 10 самых частотных среди всех глаголов, то она будет гораздо выше — 46% против 11,4% в русском языке. Грамматически язык намного проще, так как средняя длина фразы в нем не превышает четырех слов. Это даже не полные предложения, а высказывания. Возникает вопрос, можно ли в таком случае говорить вообще о синтаксисе языка запросов? Мы верим, что это возможно. В подтверждение этого рассмотрим некоторые примеры, на которых видно, что в языке запросов можно встретить конструкции, нехарактерные для русского языка, но часто встречающиеся в других, например, в японском. Грамматически язык намного проще, так как средняя длина фразы в нем не превышает четырех слов.
Соответственно, прагматика высказываний всегда одинакова, поэтому доля некоторых конструкций будет заметно отличаться. Например, доля глаголов в языке запросов в языке запросов составляет 5,4 %, а в русском языке — 17,5 %. Дело в том, что они используются с другой функцией, обычно глаголами, отражающими намерение пользователя: «скачать», «посмотреть», «послушать». Так что если посмотреть на долю 10 самых частотных среди всех глаголов, то она будет гораздо выше — 46% против 11,4% в русском языке. Грамматически язык намного проще, так как средняя длина фразы в нем не превышает четырех слов. Это даже не полные предложения, а высказывания. Возникает вопрос, можно ли в таком случае говорить вообще о синтаксисе языка запросов? Мы верим, что это возможно. В подтверждение этого рассмотрим некоторые примеры, на которых видно, что в языке запросов можно встретить конструкции, нехарактерные для русского языка, но часто встречающиеся в других, например, в японском. Грамматически язык намного проще, так как средняя длина фразы в нем не превышает четырех слов. Это даже не полные предложения, а высказывания. Возникает вопрос, можно ли в таком случае говорить вообще о синтаксисе языка запросов? Мы верим, что это возможно. В подтверждение этого рассмотрим некоторые примеры, где мы можем увидеть, что в языке запросов можно встретить конструкции, не характерные для русского языка, но часто встречающиеся в других, например, в японском. Грамматически язык намного проще, так как средняя длина фразы в нем не превышает четырех слов. Это даже не полные предложения, а высказывания. Возникает вопрос, можно ли в таком случае говорить вообще о синтаксисе языка запросов? Мы верим, что это возможно. В подтверждение этого рассмотрим некоторые примеры, на которых видно, что в языке запросов можно встретить конструкции, нехарактерные для русского языка, но часто встречающиеся в других, например, в японском.
Это даже не полные предложения, а высказывания. Возникает вопрос, можно ли в таком случае говорить вообще о синтаксисе языка запросов? Мы верим, что это возможно. В подтверждение этого рассмотрим некоторые примеры, где мы можем увидеть, что в языке запросов можно встретить конструкции, не характерные для русского языка, но часто встречающиеся в других, например, в японском. Грамматически язык намного проще, так как средняя длина фразы в нем не превышает четырех слов. Это даже не полные предложения, а высказывания. Возникает вопрос, можно ли в таком случае говорить вообще о синтаксисе языка запросов? Мы верим, что это возможно. В подтверждение этого рассмотрим некоторые примеры, на которых видно, что в языке запросов можно встретить конструкции, нехарактерные для русского языка, но часто встречающиеся в других, например, в японском.
- [фото котят]
- [фото котят]
- * [фото котят]
Не очень понятно, что происходит в первых двух запросах, но мы ясно видим, что в третьей позиции перед нами традиционная именная группа, согласованная родительным падежом. Теперь рассмотрим группу глаголов:
Теперь рассмотрим группу глаголов:
- [смотреть трейлер Family croods]
- [трейлер Family croods смотреть]
У нас есть один объект — «прицеп семейства сырых», с которым мы хотим выполнить определенное действие — «смотреть». Далее у нас языковая конструкция, практически не встречающаяся в русском языке — топизация. Это очень распространено, например, в японском языке. Там можно привести тему — о чем идет речь — поставить в начале предложения. Актуализация также может быть выполнена на языке запросов:
- [Экипажи прицепа наблюдают за семьей]
- [Семейство Крудов наблюдает за прицепом]
Если предположить, что это именно то, что происходит, а не какой-то мешок слов, который люди абы как тасуют, то естественно предположить, что другие конструкции должны быть запрещены. И это действительно так. Конструкции не хуже четырех, которые мы привели выше, не встречаются или встречаются очень редко:
- * [трейлер к просмотру семьи Крудс]
- * [смотреть семейный трейлер Croods]
Можно предположить, что наша гипотеза о топикализации подтвердилась, и попытаться выяснить, что происходит в первых двух запросах о котятах:
- [фото котят]
- [фото котят]
Похоже, что первый запрос — это исходная структура, а второй — еще один пример актуализации.
Вычислительные модели
Имея большой корпус языка, можно статистически оценить его усвоение с помощью простых тестов. Тело языка запросов огромно по своей природе. Ежедневно в Яндекс приходят сотни миллионов поисковых запросов, соответственно корпуса на миллиарды утверждений можно брать чуть ли не из воздуха. Это позволяет не только оценивать вычислительные модели, но и сравнивать их друг с другом вплоть до статистической значимости различия и т. д. Придумаем простейшую задачу, которая поможет нам оценить, изучил ли алгоритм или модель язык и как хорошо. Например, задача с восстановлением пропущенного слова:
- [в лесу *елка в лесу она росла]
- [mp3* бесплатно и без регистрации]
Идея состоит в том, что в ста процентах случаев эту задачу решить невозможно, но чем лучше кто-то освоил язык, тем в большем проценте случаев он решит эту задачу. И если у нас есть много примеров, как бы ни была велика разница между тестируемыми, мы все равно можем ее увидеть и сделать статистически значимой. При работе с естественными языками это чаще всего невозможно из-за ограниченности случаев.
При работе с естественными языками это чаще всего невозможно из-за ограниченности случаев.
Как можно создать модель, которая пытается реконструировать слова таким образом? Самый простой вариант — N-граммы, когда мы берем последовательность слов и говорим, что вероятность появления следующего слова в цепочке зависит только от того, сколько предыдущих. Затем мы оцениваем вероятность и подставляем это слово. Такие N-граммы могут дать нам возможность восстановить предыдущее следующее слово или слово в середине:
- [… скачать без * …] => регистрация
- [… * принцесса с карандашом ] => нарисовать
- [… проклятый * друон] => короли
Это не очень интересная модель. По сути, мы просто вспомнили, какие конструкции есть в языке и никоим образом не обобщаем ничего явно. Очевидно, что машина, использующая только такие шаблоны без обобщения, будет иметь гораздо худшее знание языка, чем машина, использующая более сложные правила. В качестве таких правил мы стараемся выбирать одинаковые шаблоны, в которых одни слова заменяются множеством разных слов. Например, мы можем заметить, что если после словосочетания «сокол и *» стоят слова, указывающие на контекст книги (названия форматов файлов, слово «читал» или «автор»), то слово «ласточка» скорее всего отсутствует .
В качестве таких правил мы стараемся выбирать одинаковые шаблоны, в которых одни слова заменяются множеством разных слов. Например, мы можем заметить, что если после словосочетания «сокол и *» стоят слова, указывающие на контекст книги (названия форматов файлов, слово «читал» или «автор»), то слово «ласточка» скорее всего отсутствует .
Также можем изучить уровень «знания» языка в зависимости от количества обучающих примеров: 3100 фраз, 6200 фраз, 12400 фраз, 24800 фраз, 41000 фраз. Верхняя граница примерно соответствует количеству фраз, которые ребенок слышит в первые два года жизни. Потенциально можно проследить, в какой именно момент кривая изгибается и новая информация перестает поступать. Но при 41 000 фраз даже на графиках моделей N-грамм видно, что движение не останавливается. Синий цвет на графике показывает, сколько процентов слов модель угадывает на тестах, а красный и синий — интервалы 3Σ. Интересно, что контексты слева от угаданного слова помогают идентифицировать его на один процент лучше. А если использовать правый и левый контексты одновременно, процент угадывания увеличивается на десять процентов.
А если использовать правый и левый контексты одновременно, процент угадывания увеличивается на десять процентов.
Наш следующий прорыв должен произойти, когда мы начнем использовать обобщенные дизайны шаблонов. В качестве кандидатов на эту роль мы выберем два разных типа: грамматический и контекстуально-понятийный. У нас в Яндексе есть замечательный инструмент — леммер. Он может сказать о каждом слове, какая у него лемма и как он пришел к текущему виду из этой леммы. позволяет определить начальную форму любого слова. Таким образом, мы можем добавить грамматический контекст:
- [(S, их, и) * торрент] => скачать
- [инструкция * (S, даты, единицы)] => по
В случае контекстно-понятийных паттернов можно попытаться обобщить некоторые наборы слов. Например, мы можем выделить Х как некоторый набор слов и словосочетаний, для которых справедливы выражения [Х тюнинг] и [Х цена]:
- [стук * Х], действительны [Х тюнинг] и [Х цена] = > двигатель
Тогда возникает вопрос, можно ли получить столько информации, сколько содержится в граммах, только из контекстов? Было бы просто замечательно, если бы мы знали, что можно не выделять части речи и не отделять грамматические модели от смысловых, а просто сводить все к единому понятийному типу. Если мы добавим обобщенные шаблоны, используя всю доступную грамматику, мы получим результат, гарантирующий увеличение на 0,2 процента. Это довольно забавно по сравнению с тем, что мы видели выше, но именно где-то здесь мы быстро упираемся в тот самый потолок, пробить который очень сложно. Но именно он соответствует пониманию языка, к которому все стремятся. Контекстно-концептуальные шаблоны позволяют добиться еще меньших результатов — 0,04%. Получается, что ответ на наш вопрос отрицательный: в грамме содержится больше информации. Однако остается открытым вопрос о том, можно ли получить ту же информацию, используя более сильные обобщения. Мы не использовали тот факт, что словоформы одного и того же слова очень похожи друг на друга, а суффиксы разных словоформ с одной и той же грамматикой часто похожи друг на друга. Можно ли с помощью таких обобщений вывести информацию, эквивалентную по силе решению тестовой задачи только из словоупотребления? И если да, то как формализовать этот алгоритм? Можно ли с помощью таких обобщений вывести информацию, эквивалентную по силе решению тестовой задачи только из словоупотребления? И если да, то как формализовать этот алгоритм? Можно ли с помощью таких обобщений вывести информацию, эквивалентную по силе решению тестовой задачи только из словоупотребления? И если да, то как формализовать этот алгоритм?
Если мы добавим обобщенные шаблоны, используя всю доступную грамматику, мы получим результат, гарантирующий увеличение на 0,2 процента. Это довольно забавно по сравнению с тем, что мы видели выше, но именно где-то здесь мы быстро упираемся в тот самый потолок, пробить который очень сложно. Но именно он соответствует пониманию языка, к которому все стремятся. Контекстно-концептуальные шаблоны позволяют добиться еще меньших результатов — 0,04%. Получается, что ответ на наш вопрос отрицательный: в грамме содержится больше информации. Однако остается открытым вопрос о том, можно ли получить ту же информацию, используя более сильные обобщения. Мы не использовали тот факт, что словоформы одного и того же слова очень похожи друг на друга, а суффиксы разных словоформ с одной и той же грамматикой часто похожи друг на друга. Можно ли с помощью таких обобщений вывести информацию, эквивалентную по силе решению тестовой задачи только из словоупотребления? И если да, то как формализовать этот алгоритм? Можно ли с помощью таких обобщений вывести информацию, эквивалентную по силе решению тестовой задачи только из словоупотребления? И если да, то как формализовать этот алгоритм? Можно ли с помощью таких обобщений вывести информацию, эквивалентную по силе решению тестовой задачи только из словоупотребления? И если да, то как формализовать этот алгоритм?
Сводка
На наших глазах вырос новый языковой объект.