Содержание
Основы Elasticsearch / Хабр
Elasticsearch — поисковый движок с json rest api, использующий Lucene и написанный на Java. Описание всех преимуществ этого движка доступно на официальном сайте. Далее по тексту будем называть Elasticsearch как ES.
Подобные движки используются при сложном поиске по базе документов. Например, поиск с учетом морфологии языка или поиск по geo координатам.
В этой статье я расскажу про основы ES на примере индексации постов блога. Покажу как фильтровать, сортировать и искать документы.
Чтобы не зависеть от операционной системы, все запросы к ES я буду делать с помощью CURL. Также есть плагин для google chrome под названием sense.
По тексту расставлены ссылки на документацию и другие источники. В конце размещены ссылки для быстрого доступа к документации. Определения незнакомых терминов можно прочитать в глоссарии.
Для этого нам сначала потребуется Java. Разработчики рекомендуют установить версии Java новее, чем Java 8 update 20 или Java 7 update 55.
Дистрибутив ES доступен на сайте разработчика. После распаковки архива нужно запустить bin/elasticsearch. Также доступны пакеты для apt и yum. Есть официальный image для docker. Подробнее об установке.
После установки и запуска проверим работоспособность:
# для удобства запомним адрес в переменную #export ES_URL=$(docker-machine ip dev):9200 export ES_URL=localhost:9200 curl -X GET $ES_URL
Нам придет приблизительно такой ответ:
{
"name" : "Heimdall",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.2.1",
"build_hash" : "d045fc29d1932bce18b2e65ab8b297fbf6cd41a1",
"build_timestamp" : "2016-03-09T09:38:54Z",
"build_snapshot" : false,
"lucene_version" : "5.4.1"
},
"tagline" : "You Know, for Search"
}Добавим пост в ES:
# Добавим документ c id 1 типа post в индекс blog.
# ?pretty указывает, что вывод должен быть человеко-читаемым.
curl -XPUT "$ES_URL/blog/post/1?pretty" -d'
{
"title": "Веселые котята",
"content": "<p>Смешная история про котят<p>",
"tags": [
"котята",
"смешная история"
],
"published_at": "2014-09-12T20:44:42+00:00"
}'
ответ сервера:
{
"_index" : "blog",
"_type" : "post",
"_id" : "1",
"_version" : 1,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"created" : false
}
ES автоматически создал индекс blog и тип post. Можно провести условную аналогию: индекс — это база данных, а тип — таблица в этой БД. Каждый тип имеет свою схему — mapping, также как и реляционная таблица. Mapping генерируется автоматически при индексации документа:
Можно провести условную аналогию: индекс — это база данных, а тип — таблица в этой БД. Каждый тип имеет свою схему — mapping, также как и реляционная таблица. Mapping генерируется автоматически при индексации документа:
# Получим mapping всех типов индекса blog curl -XGET "$ES_URL/blog/_mapping?pretty"
В ответе сервера я добавил в комментариях значения полей проиндексированного документа:
{
"blog" : {
"mappings" : {
"post" : {
"properties" : {
/* "content": "<p>Смешная история про котят<p>", */
"content" : {
"type" : "string"
},
/* "published_at": "2014-09-12T20:44:42+00:00" */
"published_at" : {
"type" : "date",
"format" : "strict_date_optional_time||epoch_millis"
},
/* "tags": ["котята", "смешная история"] */
"tags" : {
"type" : "string"
},
/* "title": "Веселые котята" */
"title" : {
"type" : "string"
}
}
}
}
}
}Стоит отметить, что ES не делает различий между одиночным значением и массивом значений. Например, поле title содержит просто заголовок, а поле tags — массив строк, хотя они представлены в mapping одинаково.
Например, поле title содержит просто заголовок, а поле tags — массив строк, хотя они представлены в mapping одинаково.
Позднее мы поговорим о маппинге более подобно.
Извлечение документа по его id:
# извлечем документ с id 1 типа post из индекса blog curl -XGET "$ES_URL/blog/post/1?pretty"
{
"_index" : "blog",
"_type" : "post",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"title" : "Веселые котята",
"content" : "<p>Смешная история про котят<p>",
"tags" : [ "котята", "смешная история" ],
"published_at" : "2014-09-12T20:44:42+00:00"
}
}В ответе появились новые ключи: _version и _source. Вообще, все ключи, начинающиеся с _ относятся к служебным.
Ключ _version показывает версию документа. Он нужен для работы механизма оптимистических блокировок. Например, мы хотим изменить документ, имеющий версию 1. Мы отправляем измененный документ и указываем, что это правка документа с версией 1. Если кто-то другой тоже редактировал документ с версией 1 и отправил изменения раньше нас, то ES не примет наши изменения, т.к. он хранит документ с версией 2.
Если кто-то другой тоже редактировал документ с версией 1 и отправил изменения раньше нас, то ES не примет наши изменения, т.к. он хранит документ с версией 2.
Ключ _source содержит тот документ, который мы индексировали. ES не использует это значение для поисковых операций, т.к. для поиска используются индексы. Для экономии места ES хранит сжатый исходный документ. Если нам нужен только id, а не весь исходный документ, то можно отключить хранение исходника.
Если нам не нужна дополнительная информация, можно получить только содержимое _source:
curl -XGET "$ES_URL/blog/post/1/_source?pretty"
{
"title" : "Веселые котята",
"content" : "<p>Смешная история про котят<p>",
"tags" : [ "котята", "смешная история" ],
"published_at" : "2014-09-12T20:44:42+00:00"
}
Также можно выбрать только определенные поля:
# извлечем только поле title curl -XGET "$ES_URL/blog/post/1?_source=title&pretty"
{
"_index" : "blog",
"_type" : "post",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"title" : "Веселые котята"
}
}Давайте проиндексируем еще несколько постов и выполним более сложные запросы.
curl -XPUT "$ES_URL/blog/post/2" -d'
{
"title": "Веселые щенки",
"content": "<p>Смешная история про щенков<p>",
"tags": [
"щенки",
"смешная история"
],
"published_at": "2014-08-12T20:44:42+00:00"
}'curl -XPUT "$ES_URL/blog/post/3" -d'
{
"title": "Как у меня появился котенок",
"content": "<p>Душераздирающая история про бедного котенка с улицы<p>",
"tags": [
"котята"
],
"published_at": "2014-07-21T20:44:42+00:00"
}'Сортировка
# найдем последний пост по дате публикации и извлечем поля title и published_at
curl -XGET "$ES_URL/blog/post/_search?pretty" -d'
{
"size": 1,
"_source": ["title", "published_at"],
"sort": [{"published_at": "desc"}]
}'{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : null,
"hits" : [ {
"_index" : "blog",
"_type" : "post",
"_id" : "1",
"_score" : null,
"_source" : {
"title" : "Веселые котята",
"published_at" : "2014-09-12T20:44:42+00:00"
},
"sort" : [ 1410554682000 ]
} ]
}
}Мы выбрали последний пост.
size ограничивает кол-во документов в выдаче. total показывает общее число документов, подходящих под запрос. sort в выдаче содержит массив целых чисел, по которым производится сортировка. Т.е. дата преобразовалась в целое число. Подробнее о сортировке можно прочитать в документации.
Фильтры и запросы
ES с версии 2 не различает фильты и запросы, вместо этого вводится понятие контекстов.
Контекст запроса отличается от контекста фильтра тем, что запрос генерирует _score и не кэшируется. Что такое _score я покажу позже.
Фильтрация по дате
Используем запрос range в контексте filter:
# получим посты, опубликованные 1ого сентября или позже
curl -XGET "$ES_URL/blog/post/_search?pretty" -d'
{
"filter": {
"range": {
"published_at": { "gte": "2014-09-01" }
}
}
}'Фильтрация по тегам
Используем term query для поиска id документов, содержащих заданное слово:
# найдем все документы, в поле tags которых есть элемент 'котята'
curl -XGET "$ES_URL/blog/post/_search?pretty" -d'
{
"_source": [
"title",
"tags"
],
"filter": {
"term": {
"tags": "котята"
}
}
}'{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 1. 0,
"hits" : [ {
"_index" : "blog",
"_type" : "post",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "Веселые котята",
"tags" : [ "котята", "смешная история" ]
}
}, {
"_index" : "blog",
"_type" : "post",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"title" : "Как у меня появился котенок",
"tags" : [ "котята" ]
}
} ]
}
}
0,
"hits" : [ {
"_index" : "blog",
"_type" : "post",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "Веселые котята",
"tags" : [ "котята", "смешная история" ]
}
}, {
"_index" : "blog",
"_type" : "post",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"title" : "Как у меня появился котенок",
"tags" : [ "котята" ]
}
} ]
}
} 0,
"hits" : [ {
"_index" : "blog",
"_type" : "post",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "Веселые котята",
"tags" : [ "котята", "смешная история" ]
}
}, {
"_index" : "blog",
"_type" : "post",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"title" : "Как у меня появился котенок",
"tags" : [ "котята" ]
}
} ]
}
}
0,
"hits" : [ {
"_index" : "blog",
"_type" : "post",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "Веселые котята",
"tags" : [ "котята", "смешная история" ]
}
}, {
"_index" : "blog",
"_type" : "post",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"title" : "Как у меня появился котенок",
"tags" : [ "котята" ]
}
} ]
}
}Полнотекстовый поиск
Три наших документа содержат в поле content следующее:
<p>Смешная история про котят<p><p>Смешная история про щенков<p><p>Душераздирающая история про бедного котенка с улицы<p>
Используем match query для поиска id документов, содержащих заданное слово:
# source: false означает, что не нужно извлекать _source найденных документов
curl -XGET "$ES_URL/blog/post/_search?pretty" -d'
{
"_source": false,
"query": {
"match": {
"content": "история"
}
}
}'{
"took" : 13,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0. 11506981,
"hits" : [ {
"_index" : "blog",
"_type" : "post",
"_id" : "2",
"_score" : 0.11506981
}, {
"_index" : "blog",
"_type" : "post",
"_id" : "1",
"_score" : 0.11506981
}, {
"_index" : "blog",
"_type" : "post",
"_id" : "3",
"_score" : 0.095891505
} ]
}
} 11506981,
"hits" : [ {
"_index" : "blog",
"_type" : "post",
"_id" : "2",
"_score" : 0.11506981
}, {
"_index" : "blog",
"_type" : "post",
"_id" : "1",
"_score" : 0.11506981
}, {
"_index" : "blog",
"_type" : "post",
"_id" : "3",
"_score" : 0.095891505
} ]
}
}
11506981,
"hits" : [ {
"_index" : "blog",
"_type" : "post",
"_id" : "2",
"_score" : 0.11506981
}, {
"_index" : "blog",
"_type" : "post",
"_id" : "1",
"_score" : 0.11506981
}, {
"_index" : "blog",
"_type" : "post",
"_id" : "3",
"_score" : 0.095891505
} ]
}
}Однако, если искать «истории» в поле контент, то мы ничего не найдем, т.к. в индексе содержатся только оригинальные слова, а не их основы. Для того чтобы сделать качественный поиск, нужно настроить анализатор.
Поле _score показывает релевантность. Если запрос выпоняется в filter context, то значение _score всегда будет равно 1, что означает полное соответствие фильтру.
Анализаторы нужны, чтобы преобразовать исходный текст в набор токенов.
Анализаторы состоят из одного Tokenizer и нескольких необязательных TokenFilters. Tokenizer может предшествовать нескольким CharFilters. Tokenizer разбивают исходную строку на токены, например, по пробелам и символам пунктуации.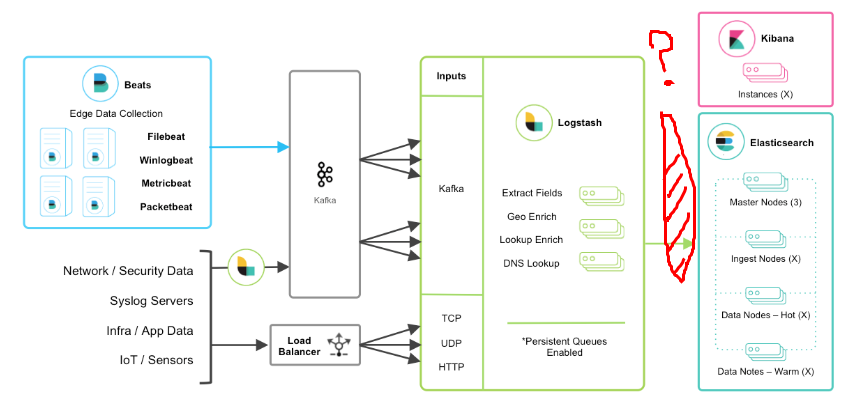 TokenFilter может изменять токены, удалять или добавлять новые, например, оставлять только основу слова, убирать предлоги, добавлять синонимы. CharFilter — изменяет исходную строку целиком, например, вырезает html теги.
TokenFilter может изменять токены, удалять или добавлять новые, например, оставлять только основу слова, убирать предлоги, добавлять синонимы. CharFilter — изменяет исходную строку целиком, например, вырезает html теги.
В ES есть несколько стандартных анализаторов. Например, анализатор russian.
Воспользуемся api и посмотрим, как анализаторы standard и russian преобразуют строку «Веселые истории про котят»:
# используем анализатор standard # обязательно нужно перекодировать не ASCII символы curl -XGET "$ES_URL/_analyze?pretty&analyzer=standard&text=%D0%92%D0%B5%D1%81%D0%B5%D0%BB%D1%8B%D0%B5%20%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D0%B8%20%D0%BF%D1%80%D0%BE%20%D0%BA%D0%BE%D1%82%D1%8F%D1%82"
{
"tokens" : [ {
"token" : "веселые",
"start_offset" : 0,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 0
}, {
"token" : "истории",
"start_offset" : 8,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 1
}, {
"token" : "про",
"start_offset" : 16,
"end_offset" : 19,
"type" : "<ALPHANUM>",
"position" : 2
}, {
"token" : "котят",
"start_offset" : 20,
"end_offset" : 25,
"type" : "<ALPHANUM>",
"position" : 3
} ]
}# используем анализатор russian curl -XGET "$ES_URL/_analyze?pretty&analyzer=russian&text=%D0%92%D0%B5%D1%81%D0%B5%D0%BB%D1%8B%D0%B5%20%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D0%B8%20%D0%BF%D1%80%D0%BE%20%D0%BA%D0%BE%D1%82%D1%8F%D1%82"
{
"tokens" : [ {
"token" : "весел",
"start_offset" : 0,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 0
}, {
"token" : "истор",
"start_offset" : 8,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 1
}, {
"token" : "кот",
"start_offset" : 20,
"end_offset" : 25,
"type" : "<ALPHANUM>",
"position" : 3
} ]
}Стандартный анализатор разбил строку по пробелам и перевел все в нижний регистр, анализатор russian — убрал не значимые слова, перевел в нижний регистр и оставил основу слов.
Посмотрим, какие Tokenizer, TokenFilters, CharFilters использует анализатор russian:
{
"filter": {
"russian_stop": {
"type": "stop",
"stopwords": "_russian_"
},
"russian_keywords": {
"type": "keyword_marker",
"keywords": []
},
"russian_stemmer": {
"type": "stemmer",
"language": "russian"
}
},
"analyzer": {
"russian": {
"tokenizer": "standard",
/* TokenFilters */
"filter": [
"lowercase",
"russian_stop",
"russian_keywords",
"russian_stemmer"
]
/* CharFilters отсутствуют */
}
}
}Опишем свой анализатор на основе russian, который будет вырезать html теги. Назовем его default, т.к. анализатор с таким именем будет использоваться по умолчанию.
{
"filter": {
"ru_stop": {
"type": "stop",
"stopwords": "_russian_"
},
"ru_stemmer": {
"type": "stemmer",
"language": "russian"
}
},
"analyzer": {
"default": {
/* добавляем удаление html тегов */
"char_filter": ["html_strip"],
"tokenizer": "standard",
"filter": [
"lowercase",
"ru_stop",
"ru_stemmer"
]
}
}
}Сначала из исходной строки удалятся все html теги, потом ее разобьет на токены tokenizer standard, полученные токены перейдут в нижний регистр, удалятся незначимые слова и от оставшихся токенов останется основа слова.
Выше мы описали default анализатор. Он будет применяться ко всем строковым полям. Наш пост содержит массив тегов, соответственно, теги тоже будут обработаны анализатором. Т.к. мы ищем посты по точному соответствию тегу, то необходимо отключить анализ для поля tags.
Создадим индекс blog2 с анализатором и маппингом, в котором отключен анализ поля tags:
curl -XPOST "$ES_URL/blog2" -d'
{
"settings": {
"analysis": {
"filter": {
"ru_stop": {
"type": "stop",
"stopwords": "_russian_"
},
"ru_stemmer": {
"type": "stemmer",
"language": "russian"
}
},
"analyzer": {
"default": {
"char_filter": [
"html_strip"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"ru_stop",
"ru_stemmer"
]
}
}
}
},
"mappings": {
"post": {
"properties": {
"content": {
"type": "string"
},
"published_at": {
"type": "date"
},
"tags": {
"type": "string",
"index": "not_analyzed"
},
"title": {
"type": "string"
}
}
}
}
}'Добавим те же 3 поста в этот индекс (blog2). 2″,
2″,
«content»
]
}
}
}’
# получим 2 поста про котиков
- Elasctic.co
- Reference
- Guide
- Глоссарий
- Установка
- Манипуляции с документами
- Операции с индексами
- Список запросов
Если интересны подобные статьи-уроки, есть идеи новых статей или есть предложения о сотрудничестве, то буду рад сообщению в личку или на почту [email protected].
Elasticsearch – поиск для самых больших
Чем крупнее компания, тем большим количеством данных она владеет. Но все эти петабайты ценной для бизнеса и его клиентов информации не должны лежать без дела – они должны работать, постоянно и эффективно.
Требования к современным системам быстрого внутреннего поиска постоянно меняются и растут. Меняется и сама структура данных. Если раньше это были единообразные записи в таблицах БД, то теперь чаще речь идет об «озерах данных», содержащих неструктурированную информацию, объектных хранилищах S3 и т.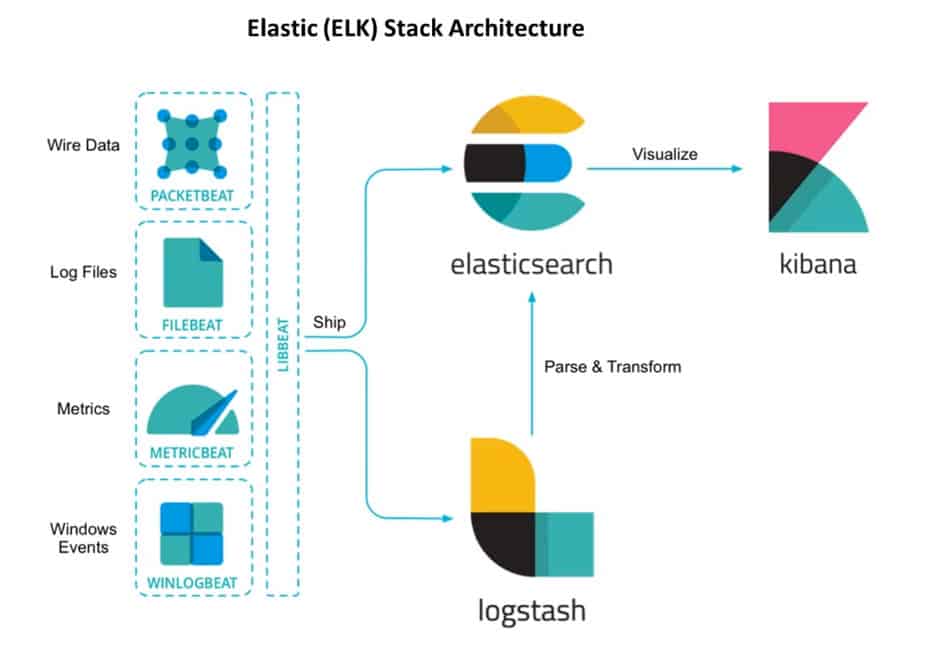 д.
д.
Не так уж много существует поисковых решений, способных хорошо показать себя в подобной среде, особенно если дело касается поиска среди многих и многих петабайт. Одной из самых популярных в области Big Data поисковых систем такого рода является, безусловно, Elasticsearch.
Первая версия поискового движка увидела свет в 2010 году. В 2012 году создатель Elasticsearch Шай Бейнон (Shay Banon) зарегистрировал одноименную компанию, задачей которой стала коммерциализация изначально открытого решения. Позднее она была переименована в Elastic.
В настоящее время возможностями Elasticsearch пользуются множество всемирно известных компаний, среди которых GitHub, Netflix, Uber, Slack, Microsoft и пр. Так, к примеру, для организации поиска по своим бездонным хранилищам Netflix постоянно использует 700-800 узлов Elasticsearch, объединенных в 100 кластеров. Uber обрабатывает по тысяче поисковых запросов в секунду и более, а GitHub индексирует более 8 млн репозиториев, обслуживая более 4 млн пользователей.
Принципы работы Elasticsearch
В основе Elasticsearch лежит написанный на Java поисковый движок, использующий свободную библиотеку скоростного полнотекстового поиска Lucene и поддерживающий JSON REST API. К ключевым достоинствам Elasticsearch, помимо высочайшей производительности и возможности практически безграничного горизонтального масштабирования, можно отнести автоматическую индексацию новых объектов, которые становятся доступными сразу после загрузки в БД в соответствии с концепцией NoSQL.
Кроме того, поисковая система оснащена широким набором настраиваемых фильтров, позволяющим реализовать мультиарендность и использовать нечеткий поиск. Также Elasticsearch снабжен анализаторами, в автоматическом режиме выполняющими токенизацию текста (разбиение на элементарные элементы – слова, знаки препинания и пр.), лемматизацию, стемминг и другие преобразования.
Elasticsearch можно назвать документно-ориентированной базой данных с поддержкой многопоточности. Поиск в реальном времени может осуществляться по документам любого типа при помощи API-интерфейсов библиотеки Lucene и запросов GET.
Поиск в реальном времени может осуществляться по документам любого типа при помощи API-интерфейсов библиотеки Lucene и запросов GET.
В случае необходимости, которая в крупных проектах возникает почти всегда, несколько копий Elasticsearch могут быть объединены в кластер. Группа таких кластеров может хранить реплицированные копии сегментов индекса, за счет чего достигается высокая отказоустойчивость решения.
В достаточно большом хранилище данных число развернутых кластеров Elasticsearch может измеряться сотнями. При этом каждый из узлов кластера умеет делегировать операции поиска правильному сегменту индекса, попутно осуществляя маршрутизацию и перебалансировку данных.
Также по теме
Elastic Stack
Важно отметить, что в своем типичном воплощении Elasticsearch не используется в отрыве от других продуктов Elastic – Logstash, Kibana и FileBeat. Вместе они образуют комплексное решение, получившее общее название Elastic Stack.
Logstash – инструмент сбора, обработки и отправки в хранилище всевозможных событий из разных источников – журналы, пакеты, события, транзакции, временные метки и т.д. Logstash написан на JRuby и работает на JVM, что позволяет запускать его на разных платформах.
В качестве источников данных для этого инструмента могут служить социальные сети, новостные агрегаторы, внутренние данные систем электронной коммерции, CRM, финансовые показатели, телеметрия мобильных устройств, сенсорные сети IoT, HTTP-запросы и ответы на них, журналы Apache или Windows, а также многое другое.
Широкий ассортимент фильтров Logstash помогает извлекать ценные выводы из данных при помощи преобразований и анализа. Построенные на основе регулярных выражений шаблоны фильтров могут быть объединены в последовательности. Также анализ данных облегчает набор плагинов для Logstash, позволяющих преобразовать содержимое журналов в любой удобный формат.
Kibana – веб-инструмент визуализации, позволяющий привести поток событий от Logstash в человекочитаемый вид для анализа. При этом Kibana не взаимодействует с Logstash напрямую, а использует в качестве источника данных уже обработанные индексы Elasticsearch. С помощью Kibana можно создавать разнообразные динамические панели мониторинга, таблицы, графики и диаграммы, демонстрирующие обстановку во входящих источниках событий в реальном времени.
FileBeat – легковесный серверный агент, с помощью которого можно организовать отправку логов серверов в Logstash. Этот элемент стека не является обязательным, однако зачастую оказывается весьма полезен в инфраструктурах определенных типов.
Особенности лицензирования
Все элементы Elastic Stack доступны для изучения и использования в виде исходных кодов в репозитории GitHub. До недавнего времени они распространялись по лицензии Apache 2.0, однако в январе 2021 года Elastic объявила о переходе на лицензию SSPL (Server Side Public License), накладывающую некоторые ограничения на коммерческое использование.
Теперь эксплуатанты Elastic Stack могут продолжать пользоваться им безвозмездно только в том случае, если все остальные компоненты, вовлеченные в работу сервиса, также будут публиковаться в виде открытого исходного кода.
Изменения коснулись главным образом облачных провайдеров, которые физически не в состоянии выполнить требования SSPL и будут вынуждены перейти на коммерческую лицензию.
В то же время, основное коммерческое предложение Elastic состоит вовсе не в этом. Различные варианты лицензий, такие как Gold, Platinum и Enterprise, включают в себя многочисленные дополнительные инструменты, направленные на расширение функциональности Elastic Stack.
· Gold включает в себя механизмы авторизации через Active Directory/LDAP, дополнительные инструменты внутреннего аудита, расширенные возможности службы оповещений и, разумеется, техническую поддержку в рабочие часы.
· Platinum в дополнение к вышеперечисленному предлагает встроенные инструменты машинного обучения, поддержку ODBC/JDBC, настройки гранулярного доступа вплоть до отдельных документов, кросс-кластерную репликацию и ряд других возможностей, включая круглосуточную техподдержку. На сегодняшний день это самый востребованный тип лицензий на Elastic Stack.
На сегодняшний день это самый востребованный тип лицензий на Elastic Stack.
· Enterprise, помимо возможностей Platinum, включает в себя решение Elastic Cloud Enterprise, оркестратор Elastic Cloud on Kubernetes, инструмент киберзащиты конечных устройств Endgame, а также поддержку неограниченного количества проектов на базе Elastic.
Поделиться:
Что такое Elasticsearch? | Elastic
Коротко говоря, мы помогаем всем быстрее найти то, что им нужно, — от сотрудников, которым нужны документы из вашей внутренней сети, до клиентов, ищущих в Интернете идеальную пару обуви. Но более техническая версия звучит примерно так:
Elasticsearch — это распределенная, бесплатная и открытая поисковая и аналитическая система для всех типов данных, включая текстовые, числовые, геопространственные, структурированные и неструктурированные. Elasticsearch построен на базе Apache Lucene и впервые был выпущен в 2010 году компанией Elasticsearch N.V. (теперь известной как Elastic). Elasticsearch, известный своими простыми REST API, распределенным характером, скоростью и масштабируемостью, является центральным компонентом Elastic Stack, набора бесплатных и открытых инструментов для приема, обогащения, хранения, анализа и визуализации данных. Обычно называемый ELK Stack (в честь Elasticsearch, Logstash и Kibana), Elastic Stack теперь включает в себя богатую коллекцию легковесных агентов доставки, известных как Beats, для отправки данных в Elasticsearch.
Elasticsearch, известный своими простыми REST API, распределенным характером, скоростью и масштабируемостью, является центральным компонентом Elastic Stack, набора бесплатных и открытых инструментов для приема, обогащения, хранения, анализа и визуализации данных. Обычно называемый ELK Stack (в честь Elasticsearch, Logstash и Kibana), Elastic Stack теперь включает в себя богатую коллекцию легковесных агентов доставки, известных как Beats, для отправки данных в Elasticsearch.
Посмотреть веб-семинар
Начало работы с Elasticsearch: Храните, ищите и анализируйте с помощью бесплатного и открытого Elastic Stack.
Посмотреть видео
Знакомство с ELK. Начните работу с журналами, метриками, приемом данных и настраиваемой визуализацией в Kibana.
Смотреть видео
Начало работы с Elastic Cloud: запустите свое первое развертывание.
Подробнее
Для чего используется Elasticsearch?
Скорость и масштабируемость Elasticsearch, а также его способность индексировать множество типов контента означают, что его можно использовать в ряде случаев:
- Application search
- Website search
- Enterprise search
- Logging and log analytics
- Infrastructure metrics and container monitoring
- Application performance monitoring
- Geospatial data analysis and visualization
- Security analytics
- Business analytics
Как работает эластичный поиск?
Необработанные данные поступают в Elasticsearch из различных источников, включая журналы, системные показатели и веб-приложения. Прием данных — это процесс, в ходе которого эти необработанные данные анализируются, нормализуются и обогащаются, прежде чем они будут проиндексированы в Elasticsearch. После индексации в Elasticsearch пользователи могут выполнять сложные запросы к своим данным и использовать агрегации для получения сложных сводок своих данных. С помощью Kibana пользователи могут создавать мощные визуализации своих данных, делиться информационными панелями и управлять Elastic Stack.
Прием данных — это процесс, в ходе которого эти необработанные данные анализируются, нормализуются и обогащаются, прежде чем они будут проиндексированы в Elasticsearch. После индексации в Elasticsearch пользователи могут выполнять сложные запросы к своим данным и использовать агрегации для получения сложных сводок своих данных. С помощью Kibana пользователи могут создавать мощные визуализации своих данных, делиться информационными панелями и управлять Elastic Stack.
Что такое индекс Elasticsearch?
Эластичный поиск индекс представляет собой набор документов, которые связаны друг с другом. Elasticsearch хранит данные в виде документов JSON. Каждый документ сопоставляет набор из ключей (имен полей или свойств) с соответствующими им значениями (строками, числами, логическими значениями, датами, массивами значений , геолокациями или другими типами данных).
Elasticsearch использует структуру данных, называемую инвертированным индексом , которая предназначена для очень быстрого полнотекстового поиска. Инвертированный индекс перечисляет каждое уникальное слово, встречающееся в любом документе, и идентифицирует все документы, в которых встречается каждое слово.
Инвертированный индекс перечисляет каждое уникальное слово, встречающееся в любом документе, и идентифицирует все документы, в которых встречается каждое слово.
В процессе индексирования Elasticsearch сохраняет документы и создает инвертированный индекс, чтобы сделать данные документа доступными для поиска почти в реальном времени. Индексирование инициируется с помощью API индекса, с помощью которого вы можете добавить или обновить документ JSON в определенном индексе.
Для чего используется Logstash?
Logstash, один из основных продуктов Elastic Stack, используется для сбора и обработки данных и отправки их в Elasticsearch. Logstash — это серверный конвейер обработки данных с открытым исходным кодом, который позволяет одновременно получать данные из нескольких источников, а также обогащать и преобразовывать их до того, как они будут проиндексированы в Elasticsearch.
Для чего используется Kibana?
Kibana — это инструмент визуализации и управления данными для Elasticsearch, который предоставляет гистограммы, линейные графики, круговые диаграммы и карты в реальном времени. Kibana также включает расширенные приложения, такие как Canvas, который позволяет пользователям создавать собственную динамическую инфографику на основе своих данных, и Elastic Maps для визуализации геопространственных данных.
Kibana также включает расширенные приложения, такие как Canvas, который позволяет пользователям создавать собственную динамическую инфографику на основе своих данных, и Elastic Maps для визуализации геопространственных данных.
Зачем использовать Elasticsearch?
Elasticsearch работает быстро. Поскольку Elasticsearch построен на базе Lucene, он отлично справляется с полнотекстовым поиском. Elasticsearch также является поисковой платформой почти в реальном времени, что означает, что задержка с момента индексации документа до момента, когда он становится доступным для поиска, очень короткая — обычно одна секунда. В результате Elasticsearch хорошо подходит для срочных случаев использования, таких как аналитика безопасности и мониторинг инфраструктуры.
Elasticsearch распространяется по своей природе. Документы, хранящиеся в Elasticsearch, распределяются по разным контейнерам, известным как сегменты , которые дублируются для обеспечения избыточных копий данных в случае сбоя оборудования. Распределенный характер Elasticsearch позволяет масштабировать его до сотен (или даже тысяч) серверов и обрабатывать петабайты данных.
Распределенный характер Elasticsearch позволяет масштабировать его до сотен (или даже тысяч) серверов и обрабатывать петабайты данных.
Elasticsearch обладает широким набором функций. В дополнение к скорости, масштабируемости и отказоустойчивости Elasticsearch обладает рядом мощных встроенных функций, которые делают хранение и поиск данных еще более эффективными, например, сводные копии данных и управление жизненным циклом индексов.
Эластичный стек упрощает прием данных, визуализацию и создание отчетов. Интеграция с Beats и Logstash упрощает обработку данных перед индексацией в Elasticsearch. А Kibana обеспечивает визуализацию данных Elasticsearch в режиме реального времени, а также пользовательские интерфейсы для быстрого доступа к мониторингу производительности приложений (APM), журналам и данным показателей инфраструктуры.
Часто задаваемые вопросы по Elasticsearch
Является ли Elasticsearch бесплатным?
Да, бесплатные и открытые функции Elasticsearch можно использовать бесплатно по лицензии SSPL или Elastic License. Дополнительные бесплатные функции доступны по лицензии Elastic, а платные подписки предоставляют доступ к поддержке, а также к расширенным функциям, таким как оповещения и машинное обучение.
Дополнительные бесплатные функции доступны по лицензии Elastic, а платные подписки предоставляют доступ к поддержке, а также к расширенным функциям, таким как оповещения и машинное обучение.
Какой официальный дистрибутив Elasticsearch?
Официальный дистрибутив Elasticsearch доступен на сайте Elastic.
Кто может внести свой вклад в проект Elasticsearch ?
Elasticsearch — это бесплатный и открытый проект, управляемый Elastic. База кода включает в себя вклад разработчиков как внутри, так и за пределами Elastic.
Любой может отправить запрос на включение в репозиторий Elasticsearch GitHub. Elastic проводит прозрачную проверку всех запросов на вытягивание перед их слиянием с кодовой базой.
Какие есть варианты развертывания Elasticsearch?
Elasticsearch можно развернуть как размещенную управляемую службу через службу Elasticsearch Service (доступную в Amazon Web Services (AWS), Google Cloud и Alibaba Cloud), или вы можете загрузить и установить ее на собственное оборудование или в облако. Документация Elasticsearch содержит инструкции по загрузке, установке и настройке Elasticsearch.
Документация Elasticsearch содержит инструкции по загрузке, установке и настройке Elasticsearch.
Для пользователей, которые хотят развертывать, управлять и отслеживать свои развертывания с единой консоли, но предпочитают не использовать общедоступную облачную платформу, Elastic также предлагает Elastic Cloud Enterprise (которое можно развернуть в общедоступных или частных облаках, виртуальных машинах или «голое железо»), а также частный уровень подписки.
Какие языки программирования поддерживает Elasticsearch?
Elasticsearch поддерживает множество языков, а официальные клиенты доступны для:
- Java
- JavaScript (Node.js)
- Go
- .NET (C#)
- PHP
- Perl
- Python
- Ruby
What text languages does Elasticsearch support?
Elasticsearch поддерживает 34 текстовых языка, от арабского до тайского, и предоставляет анализаторы для каждого из них. Полный список можно найти в документации Elasticsearch Language Analyzer. Поддержка дополнительных языков может быть добавлена с помощью пользовательских плагинов.
Полный список можно найти в документации Elasticsearch Language Analyzer. Поддержка дополнительных языков может быть добавлена с помощью пользовательских плагинов.
Предоставляет ли Elasticsearch API REST?
Да, Elasticsearch предоставляет исчерпывающий и мощный набор REST API для выполнения таких задач, как проверка работоспособности кластера, выполнение CRUD (создание, чтение, обновление и удаление) и операций поиска по индексам, а также выполнение расширенных операций поиска, таких как фильтрация и агрегаты.
Где я могу найти дополнительную информацию об Elasticsearch?
- Репозиторий Elasticsearch GitHub
- Служба Elasticsearch
- Документация Elasticsearch
- Цены на Elasticsearch
Экономьте массу времени с помощью полей среды выполнения
Попробуйте поля среды выполнения с бесплатной пробной версией Elastic Cloud.
Зарегистрироваться
Погрузитесь в документацию по полям среды выполнения.
Читать документы
Узнайте больше о полях среды выполнения.
Чтение блога
Схема при записи, схема соответствия при чтении
Получите максимальную эластичность от ваших данных
С помощью полей среды выполнения вы можете сразу же начать прием данных. Вот как это все работает.
Получите быстрый доступ к своим данным
Когда вы принимаете новые данные, вы можете еще не знать, как они будут искаться. И это нормально. С полями времени выполнения вы можете пропустить предварительное определение полей, чтобы сэкономить время и создавать поля на лету. Кроме того, вы всегда можете применить любое из ваших полей времени выполнения к следующему индексу в качестве проиндексированных полей для более быстрого поиска.
Помогите вашим данным идти в ногу со временем
Как только ваш кластер тихонько гудит в фоновом режиме, сообщение журнала изменяется и прерывает сопоставление индекса. С полями времени выполнения вам не нужно начинать все сначала. Вы можете сохранить поля, которые все еще применяются, при динамическом создании новых полей для изменений в ваших данных.
С полями времени выполнения вам не нужно начинать все сначала. Вы можете сохранить поля, которые все еще применяются, при динамическом создании новых полей для изменений в ваших данных.
Новый слой краски для полей
С помощью полей среды выполнения вы также можете определить новые способы анализа данных, которые уже были проиндексированы. Создайте новое поле среды выполнения, используя любую комбинацию существующих полей, которые будут использоваться в запросе или визуализации. Эти изменения могут применяться только к вам, позволяя вам исследовать данные, не влияя на работу других.
Сократите время простоя и избегайте простоев
Мы все совершали ошибки. Перед полями времени выполнения вам пришлось бы исправлять сопоставление индексов и _reindex данных, что продлевало простои. Теперь вы можете затенить неправильное поле полем времени выполнения, чтобы немедленно исправить ошибку без _reindex. Это позволяет вам быть более гибкими и сокращает время контроля качества, что может снизить затраты.
Загляните под капот
Поля времени выполнения позволяют вам быть гибкими, чтобы вы могли быстро реагировать на изменения в данных, которые вы индексируете. Не стесняйтесь следить за использованием Kibana Dev Tools, чтобы увидеть, как легко динамически создать поле среды выполнения. Мы добавили комментарий, объясняющий детали для каждого шага.
Шаблон данных
ПРИНЯТИЯ ДОКУМЕНТЫ
Запрос Runtime
QUERIN
#timestamp и response_code, который будет создан
#когда мы получаем данные.
