Содержание
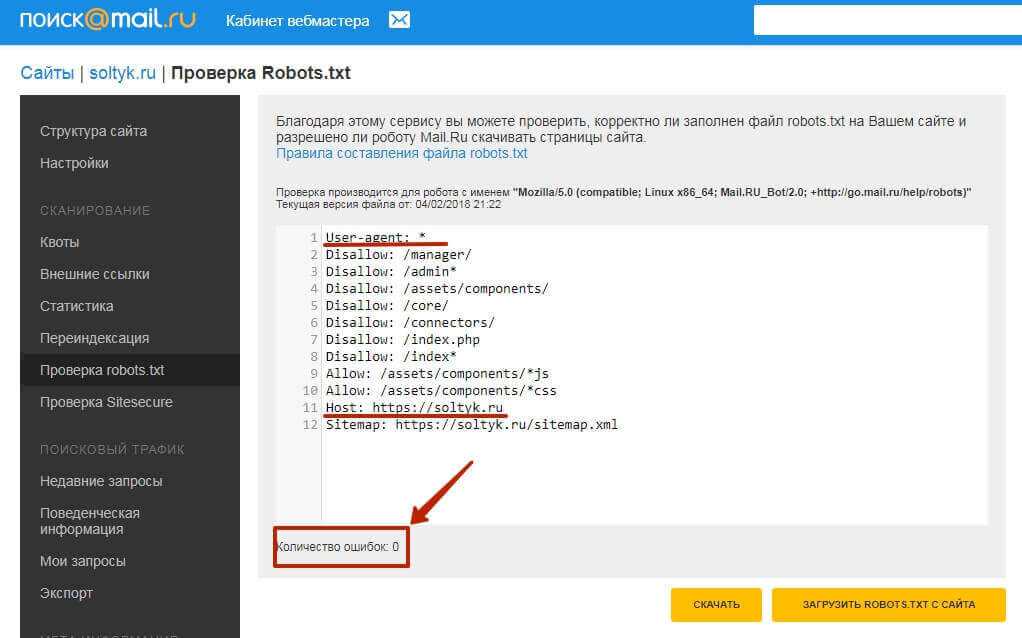
Директивы Disallow и Allow — Вебмастер. Справка
- Disallow
- Allow
- Совместное использование директив
- Директивы Allow и Disallow без параметров
- Использование спецсимволов * и $
- Обработка символа #
- Примеры интерпретации директив
Используйте эту директиву, чтобы запретить обход разделов сайта или отдельных страниц. Например:
страницы с конфиденциальными данными;
страницы с результатами поиска по сайту;
статистика посещаемости сайта;
дубликаты страниц;
разнообразные логи;
сервисные страницы баз данных.
Примечание. При выборе директивы для страниц, которые не должны участвовать в поиске, если их адреса содержат GET-параметры, лучше использовать директиву Clean-param, а не Disallow. При использовании Disallow может не получиться выявить дублирование адреса ссылки без параметра и передать некоторые показатели запрещенных страниц.
Примеры:
User-agent: Yandex Disallow: / # запрещает обход всего сайта User-agent: Yandex Disallow: /catalogue # запрещает обход страниц, адрес которых начинается с /catalogue User-agent: Yandex Disallow: /page? # запрещает обход страниц, URL которых содержит параметры
Директива разрешает обход разделов или отдельных страниц сайта.
Примеры:
User-agent: Yandex Allow: /cgi-bin Disallow: / # запрещает скачивать все, кроме страниц # начинающихся с '/cgi-bin'
User-agent: Yandex Allow: /file.xml # разрешает скачивание файла file.xml
Примечание. Недопустимо наличие пустых переводов строки между директивами User-agent, Disallow и Allow.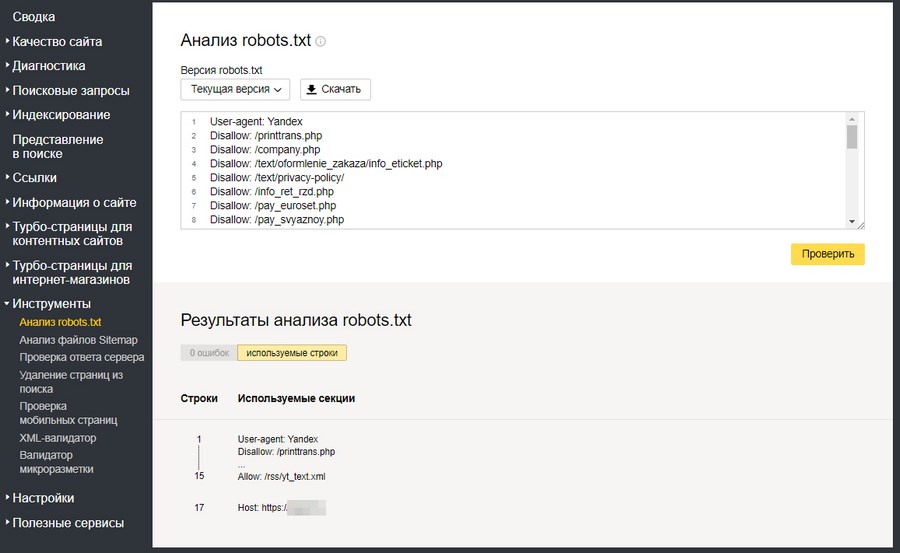
Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом.
Примечание. При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow.
# Исходный robots.txt: User-agent: Yandex Allow: / Allow: /catalog/auto Disallow: /catalog # Сортированный robots.txt: User-agent: Yandex Allow: / Disallow: /catalog Allow: /catalog/auto # запрещает скачивать страницы, начинающиеся с '/catalog', # но разрешает скачивать страницы, начинающиеся с '/catalog/auto'.

Общий пример:
User-agent: Yandex
Allow: /archive
Disallow: /
# разрешает все, что содержит '/archive', остальное запрещено
User-agent: Yandex
Allow: /obsolete/private/*.html$ # разрешает html файлы
# по пути '/obsolete/private/...'
Disallow: /*.php$ # запрещает все '*.php' на данном сайте
Disallow: /*/private/ # запрещает все подпути содержащие
# '/private/', но Allow выше отменяет
# часть запрета
Disallow: /*/old/*.zip$ # запрещает все '*.zip' файлы, содержащие
# в пути '/old/'
User-agent: Yandex
Disallow: /add.php?*user=
# запрещает все скрипты 'add.php?' с параметром 'user'Если директивы не содержат параметры, робот учитывает данные следующим образом:
User-agent: Yandex Disallow: # то же, что и Allow: / User-agent: Yandex Allow: # не учитывается роботом
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, чтобы задавать определенные регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов. Примеры:
User-agent: Yandex
Disallow: /cgi-bin/*.aspx # запрещает '/cgi-bin/example.aspx'
# и '/cgi-bin/private/test.aspx'
Disallow: /*private # запрещает не только '/private',
# но и '/cgi-bin/private'По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *. Пример:
User-agent: Yandex
Disallow: /cgi-bin* # блокирует доступ к страницам
# начинающимся с '/cgi-bin'
Disallow: /cgi-bin # то же самоеЧтобы отменить * на конце правила, можно использовать спецсимвол $, например:
User-agent: Yandex
Disallow: /example$ # запрещает '/example',
# но не запрещает '/example.html'User-agent: Yandex
Disallow: /example # запрещает и '/example',
# и '/example. html' html'
html'Спецсимвол $ не запрещает указанный * на конце, то есть:
User-agent: Yandex
Disallow: /example$ # запрещает только '/example'
Disallow: /example*$ # так же, как 'Disallow: /example'
# запрещает и /example.html и /exampleВ соответствии со стандартом перед каждой директивой User-agent рекомендуется вставлять пустой перевод строки. Символ # предназначен для описания комментариев. Все, что находится после этого символа и до первого перевода строки не учитывается.
Страницы с адресами вида https://example.com/page#part_1 не индексируются поисковым роботом и будут обходиться по адресу https://example.com/page. Поэтому в директиве достаточно указать адрес страницы без якоря.
Если не учесть этой особенности и написать запрещающую директиву с символом #, она может закрыть от индексирования весь сайт. Например, директиву вида Disallow: /# поисковая система воспримет как Disallow: / — полный запрет на индексирование.
User-agent: Yandex Allow: / Disallow: / # все разрешается User-agent: Yandex Allow: /$ Disallow: / # запрещено все, кроме главной страницы User-agent: Yandex Disallow: /private*html # запрещается и '/private*html', # и '/private/test.html', и '/private/html/test.aspx' и т. п. User-agent: Yandex Disallow: /private$ # запрещается только '/private' User-agent: * Disallow: / User-agent: Yandex Allow: / # так как робот Яндекса # выделяет записи по наличию в строке 'User-agent:', # результат — все разрешается
что означает и как правильно использовать
В данной статье речь пойдет о самых популярных директивах Dissalow и Allow в файле robots.txt.
Disallow
Allow
Совместная интерпретация директив
Пустые Allow и Disallow
Специальные символы в директивах
Примеры совместного применения Allow и Disallow
Disallow
Disallow – директива, запрещающая индексирование отдельных страниц, групп страниц, их отдельных файлов и разделов сайта(папок). Это наиболее часто используемая директива, которая исключает из индекса:
Это наиболее часто используемая директива, которая исключает из индекса:
- страницы с результатами поиска на сайте;
- страницы посещаемости ресурса;
- дубли;
- сервисные страницы баз данных;
- различные логи;
- страницы, содержащие персональные данные
пользователей.
Примеры директивы Disallow в robots.txt:
# запрет на индексацию всего веб-ресурса User-agent: Yandex Disallow: /
# запрет на обход страниц, адрес которых начинается с /category User-agent: Yandex Disallow: /category
# запрет на обход страниц, URL которых содержит параметры User-agent: Yandex Disallow: /page?
# запрет на индексацию всего раздела wp-admin User-agent: Yandex Disallow: /wp-admin
# запрет на индексацию подраздела plugins User-agent: Yandex Disallow: /wp-content/plugins
# запрет на индексацию конкретного изображения в папке img User-agent: Yandex Disallow: /img/images.
 jpg
jpg# запрет индексации конкретного PDF документа User-agent: Yandex Disallow: /dogovor.pdf
# запрет на индексацию не только /my, но и /folder/my или /folder/my User-agent: Yandex Disallow: /*my
Правило Disallow работает с масками, позволяющими проводить операции с группами файлов или папок.
После данной директивы необходимо ставить пробел, а в конце строки пробел недопустим. В одной строке с Disallow через пробел можно написать комментарий после символа “#”.
Allow
В отличие от Disallow, данное указание разрешает индексацию определенных страниц, разделов или файлов сайта. У директивы Allow схожий синтаксис, что и у Disallow.
Хотя окончательное решение о посещении вашего сайта роботами принимает поисковая система, данное правило дополнительно призывает их это делать.
Примеры Allow в robots.txt:
# разрешает индексацию всего каталога /img/ User-agent: Yandex Allow: /img/
# разрешает индексацию PDF документа User-agent: Yandex Allow: /prezentaciya.
 pdf
pdf# открывает доступ к индексированию определенной HTML страницы User-agent: Yandex Allow: /page.html
# разрешает индексацию по маске *your User-agent: Yandex Allow: /*your
# запрещает индексировать все, кроме страниц, начинающихся с /cgi-bin User-agent: Yandex Allow: /cgi-bin Disallow: /
Для директивы применяются аналогичные правила, что и для Disallow.
Совместная
интерпретация директив
Поисковые системы используют Allow и Disallow из одного User-agent блока последовательно, сортируя их по длине префикса URL, начиная от меньшего к большему. Если для конкретной страницы веб-сайта подходит применение нескольких правил, поисковый бот выбирает последний из списка. Поэтому порядок написания директив в robots никак не сказывается на их использовании роботами.
На заметку. Если директивы имеют одинаковую длину префиксов и при этом конфликтуют между собой, то предпочтительнее будет Allow.
Пример robots.txt написанный оптимизатором:
User-agent: Yandex Allow: / Allow: /catalog/phones Disallow: /catalog
Пример отсортированного файл robots. txt поисковой системой:
txt поисковой системой:
User-agent: Yandex Allow: / Disallow: /catalog Allow: /catalog/phones # запрещает посещать страницы, начинающиеся с /catalog, # но разрешает индексировать страницы, начинающиеся с /catalog/phones
Пустые Allow и Disallow
Когда в директивах отсутствуют какие-либо параметры,
поисковый бот интерпретирует их так:
# то же, что и Allow: / значит разрешает индексировать весь сайт User-agent: Yandex Disallow:
# не учитывается роботом User-agent: Yandex Allow:
Специальные символы в директивах
В параметрах запрещающей директивы Disallow и
разрешающей директивы Allow можно применять специальные символы “$” и “*”, чтобы задать
конкретные регулярные выражения.
Специальный символ “*” разрешает индексировать все страницы с параметром, указанным в директиве. К примеру, параметр /katalog* значит, что для ботов открыты страницы /katalog, /katalog-tovarov, /katalog-1 и прочие. Спецсимвол означает все возможные последовательности символов, даже пустые.
Примеры:
User-agent: Yandex
Disallow: /cgi-bin/*.aspx # запрещает /cgi-bin/example.aspx
# и /cgi-bin/private/test.aspx
Disallow: /*private # запрещает не только /private
# но и /cgi-bin/privateПо стандарту в конце любой инструкции, описанной в Robots, указывается специальный символ “*”, но делать это не обязательно.
Пример:
User-agent: Yandex
Disallow: /cgi-bin* # закрывает доступ к страницам
# начинающимся с /cgi-bin
Disallow: /cgi-bin # означает то же самоеДля отмены данного спецсимвола в конце директивы применяют
другой спецсимвол – “$”.
Пример:
User-agent: Yandex
Disallow: /example$ # закрывает /example,
# но не запрещает /example.html
User-agent: Yandex
Disallow: /example # запрещает и /example
# и /example.htmlНа заметку. Символ “$” не запрещает прописанный в конце “*”.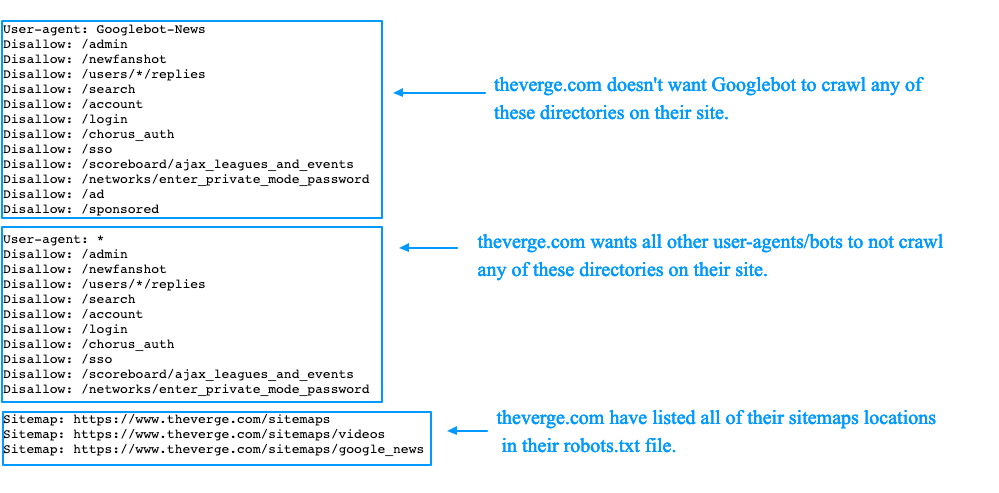
Пример:
User-agent: Yandex
Disallow: /example$ # закрывает только /example
Disallow: /example*$ # аналогично, как Disallow: /example
# запрещает и /example.html и /exampleБолее сложные примеры:
User-agent: Yandex
Allow: /obsolete/private/*.html$ # разрешает HTML файлы
# по пути /obsolete/private/...
Disallow: /*.php$ # запрещает все *.php на сайте
Disallow: /*/private/ # запрещает все подпути содержащие /private/
# но Allow выше отменяет часть запрета
Disallow: /*/old/*.zip$ # запрещает все .zip файлы, содержащие в пути /old/
User-agent: Yandex
Disallow: /add.php?*user=
# запрещает все скрипты add.php? с параметром userПримеры совместного применения Allow и Disallow
User-agent: Yandex Allow: / Disallow: / # разрешено индексировать весь веб-ресурс User-agent: Yandex Allow: /$ Disallow: / # запрещено включать в индекс все, кроме главной страницы User-agent: Yandex Disallow: /private*html # заблокирован и /private*html, # и /private/test.
 html, и /private/html/test.aspx и т.п.
User-agent: Yandex
Disallow: /private$
# запрещается только /private
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
# так как робот Яндекса
# выделяет записи по наличию его названия в строке User-agent:
# тогда весь сайт будет доступен для индексирования
html, и /private/html/test.aspx и т.п.
User-agent: Yandex
Disallow: /private$
# запрещается только /private
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
# так как робот Яндекса
# выделяет записи по наличию его названия в строке User-agent:
# тогда весь сайт будет доступен для индексированияЯ всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
robots.txt, чтобы запретить все страницы, кроме одной? Они переопределяют и каскадируют?
спросил
Изменено
5 лет, 7 месяцев назад
Просмотрено
49 тысяч раз
Я хочу, чтобы сканировалась одна страница моего сайта и никакие другие.
Кроме того, если это отличается от ответа выше, я также хотел бы знать синтаксис для запрета всего, кроме корня (индекса) веб-сайта.
# robots.txt для http://example.com/ Пользовательский агент: * Запретить: /style-guide Запретить: /всплеск Запретить: /etc Запретить: /etc Запретить: /etc Запретить: /etc Запретить: /etc
Или можно так?
# robots.txt для http://example.com/ Пользовательский агент: * Запретить: / Разрешить: /в стадии строительства
Также я должен упомянуть, что это установка WordPress, поэтому, например, «в разработке» установлено на первой странице. Так что в этом случае он действует как индекс.
Я думаю, что мне нужно, чтобы http://example.com ползали, но не другие страницы.
# robots.txt для http://example.com/ Пользовательский агент: * Запретить: /*
Означает ли это, что запрещать что-либо после корня?
- robots.txt
Самый простой способ разрешить доступ только к одной странице:
User-agent: * Разрешить: /в стадии строительства Запретить: /
В исходной спецификации robots.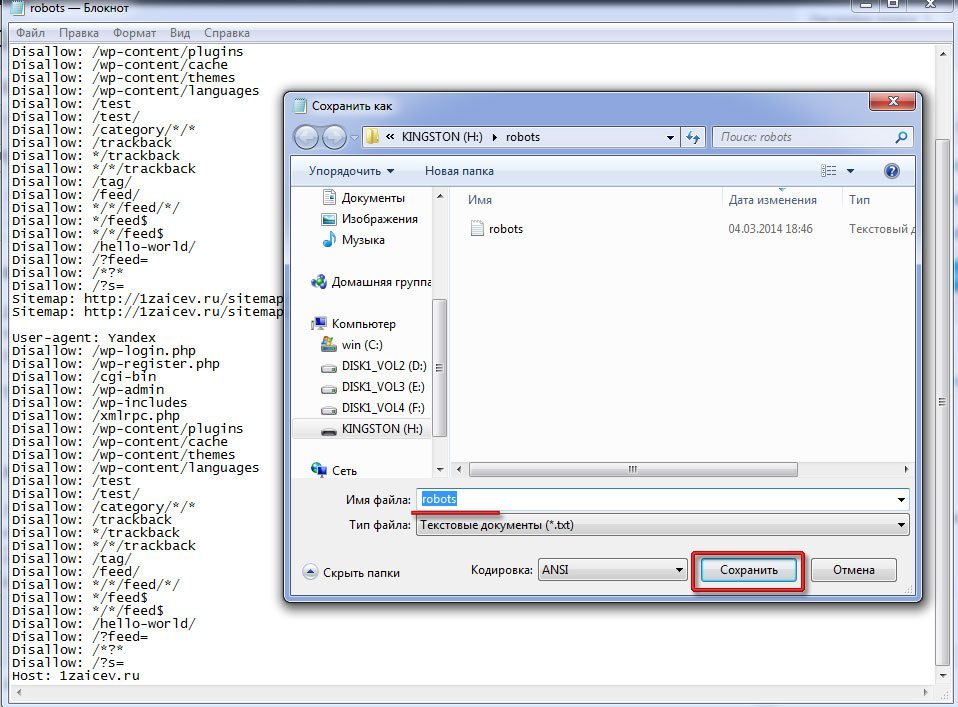 txt сказано, что поисковые роботы должны читать robots.txt сверху вниз и использовать первое правило соответствия. Если поставить
txt сказано, что поисковые роботы должны читать robots.txt сверху вниз и использовать первое правило соответствия. Если поставить Сначала запретите , тогда многие боты увидят, что они не могут ничего сканировать. Поставив сначала Разрешить , те, кто применит правила сверху вниз, увидят, что они могут получить доступ к этой странице.
Правила выражения просты: выражение Disallow: / говорит «запретить все, что начинается с косой черты ». Так что значит все на сайте.
Ваш Disallow: /* означает одно и то же для роботов Googlebot и Bingbot, но боты, не поддерживающие подстановочные знаки, могут видеть /* и думаю, что вы имели в виду буквальное * . Таким образом, они могли предположить, что сканирование /*foo/bar.html — это нормально.
Если вы просто хотите просканировать http://example.com , но ничего больше, вы можете попробовать:
Разрешить: /$ Запретить: /
$ означает «конец строки», как и в регулярных выражениях. Опять же, это будет работать для Google и Bing, но не будет работать для других сканеров, если они не поддерживают подстановочные знаки.
Опять же, это будет работать для Google и Bing, но не будет работать для других сканеров, если они не поддерживают подстановочные знаки.
4
Если вы войдете в Инструменты Google для веб-мастеров, на левой панели перейдите к сканированию, затем перейдите к Просмотреть как Google. Здесь вы можете проверить, как Google будет сканировать каждую страницу.
В случае блокировки всего, кроме главной страницы:
User-agent: * Разрешить: /$ Запретить: /
подойдет.
1
вы можете использовать это ниже, оба будут работать
User-agent: * Разрешить: /$ Запретить: /
или
User-agent: * Разрешить: /index.php Запретить: /
Разрешить должно быть перед Запретить, потому что файл читается сверху вниз
Запретить: / говорит «запретить все, что начинается с косой черты». Так что значит все на сайте.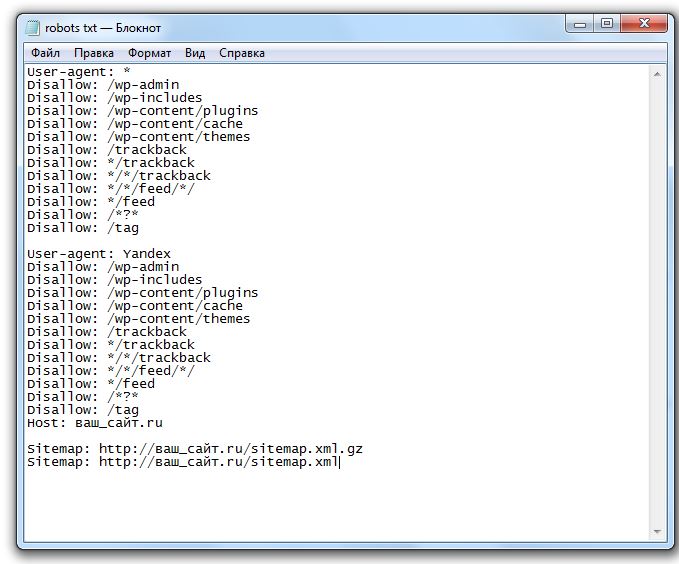
Символ $ означает «конец строки», как и в регулярных выражениях. поэтому результатом Allow : /$ является ваша домашняя страница /index
http://en.wikipedia.org/wiki/Robots.txt#Allow_directive
Порядок важен только для роботов, которые следуют стандарту; в случае ботов Google или Bing порядок не важен.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Как запретить страницы поиска из robots.
 txt
txt
спросил
Изменено
10 лет, 6 месяцев назад
Просмотрено
23 тысячи раз
Мне нужно запретить индексацию http://example.com/startup?page=2 поисковых страниц.
Я хочу, чтобы http://example.com/startup индексировался, но не http://example.com/startup?page=2 и page3 и так далее.
Кроме того, запуск может быть случайным, например, http://example.com/XXXXX?page
- robots.txt
Что-то вроде этого работает, как подтверждает функция Google Webmaster Tools «test robots.txt»:
Агент пользователя: * Запретить: /startup?page=
Запретить Значение этого поля
указывает частичный URL-адрес, который не
быть посещенным. Это может быть полный путь,
или частичный путь; любой URL, который начинается
с этим значением не будет получено.

Однако, , если первая часть URL-адреса изменится на , необходимо использовать подстановочные знаки:
User-Agent: * Запретить: /startup?page= Запретить: *страница= Запретить: *?page=
0
Вы можете поместить это на страницы, которые вы не хотите индексировать:
Это говорит роботам не индексировать страницу.
На странице поиска может быть интереснее использовать:
Указывает роботам не индексировать текущую страницу, но по-прежнему переходить по ссылкам на этой странице, что позволяет им попадать на страницы, найденные в поиске.
- Создайте текстовый файл и назовите его: robots.txt
- Добавить пользовательские агенты и запретить разделы (см. пример ниже)
- Поместите файл в корень вашего сайта
Образец:
################################
#Мой файл robots.
