Содержание
Канонический адрес страницы — Вебмастер. Справка
Если на сайте есть страница, доступная по нескольким адресам, а также страницы с одинаковым или схожим содержимым, робот Яндекса может посчитать их дублями. Тогда он объединит страницы в группу дублей и выберет для показа в результатах поиска только одну из них — наиболее информативную и релевантную поисковым запросам. Такая страница называется канонической.
Вы можете указать роботу страницу, предпочитаемую для показа в результатах поиска, с помощью атрибута rel=»canonical». Также вы можете указать канонический адрес, если хотите изменить адрес сайта — с префиксом www или без него, протоколом HTTP или HTTPS.
Внимание. Робот Яндекса воспринимает указание на канонический адрес как рекомендацию и может проигнорировать его в нескольких случаях.
- Как указать канонический адрес страницы
- Как изменить адрес сайта с помощью канонического адреса
- Случаи, когда канонический адрес не учитывается
- Вопросы и ответы
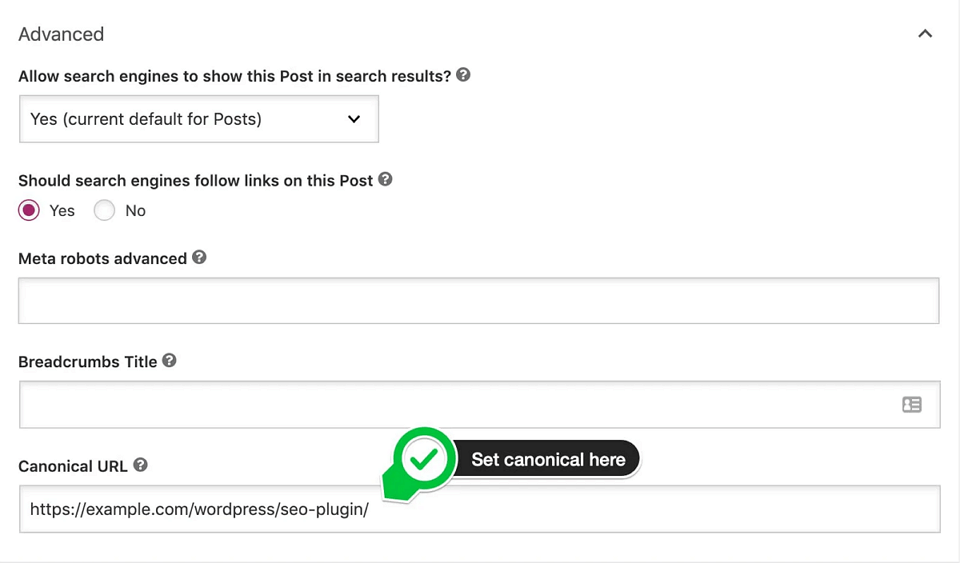
Добавьте канонический адрес страницы с помощью атрибута rel=»canonical» одним из способов:
Например, страница доступна по двум адресам: www. example.com/pages?id==2 и www.example.com/blog.
example.com/pages?id==2 и www.example.com/blog.
Если предпочитаемый адрес — /blog, добавьте в HTML-код страницы /pages?id=2 элемент link:
<link rel="canonical" href="http://www.example.com/blog"/>
Например, на сайте есть PDF-файл, доступный по нескольким адресам: www.example.com/offer/file.pdf и www.example.com/files/file.pdf. Если предподчитаемый адрес — /offer/file.pdf, настройте сервер так, чтобы он передавал в HTTP-заголовке страницы /files/file.pdf следующее:
Link: <http://www.example.com/offer/file.pdf>; rel="canonical"
Примечание. Указывайте канонический адрес в пределах одного домена. В качестве канонического адреса задавайте абсолютный путь, например http://example.com/blog/.
Страница, на которой размещен атрибут rel=»canonical» с адресом другой страницы, считается неканонической.
Робот узнает об изменениях при обходе сайта. Если канонический адрес указан верно и робот не проигнорировал указание, неканоническая страница пропадет из результатов поиска. Убедиться в том, что страница удалена из поиска, можно в Вебмастере на странице Индексирование → Страницы в поиске (блок Исключённые страницы).
Убедиться в том, что страница удалена из поиска, можно в Вебмастере на странице Индексирование → Страницы в поиске (блок Исключённые страницы).
Робот игнорирует указания, если содержимое канонической страницы значительно отличается от содержимого неканонической. В этом случае в поиске может участвовать неканоническая страница. Чтобы проверить это, перейдите на страницу Индексирование → Страницы в поиске.
Чтобы исключить из поиска неканоническую страницу, адрес которой содержит GET-параметры или метки (UTM, from и т. д.), добавьте директиву Clean-param в файл robots.txt. В другом случае используйте директиву Disallow.
Вы можете указать канонический адрес, если хотите изменить адрес сайта:
на домен с префиксом www или без него;
с протоколом HTTPS или HTTP.
Робот воспримет канонический адрес как редирект на новое главное зеркало и объединит две версии сайта в одну группу. Для этого в HTML-код или в HTTP-заголовок каждой страницы старого сайта добавьте ссылку на аналогичную страницу нового с атрибутом rel=»canonical». Например, вы меняете адрес http://example.com на https://example.com. На странице http://example.com/main/ нужно указать:
Например, вы меняете адрес http://example.com на https://example.com. На странице http://example.com/main/ нужно указать:
<link rel="canonical" href="https://example.com/main"/>
Если атрибут будет указывать на другую страницу, робот может посчитать это различием в структуре сайтов. В таком случае переезд будет невозможен.
При смене адреса убедитесь, что контент старого и нового сайтов совпадает. Подробнее см. инструкцию по переезду.
Примечание. Если атрибут добавлен только на отдельные страницы, он не будет указывать на главное зеркало.
Робот Яндекса не учтет канонический адрес, если:
На момент обхода неканонические страницы более полно отвечают на запрос пользователя, и их контент существенно отличается от канонических. Если вы уверены, что такие страницы не будут полезны пользователям в поиске, запретите индексирование в файле robots.txt.
Канонический адрес недоступен для робота — перенаправляет на другую страницу или закрыт от индексирования.
 Это значит, что он не сможет участвовать в поиске. Тогда вместо канонического адреса может участвовать неканонический, если он доступен для робота.
Это значит, что он не сможет участвовать в поиске. Тогда вместо канонического адреса может участвовать неканонический, если он доступен для робота.В качестве канонического адреса указан URL в другом домене или поддомене.
Указано несколько канонических адресов.
Указана цепочка канонических адресов. Например, для адреса example.com/1 каноническим адресом является example.com/2, в то время как для адреса example.com/2 указан канонический адрес example.com/3.
 Это значит, что он не сможет участвовать в поиске. Тогда вместо канонического адреса может участвовать неканонический, если он доступен для робота.
Это значит, что он не сможет участвовать в поиске. Тогда вместо канонического адреса может участвовать неканонический, если он доступен для робота.Атрибут rel=»canonical» указывает на страницу, на которой размещен. Это ошибка?
Нет. Если на странице атрибут rel=»canonical» указывает на эту же страницу, робот посчитает ее канонической.
Как вернуть неканоническую страницу в поиск
Если страница была исключена из поиска как неканоническая, значит, в ее HTML-коде или HTTP-заголовке робот нашел атрибут rel=»canonical» с указанием на канонический адрес. Удалите это указание и проверьте, что индексирование страницы, которую вы хотите вернуть в поиск, не запрещено.
Удалите это указание и проверьте, что индексирование страницы, которую вы хотите вернуть в поиск, не запрещено.
Если у вас остались вопросы об использовании атрибута rel=»canonical», укажите в форме ниже примеры страниц, с которыми возникли проблемы.
как повысить рейтинг одинакового контента
Причин возникновения дублей контента может быть много: особенности CMS сайта, страницы с динамическими параметрами URL, сайт доступен по https://www.site.com/ и по https://site.com/, https://site.com/ и так далее. Если не указать поисковику приоритетную — каноническую страницу с дублирующимся контентом, робот выберет ее на свое усмотрение и последствия могут быть неприятными, особенно для владельцев сайтов.
В этом выпуске «Азбуки SEO» поговорим о понятии каноничности страниц и атрибуте rel=»canonical».
Что такое атрибут rel=»canonical»?
Атрибут rel=»canonical» указывает роботам поисковых систем, какую страницу необходимо считать приоритетной.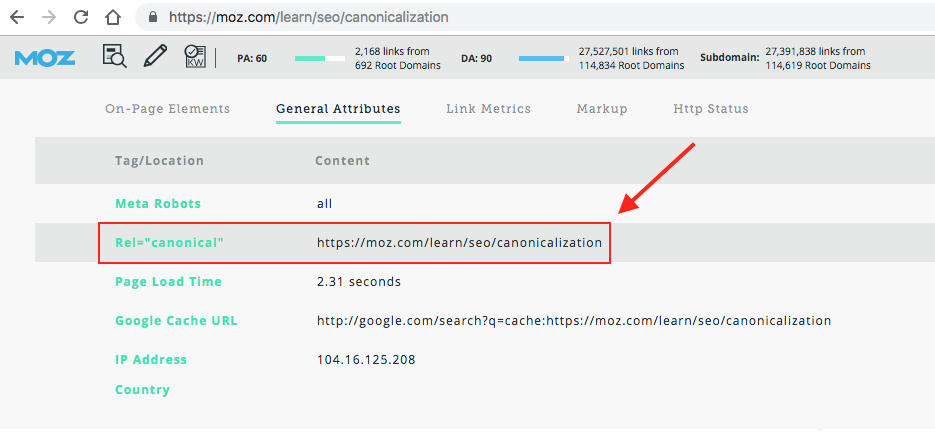 Он присваивается тегу link и располагается в <head></head> страницы. Страница, указанная в атрибуте rel=»canonical», начинает восприниматься поисковыми роботами как приоритетная (каноническая).
Он присваивается тегу link и располагается в <head></head> страницы. Страница, указанная в атрибуте rel=»canonical», начинает восприниматься поисковыми роботами как приоритетная (каноническая).
Например: <link rel=»canonical» href=»https://[url]» />, где [url] — адрес канонической страницы.
Допустим, для страницы «https://site.com/?get=12345» канонической является «https://site.com/». В таком случае на странице «https://site.com/?get=12345» тег будет таким: <link rel=»canonical» href=»https://site.com/» />.
Google поддерживает этот атрибут с 2009, Яндекс — с 2011 года.
Зачем указывать canonical?
- Устранить полные или частичные дубли контента на сайте.
- Защитить контент от дублирования на ресурсах, которые частично или полностью могут кешировать сайт (например, веб-архивы).
В каких случаях нужно определять каноничность?
Страницы пагинации
Для страниц пагинации есть два решения вопроса с каноническими страницами.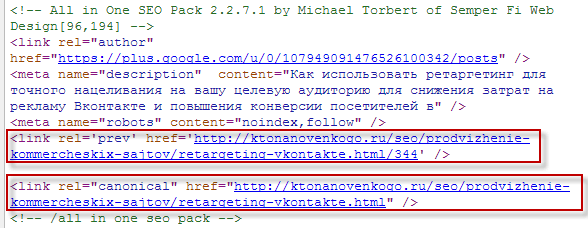 Выбор варианта зависит от того, есть ли в каждой категории сайта страница «Показать все», например, «https://site.com/category-1/show-all», на которой доступны все товары из категории.
Выбор варианта зависит от того, есть ли в каждой категории сайта страница «Показать все», например, «https://site.com/category-1/show-all», на которой доступны все товары из категории.
Если такая страница есть, Google рекомендует на каждой из страниц пагинации указать канонической страницу «Показать все».
Например, «https://site.com/category-1/page-2» должна содержать каноническую ссылку: <link rel=»canonical» href=»https://site.com/category-1/show-all» />.
Если страницы «Показать все» нет и мы имеем дело с классической пагинацией, следует в качестве канонических указывать эти же страницы.
Например, страница «https://site.com/category-1/page-2» должна содержать каноническую ссылку: <link rel=»canonical» href=»https://site.com/category-1/page-2″ />.
О том, как мы используем rel=»canonical» для оптимизации страниц интернет-магазина, читайте здесь.
Страницы с UTM-метками
Необходимо настроить сервер так, чтобы при нахождении UTM-параметров в адресе страницы, отдавался код «200 ОК» и страница содержала абсолютную каноническую ссылку на URL этой страницы без UTM-метки.
Речь о следующих UTM-параметрах:
- gclid;
- utm_medium;
- utm_source;
- utm_campaign;
- utm_content;
- utm_term;
- _openstat.
Так, страница «https://site.com/?utm_source=testk&utm_medium=test&utm_campaign=test» должна содержать каноническую ссылку: <link rel=»canonical» href=»https://site.com/» />.
Читайте, как правильно создавать и проставлять UTM-метки.
Страницы фильтрации
На страницах фильтрации следует в качестве канонических указывать сами страницы фильтрации.
Например, для страницы «https://site.com/category-1/filter-1/» нужна ссылка: <link rel=»canonical» href=»https://site.com/category-1/filter-1/» />.
Дублирование контента на разных доменах
Иногда при переходе на новое доменное имя используется сервер, который не поддерживает переадресацию на своей стороне. В таком случае можно использовать междоменный атрибут rel=»canonical» в элементе link.
Просто нужно указать канонические ссылки со всех доменов, на которых есть дублирующийся контент, на основной — предпочтительный для индексирования.
Важно: на данный момент междоменный каноникал понимает только Google.
О чем следует помнить при простановке rel=»canonical»?
- Ссылки в атрибуте следует ставить абсолютные — с https:// или https://. Так сокращается риск появления ошибок.
- Если на странице с дублирующимся контентом указываете на другую страницу как каноническую, не забудьте в <head></head> той страницы также прописать ее как каноническую.
- Если на странице указаны несколько канонических адресов, поисковый робот проигнорирует их и определит каноническую страницу самостоятельно.
- Если канонической указана страница, отдающая код ответа 404, поисковый робот не сможет использовать данную рекомендацию.
- Чтобы избежать ошибок, не стоит использовать цепочки канонических страниц.
- Поисковые роботы воспринимают атрибут rel=»canonical» не как строгую директиву, а как рекомендацию, то есть указанный URL может быть проигнорирован.
- При самостоятельном определении канонических страниц поисковая система Google отдает предпочтение страницам на https.

Выводы
В нашей практике бывали случаи, когда контент с сайта копировали полностью, вместе с внутренней текстовой перелинковкой и каноническими адресами. Поэтому атрибут rel=»canonical» стоит указывать на всех страницах.
Особенно важно определять каноничность для:
- страниц пагинации;
- страниц с UTM-метками;
- страниц фильтрации.
Это помогает бороться с дублированием контента и обезопасить сайт от копирования.
Узнайте больше о продвинутых способах использования rel=»canonical».
сборка — канонический адрес x86-64?
спросил
Изменено
3 года, 1 месяц назад
Просмотрено
9к раз
Часть коллектива Intel
При чтении справочной книги Intel я наткнулся на следующее:
На процессорах, поддерживающих архитектуру Intel 64, поле
IA32_SYSENTER_ESPи полеIA32_SYSENTER_EIPдолжны содержать канонический адрес.

Что такое «канонический адрес»?
- сборка
- x86-64
- Intel
- адрес памяти
- виртуальное адресное пространство
3
Я предлагаю вам загрузить полное руководство разработчика программного обеспечения. Документация доступна в отдельных томах, но эта ссылка дает вам все семь томов в одном большом PDF-файле, что упрощает поиск вещей.
Ответ находится в разделе 3.3.7.1. В первой строке этого раздела указано
.
В 64-битном режиме адрес считается в канонической форме, если биты адреса с 63 до старшего бита, реализованного микроархитектурой, установлены либо на все единицы, либо на все нули.
Далее…
Вы можете использовать cpuid для запроса поддерживаемой ширины виртуального адреса на этом ЦП. (т. е. «реализован микроархитектурой».) Или вы обычно можете просто предположить 48-битную.
Т.е. канонический виртуальный адрес состоит из 48 бит, правильно расширенных по знаку до 64. Если старшие биты не совпадают, он неканонический и приведет к ошибке, если вы попытаетесь разыменовать его.
(Или с грядущим 5-уровневым расширением таблицы страниц Intel, 57-битное расширение со знаком до 64).
0
Этот ответ менее подробный, чем предыдущие, но ИМХО более понятный:
Хотя 64-битные процессоры имеют 64-битные регистры, системы обычно
не реализовывать все 64-битные для адресации (16 экзабайтов
теоретическая физическая память).Таким образом, большинство архитектур определяют нереализованную область адреса
пространство, которое процессор сочтет недействительным для использования. x86-64 (…)
определить самый старший допустимый бит адреса, который затем должен
быть дополненным знаком (…) для создания действительного адреса. Результат этого
заключается в том, что общее адресное пространство эффективно разделено на две части,
верхняя и нижняя части, с промежуточными адресами
инвалид.
адреса неканонические).
 (…) Действительные адреса называются каноническими адресами (недействительными
(…) Действительные адреса называются каноническими адресами (недействительнымиИз https://www.bottomupcs.com/virtual_memory_is.xhtml
Расширенный знак — это тот же старший бит, скопированный в адрес старших битов. Верхний 11111... нижний 00000... .
1
Раздел 3.3.7.1 Руководства Intel содержит 5 (трудно усваиваемых) абзацев, для меня это 74-я страница в 4-х томах, которые можно загрузить с сайта Intel или перейти прямо сюда: https://software.intel. ком/сайты/по умолчанию/файлы/управляемые/39/c5/325462-sdm-vol-1-2abcd-3abcd.pdf
В этих абзацах говорится, что канонические адреса — это что-то меньшее, чем полный 64-битный адрес. Существуют различные реализации адресации, такие как 48-битная или 57-битная. (57-разрядная версия требует дополнительного уровня таблиц страниц, что увеличивает стоимость обхода страниц. См. https://en.wikipedia.org/wiki/Intel_5-level_paging для получения дополнительной информации об этой новой функции ЦП, которую можно оставить отключенной).
См. https://en.wikipedia.org/wiki/Intel_5-level_paging для получения дополнительной информации об этой новой функции ЦП, которую можно оставить отключенной).
48-битная реализация будет иметь старший половинный канонический адрес, начинающийся с
0xFFFF800000000000
, в то время как нижняя половина будет
0x00007FFFFFFFFFFFF
Бит 63 на то, что будет обозначать его как канонический адрес, если вы видите все единицы или все нули. В 57-битной реализации я бы сразу понял, что смотрю на канонический адрес, когда увижу 0xFF____ или 0x00____. (Младший бит старшего байта является значащим адресным битом, а остальные 7 являются его копиями: т. е. правильно расширенный знак)
Может быть, полезным способом запомнить это является то, что само слово «канонический» означает отношение к общему правилу или способ сделать что-л. В общем, никому не нужно столько адресов, сколько могут дать 64 бита, поэтому они, как правило, не используются. Кроме того, если что-то соответствует канону, как в «Звездном пути» или комиксах, это то, как все было увидено или сделано изначально.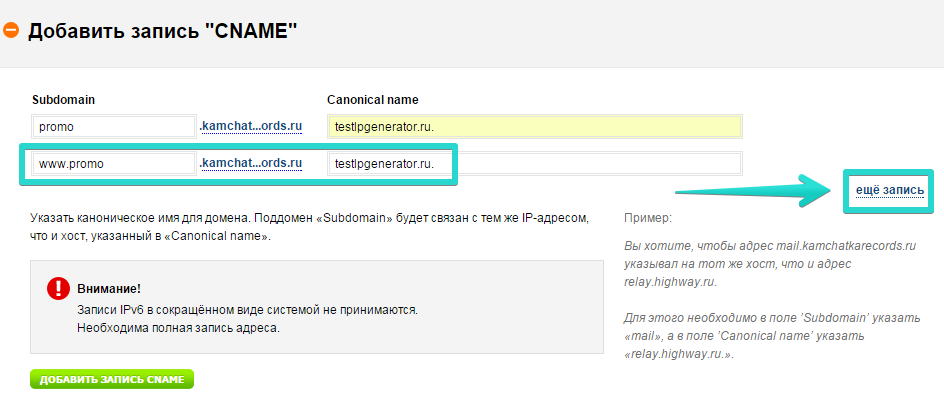
Теперь ответ ПОЧЕМУ у нас канонические адреса? Никому не нужно будет адресовать до 16 эксабайт (теоретический предел 64-битной машины), поэтому во втором абзаце этого руководства просто говорится, что архитектура Intel «определяет» 64-битный линейный адрес, но похоже, что никто не будет его использовать. Теперь, на всякий случай, в третьем абзаце говорится, что реализация по-прежнему будет проверять эти первые несколько битов и, если НЕ в канонической форме, генерировать исключение «общей защиты».
Основная причина проверки для канонических адресов вместо молчаливого игнорирования старших битов, чтобы убедиться, что программное обеспечение совместимо с будущим оборудованием, которое поддерживает больше битов виртуального адреса.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
linux — получение данных памяти с неканоническим адресом вызывает SIGSEGV, а не SIGBUS
спросил
Изменено
2 года, 4 месяца назад
Просмотрено
235 раз
Часть коллектива Intel
Не могу выдать «Ошибку шины» со следующим ассемблерным кодом.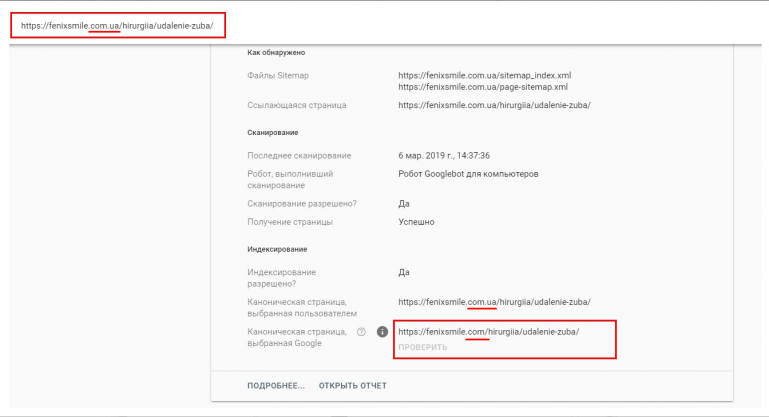 Здесь адрес памяти, который я использую, не является законным «каноническим адресом». Итак, как я могу вызвать эту ошибку?
Здесь адрес памяти, который я использую, не является законным «каноническим адресом». Итак, как я могу вызвать эту ошибку?
Я запускал этот фрагмент кода в Ubuntu 20.04 LTS с NASM 2.14.02, но это приводит к ошибке сегментации SIGSEGV при загрузке, а не SIGBUS.
глобальный _start
раздел .текст
_Начало:
мов ракс, [qword 0x11223344557788]
мов ракс, 60
xor рди, рди
системный вызов
Соответствующий код сборки X86-64 после компиляции:
Разборка раздела .text: 0000000000401000 <_start>: 401000: 48 a1 88 77 55 44 33 movabs 0x11223344557788,%rax 401007: 22 11 00 40100a: b8 3c 00 00 00 mov $0x3c,%eax 40100f: 48 31 и далее xor%rdi,%rdi 401012: системный вызов 0f 05
- linux
- сборка
- x86-64
- nasm
- ошибка шины
8
Если вы просмотрите руководство по архитектуре набора инструкций для инструкции MOV, вы обнаружите, что доступ к неканоническому адресу приводит к ошибке общей защиты #GP(0) :
Linux сопоставляет все исключения #GP с Сигнал SIGSEGV (ошибка сегментации). Однако в Linux есть способ, которым неканонический адрес может вызвать ошибку 9.0060 Bus Error , и это достигается за счет того, что процессор вызывает исключение
Однако в Linux есть способ, которым неканонический адрес может вызвать ошибку 9.0060 Bus Error , и это достигается за счет того, что процессор вызывает исключение # SS (сегмент стека). Linux сопоставляет исключения #SS с сигналом SIGBUS. Установка указателя стека на неканонический адрес и последующее выполнение операции, связанной со стеком, вызовет такое исключение.
Этот код должен привести к ошибке Bus :
global _start
раздел .текст
_Начало:
мов рсп, 0x8000000000000000 ; Установите RSP на неканонический адрес
толкать ракс ; Помещение значения в стек должно привести к ошибке BUS ERROR
Еще один способ вызвать ошибку шины в Linux — вызвать исключение #AC (проверка выравнивания). Если вы пишете код кольца 3 (пользовательский), который включает бит проверки выравнивания (бит 18) в RFLAGS и выполняете невыровненный доступ к памяти, вы также должны получить сигнал SIGBUS. Этот код должен привести к ошибке Bus :
global _start
раздел .