Содержание
Операторы Wordstat — как работать с ними эффективно
Сегодня мы в Rush Analytics до конца реализовали поддержку всех операторов Wordstat.
Зачастую Вордстат может сильно облегчить задачу сбора семантики, особенно на начальном этапе, поэтому грамотное использование операторов на старте обязательно.
Навигация по статье
- Какие операторы поддерживает Вордстат?
- Переходим к практике
- Кейс №2
- Кейс №3
- Кейс №4
Какие операторы поддерживает Вордстат?
Давайте для начала рассмотрим все поддерживаемые операторы:
• “кавычки” – число показов только данного запроса, но по всем возможным окончаниям и порядку слов в запросе.
• ! восклицательный знак – данный оператор фиксирует окончание слова.
• + оператор «Плюс» — оператор будет полезен для поиска запросов с предлогами и союзами.
• — оператор «Минус» — думаю многим знакомый оператор, поможет вам избавиться от стоп слов и получить только нужные запросы.
• | оператор «Или» — так же еще один полезный оператор, который позволит вам получить запросы сразу по нескольким условиям. Например – купить машину (недорого|ваз)
• () оператор «Группировка» — в совокупности с оператором «Или» позволит делать вам полезные регулярки и извлекать запросы по комбинированным условиям.
Это была теоретическая часть, чтобы освежить знания. Теперь давайте разберем конкретные кейсы с данными операторами и их комбинациями.
Переходим к практике
Начнем от простого к сложному и постараемся рассмотреть типичные ситуации, с которыми многие сталкиваются при сборе ключевых слов из Wordstat.
Кейс №1
Бывают такие тематики, в которых основная частотная семантика начинается от 3-4 слов и выше. Одной из них являются микрозаймы. Как вытащить из вордстата только четырехсловные запросы? А очень просто – тут нам поможет оператор кавычек
Как вытащить из вордстата только четырехсловные запросы? А очень просто – тут нам поможет оператор кавычек
Почему так происходит? Все очень просто. Указывая оператор «Кавычки» вы говорите Вордстату – покажи мне ограниченный по длине диапазон слов, которые включают в себя слова, указанные в кавычках. Так как мы указали 4 раза слово «микрозайм» – то мы получаем всех четырехсловные запросы, с содержанием данного слова.
Если у вас основной запрос тематики двухсловный, например «натяжные потолки», то вам нужно будет указать “натяжные потолки потолки” или «натяжные натяжные потолки» – и получить все 3-х словные запросы по вашей тематике.
Читайте также: Сбор подсказок Яндекса
Кейс №2
Второй практический пример – нам надо получить маркерные запросы для категории «Стиральные машины Samsung», по которым мы в дальнейшем будем собирать облако запросов и делать теговые страницы. Так как искать данную категорию могут по разным написаниям запросов – стиральная машина, стиральная машинка, Samsung, Самсунг – нам нужно сделать соответствующую регулярку в Вордстате и в 1 клик получить все запросы для данной категории:
стиральные (машины|машинки) (samsung|самсунг) -ремонт -ошибки -отзыв -коды -видео -запчасти –неисправности
Также были добавлены базовые стоп слова, чтобы не получать мусорные запросы.
Присоединяйтесь к
Rush-Analytics уже сегодня
7-ми дневный бесплатный доступ к полному функционалу. Без привязки карты.
Попробовать бесплатно
Кейс №3
Очень часто бывают такие тематики, которые содержат очень много смешанных интентов, на чистку которых в дальнейшем уходит очень много времени. Один из таких примеров – продажа компьютеров. Если мы вобьем «купить компьютер» в Вордстат – то соберем кучу ненужного, например: «купить монитор для компьютера», «купить клавиатуру для компьютера» и т.д.
Чтобы собрать только нужные нам маркеры нам нужно просто зафиксировать словоформу и подать запрос в Вордстат «купить !компьютер» и получить уже запросы без лишних интентов.
Читайте также: Как быстро выгрузить поисковые запросы из Яндекс Метрики
Кейс №4
Допустим, перед нами стоит задача быстро собрать теги для категории «Смартфоны» и у нас нет времени чистить огромное облако запросов данной категории от мусора.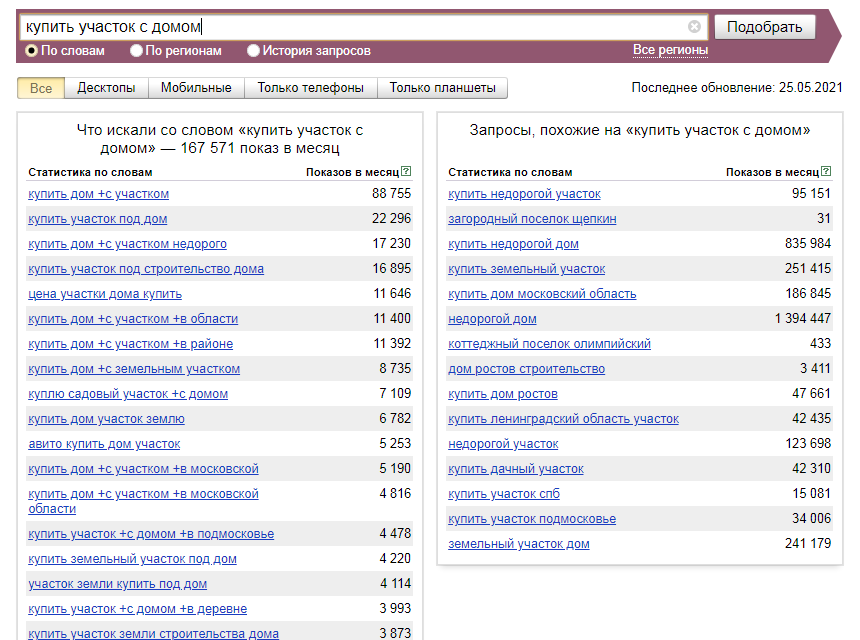 Чаще всего тегами являются 2 типа интентов – характеристика объекта (белый смартфон, мощный смартфон) и по назначению объекта (смартфон для пожилых, смартфон для девушки). С помощью Вордстата мы можем легко собрать теги 2-го типа – по назначению, так как все такие запросы содержат предлоги. Исходя из этого мы делаем следующую регулярку:
Чаще всего тегами являются 2 типа интентов – характеристика объекта (белый смартфон, мощный смартфон) и по назначению объекта (смартфон для пожилых, смартфон для девушки). С помощью Вордстата мы можем легко собрать теги 2-го типа – по назначению, так как все такие запросы содержат предлоги. Исходя из этого мы делаем следующую регулярку:
смартфоны (+до|+с|+на) -скачать -игры -интернет -мтс -фото
Так же указываем базовые стоп слова, чтобы не собирать мусор.
Сразу видны будущие теги – смартфоны на андроиде, с мощным аккумулятором, с хорошей камерой и т.д. Естественно у каждого могут быть индивидуальные проблемы и текущие кейсы не подойдут для решения вашей задачи, но включив логику, вы всегда можете видоизменить наши примеры под ваши нужды.
С помощью Rush Analytics можно настроить работу с запросами для интернет-магазина, а МойСклад поможет автоматизировать ведение складского учета для предприятий малого и среднего бизнеса. Все приведенные выше примеры работают в нашем парсере Wordstat – можете сами в этом убедиться. 🙂
🙂
Как работать с Яндекс Вордстат
Полезный инструмент для всех, кто занимается продвижением, — Яндекс Вордстат — поможет не только повысить интерес пользователей к вашему продукту, но и правильно распределить бюджет на рекламу. С его помощью вы можете анализировать статистику по конкретным ключевым словам и фразам либо подбирать новые. Функционал Вордстата позволяет уточнять, какие запросы в какое время года популярнее, и оценивать перспективы запуска рекламы в конкретном регионе. И всё это бесплатно.
В этой статье разберёмся, какие возможности предлагает Wordstat, что такое операторы и как ими пользоваться и как можно сделать подбор ключей эффективнее.
Оглавление
- Что такое Wordstat от Яндекса
- Интерфейс и функционал сервиса Вордстат
- Операторы Wordstat: как правильно пользоваться
- Пример: как подбирать ключевые слова в Яндекс Wordstat для блога
- Полезные расширения для Вордстата
Что такое Wordstat от Яндекса
Wordstat — это бесплатный сервис от Яндекса, в котором можно подбирать ключевые слова для поисковых запросов и собирать по ним статистику. С его помощью легко выяснить, какой товар или услуга вызывает больший интерес у пользователей, и собрать семантическое ядро для SEO-продвижения.
С его помощью легко выяснить, какой товар или услуга вызывает больший интерес у пользователей, и собрать семантическое ядро для SEO-продвижения.
Ключ, ключевое слово, ключевая фраза — это те самые слова, которые пользователи вводят в поисковую строку для поиска, чтобы найти нужный сайт.
Семантическое ядро — это набор ключей, которые могут привести на сайт потенциального клиента.
Вордстат — необходимый инструмент для продвижения бизнеса. С его помощью можно решить разнообразные задачи:
- проанализировать пользовательский интерес к определённому товару или услуге;
- спрогнозировать трафик на нужный сайт;
- прописать анкор-лист для ссылок;
- собрать ключевые слова для контекстной рекламы;
- оценить географическую популярность запросов.
Читайте также:
Гид по контекстной рекламе: как она выглядит и как помогает бизнесу
Рузана Анчек
12 мин.
Интерфейс и функционал сервиса Вордстат
Подбор слов в Wordstat — не единственная функция сервиса. С помощью этого инструмента вы можете не только оценить популярность тех или иных фраз, но и применить её в конкретных регионах с учётом сезонности. Покажем на примерах, как пользоваться Вордстатом.
Статистика запросов
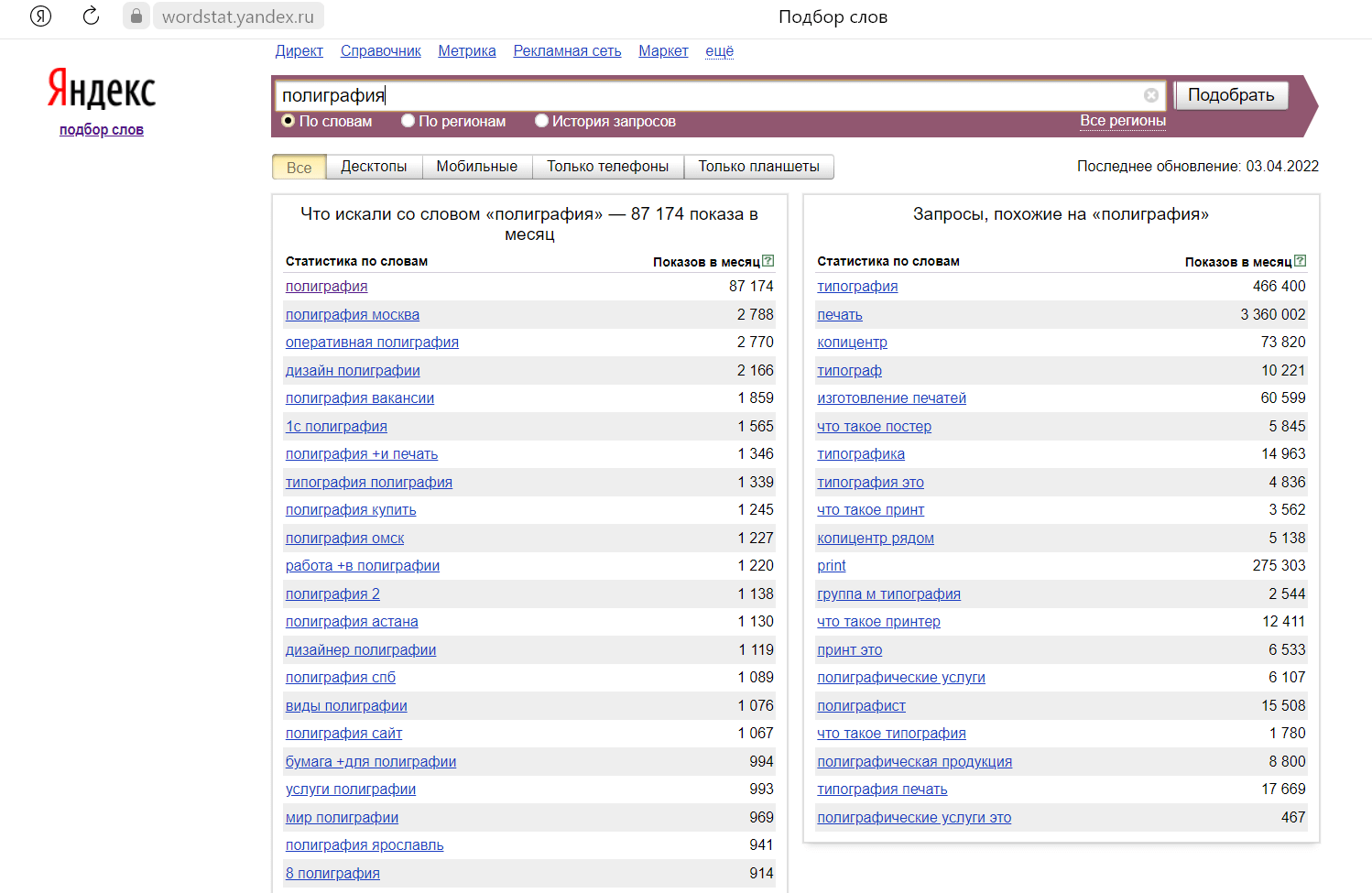
Для начала вам придётся зарегистрироваться в сервисах Яндекс и зайти на страницу wordstat.yandex.ru. Указав в поисковой строке ключевое слово или фразу, мы можем увидеть частотность запросов.
Подбор слов в Вордстат
В левой колонке вы видите запросы, включающие вашу фразу и слово, а также другие варианты ключа, которые пользователи искали вместе с вашим. В правой колонке Вордстат предлагает похожие по смыслу фразы, которыми также интересовались люди.
Цифры рядом с каждой фразой означают суммарное количество показов в месяц. По сути, это прогноз, как часто пользователи будут искать это словосочетание в месяц.
Тип устройства
По умолчанию сервис показывает статистику запросов со всех устройств, но предлагает возможность посмотреть данные и по отдельным видам. Например, проверить, как часто люди ищут вашу фразу с мобильных телефонов или только с десктопов.
Например, проверить, как часто люди ищут вашу фразу с мобильных телефонов или только с десктопов.
Частота запросов на разных видах устройств в Яндекс Вордстате
Региональная популярность
Вкладка «по регионам» показывает популярность запроса в разных регионах.
Популярность запроса в разных регионах в Яндекс Вордстате
Региональная популярность (крайняя колонка справа) показывает, какую долю занимает тот или иной регион или город в показах по данному запросу, делённую на долю всех показов поисковых результатов этого региона. Говоря проще, эта метрика помогает понять, насколько этот запрос популярен в конкретном месте. Популярность выше 100% означает, что в данной местности есть повышенный интерес к продукту. Ниже 100% — продукт не очень популярен в этом регионе.
Иногда, в качестве эксперимента, можно и попробовать запустить рекламу в регионе, где популярность запроса ниже 100%. Есть вариант, что ваши конкуренты целятся в регионы, где спрос повыше, поэтому вы беспрепятственно сможете охватить там больше аудитории.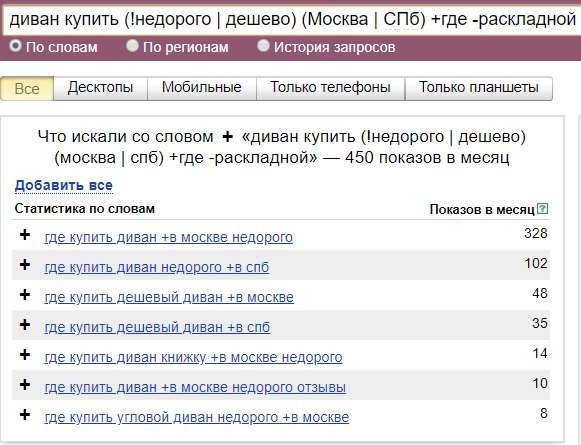
На примере нашего запроса пользователи больше всего интересуются курсами по программированию в Санкт-Петербурге и Москве. Если вы продаёте соответствующие программы и запускаете таргетированную рекламу, эта статистика поможет вам определиться, показы в каких регионах страны будут вам выгоднее.
Данные по регионам: как посмотреть вне Вордстата
Яндекс Вордстат в октябре 2022 года убрал возможность просмотра статистики по отдельным регионам (за исключением Москвы). Тем не менее есть возможность узнать количество показов в определённой местности с помощью функции расчёта бюджета в Яндекс Директе.
Для этого перейдите в инструмент «Прогноз бюджета», выберите нужный регион и подберите ключевые слова.
Сервис «Прогноз бюджета» в Яндекс Директе. Источник: direct.yandex.ru
В новом окне вы можете проверить ключевую фразу в конкретном регионе.
Подбор ключевых слов в сервисе «Прогноз бюджета» Яндекс Директа
История запросов (сезонность)
Вкладка «История запросов» поможет вам отследить популярность ключевой фразы в зависимости от конкретного периода времени.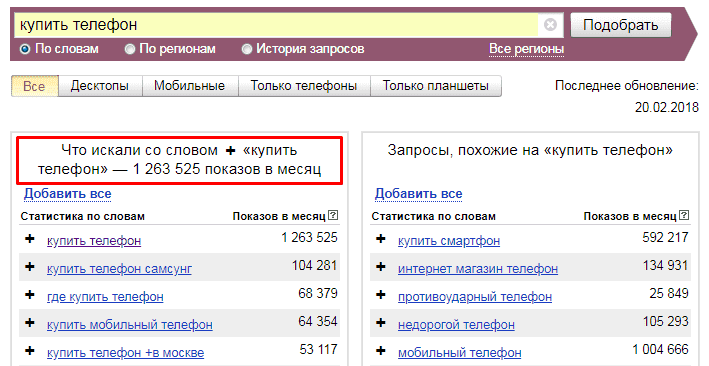
История запросов в Вордстате по ключевой фразе «курсы программирования»
Как мы видим, интерес к курсам программирования растёт в сентябре, что может быть связано с началом учебного года. Также мы видим, что в 2022 г. количество запросов резко выросло относительно прошлого года. Это значит, что популярность этого вида продуктов растёт.
Операторы Wordstat: как правильно пользоваться
Чтобы сделать подбор слов в Wordstat более конкретным, исключить лишние фразы и получить более точную статистику, можно воспользоваться операторами. Их используют как самостоятельно, так и в любой комбинации.
Оператор «!» (восклицательный знак) фиксирует форму фразы — род, число, падеж, окончания, но не ограничивает количество слов.
Пример использования оператора «!» в Яндекс Вордстате
Оператор «“ ”» (кавычки) ограничивает количество слов в запросе, но не фиксирует их окончание.
Пример использования оператора «“ ”» в Яндекс Вордстате
Оператор «[ ]» (квадратные скобки) очень удобен, если вам нужно сохранить порядок слов.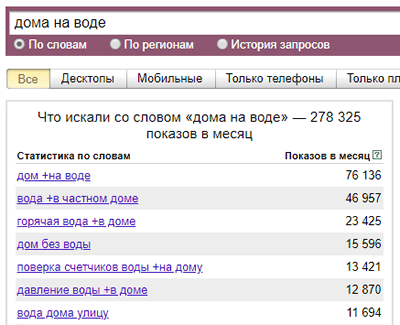 Например, если вы продаёте конкретный маршрут «от» и «до».
Например, если вы продаёте конкретный маршрут «от» и «до».
Пример использования оператора «[ ]» в Яндекс Вордстате
Без использования скобок вам будут предложены как варианты Москва — Краснодар, так и Краснодар — Москва. Оператор позволит исключить лишние данные.
Оператор «|» (или) поможет определить синонимичные варианты ключевых слов. В сочетании с оператором «()» (круглые скобки) эти инструменты используют для определения фраз с похожим значением.
Пример использования оператора «|» в Яндекс Вордстате
Оператор «-» (минус) убирает лишние слова. Например, уберём курсы по java, которые мы не предлагаем.
Пример использования оператора «-» в Яндекс Вордстате
Оператор «+» (плюс) фиксирует частицы, предлоги, союзы и местоимения, которые Вордстат обычно не принимает во внимание. Например, если рассмотрим фразу «работа по дереву», Вордстат покажет ненужные варианты вроде «купить дерево» или «краска для дерева».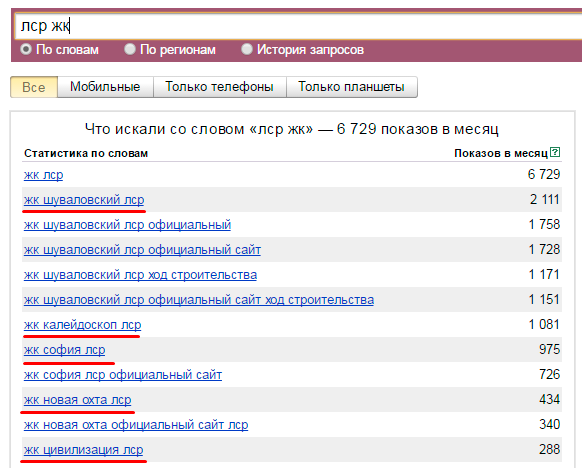 Уточнив запрос с помощью операторов, мы получим статистику по нужным нам фразам.
Уточнив запрос с помощью операторов, мы получим статистику по нужным нам фразам.
Пример использования оператора «+» в Яндекс Вордстате
Пример: как подбирать ключевые слова в Яндекс Wordstat для блога
Подбор слов в Wordstat может быть как ручным, так и с использованием различных сервисов. В первом случае вы потратите больше времени и сил, но сэкономите деньги. Профессиональные инструменты (например, Key Collector) платные, но при больших объёмах работы незаменимы. Пользуются ими в основном профессионалы в SEO.
Для продвижения собственных небольших проектов достаточно ручного поиска ключевых фраз в Вордстат. Например, нам надо заполнить блог магазина по продаже постельного белья.
1. Для начала нам надо понять, что будет интересно пользователям почитать о постельном белье. Забиваем в поиск «постельное бельё» и посмотрим, что чаще всего ищут люди.
Просмотр общей статистики запросов в Яндекс Вордстате
2. Поскольку у нас блог информационный, мы можем с помощью операторов убрать ненужные варианты фразы. Например, запросы со словом «купить», «магазин» или упоминания конкурентов.
Например, запросы со словом «купить», «магазин» или упоминания конкурентов.
Ограничение количества ключевых фраз с помощью оператора в Яндекс Вордстате
3. Как мы видим, пользователям интереснее всего узнать, как выбрать постельное бельё, какие ткани предпочтительное и какие размеры бывают и чем отличаются. На основе этих данных мы можем построить контент-план для нашего блога и составить планы нескольких статей.
Какие темы можно запланировать после такого анализа:
- как выбрать для себя лучшее постельное бельё,
- какие бывают размеры постельного белья,
- что нужно знать о сатиновом постельном белье перед покупкой;
- постельное бельё из поплина: свойства, плюсы и минусы.
Нажимая на каждый запрос, вы будете глубже погружаться в тему, собирая всё новые идеи для статей.
Для тех, кто хотел бы детальнее разобраться в теме сбора семантического ядра рекламы или начать карьеру в SEO мы подготовили подборку курсов.
Курсы по SEO
Курс
Школа
Рейтинг
Стоимость
Рассрочка
Длительность
Ссылка
SEO для всех
Loftschool
4.8
13 650 ₽
Есть
1.5 месяц
Сайт школы
SEO 2.0
Teachline
4.8
12 000 ₽
Есть
—
Сайт школы
Онлайн-курс SEO-специалист
Бруноям
4.8
19 900 ₽
Есть
3 месяца
Сайт школы
Контекстная реклама и SEO
ProductStar
4.6
39 900 ₽
Есть
1 месяц
Сайт школы
Больше курсов
Курсы по контекстной рекламе
Курс
Школа
Рейтинг
Стоимость
Рассрочка
Длительность
Ссылка
Контекстная реклама в «Яндекс.Директ»
Teachline
4.8
7 500 ₽
Есть
0.5 месяцев
Сайт школы
Курсы по контекстной рекламе
Бруноям
4. 8
8
24 900 ₽
Есть
1 месяц
Сайт школы
Специалист по контекстной рекламе: с нуля до middle
Нетология
4.6
66 300 ₽
Есть
7 месяцев
Сайт школы
Контекстная реклама с нуля
Skillbox
4.5
35 972 ₽
Есть
3 месяца
Сайт школы
Контекстная реклама (Яндекс.Директ и Google Adwords)
Международная школа профессий
4.3
11 400 ₽
—
1.3 месяц
Сайт школы
Больше курсов
Полезные расширения для Вордстата
Автоматизировать сбор ключевых фраз и их статистики помогут расширения для Вордстата.
Yandex Wordstat Helper — это виджет, который добавляется на страницу Яндекс Вордстата. С его помощью можно автоматизировать группировку ключей, просматривать счётчики количества слов и частотности, добавлять ключи в таблицы и сортировать их.
WordStater собирает не только ключи, но и стоп-слова (слова-минусы), а также может спрогнозировать цену клика каждой фразы.
Yandex Wordstat Assistant позволяет собрать все фразы в таблицу, сортировать их по частоте, алфавиту или порядку добавления, а также проверить на дубли.
Вордстат — простой и функциональный помощник для маркетологов, проджект-менеджеров, копирайтеров. Даже начинающий специалист без труда научится определять успешность того или иного запроса и использовать его в продвижении.
WordStat — Исследование Provalis
WordStat — это гибкое и простое в использовании программное обеспечение для анализа текста — нужны ли вам инструменты анализа текста для быстрого извлечения тем и тенденций или тщательное и точное измерение с помощью современных инструментов количественного анализа контента. WordStat может использоваться всеми, кому необходимо быстро извлекать и анализировать информацию из больших объемов документов. Наше программное обеспечение для контент-анализа и интеллектуального анализа текста можно использовать во многих приложениях, таких как анализ открытых ответов, бизнес-аналитика, контент-анализ новостей, обнаружение мошенничества и многое другое. Полная интеграция WordStat с SimStat — наш инструмент для анализа статистических данных — QDA Miner — наше программное обеспечение для качественного анализа данных — и Stata — комплексное статистическое программное обеспечение от StataCorp, обеспечивающее беспрецедентную гибкость при анализе текста и сопоставлении его содержания со структурированной информацией, включая числовую. и категориальные данные.
Полная интеграция WordStat с SimStat — наш инструмент для анализа статистических данных — QDA Miner — наше программное обеспечение для качественного анализа данных — и Stata — комплексное статистическое программное обеспечение от StataCorp, обеспечивающее беспрецедентную гибкость при анализе текста и сопоставлении его содержания со структурированной информацией, включая числовую. и категориальные данные.
СКАЧАТЬ БЕСПЛАТНУЮ ПРОБНУЮ ПРОБНУЮ ВЕРСИЮ ЗАПРОСИТЬ ВЕБ-ДЕМО
ИССЛЕДОВАНИЕ СОДЕРЖИМОГО ДОКУМЕНТА С ИСПОЛЬЗОВАНИЕМ ИНТЕРФЕЙСА ТЕКСТА
• Анализ больших объемов неструктурированной информации с помощью WordStat. Программное обеспечение может обрабатывать 25 миллионов слов в минуту, быстро извлекать темы и автоматически определять закономерности, используя кластеризацию, многомерное масштабирование, диаграммы близости и многое другое.
БЫСТРОЕ ИЗВЛЕЧЕНИЕ ЗНАЧЕНИЯ В РЕЖИМЕ ПРОВОДНИКА
• Быстро и легко извлекайте смысл из больших объемов текстовых данных с помощью режима Проводника, специально созданного для тех, у кого мало опыта в анализе текста.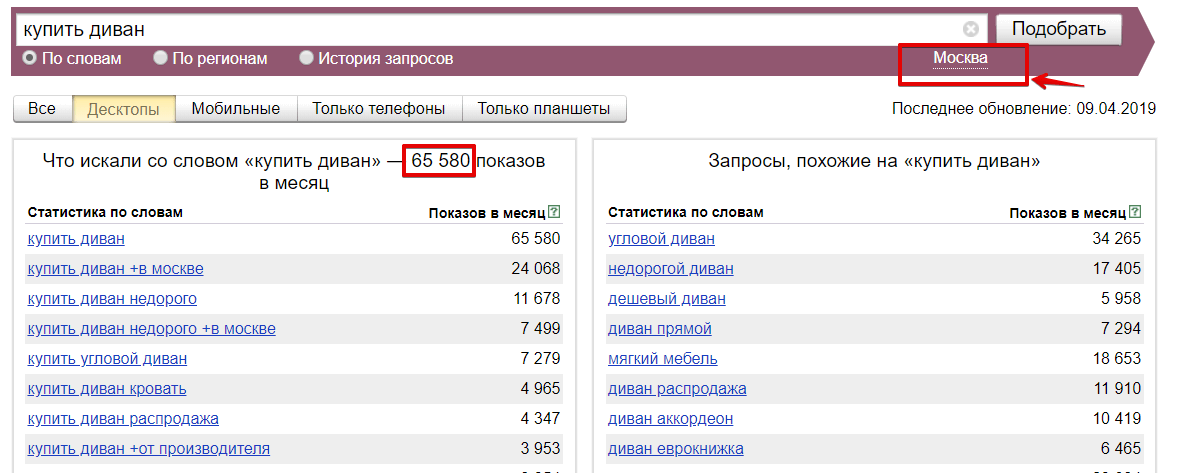 Одним щелчком мыши вы можете извлечь наиболее часто встречающиеся слова, фразы и самые важные темы в ваших документах.
Одним щелчком мыши вы можете извлечь наиболее часто встречающиеся слова, фразы и самые важные темы в ваших документах.
ИМПОРТ ИЗ МНОГИХ ИСТОЧНИКОВ
• Импорт Word, Excel, HTML, XML, SPSS, Stata, NVivo, PDF-файлов, а также изображений. Подключайтесь и напрямую импортируйте данные из социальных сетей, электронной почты, платформ веб-опросов и инструментов управления ссылками.
ИЗВЛЕЧЕНИЕ НАИБОЛЕЕ ЗНАЧИМЫХ ТЕМ С ПОМОЩЬЮ ТЕМАТИЧЕСКОГО МОДЕЛИРОВАНИЯ
• Получите краткий обзор наиболее важных тем из очень больших текстовых коллекций, используя современное автоматическое извлечение тем на основе слов, фраз и родственных слов (включая орфографические ошибки).
ИССЛЕДУЙТЕ СОЕДИНЕНИЯ
• Исследуйте отношения между словами или понятиями и извлекайте текстовые сегменты, связанные с определенными соединениями.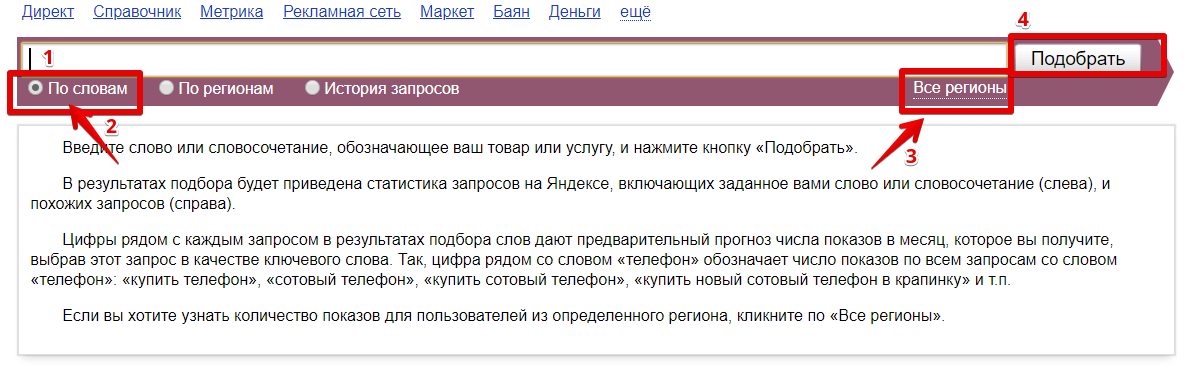
СВЯЗАТЬ ТЕКСТ СО СТРУКТУРИРОВАННЫМИ ДАННЫМИ
• Исследовать отношения между неструктурированным текстом и структурированными данными, такими как даты, числа или категориальные данные, для выявления временных тенденций или различий между подгруппами или для оценки отношений с рейтингом или другими видами категориальных или числовых данных со статистическими и графические инструменты (анализ соответствия, тепловые карты, пузырьковые диаграммы и др.).
КАТЕГОРИЗАЦИЯ ТЕКСТОВЫХ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ СЛОВАРОВ
• Автоматизируйте полнотекстовый анализ с помощью существующих словарей или создайте собственную модель категоризации со словами, фразами, правилами близости и т. д.
ПОЛУЧИТЕ УНИКАЛЬНУЮ ПОДДЕРЖКУ ДЛЯ СОЗДАНИЯ СЛОВАРОВ
• Создавайте свой словарь быстрее с помощью инструментов для извлечения общих фраз и технических терминов, а также для быстрого выявления в вашей текстовой коллекции орфографических ошибок, синонимов, антонимов и родственных слов.
КАТЕГОРИЗАЦИЯ ТЕКСТОВЫХ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ МАШИННОГО ОБУЧЕНИЯ
• Разрабатывайте и оптимизируйте модели автоматической классификации документов с использованием наивного байесовского метода и алгоритма K-ближайших соседей.
ВОЗВРАТ К ИСХОДНОМУ ДОКУМЕНТУ В ОДИН ЩЕЛЧОК
• Проверяйте или углубляйтесь в свой анализ, возвращаясь к тексту почти любой функции, диаграммы или графика. Вы можете использовать функции поиска ключевых слов или ключевых слов в контексте для поиска предложений, абзацев или целых документов. Это особенно полезно при построении таксономий или для устранения неоднозначности смысла слова. Вы также можете прикрепить коды QDA Miner к полученным сегментам.
ВЫПОЛНЕНИЕ КАЧЕСТВЕННОГО КОДИРОВАНИЯ
• Объедините WordStat с современным инструментом качественного кодирования (QDA Miner) для более точного исследования данных или более глубокого анализа конкретных документов или извлеченных текстовых сегментов, когда это необходимо.
ПРЕОБРАЗОВАНИЕ НЕСТРУКТУРИРОВАННОГО ТЕКСТА В ИНТЕРАКТИВНЫЕ КАРТЫ (ОТОБРАЖЕНИЕ ГИС)
• Связывайте неструктурированные текстовые данные с географической информацией и создавайте интерактивные графики точек данных, тематических карт и тепловых карт, а также веб-службу геокодирования для преобразования названий местоположений, почтовых индексов и IP-адресов в широту и долготу.
АВТОМАТИЧЕСКОЕ ИЗВЛЕЧЕНИЕ ИМЕНОВАННЫХ ОБЪЕКТОВ
• Автоматическое извлечение именованных объектов, которые можно добавить в словарь категорий с помощью простой операции перетаскивания.
ЭКСПОРТ РЕЗУЛЬТАТОВ
• Простой экспорт результатов анализа текста в распространенные отраслевые форматы файлов, такие как Excel, SPSS, ASCII, HTML, XML, MS Word, а также графики, такие как PNG, BMP и JPEG.
ПРЕОБРАЗОВАНИЕ ТЕКСТА С ИСПОЛЬЗОВАНИЕМ СКРИПТОВ PYTHON
• Используйте скрипты Python и полный спектр библиотек с открытым исходным кодом для предварительной обработки или преобразования текстовых документов для анализа в WordStat.
Мы пришли к выводу, что WordStat является самым мощным инструментом текстовой аналитики, доступным для бизнес-приложений.
Д-р Джон М. Аарон
Профессор Элмхерстского колледжа, магистерская программа по науке о данных
WordStat может легко выполнять широкий спектр анализа текста. Он имеет множество удобных возможностей, которые делают его намного проще в использовании, чем другие продукты.
Д-р Грант Бланк
Исследовательский научный сотрудник Оксфордского университета
Что нового в WordStat 9
Что нового в версии 2023?
Мы рады объявить о выпуске WordStat 2023, который представляет собой значительный шаг вперед в применении устранения неоднозначности смысла слов к тематическим моделям. Наша уникальная функция обогащения тем претерпела значительные улучшения, и мы представили несколько новых возможностей моделирования тем, чтобы помочь пользователям получить еще больше информации из своих данных. Кроме того, мы реализовали множество оптимизаций скорости, которые сделали программное обеспечение более отзывчивым и удобным для пользователя. В версии 2023.1 также представлены импорт и обработка финансовых документов, интеграция Power BI, Gephi и NetDraw, а также настраиваемые цветовые палитры для построения диаграмм.
Наша уникальная функция обогащения тем претерпела значительные улучшения, и мы представили несколько новых возможностей моделирования тем, чтобы помочь пользователям получить еще больше информации из своих данных. Кроме того, мы реализовали множество оптимизаций скорости, которые сделали программное обеспечение более отзывчивым и удобным для пользователя. В версии 2023.1 также представлены импорт и обработка финансовых документов, интеграция Power BI, Gephi и NetDraw, а также настраиваемые цветовые палитры для построения диаграмм.
1. Улучшенное обогащение темы
WordStat теперь добавляет более релевантные фразы к извлеченным темам, а также предлагает улучшенные предложения для дополнительных фраз. Кроме того, теперь он может похвастаться большей точностью в определении ложноположительных выражений или исключений, которые можно включить в модель темы, чтобы помочь устранить неоднозначность слов, связанных с контекстами, не связанными с извлеченными темами.
2.
 Моделирование темы Облако слов
Моделирование темы Облако слов
Панель сравнения в правой части таблицы модели темы теперь содержит недавно добавленное облако слов, которое визуально отображает относительную важность первых слов в выбранной теме. Это облако слов можно настроить, скопировать в буфер обмена или сохранить на диск в стандартных графических форматах, таких как BMP, PNG или JPEG.
3. Новая интегрированная функция поиска текста
Новая удобная панель Образец текста справа от сетки тем может быть активирована для автоматического отображения предложений или абзацев, соответствующих выбранной теме. Эти текстовые сегменты представлены в порядке убывания релевантности, а ключевые слова выделены жирным шрифтом, что упрощает понимание сути каждой темы и определение ключевых примеров, которые можно использовать для ее иллюстрации. Этот мощный инструмент предоставляет пользователям более глубокое понимание их данных и способствует более эффективному обмену их выводами.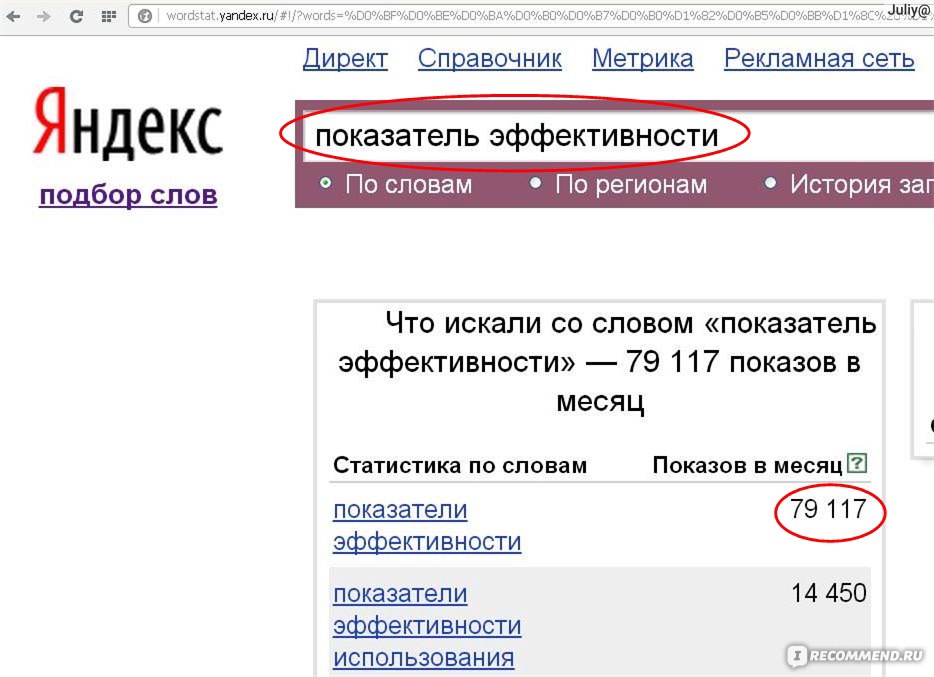
4. Улучшенная скорость обогащения верхней части
Благодаря значительным усилиям по оптимизации процесс обогащения темы был значительно ускорен, что привело к повышению производительности до 10-20 раз быстрее, чем в предыдущих версиях.
5. Мгновенное извлечение фраз
Используя возможности многоядерной обработки, извлечение фраз теперь легко интегрируется с основной обработкой текста, что позволяет пользователям получать доступ к результатам почти мгновенно. Например, из набора данных, содержащего более 50 000 отзывов клиентов, извлечение 5000 наиболее частых фраз теперь можно выполнить всего за 0,4 секунды по сравнению с 14 секундами, необходимыми в предыдущей версии.
6. Импорт финансовых документов 10-K и 10-Q
Новая процедура импорта позволяет пользователям импортировать определенные разделы финансовых документов 10-K и 10-Q и сохранять их отдельно или объединять в отдельные документы. Процедура извлечения автоматически распознает название компании, период времени (квартал и год) и сохраняет их как переменные для удобства анализа.
7. Экспорт результатов анализа текста в Power BI
WordStat теперь предлагает бесшовную интеграцию с Microsoft Power BI, позволяя пользователям экспортировать результаты анализа текста и метаданные в Power BI Desktop для интерактивных информационных панелей и отчетов. Экспортируя результаты анализа текста и метаданные в Power BI Desktop, пользователи могут создавать привлекательные визуализации, получать более глубокое представление о своих данных и легко делиться своими выводами с другими.
8. Отправьте данные о совпадении в Gephi или NetDraw.
С новой опцией, доступной на странице Дендрограмма, пользователи теперь могут экспортировать данные о совпадениях вместе с дополнительной информацией, такой как частота и номер кластера, в программное обеспечение для анализа социальных сетей, такое как Gephi и NetDraw. Эти инструменты обеспечивают мощную визуализацию, помогающую пользователям выявлять закономерности и взаимосвязи в своих данных. Gephi предлагает алгоритмы компоновки и интерактивные функции для исследования в реальном времени, а NetDraw предоставляет возможности визуализации сетевых графиков.
Gephi предлагает алгоритмы компоновки и интерактивные функции для исследования в реальном времени, а NetDraw предоставляет возможности визуализации сетевых графиков.
9. Пользовательские палитры диаграмм
WordStat 2023 представляет новую функцию, которая позволяет пользователям создавать собственные цветовые палитры. Эта функция обеспечивает больший контроль над цветами, используемыми для диаграмм, облаков слов, кластеризации и других визуализаций, позволяя пользователям настраивать вывод в соответствии со своими конкретными потребностями.
Представлено в версии 2022
1. Оптимизированное тематическое моделирование с факторным анализом
В WordStat 2022 мы внедрили новую процедуру многопоточного факторного анализа, которая работает до 65 раз быстрее, чем в предыдущих версиях. Это означает, что большие задачи, на вычисление которых ушел бы час, теперь могут быть получены менее чем за минуту. Мы также смогли увеличить емкость факторного анализа до 10 000 слов (с 3 000 в предыдущих версиях).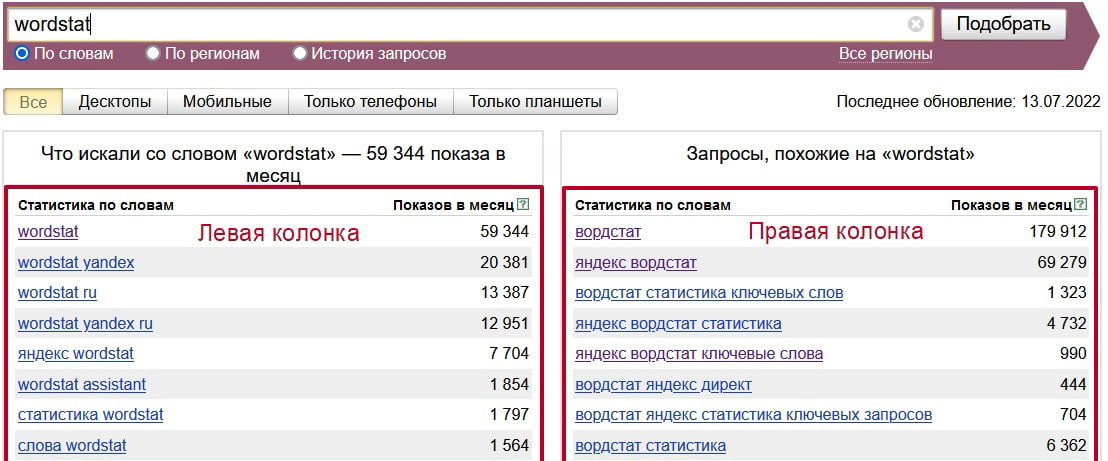
Наши собственные исследования показали, что тематическое моделирование с использованием факторного анализа дает тематические решения, которые являются более последовательными и разнообразными, чем методы тематического моделирования, основанные на методах LDA и нейронных сетей (Peladeau & Davoodi, 2018; Peladeau, 2022). Он также имеет дополнительное преимущество в том, что он стабилен и каждый раз дает одинаковые результаты. Однако главным его неудобством всегда были скорость и вместительность. Это привело нас к реализации в WordStat 8 специальной процедуры извлечения темы с использованием неотрицательной матричной факторизации (или NMF). Этот метод гораздо быстрее дает результаты, очень похожие на результаты, полученные с помощью факторного анализа. Однако его вероятностная реализация приводит к тому, что результаты немного отличаются от одного прогона к другому, что некоторые исследователи находят несколько тревожным. Важно отметить, что почти все другие популярные методы тематического моделирования в компьютерных науках дают тематические решения, которые еще более нестабильны, чем наша собственная реализация NMF. Те, кто ищет оптимальные и стабильные тематические решения, вероятно, оценят значительно улучшенную скорость и возможности новой процедуры тематического моделирования факторного анализа.
Те, кто ищет оптимальные и стабильные тематические решения, вероятно, оценят значительно улучшенную скорость и возможности новой процедуры тематического моделирования факторного анализа.
2. Улучшенные предложения на странице Частоты
Панель Предложения в предыдущих версиях WordStat отображала синонимы, антонимы и родственные слова для языков, для которых был доступен тезаурус. В нем также представлены слова, начинающиеся с одних и тех же начальных букв, что позволяет определить некоторые орфографические ошибки, а также родственные слова. Новый раздел Associated Words теперь извлекает из корпуса текстов другие слова, семантически, синтаксически и статистически связанные с выбранными словами в частотной таблице. Эта новая функция должна работать на любом языке. Записи будут перечислены по умолчанию в порядке убывания релевантности. Синонимы, антонимы и родственные слова также будут отсортированы в порядке убывания релевантности, что облегчит определение подходящих предложений. Можно по-прежнему сортировать эти записи в алфавитном порядке или в порядке убывания частоты. Кроме того, новая опция частотной фильтрации позволяет отфильтровывать низкочастотные предложения, позволяя сосредоточиться на более частых предложениях.
Можно по-прежнему сортировать эти записи в алфавитном порядке или в порядке убывания частоты. Кроме того, новая опция частотной фильтрации позволяет отфильтровывать низкочастотные предложения, позволяя сосредоточиться на более частых предложениях.
Поскольку этот новый способ извлечения связанных слов и предложений по порядку не зависит от языка, он будет особенно полезен для людей, анализирующих языки, для которых нет тезауруса. Тем не менее, мы обнаружили, что даже когда такие лингвистические ресурсы доступны, дополнительные предложения, основанные на контекстуальном использовании слов и сортировке существующих синонимов и связанных слов по релевантности, должны значительно облегчить идентификацию соответствующих элементов.
3. Новая вкладка предложений для процедуры извлечения фраз.
Панель Overlap была заменена панелью Suggestions , отображающей фразы, семантически, синтаксически или статистически связанные с выбранными строками в таблице частоты фраз, в дополнение к перекрывающимся фразам. Эта функция также не зависит от языка.
Эта функция также не зависит от языка.
4. Улучшение распознавания именованных объектов.
На страницу Распознавание именованных объектов добавлена новая панель Related . При выборе одного именованного объекта появятся связанные именованные объекты, а также объекты, принадлежащие к одному и тому же классу (люди, место, организация и т. д.). При выборе нескольких примеров определенного класса (например, нескольких городов) также будет получено больше элементов, принадлежащих этому классу. Контекстное меню также позволяет переместить любой элемент в словарь категорий или в список исключений. По выбранным предложениям также может быть выполнен поиск по ключевым словам в контексте.
5. Выделение контекстных слов в таблицах ключевых слов в контексте.
При оценке слов в категоризационном словаре или кандидатов на включение часто необходимо смотреть на наличие дополнительных ключевых слов в контексте появления целевого слова или фразы.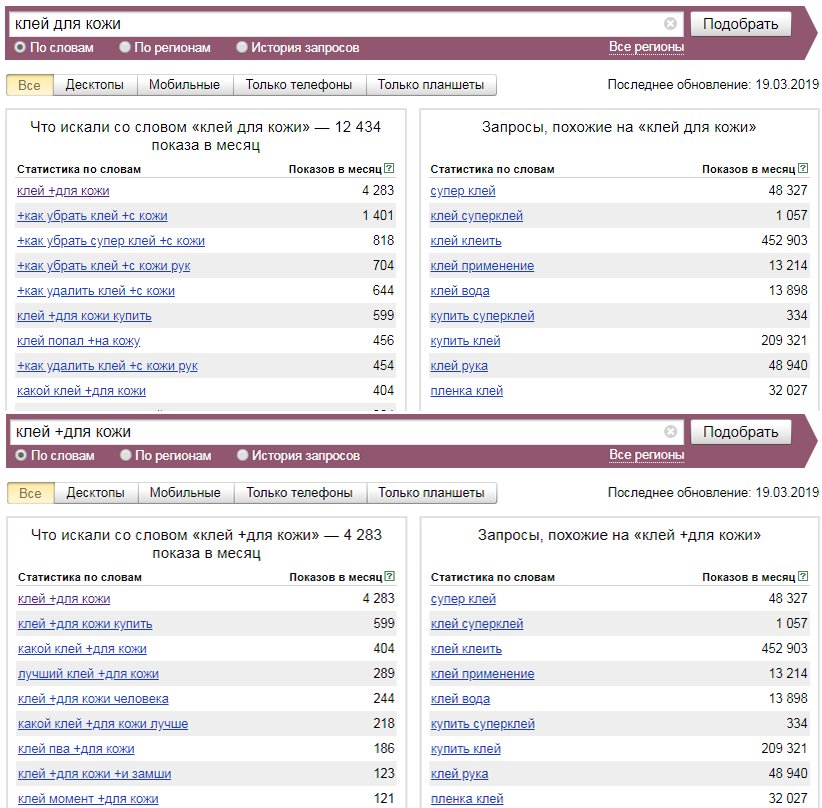 Новая функция выделения позволяет указать список слов и фраз для поиска в окружающем контексте слова. Этот список заполняется автоматически, когда список KWIC вызывается из моделирования темы или из дендрограммы, или при оценке элементов в категории содержимого, содержащей несколько записей.
Новая функция выделения позволяет указать список слов и фраз для поиска в окружающем контексте слова. Этот список заполняется автоматически, когда список KWIC вызывается из моделирования темы или из дендрограммы, или при оценке элементов в категории содержимого, содержащей несколько записей.
6. Фильтрация элементов в графиках соответствий по частоте или расстоянию от исходной точки.
Графики соответствий из более чем нескольких сотен элементов могут создавать темную массу перекрывающихся элементов в центре графика (начало). Добавлен новый ползунок для скрытия элементов, которые встречаются реже или близки к этому происхождению. Если кто-то не хочет определить, что является общим для всех классов независимой переменной, наиболее интересными являются те элементы, которые далеки от начала, поскольку они характеризовали разные классы. Фильтрация этих элементов позволяет легче идентифицировать дифференцирующие элементы.
7. Улучшенный поиск по ключевым словам
Результаты поиска по ключевым словам теперь сортируются в порядке убывания релевантности с учетом как частоты, так и разнообразия совпадающих элементов в зависимости от длины извлеченного текстового сегмента.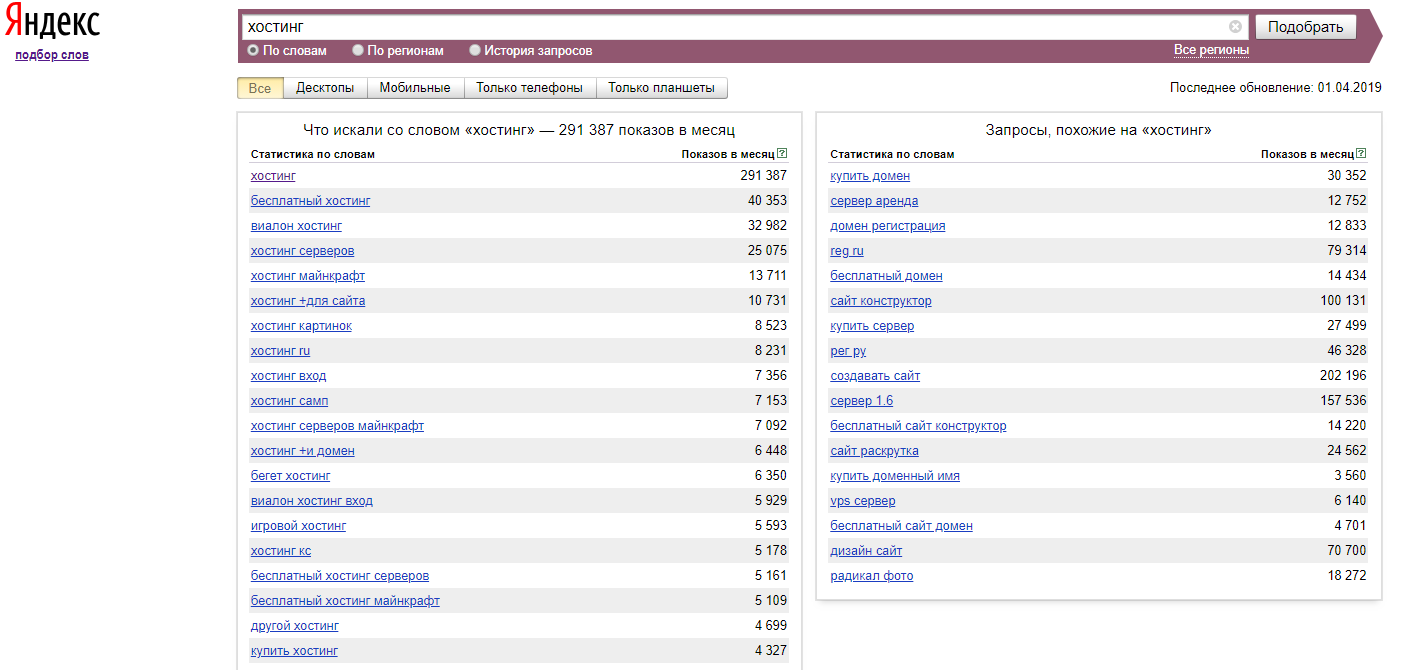 Новый столбец частоты также можно использовать для сортировки только по частотам.
Новый столбец частоты также можно использовать для сортировки только по частотам.
8. Вычисление строковой переменной конкатенацией
Новая команда преобразования данных позволяет вычислять строковую переменную путем конкатенации значений нескольких существующих переменных (числа, строки, даты и т.д.), а также печатного текста. Такую процедуру также можно использовать для инициализации строковой переменной постоянным строковым значением.
9. Постоянные настройки сравнительных диаграмм
Тип диаграммы и статистика, а также цветовая палитра этих сравнительных диаграмм теперь связаны с именем переменной и хранятся в настройках проекта. Эти параметры должны оставаться постоянными на всех страницах (частоты, фразы, моделирование тем, дендрограмма и т. д.) и между сеансами, что снижает необходимость постоянной корректировки этих параметров.
Что нового в версии 9.0?
1. Полная поддержка Unicode
Мы всегда стараемся выбирать методы анализа текста, не зависящие от языка. Это позволило пользователям анализировать текстовые данные на более чем 50 языках. Однако для анализа языков, не поддерживаемых установкой Windows по умолчанию, пользователю необходимо изменить некоторые параметры Windows. И хотя можно было анализировать наборы данных на нескольких языках, некоторые комбинации языков были просто невозможны. Новая версия Unicode WordStat позволяет анализировать любой из них без каких-либо изменений настроек, а также новые языки, ранее не поддерживаемые, такие как китайский, японский или тайский. Также были добавлены процедуры сегментации слов для трех предыдущих азиатских языков.
Это позволило пользователям анализировать текстовые данные на более чем 50 языках. Однако для анализа языков, не поддерживаемых установкой Windows по умолчанию, пользователю необходимо изменить некоторые параметры Windows. И хотя можно было анализировать наборы данных на нескольких языках, некоторые комбинации языков были просто невозможны. Новая версия Unicode WordStat позволяет анализировать любой из них без каких-либо изменений настроек, а также новые языки, ранее не поддерживаемые, такие как китайский, японский или тайский. Также были добавлены процедуры сегментации слов для трех предыдущих азиатских языков.
2. Интеграция сценариев предварительной и постобработки R и Python
В 2018 году мы представили возможность создавать сценарии предварительной обработки Python в WordStat 8. Версия 9.0 расширяет эту возможность, предлагая возможность создавать сценарии предварительной обработки в Р тоже. Что еще более важно, теперь можно создавать сценарии постобработки на этих двух языках программирования, что позволяет выполнять пользовательский анализ исходных или преобразованных текстовых данных или количественных результатов, полученных в результате анализа содержимого этих документов. Такая функция предлагает бесконечные возможности для расширения функций WordStat, таких как внедрение новых алгоритмов машинного обучения, передовых методов статистического моделирования или преобразования пользовательских данных. Были включены примеры сценариев для вычисления показателей удобочитаемости текста, определения языков, применения других методов тематического моделирования (LDA или STM) или создания прогностических моделей с использованием машинного обучения (SVM, kNN и т. д.).
Такая функция предлагает бесконечные возможности для расширения функций WordStat, таких как внедрение новых алгоритмов машинного обучения, передовых методов статистического моделирования или преобразования пользовательских данных. Были включены примеры сценариев для вычисления показателей удобочитаемости текста, определения языков, применения других методов тематического моделирования (LDA или STM) или создания прогностических моделей с использованием машинного обучения (SVM, kNN и т. д.).
3. Автоматическая коррекция орфографии
Новый механизм проверки орфографии был написан с нуля для достижения гораздо более быстрой и точной коррекции орфографии, что позволяет реализовать функцию автоматической коррекции орфографии с минимальным влиянием на существующую скорость обработки текста. из WordStat. Интеллектуальная коррекция орфографии может даже исправить написание неизвестных терминов, таких как технические словари, имена собственные и т. д. Результаты могут быть автоматически сохранены в списке замен для пересмотра и исправления.
4. Кросс-таблица с панелями диаграмм и фильтрацией
Страница кросс-таблицы теперь включает панель диаграммы, позволяющую быстро построить распределение выбранных строк таблицы кросс-таблицы для значений текущей выбранной переменной или любой другой переменной. Список фильтрации также позволяет анализировать такие распределения для одного значения или набора значений выбранной переменной.
5.
Интерактивная матрица совпадений
На страницу совпадений добавлена новая функция интерактивной матрицы, позволяющая сосредоточиться на определенных совпадениях. Основные результаты состоят из таблицы, отображающей выбор из различных статистических данных о совпадениях. Такая матрица также очень интерактивна, позволяя преобразовывать определенные строки в новые столбцы или наоборот, используя простые операции перетаскивания. Панель диаграмм слева также позволяет оценить распределение конкретного совпадения по другим переменным. Можно также получить быстрый просмотр всех текстовых сегментов, связанных с определенным совпадением.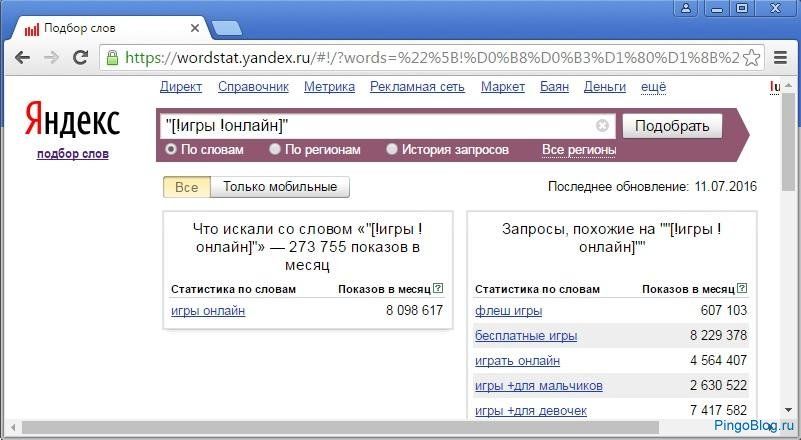 Эту новую функцию WordStat также можно вызвать из списка частот, выбрав целевые элементы (слова или категории контента), которые должны отображаться в виде столбцов, щелкнув правой кнопкой мыши и выбрав Матрица совпадений.
Эту новую функцию WordStat также можно вызвать из списка частот, выбрав целевые элементы (слова или категории контента), которые должны отображаться в виде столбцов, щелкнув правой кнопкой мыши и выбрав Матрица совпадений.
6. Импорт файлов Nexis UNI и Factiva
Представленный в QDA Miner 6.0 в 2020 году, WordStat теперь также может импортировать стенограммы новостей из выходных файлов LexisNexis и Factiva. После выбора одного или нескольких файлов .DOCX или RTF, полученных от этих служб, WordStat извлечет и сохранит в отдельных переменных название и основную часть стенограммы новостей, ее источник, дату публикации и другую соответствующую информацию. Такая функция должна оказаться полезной для управления репутацией, управления брендом, кризисной коммуникации, анализа медиа-фрейминга, сравнительных медиа-исследований и т. д.
7. Пакетная обработка тематических моделей
Выбор количества тем для извлечения с использованием методов тематического моделирования остается вопросом, на который, насколько нам известно, нет однозначного ответа.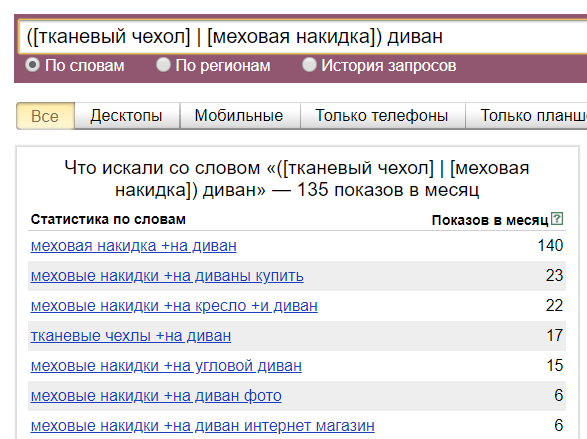 Мы можем даже усомниться в существовании такого оптимального числа. На самом деле можно даже предположить, что информация, полученная в разных условиях, вполне может служить разным целям или раскрывать разные аспекты реальности. В таком контексте неопределенности исследователи часто хотят сравнить различные решения. Новая функция пакетной обработки позволяет вычислять несколько тематических моделей путем систематического изменения количества тем для извлечения, а для вероятностного метода (например, NNMF) выполнять несколько прогонов с использованием одних и тех же настроек для оценки стабильности результатов. Все решения тематических моделей временно агрегируются в менеджере отчетов, что позволяет сравнивать решения, полученные в нескольких прогонах с разными настройками.
Мы можем даже усомниться в существовании такого оптимального числа. На самом деле можно даже предположить, что информация, полученная в разных условиях, вполне может служить разным целям или раскрывать разные аспекты реальности. В таком контексте неопределенности исследователи часто хотят сравнить различные решения. Новая функция пакетной обработки позволяет вычислять несколько тематических моделей путем систематического изменения количества тем для извлечения, а для вероятностного метода (например, NNMF) выполнять несколько прогонов с использованием одних и тех же настроек для оценки стабильности результатов. Все решения тематических моделей временно агрегируются в менеджере отчетов, что позволяет сравнивать решения, полученные в нескольких прогонах с разными настройками.
8. Создание облаков слов на основе поиска ключевых слов и результатов KWIC
Интерактивные облака слов и таблицы частотности слов теперь могут быть получены непосредственно в результатах поиска ключевых слов и ключевых слов в контексте (KWIC), что позволяет быстро идентифицировать слова, связанные с конкретным содержанием. категории или те, которые появляются до и после определенного целевого элемента.
категории или те, которые появляются до и после определенного целевого элемента.
9. Более мощные правила близости
Количество условий в правилах близости увеличено с четырех до максимум двадцати условий. Если вы считаете, что этого недостаточно, сообщите нам об этом.
10. Предварительный просмотр эффекта подстановочных знаков и взаимодействий со словарем
Использование подстановочных знаков в словаре весьма полезно, но потенциально проблематично, поскольку оно может сопоставлять элементы, о которых вы, возможно, и не подозревали. Например, такая запись, как НАЛОГ*, может позволить вам сопоставить НАЛОГ, НАЛОГИ, НАЛОГООБЛОЖЕНИЕ, но также будет соответствовать таким словам, как ТАКСИ, ТАКСОНОМИЯ, ТАКСИДЕРМИЯ и т. д. Кроме того, правила WordStat для сопоставления элементов и предотвращения двойного подсчета также могут привести к неожиданным результатам. результаты, вызванные другими записями в вашей модели категоризации.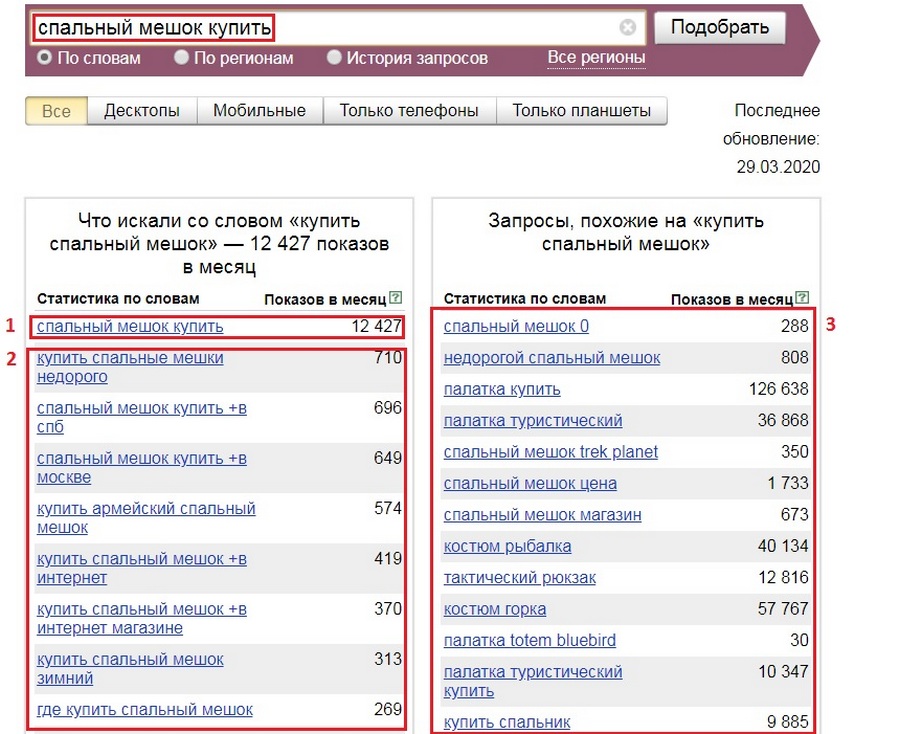 Новая панель справа от страниц исключения и категоризации позволяет вам легко идентифицировать новые записи, которые будут сопоставляться с использованием подстановочного знака * в конце слова, а также возможные конфликты с другими записями в вашем словаре.
Новая панель справа от страниц исключения и категоризации позволяет вам легко идентифицировать новые записи, которые будут сопоставляться с использованием подстановочного знака * в конце слова, а также возможные конфликты с другими записями в вашем словаре.
11. Защита паролем файлов проекта
WordStat 9.0 теперь предлагает возможность защиты паролем файлов проекта, ограничивая доступ к определенным проектам только авторизованным пользователям. Диалоговое окно позволяет администратору проекта создавать новые учетные записи пользователей и указывать, какую операцию может выполнять каждый пользователь. Можно ограничить редактирование данных, импорт или преобразование данных, а также экспорт данных проекта, таблиц и графики. В качестве альтернативы вы можете позволить пользователям выполнять любое преобразование, которое они хотят, но запретить им сохранять файл проекта.
12.
Новые параметры очистки данных
Страница предварительной обработки теперь включает параметры для автоматического удаления URL-адресов из текстовых сообщений, а также обозначений выступающих в новостях и расшифровках интервью.
13. Новые диаграммы с областями с накоплением
Функция построения диаграмм на странице кросс-таблицы добавляет возможность создания двух типов диаграмм с областями с накоплением.
14. Цветные элементы на графике соответствия
Цветовые градиенты теперь можно использовать для представления положения определенных элементов или классов переменных в третьем (глубинном) измерении или на графике соответствия 2D и 3D. Для создания этих градиентов можно выбрать до четырех цветов.
15. Улучшенная пузырьковая диаграмма
Теперь можно переставлять строки и столбцы пузырьковых диаграмм.
16. Буфер анализа каналов
Буфер анализа каналов позволяет вернуться к предыдущим диаграммам каналов, а затем перейти вперед.
17. Более быстрое и точное обогащение тем
WordStat выходит за рамки обычного моделирования тем, предлагая «уникальную функцию обогащения тем, которая идентифицирует связанные фразы, возможные исключения и орфографические ошибки. Он также автоматически генерирует соответствующие названия тем. С версией 9, эта функция обогащения темы теперь работает в два раза быстрее, чем раньше, и обеспечивает лучшее устранение неоднозначности слов для более точного списка исключений. Он также предоставляет лучшие предложения по исправлению орфографии.
Он также автоматически генерирует соответствующие названия тем. С версией 9, эта функция обогащения темы теперь работает в два раза быстрее, чем раньше, и обеспечивает лучшее устранение неоднозначности слов для более точного списка исключений. Он также предоставляет лучшие предложения по исправлению орфографии.
18. Повышенная скорость и точность существующих исправлений орфографии
Существующая функция исправления орфографии теперь работает до 30 раз быстрее, и требуется всего одна или две секунды, чтобы предложить исправления для десятков тысяч неизвестных слов.
19. Новый формат файла .PPRJ
Создан новый формат файла с новым расширением файла (.pprj), обеспечивающий улучшенную поддержку данных Unicode. Тем не менее, WordStat 9 сохраняет обратную совместимость с предыдущими версиями всего нашего программного обеспечения и может открывать и анализировать текущие файлы проекта (.ppj), созданные QDA Miner, SimStat или более ранними версиями WordStat.
20.