Содержание
Операторы Wordstat — как работать с ними эффективно
- Семантика
- SEO-оптимизация
10 декабря 2021
7 мин.
SEO-аналитик
Антон Жиронкин
Обновлено 27 сентября 2022
Что изменено?
Сегодня мы в Rush Analytics до конца реализовали поддержку всех операторов Wordstat.
Зачастую Вордстат может сильно облегчить задачу сбора семантики, особенно на начальном этапе, поэтому грамотное использование операторов на старте обязательно.
Навигация по статье
- Какие операторы поддерживает Вордстат?
- Переходим к практике
- Кейс №2
- Кейс №3
- Кейс №4
Какие операторы поддерживает Вордстат?
Давайте для начала рассмотрим все поддерживаемые операторы:
• “кавычки” – число показов только данного запроса, но по всем возможным окончаниям и порядку слов в запросе.
• ! восклицательный знак – данный оператор фиксирует окончание слова.
• + оператор «Плюс» — оператор будет полезен для поиска запросов с предлогами и союзами.
• — оператор «Минус» — думаю многим знакомый оператор, поможет вам избавиться от стоп слов и получить только нужные запросы.
• | оператор «Или» — так же еще один полезный оператор, который позволит вам получить запросы сразу по нескольким условиям. Например – купить машину (недорого|ваз)
Например – купить машину (недорого|ваз)
• () оператор «Группировка» — в совокупности с оператором «Или» позволит делать вам полезные регулярки и извлекать запросы по комбинированным условиям.
Это была теоретическая часть, чтобы освежить знания. Теперь давайте разберем конкретные кейсы с данными операторами и их комбинациями.
Переходим к практике
Начнем от простого к сложному и постараемся рассмотреть типичные ситуации, с которыми многие сталкиваются при сборе ключевых слов из Wordstat.
Кейс №1
Бывают такие тематики, в которых основная частотная семантика начинается от 3-4 слов и выше. Одной из них являются микрозаймы. Как вытащить из вордстата только четырехсловные запросы? А очень просто – тут нам поможет оператор кавычек
Почему так происходит? Все очень просто. Указывая оператор «Кавычки» вы говорите Вордстату – покажи мне ограниченный по длине диапазон слов, которые включают в себя слова, указанные в кавычках. Так как мы указали 4 раза слово «микрозайм» – то мы получаем всех четырехсловные запросы, с содержанием данного слова.
Так как мы указали 4 раза слово «микрозайм» – то мы получаем всех четырехсловные запросы, с содержанием данного слова.
Если у вас основной запрос тематики двухсловный, например «натяжные потолки», то вам нужно будет указать “натяжные потолки потолки” или «натяжные натяжные потолки» – и получить все 3-х словные запросы по вашей тематике.
Читайте также: Сбор подсказок Яндекса
Кейс №2
Второй практический пример – нам надо получить маркерные запросы для категории «Стиральные машины Samsung», по которым мы в дальнейшем будем собирать облако запросов и делать теговые страницы. Так как искать данную категорию могут по разным написаниям запросов – стиральная машина, стиральная машинка, Samsung, Самсунг – нам нужно сделать соответствующую регулярку в Вордстате и в 1 клик получить все запросы для данной категории:
стиральные (машины|машинки) (samsung|самсунг) -ремонт -ошибки -отзыв -коды -видео -запчасти –неисправности
Также были добавлены базовые стоп слова, чтобы не получать мусорные запросы.
Присоединяйтесь к
Rush-Analytics уже сегодня
7-ми дневный бесплатный доступ к полному функционалу. Без привязки карты.
Попробовать бесплатно
Кейс №3
Очень часто бывают такие тематики, которые содержат очень много смешанных интентов, на чистку которых в дальнейшем уходит очень много времени. Один из таких примеров – продажа компьютеров. Если мы вобьем «купить компьютер» в Вордстат – то соберем кучу ненужного, например: «купить монитор для компьютера», «купить клавиатуру для компьютера» и т.д.
Чтобы собрать только нужные нам маркеры нам нужно просто зафиксировать словоформу и подать запрос в Вордстат «купить !компьютер» и получить уже запросы без лишних интентов.
Читайте также: Как быстро выгрузить поисковые запросы из Яндекс Метрики
Кейс №4
Допустим, перед нами стоит задача быстро собрать теги для категории «Смартфоны» и у нас нет времени чистить огромное облако запросов данной категории от мусора.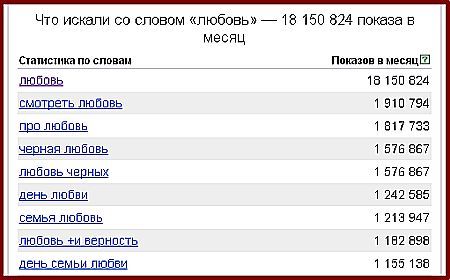 Чаще всего тегами являются 2 типа интентов – характеристика объекта (белый смартфон, мощный смартфон) и по назначению объекта (смартфон для пожилых, смартфон для девушки). С помощью Вордстата мы можем легко собрать теги 2-го типа – по назначению, так как все такие запросы содержат предлоги. Исходя из этого мы делаем следующую регулярку:
Чаще всего тегами являются 2 типа интентов – характеристика объекта (белый смартфон, мощный смартфон) и по назначению объекта (смартфон для пожилых, смартфон для девушки). С помощью Вордстата мы можем легко собрать теги 2-го типа – по назначению, так как все такие запросы содержат предлоги. Исходя из этого мы делаем следующую регулярку:
смартфоны (+до|+с|+на) -скачать -игры -интернет -мтс -фото
Так же указываем базовые стоп слова, чтобы не собирать мусор.
Сразу видны будущие теги – смартфоны на андроиде, с мощным аккумулятором, с хорошей камерой и т.д. Естественно у каждого могут быть индивидуальные проблемы и текущие кейсы не подойдут для решения вашей задачи, но включив логику, вы всегда можете видоизменить наши примеры под ваши нужды.
С помощью Rush Analytics можно настроить работу с запросами для интернет-магазина, а МойСклад поможет автоматизировать ведение складского учета для предприятий малого и среднего бизнеса. Все приведенные выше примеры работают в нашем парсере Wordstat – можете сами в этом убедиться.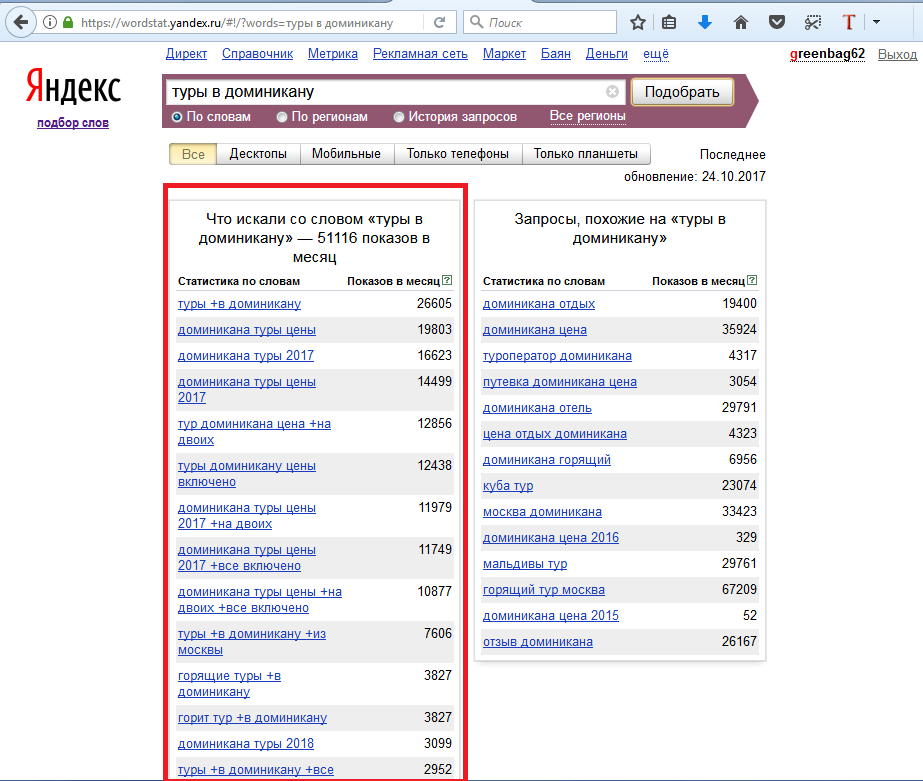 🙂
🙂
Просмотров
7001
Рейтинг
5,0/5
Оценить
Комментариев
Комментировать
Другие наши статьи
На страницу статей
Семантика
SEO-оптимизация
Инструкция
Аналитика источников семантики
Каждый SEO-специалист знает, что успешное продвижение сайта в поиске невозможно без качественного семантического ядра, включающего в себя по возможности все поисковые запросы (или ключевые слова, маркерные запросы) в нужной ему тематике.
Валентин Батрак
09 декабря 2021
Семантика
SEO-оптимизация
Операторы Wordstat — как работать с ними эффективно
Сегодня мы в Rush Analytics до конца реализовали поддержку всех операторов Wordstat.
Зачастую Вордстат может сильно облегчить задачу сбора семантики, особенно на начальном этапе, поэтому грамотное использование операторов на старте обязательно.
Антон Жиронкин
10 декабря 2021
Семантика
SEO-оптимизация
Обучение
Низкочастотные запросы
Обычно такие запросы вводят люди, которые точно знают, что ищут. Продвижение по низкочастотным запросам — это недорогой способ получения целевого трафика — правило касается как SEO, так и контекстной рекламы.
Продвижение по низкочастотным запросам — это недорогой способ получения целевого трафика — правило касается как SEO, так и контекстной рекламы.
Дмитрий Цытрош
10 декабря 2021
Получите 7 дней бесплатного доступа
Здесь вы можете собрать поисковые подсказки из Яндекс, Google или YouTube
Зарегистрироваться
Что такое Яндекс Вордстат простыми словами, зачем он нужен и как его правильно использовать
Яндекс Wordstat – это бесплатный инструмент для определения популярности поисковых запросов – незаменимый помощник seo-специалистов, маркетологов, рекламщиков, аналитиков всех мастей, социологов, филологов и многих других специалистов.
Ссылка: https://wordstat.yandex.ru
Задумывался Яндекс Wordstat как инструмент для настройки контекстной рекламы, но используется всеми подряд, по большей части – seo-специалистами для сбора семантики.
Результат использования Вордстата – список запросов с количеством показов этих запросов в месяц. Нюанс в том, что цифры (количество показов) – это прогноз показов, а не статистика показов за некий период. Впрочем, этот нюанс значим лишь в редких случаях; большинство тех, кто пользуется Вордстатом, используют его как историю показов тех или иных запросов.
Базовые возможности Вордстата на первый взгляд не слишком велики, однако, закрывают почти все необходимые нужды при работе с семантикой.
Данные, которые можно получить в Вордстате
- Частотности запросов (количество показов в месяц).
- Вариации запросов.
- Частотности запросов в определённых регионах (включая городки с населением в пару десятков тысяч человек).
- Сезонность запросов.
- Частотности запросов на разных устройствах (десктопные ПК, телефоны, планшеты или все мобильные устройства в целом (телефоны + планшеты)).
- Похожие запросы – не синонимы, а скорее похожие тематически, по интенту и по товарной группе.
 Например, у запроса «купить телефон» в похожих будут и «купить телевизор», и названия конкретных моделей, и названия магазинов, торгующих телефонами, и запросы о рассрочке.
Например, у запроса «купить телефон» в похожих будут и «купить телевизор», и названия конкретных моделей, и названия магазинов, торгующих телефонами, и запросы о рассрочке.
 Например, у запроса «купить телефон» в похожих будут и «купить телевизор», и названия конкретных моделей, и названия магазинов, торгующих телефонами, и запросы о рассрочке.
Например, у запроса «купить телефон» в похожих будут и «купить телевизор», и названия конкретных моделей, и названия магазинов, торгующих телефонами, и запросы о рассрочке.Дополнительные возможности Яндекс Wordstat
Как и в поиске Яндекса, в Wordstat можно использовать поисковые операторы, расширяющие возможности фильтрации и сортировки получаемых данных.
Операторы в Яндекс Вордстат – это набор сочетаний знаков препинания, с помощью которых можно ограничить количество слов в запросе, зафиксировать форму слова (падеж, окончания) или порядок слов в запросе, использовать стоп-слова (местоимения, предлоги и др.), отминусовать ненужные слова в запросах или сгруппировать нужные слова в сложных запросах.
Подробнее в Яндекс Справке — https://yandex.ru/support/direct/keywords/symbols-and-operators.html
KeyCollector
Конечно, учитывая огромные массивы данных, с которыми приходится работать всем, кто пользуется Вордстатом, не могли не появиться инструменты, для работы с этим сервисом.
Самый популярный из них – KeyCollector, способный как производить множество манипуляций с собранными из Wordstat (и не только) запросами: кластеризировать, определять сезонность, снимать позиции запросов в поисковых системах и т.п., так и собирать дополнительные данные, например, поисковые подсказки или статистику Яндекс Метрики.
Имеются и другие инструменты, от полноценных программ для парсинга до расширений для браузеров (Yandex Wordstat Assistant).
Альтернатива Яндекс Wordstat
Так как Яндекс в рунете не монополист на рынке поисковых услуг, у Google не может не быть аналогичного инструмента. У Google он называется keywordplanner и предназначен для того же – подбирать запросы для использования их в контекстной рекламе, Google AdWords (аналог Яндекс Директа).
При этом как альтернативу рассматривать инструменты Google нельзя – при работе с запросами следует понимать, что инструменты Яндекса и Google собирают только те данные, которые им доступны, то есть – только свои.
Для того, чтобы действительно понять покупательский и информационный спрос, маркетологам и seo специалистам следует использовать оба инструмента; и Яндекс, и Google способны показать лишь половина данных.
Другие термины интернет-маркетинга
Графический редактор Figma
Прототип сайта
Лиды
Редизайн сайта
SDAS — WordStat
Передовое программное обеспечение для анализа контента и извлечения текста с непревзойденными возможностями анализа.
Загрузите бесплатную пробную версию
Нужны ли вам инструменты анализа текста для быстрого извлечения тем и тенденций или тщательное и точное измерение с помощью современных инструментов количественного анализа контента. Полная интеграция WordStat с SimStat — нашим инструментом статистического анализа данных — QDA Miner — нашим программным обеспечением для качественного анализа данных — и Stata — комплексным статистическим программным обеспечением от StataCorp, дает вам беспрецедентную гибкость для анализа текста и сопоставления его содержимого со структурированной информацией, включая числовую.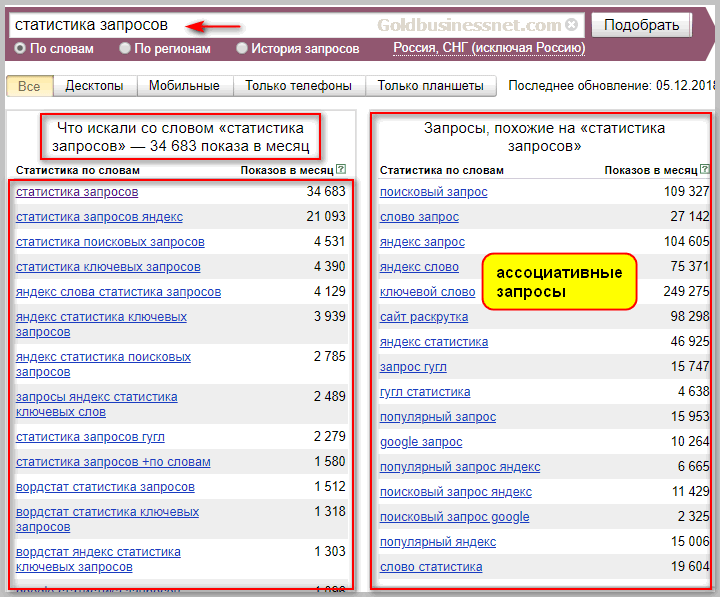 и категориальные данные.
и категориальные данные.
WordStat может использоваться всеми, кому необходимо быстро извлекать и анализировать информацию из больших объемов документов. Наше программное обеспечение для контент-анализа и анализа текста используется для:
- Контент-анализа открытых ответов, стенограмм интервью или фокус-групп
- Бизнес-аналитика и анализ конкурентных веб-сайтов
- Извлечение информации и обнаружение знаний из отчетов об инцидентах, жалоб клиентов
- Контент-анализ новостей или научной литературы
- Автоматическая маркировка и классификация документов
- Обнаружение мошенничества, установление авторства, патентный анализ
- Разработка и проверка таксономии
Исследование содержимого документа с помощью анализа текста
Анализ больших объемов неструктурированной информации с помощью WordStat. Программное обеспечение может обрабатывать 25 миллионов слов в минуту, быстро извлекать темы и автоматически определять закономерности, используя кластеризацию, многомерное масштабирование, диаграммы близости и многое другое.
Извлечение смысла с помощью режима проводника
Быстро и легко извлекайте смысл из больших объемов текстовых данных с помощью режима проводника, специально разработанного для тех, у кого мало опыта анализа текста. Одним щелчком мыши вы можете извлечь наиболее часто встречающиеся слова, фразы и самые важные темы в ваших документах.
Связывание текста со структурированными данными
Изучение отношений между неструктурированным текстом и структурированными данными, такими как даты, числа или категориальные данные, для выявления временных тенденций или различий между подгруппами или для оценки взаимосвязей с рейтингом или другими видами категориальных или числовых данных с помощью статистические и графические инструменты.
Основные темы
Получите краткий обзор наиболее важных тем из больших текстовых коллекций с помощью современных методов автоматического извлечения тем.
Исследуйте соединения
Исследуйте отношения между словами или понятиями и извлекайте текстовые сегменты, связанные с определенными соединениями.
Импорт
Импорт Word, Excel, HTML, XML, SPSS, Stata, NVivo, PDF-файлов, а также изображений. Подключайтесь и напрямую импортируйте данные из социальных сетей, электронной почты, платформ веб-опросов и инструментов управления ссылками.
Категоризация текстовых данных с помощью словарей
Добейтесь автоматизации полнотекстового анализа с помощью существующих словарей или создайте собственную модель категоризации со словами, фразами, правилами близости и т. д.
Уникальная помощь при создании словаря
Создавайте свой словарь быстрее с помощью инструментов для извлечения общих фраз и технических терминов, а также для быстрого выявления в вашей текстовой коллекции орфографических ошибок, синонимов, антонимов и родственных слов.
Картографирование ГИС
Связывайте неструктурированные текстовые данные с географической информацией и создавайте интерактивные графики точек данных, тематических карт и тепловых карт, а также веб-службу геокодирования для преобразования названий местоположений, почтовых индексов и IP-адресов в широту и долготу.
Экспорт
Легко экспортируйте результаты анализа текста в распространенные отраслевые форматы файлов, такие как Excel, SPSS, ASCII, HTML, XML, MS Word и графики, такие как PNG, BMP и JPEG.
Качественное кодирование
Объедините WordStat с современным инструментом качественного кодирования (QDA Miner) для более точного исследования данных или более глубокого анализа конкретных документов или извлеченных текстовых сегментов, когда это необходимо.
Категоризация текстовых данных с помощью машинного обучения
Разработка и оптимизация моделей автоматической классификации документов с использованием наивного байесовского метода и метода K-ближайших соседей.
Автоматическое извлечение именованных объектов
Автоматически извлекать именованные объекты, которые можно добавить в словарь категорий с помощью простой операции перетаскивания.
Возврат к исходному документу одним щелчком мыши
Проверьте или углубитесь в свой анализ, вернувшись к тексту практически любой функции, диаграммы или графика.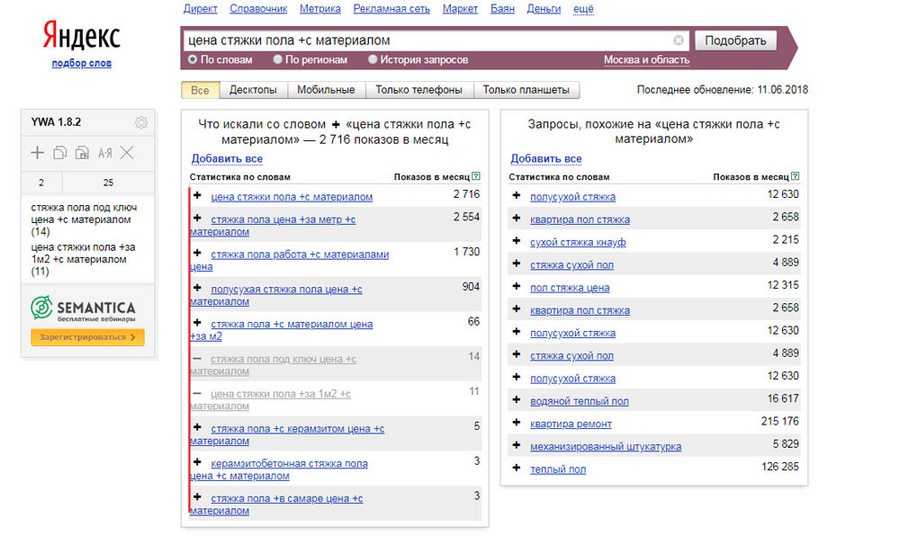 Вы можете использовать функции поиска ключевых слов или ключевых слов в контексте для поиска предложений, абзацев или целых документов.
Вы можете использовать функции поиска ключевых слов или ключевых слов в контексте для поиска предложений, абзацев или целых документов.
Преобразование текста с помощью скриптов Python
Используйте сценарий Python и полный набор библиотек с открытым исходным кодом для предварительной обработки или преобразования текстовых документов для анализа в WordStat.
Скачать бесплатную пробную версию
Купить WordStat
WordStat Отзывы и цены 2022
Аудитория
Организации, которым требуется программное обеспечение для контент-анализа и интеллектуального анализа текста для быстрой и точной обработки больших объемов неструктурированной информации.
О WordStat
WordStat — это гибкое и простое в использовании программное обеспечение для анализа текста — нужны ли вам инструменты анализа текста для быстрого извлечения тем и тенденций или тщательное и точное измерение с помощью современных инструментов количественного анализа контента.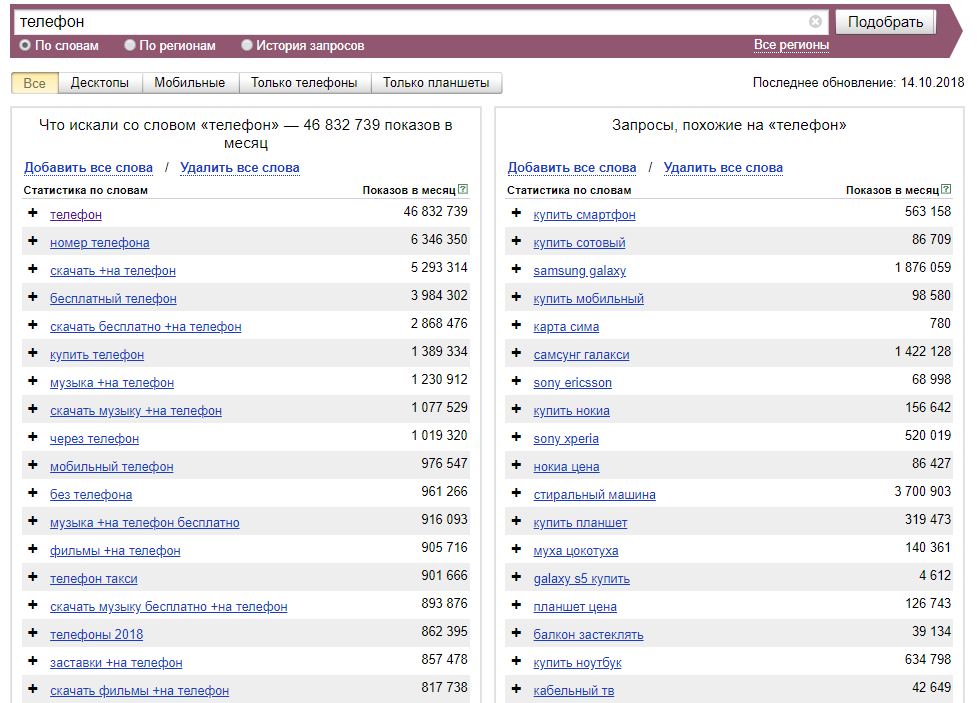 WordStat может использоваться всеми, кому необходимо быстро извлекать и анализировать информацию из больших объемов документов. Наше программное обеспечение для контент-анализа и интеллектуального анализа текста можно использовать во многих приложениях, таких как анализ открытых ответов, бизнес-аналитика, контент-анализ новостей, обнаружение мошенничества и многое другое. Полная интеграция WordStat с SimStat — нашим инструментом статистического анализа данных — QDA Miner — нашим программным обеспечением для качественного анализа данных — и Stata — комплексным статистическим программным обеспечением от StataCorp, дает вам беспрецедентную гибкость для анализа текста и сопоставления его содержимого со структурированной информацией, включая числовую. и категориальные данные.
WordStat может использоваться всеми, кому необходимо быстро извлекать и анализировать информацию из больших объемов документов. Наше программное обеспечение для контент-анализа и интеллектуального анализа текста можно использовать во многих приложениях, таких как анализ открытых ответов, бизнес-аналитика, контент-анализ новостей, обнаружение мошенничества и многое другое. Полная интеграция WordStat с SimStat — нашим инструментом статистического анализа данных — QDA Miner — нашим программным обеспечением для качественного анализа данных — и Stata — комплексным статистическим программным обеспечением от StataCorp, дает вам беспрецедентную гибкость для анализа текста и сопоставления его содержимого со структурированной информацией, включая числовую. и категориальные данные.
Интеграции
Нет перечисленных интеграций.
Рейтинги/отзывы
Общий
0,0 / 5
простота
0,0 / 5
Особенности
0,0 / 5
дизайн
0,0 / 5
поддерживать
0,0 / 5
Это программное обеспечение еще не проверено.