Содержание
Что такое парсеры и зачем они нужны — Журнал «Код»
07.07.2020
И как стащить с сайта что угодно.
Допустим, вы великий учёный и делаете научную работу: например, исследуете, как люди общаются в интернете. Или как пресса пишет на какую-то тему. Или как разные компании манипулируют статистикой. В общем, вам для работы нужен большой массив информации из интернета.
Вы могли бы дать задание своим лаборантам: «Ходите по этим сайтам и собирайте с них копипастом нужные данные». Не самый элегантный способ, но рабочий.
А можно вместо лаборантов посадить за это дело скрипт: он будет работать намного быстрее, а данных соберёт намного больше. Главное — обучить его правильному парсингу.
Что за парсинг
Парсинг — это когда вы берёте массив данных и раскладываете его на нужные вам составляющие. Например, берёте страницу товара в интернет-магазине и достаёте с неё цену.
Парсер — это программа, которая занимается парсингом по определённым правилам. На вход она получает данные или направление для поиска, и она среди них находит нужное и оформляет это, как нам надо.
На вход она получает данные или направление для поиска, и она среди них находит нужное и оформляет это, как нам надо.
Что можно парсить
Вытаскивать со страниц и собирать можно всё, что есть в интернете:
- каталоги товаров,
- данные из соцсетей,
- вакансии на досках объявлений,
- информацию конкурентов,
- ссылки на документацию.
Как утащить что угодно с любого сайта
Единственное, что нужно для парсинга, — это чтобы на сайт или сервис можно было зайти без регистрации. Или чтобы программа сама умела регистрироваться в них, чтобы потом спокойно забирать оттуда данные после авторизации.
Также полезно помнить, что многие сайты запрещают у себя парсинг и будут стараться технически его ограничить. Например, на «Авито» телефон покупателя выводится только после клика по кнопке, — это один из способов защитить ваши данные от парсинга.
Идеи для парсинга
Телеграм-бот, который каждое утро присылает вам прогноз погоды. Для этого он идёт на погодный сайт и парсит с него нужные данные.
Для этого он идёт на погодный сайт и парсит с него нужные данные.
Следильщик за ценой товара на сайте. Настраиваете его каждый день ходить на нужный сайт и смотреть, как меняется цена. Как только цена упадёт до нужного вам показателя, вам приходит уведомление.
Удалятель прилагательных из художественных произведений или подсвечивальщик ключевых слов. Например, настроили парсер, чтобы он находил в любом художественном тексте имена героев и глаголы. И получаете кривенькое, но читаемое краткое содержание произведения без описаний природы.
Информер для борьбы с угнетением: настраиваете парсер на ключевые слова, которые используются для угнетения чего-то, что близко вашему сердцу. Натравливаете парсер на форумы и сайты, где может случаться угнетение. Получаете список страниц, где происходит угнетение. Но не забывайте, что если вы натравили на что-то парсер, то это считается травлей.
Что дальше
Скоро мы попрактикуемся — напишем парсер, который будет брать с главной страницы нашего Кода названия всех статей и выводить их отдельным списком. Может, даже и ссылки к ним прикрутим.
Может, даже и ссылки к ним прикрутим.
Парсинг данных. Для чего нужны парсеры сайтов
Простое понятие «парсинга» — это извлечение необходимых данных с какого-либо источника информации. Средства для этого процесса и называют парсерами.
Что же обычно парсят?
Представьте, Вы открыли интернет-магазин товаров какого-нибудь бренда, у которого есть свой официальный сайт с тысячами наименований, но доступа к их базе нет и ассортимент в электронном виде они тоже не передают. Заносить все это вручную? На эту работу уйдут десятки человека-часов, что станет просто нерентабельным. Куда проще написать парсер, «натравить» его на этот сайт и за короткое время получить всю базу, и занести её в свой каталог. Все, весь контент готов. Можно парсить не только текстовую информацию, но и изображения и видео.
В свое время мы спарсили весь каталог бытовой техники и выложили его на сайты сервисов по ремонту, чем получили огромный низкочастотный трафик, ищущих ремонт или запчасти для конкретной модели.
Что еще парсят?
Очень простой ответ: все-что угодно. Например, цены. Очень важно знать цены конкурентов, чтобы предлагать свои. Благо, есть много агрегаторов товарных предложений, на которых публикуется сотни других интернет-магазинов. Брать цены для анализа – милое дело. Но, что делать, если товаров опять тысячи, а анализировать надо минимум раз в день?
На помощь опять приходят парсеры. Парсер создается под конкретную площадку и должен постоянно обновляться. Не верьте в существование универсальных программ, которые один раз купил и забыл.
Почему парсеры надо регулярно обновлять?
Помимо того, что шаблоны целевого сайта могут меняться, никто не хочет, чтобы их парсили. Дело даже не в том, что парсинг создает дополнительную нагрузку, а в том, что каждый дорожит своим контентом и не хочет им делиться. Видя, что их контент начинают разбирать, реализуют всевозможные защиты. Например, если начать парсить Яндекс.Маркет, то уже через 5-10 страниц «нарвешься» на капчу (защиту от роботов, а парсер – и есть робот). Такие защиты надо как-то обходить. Использовать разные IP адреса, но для этого нужно иметь огромную подсеть, или анонимные прокси, которые очень быстро попадают в черные списки. Либо интегрировать парсеры с сервисами автоматического распознавания капчи.
Такие защиты надо как-то обходить. Использовать разные IP адреса, но для этого нужно иметь огромную подсеть, или анонимные прокси, которые очень быстро попадают в черные списки. Либо интегрировать парсеры с сервисами автоматического распознавания капчи.
Нет ничего не возможного!
У нас работают настоящие хакеры сетевых протоколов, мы давно нашли решение парсить всё, в том числе и Яндекс.Маркет. Все уже давно просниффлено, даже защищенный протокол, на который давно перешли. В своих парсерах мы можем задавать запросы сотнями одновременно, не попадая ни под какие санкции.
Только Маркет? Нет, конечно!
С какими только задачами парсинга не обращались к нам клиенты. Например, брали данные у известных агрегаторов скидок по продуктовым и алкогольным предложениям. Для себя умеем сканировать выдачу поисковых систем для мониторинга позиций или анализа. Последнее, с чем работаем – это парсинг групп одной крупной социальной сети.
Вам необходимо заказать парсер сайта или иных данных? Обращайтесь. Для нас нет ничего невозможного! Мы предоставим как готовый парсер, так и любую разовую выгрузку в форматах XML, CSV, SQL или в любом другом по требованию.
Для нас нет ничего невозможного! Мы предоставим как готовый парсер, так и любую разовую выгрузку в форматах XML, CSV, SQL или в любом другом по требованию.
Все наши парсеры имеют:
- удобный интерфейс;
- стабильный функционал;
- фоновую работу над заданиями;
- пакетную многопоточную загрузку;
- масштабируемость.
Каждый парсер можно интегрировать с большинством CMS: Bitrix, Joomla, WordPress и любой другой, которая использует открытый формат хранения данных, например, СУБД MySQL. Если у Вас нет собственного сайта – воспользуйтесь нашей услугой по разработке сайтов. Мы используем собственную ELiTES CMS, которая не имеет никаких ограничений по конфигурации под задачи заказчика и расширяемая любыми необходимыми модулями.
Что такое разбор данных?
Вернуться к блогу
Сбор данных
Gabija Fatenaite
2021-09-13
Если вы работаете с разработкой (будь то часть команды или работаете в компании, где вам нужно часто общаться с технической командой), вы, скорее всего, столкнетесь с термином анализ данных. Проще говоря, это процесс преобразования одного формата данных в другой, более читаемый формат данных. Но это довольно простое объяснение.
Проще говоря, это процесс преобразования одного формата данных в другой, более читаемый формат данных. Но это довольно простое объяснение.
В этой статье мы немного углубимся в то, что такое синтаксический анализ в программировании, и обсудим, является ли создание внутреннего анализатора данных более выгодным для бизнеса, или лучше купить решение для извлечения данных, которое уже выполняет синтаксический анализ. для тебя.
Что такое анализ данных?
Синтаксический анализ данных — широко используемый метод структурирования данных; таким образом, вы можете обнаружить множество различных описаний, пытаясь выяснить, что именно это такое. Чтобы упростить понимание этой концепции, мы дали ей простое определение.
Что такое разбор данных?
Анализ данных — это метод, при котором одна строка данных преобразуется в данные другого типа. Допустим, вы получаете данные в виде необработанного HTML, синтаксический анализатор возьмет указанный HTML и преобразует его в более удобочитаемый формат данных, который можно легко прочитать и понять.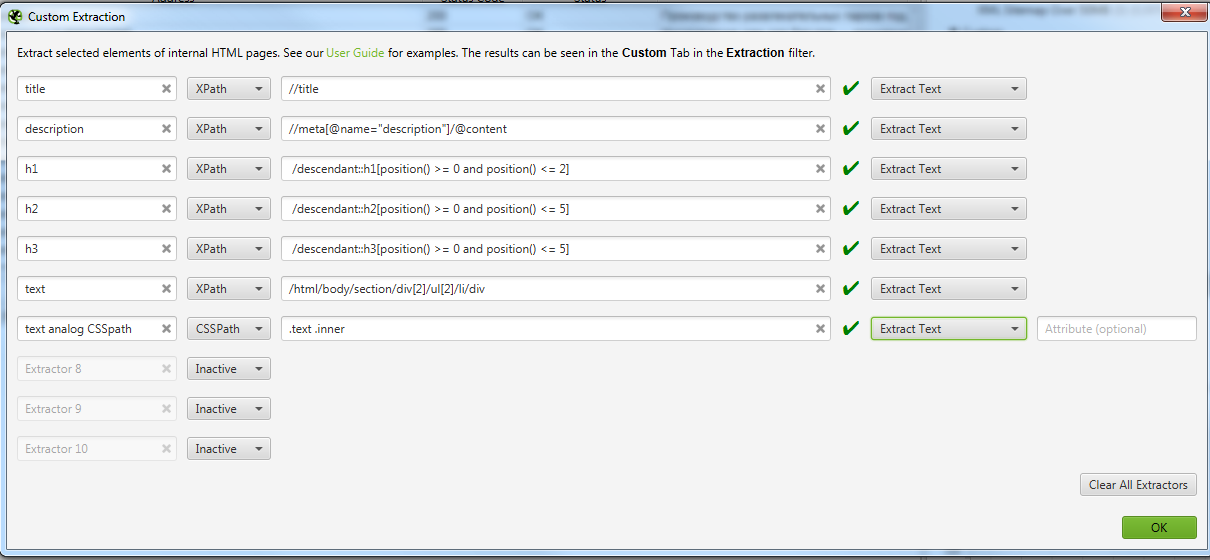
Что делает синтаксический анализатор?
Хорошо сделанный синтаксический анализатор определит, какая информация из строки HTML необходима, и в соответствии с заранее написанным кодом и правилами синтаксического анализатора выберет необходимую информацию и преобразует ее в JSON, CSV или таблицу, для пример.
Важно отметить, что сам парсер не привязан к формату данных. Это инструмент, который конвертирует один формат данных в другой, как он его конвертирует и во что, зависит от того, как был построен парсер.
Парсеры используются для многих технологий, включая:
Java и другие языки программирования
HTML и XML
Язык интерактивных данных и язык определения объектов
- другие языки баз данных и SQL0003
Языки моделирования
Языки сценариев
HTTP и другие интернет-протоколы
Строить или покупать?
Теперь, когда дело доходит до деловой стороны, можно задать себе отличный вопрос: «Должна ли моя техническая команда создать собственный синтаксический анализатор или мы должны просто отдать его на аутсорсинг?»
Как правило, дешевле изготовить собственный инструмент, чем покупать готовый. Однако ответить на этот вопрос непросто, и при принятии решения о строительстве или покупке следует учитывать гораздо больше вещей.
Однако ответить на этот вопрос непросто, и при принятии решения о строительстве или покупке следует учитывать гораздо больше вещей.
Давайте рассмотрим возможности и результаты обоих вариантов.
Создание анализатора данных
Допустим, вы решили создать собственный анализатор. Есть несколько явных преимуществ при принятии этого решения:
Парсер может быть чем угодно. Он может быть адаптирован для любой требуемой работы (анализа).
Обычно дешевле создать собственный парсер.
Вы контролируете любые решения, которые необходимо принимать при обновлении и обслуживании вашего парсера.
Но, как и во всем, всегда есть обратная сторона создания собственного синтаксического анализатора:
Вам потребуется нанять и обучить целую команду для создания синтаксического анализатора.
Обслуживание парсера необходимо — это означает больше внутренних расходов и используемых временных ресурсов.

Вам нужно будет купить и построить сервер, который будет достаточно быстрым, чтобы анализировать ваши данные с нужной вам скоростью.
Быть под контролем не обязательно легко или выгодно — вам нужно тесно сотрудничать с технической командой, чтобы принимать правильные решения, чтобы создать что-то хорошее, тратя много времени на планирование и тестирование.
Самостоятельное создание имеет свои преимущества, но требует много ресурсов и времени. Особенно, если вам нужно разработать сложный парсер для разбора больших объемов. Это потребует большего обслуживания и человеческих ресурсов, а также ценных человеческих ресурсов, потому что для его создания потребуется высококвалифицированная команда разработчиков.
Покупка анализатора данных
А как насчет покупки инструмента для анализа ваших данных? Начнем с преимуществ :
Вам не нужно будет тратить деньги на человеческие ресурсы, так как все будет сделано за вас, включая обслуживание парсера и серверов.
Любые возникающие проблемы будут решаться намного быстрее, так как люди, у которых вы покупаете инструменты, обладают обширными ноу-хау и знакомы с их технологиями.
Также менее вероятно, что синтаксический анализатор выйдет из строя или возникнут проблемы в целом, поскольку он будет протестирован и улучшен в соответствии с требованиями рынка.
Вы значительно сэкономите человеческие ресурсы и свое время, так как решение о том, как создать лучший парсер, будет приниматься аутсорсингом.

Конечно, есть несколько недостатков в покупке парсера:
Теперь кажется, что есть много преимуществ просто купить парсер. Но одна вещь, которая может упростить выбор, — это подумать о том, какой парсер вам понадобится. Опытный разработчик может сделать простой парсер примерно за неделю. Но если сложный, то на это могут уйти месяцы — это много времени и ресурсов.
Это также зависит от того, являетесь ли вы крупным бизнесом, у которого есть много времени и ресурсов для создания и обслуживания синтаксического анализатора. Или вы представляете небольшой бизнес, которому нужно что-то делать, чтобы иметь возможность расти на рынке.
Или вы представляете небольшой бизнес, которому нужно что-то делать, чтобы иметь возможность расти на рынке.
Как мы это делаем: Scraper API
Здесь, в Oxylabs, у нас есть набор инструментов для сбора данных — Scraper API. Эти инструменты специально созданы для крупномасштабной очистки поисковых систем и веб-сайтов электронной коммерции. Мы подробно рассказали, что такое Scraper API и как они работают, в одной из наших статей, поэтому обязательно ознакомьтесь с ней.
Наш встроенный синтаксический анализатор ежедневно обрабатывает довольно много данных. В феврале было сделано 12 миллиардов запросов! И это еще в феврале! Согласно нашей статистике за первый квартал 2019 года, общее количество запросов выросло на 7,02% по сравнению с четвертым кварталом 2018 года. И эти цифры продолжают расти в соответствии со вторым кварталом 2019 года.
Наша техническая команда работает над этим проектом уже несколько лет. , и имея такой большой опыт, мы можем с уверенностью сказать, что созданный нами парсер может обработать любой объем данных, который может быть запрошен.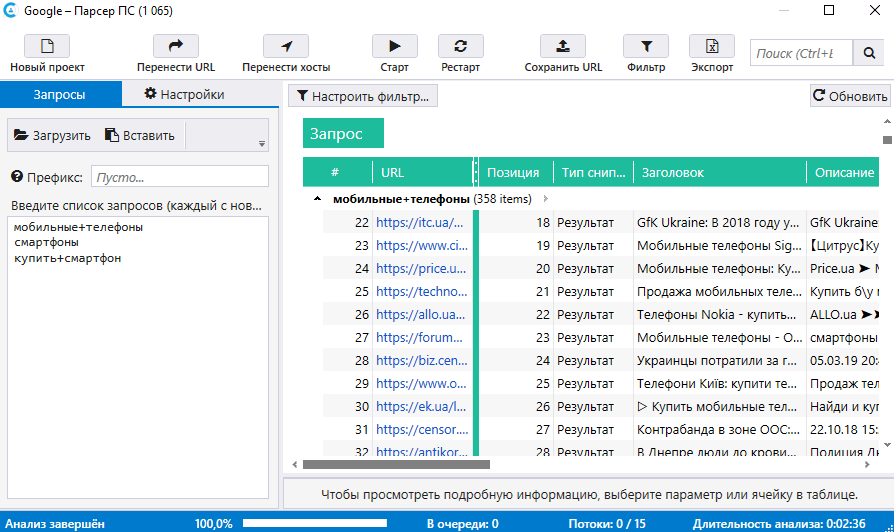
Итак, строить или покупать? Что ж, создание многолетнего опыта, доработок и обслуживания инструмента, который делает свою работу в совершенстве, — честно говоря, довольно дорого.
Подведение итогов
Надеюсь, теперь вы хорошо понимаете, что такое парсинг данных. Принимая все во внимание, имейте в виду, создаете ли вы очень сложный парсер или нет. Если вы анализируете большие объемы данных, вам потребуются хорошие разработчики в вашей команде для разработки и поддержки парсера. Но, если вам нужен менее сложный парсер меньшего размера, вероятно, лучше всего создать свой собственный. Вот практическое руководство о том, как читать и анализировать данные с помощью Python.
Также имейте в виду, если вы крупная компания с большим количеством ресурсов или небольшая компания, которой нужны правильные инструменты для поддержания своего роста.
Клиенты Oxylabs значительно увеличили свой рост благодаря нашим Scraper API! Если вы также ищете способы улучшить свой бизнес или у вас есть дополнительные вопросы об анализе данных, свяжитесь с нашей командой!
Люди также спрашивают
Какие инструменты необходимы для анализа данных?
После того, как инструменты веб-скрейпинга, такие как веб-скребок Python, предоставят необходимые данные, существует несколько вариантов анализа данных. BeautifulSoup и LXML — два часто используемых инструмента для анализа данных.
BeautifulSoup и LXML — два часто используемых инструмента для анализа данных.
Как пользоваться парсером данных?
К каждому инструменту анализа данных прилагается собственное руководство. Для большинства из них потребуются некоторые технические знания, такие как понимание Python и использование Python для очистки веб-страниц.
Что такое парсинг данных?
Сбор данных — это процесс получения больших объемов данных из Интернета с использованием автоматизации и чередующихся IP-адресов.
Об авторе
Габия Фатенайте
Ведущий менеджер по маркетингу продукции
Габия Фатенайте — ведущий менеджер по маркетингу продуктов в Oxylabs. Выросшая на видеоиграх и в Интернете, она с годами находила все более и более интересной техническую сторону вещей. Поэтому, если вы когда-нибудь захотите узнать больше о прокси (или видеоиграх), не стесняйтесь обращаться к ней — она будет более чем рада ответить вам.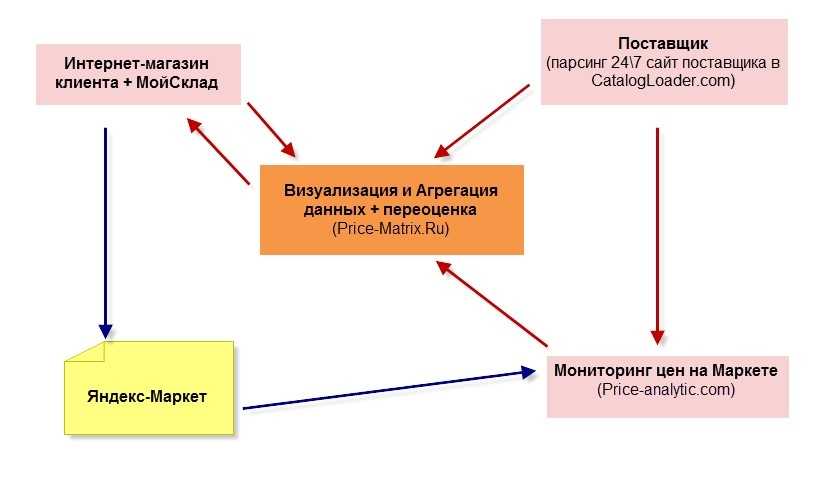
Узнать больше о Габии Фатенайте
Вся информация в блоге Oxylabs предоставляется на условиях «как есть» и только в информационных целях. Мы не делаем никаких заявлений и отказываемся от любой ответственности в отношении использования вами любой информации, содержащейся в блоге Oxylabs или любых сторонних веб-сайтах, ссылки на которые могут быть в нем. Прежде чем приступать к парсингу любого рода, вам следует проконсультироваться со своими юридическими консультантами и внимательно прочитать условия обслуживания конкретного веб-сайта или получить лицензию на парсинг.
Related articles
Tutorials
Data acquisition
Guide to Scraping Data from Websites to Excel with Web Query
Iveta Vistorskyte
2022-11-10
Tutorials
Data acquisition
Scrapers
Guide к Использование Google Таблиц для базового веб-скрейпинга
Vytenis Kaubre
2022-11-08
Учебные пособия
Сбор данных
Использование данных
Что такое конвейер ETL?
Даниэлюс Радавичюс
2022-10-14
Получайте последние новости из мира сбора данных
Меня интересует
В ЭТОЙ СТАТЬЕ
Что такое разбор данных?
Что делает синтаксический анализатор?
Строить или покупать?
Создание анализатора данных
Покупка анализатора данных
Как мы это делаем: Scraper API
Подведение итогов
Определение проанализированного с помощью бесплатного словаря
Parse
(Pärs)
против PARSED , PARS · ING , PARS · ES 63.
1.
а. Разбить (предложение) на составные части речи с объяснением формы, функции и синтаксических отношений каждой части.
б. Чтобы описать (слово), указав его часть речи, форму и синтаксические отношения в предложении.
в. Обрабатывать (лингвистические данные, такие как речь или письменный язык) в режиме реального времени, когда они произносятся или читаются, чтобы определить их языковую структуру и значение.
2.
а. Чтобы изучить внимательно или подвергнуть подробному анализу, особенно путем разбивки на компоненты: «Что мы упускаем, разбивая поведение шимпанзе на обычные категории, признанные в основном из нашего собственного поведения?» (Стивен Джей Гулд).
б. Чтобы понять; понять: я просто не мог разобрать, что вы только что сказали.
3. Компьютеры Для анализа или разделения (например, ввода) на более легко обрабатываемые компоненты.
v. вн.
Признать разборчивость: предложения, которые нелегко разобрать.
[Вероятно, от среднеанглийского pars, часть речи , от латинского pars (ōrātiōnis), часть (речи) ; см. perə- в индоевропейских корнях.]
pars′er сущ.
Словарь английского языка American Heritage®, пятое издание. Авторские права © 2016, издательство Houghton Mifflin Harcourt Publishing Company. Опубликовано издательством Houghton Mifflin Harcourt Publishing Company. Все права защищены.
parse
(pɑːz)
vb
1. (Грамматика) для присвоения составной структуры (предложению или словам в предложении)
2. (грамматика) ( intr ) (слова или языкового элемента) играть определенную роль в структуре предложения
3. (информатика) код компьютерной программы, чтобы убедиться, что она структурно правильна, прежде чем она будет скомпилирована и преобразована в машинный код
(информатика) код компьютерной программы, чтобы убедиться, что она структурно правильна, прежде чем она будет скомпилирована и преобразована в машинный код
[C16: от латинского pars ( orātionis ) часть (речи)]
ˈparsable adj
ˈparsing n
Collins English Dictionary – Complete and Unabridged, 12th Edition 2014 © HarperCollins Publishers 1991, 1994, 1998, 2000, 2003, 2006, 2007, 2009, 2011, 2014
parse
(pɑrs, pɑrz)
v. разбор, разбор. в.т.
1. анализировать (предложение) с точки зрения грамматических составляющих, определения частей речи, синтаксических отношений и т. д.
2. грамматически описывать (слово в предложении), определяя часть речи, форму словоизменения, синтаксическую функцию и т. д.
v.i.
3. признать анализируемым.
[1545–55; < латинское pars часть, как в pars ōrātiōnis часть речи]
parsʻa•ble, прил.
парсер, н.
Random House Словарь Kernerman Webster’s College Dictionary, © 2010 K Dictionaries Ltd. Copyright 2005, 1997, 1991, Random House, Inc. Все права защищены.
parse
Past participle: parsed
Gerund: parsing
ImperativePresentPreteritePresent ContinuousPresent PerfectPast ContinuousPast PerfectFutureFuture PerfectFuture ContinuousPresent Perfect ContinuousFuture Perfect ContinuousPast Perfect ContinuousConditionalPast Conditional
| Imperative |
|---|
| parse |
| parse |
| Present |
|---|
| I parse |
| you parse |
| he/she/it parses |
| we parse |
| you parse |
| they parse |
| Претеририт | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I Парсировал | |||||||||||||
| Вы пропокат | |||||||||||||
| HE/SESE PARSED | |||||||||||||
| HE/SESE PARSED | |||||||||||||
| WE/SESEDED | |||||||||||||
. 0439 0439 | |||||||||||||
| they parsed |
| Present Continuous |
|---|
| I am parsing |
| you are parsing |
| he/she/it is parsing |
| we are parsing |
| вы разбираете |
| они разбирают |
| настоящее совершенное |
|---|
| я проанализировал |
| he/she/it has parsed |
| we have parsed |
| you have parsed |
| they have parsed |
| Past Continuous |
|---|
| I was parsing |
| вы разбирали |
| он/она/оно разбирали |
| мы разбирали |
| вы разбирали |
| они разбирали 6 |
| Past Perfect |
|---|
| I had parsed |
| you had parsed |
| he/she/it had parsed |
| we had parsed |
| you had parsed |
| У них была пропорционала |
| Future |
|---|
| Я буду разбираться |
.
|