Содержание
Что такое парсеры и зачем они нужны — Журнал «Код»
07.07.2020
Зачем нужны парсеры
И как стащить с сайта что угодно.
medium
И как стащить с сайта что угодно.
Допустим, вы великий учёный и делаете научную работу: например, исследуете, как люди общаются в интернете. Или как пресса пишет на какую-то тему. Или как разные компании манипулируют статистикой. В общем, вам для работы нужен большой массив информации из интернета.
Вы могли бы дать задание своим лаборантам: «Ходите по этим сайтам и собирайте с них копипастом нужные данные». Не самый элегантный способ, но рабочий.
А можно вместо лаборантов посадить за это дело скрипт: он будет работать намного быстрее, а данных соберёт намного больше. Главное — обучить его правильному парсингу.
Что за парсинг
Парсинг — это когда вы берёте массив данных и раскладываете его на нужные вам составляющие. Например, берёте страницу товара в интернет-магазине и достаёте с неё цену.
Парсер — это программа, которая занимается парсингом по определённым правилам. На вход она получает данные или направление для поиска, и она среди них находит нужное и оформляет это, как нам надо.
Что можно парсить
Вытаскивать со страниц и собирать можно всё, что есть в интернете:
- каталоги товаров,
- данные из соцсетей,
- вакансии на досках объявлений,
- информацию конкурентов,
- ссылки на документацию.
Как утащить что угодно с любого сайта
Единственное, что нужно для парсинга, — это чтобы на сайт или сервис можно было зайти без регистрации. Или чтобы программа сама умела регистрироваться в них, чтобы потом спокойно забирать оттуда данные после авторизации.
Также полезно помнить, что многие сайты запрещают у себя парсинг и будут стараться технически его ограничить. Например, на «Авито» телефон покупателя выводится только после клика по кнопке, — это один из способов защитить ваши данные от парсинга.
Идеи для парсинга
Телеграм-бот, который каждое утро присылает вам прогноз погоды. Для этого он идёт на погодный сайт и парсит с него нужные данные.
Следильщик за ценой товара на сайте. Настраиваете его каждый день ходить на нужный сайт и смотреть, как меняется цена. Как только цена упадёт до нужного вам показателя, вам приходит уведомление.
Удалятель прилагательных из художественных произведений или подсвечивальщик ключевых слов. Например, настроили парсер, чтобы он находил в любом художественном тексте имена героев и глаголы. И получаете кривенькое, но читаемое краткое содержание произведения без описаний природы.
Информер для борьбы с угнетением: настраиваете парсер на ключевые слова, которые используются для угнетения чего-то, что близко вашему сердцу. Натравливаете парсер на форумы и сайты, где может случаться угнетение. Получаете список страниц, где происходит угнетение. Но не забывайте, что если вы натравили на что-то парсер, то это считается травлей.
Что дальше
Скоро мы попрактикуемся — напишем парсер, который будет брать с главной страницы нашего Кода названия всех статей и выводить их отдельным списком. Может, даже и ссылки к ним прикрутим.
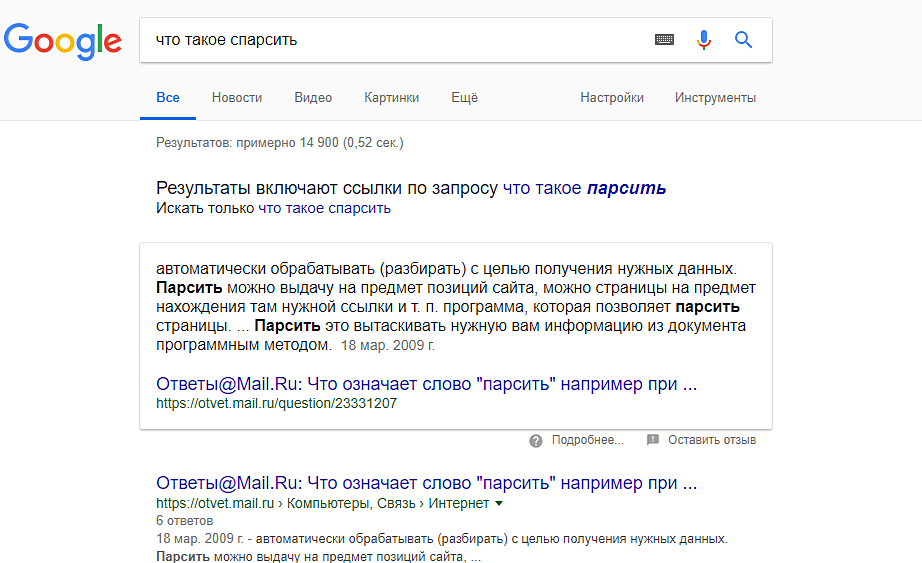
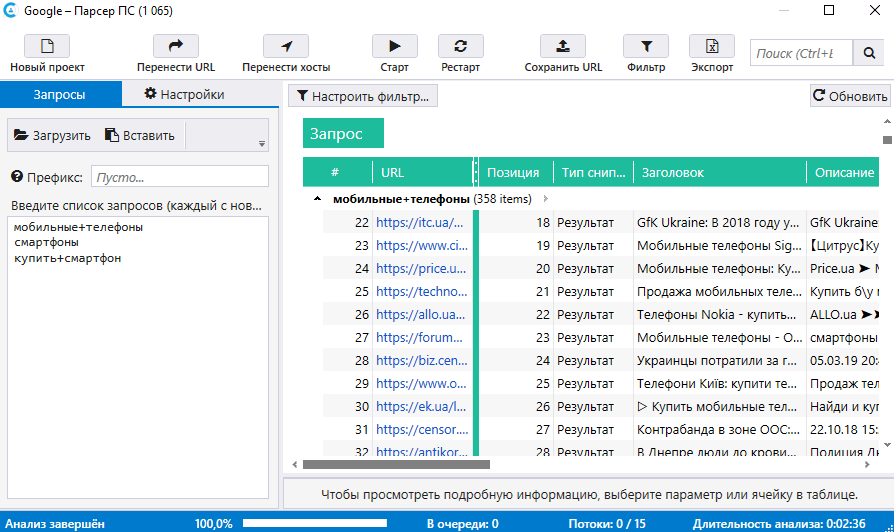
10 инструментов, позволяющих парсить информацию с сайтов, включая цены конкурентов и правовая оценка — Сервисы на vc.ru
Инструменты web scraping (т.е. парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти инструменты нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копи-пастинга. Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте OZON.RU.
18 680
просмотров
Ниже рассмотрим варианты использования инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов.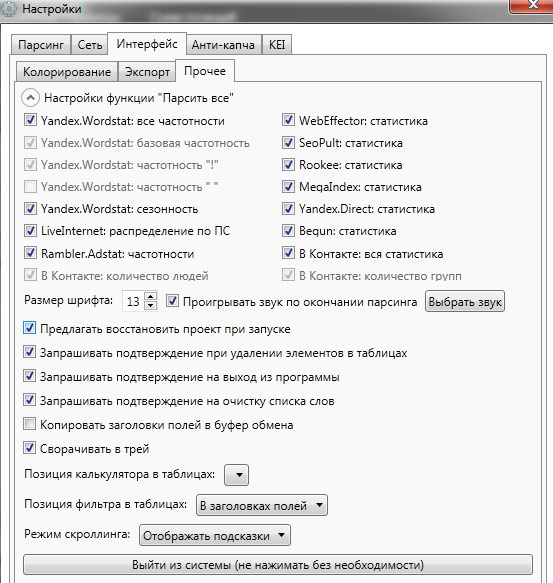 Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим краткую правовую оценку парсинга в России.
Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим краткую правовую оценку парсинга в России.
Важно заранее упомянуть, что нахождение частной информации даже в открытом виде на одних сайтах не даёт однозначного права использовать эти данные третьими лицами. Но правовую основу парсинга рассмотрим более подробно в конце данной статьи.
Цели парсинга
1. Сбор данных для исследования рынка. Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации. Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow. С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников. Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.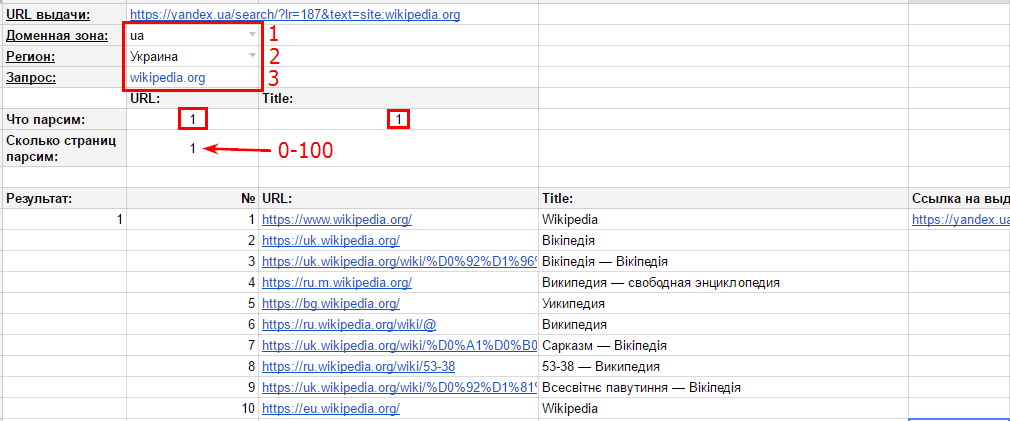
5. Отслеживание цен в разных магазинах. Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.
В обзор ниже не попал наш сервис парсинга сайтов и последующего мониторинга цен, который в основном ориентирован на так называемый full-site web scraping (парсинг всего сайта). В отличии от инструментов ниже мы просто ежедневно отдаем «слепок» сайта в формате CSV/Excel для последующего анализа (ассортимент и цены), а инструменты ниже требуют некоторых усилий и подойдут для тех, кто готов «поработать руками» и кому нужна гибкость в парсинге.
10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
1. Import.io
Import.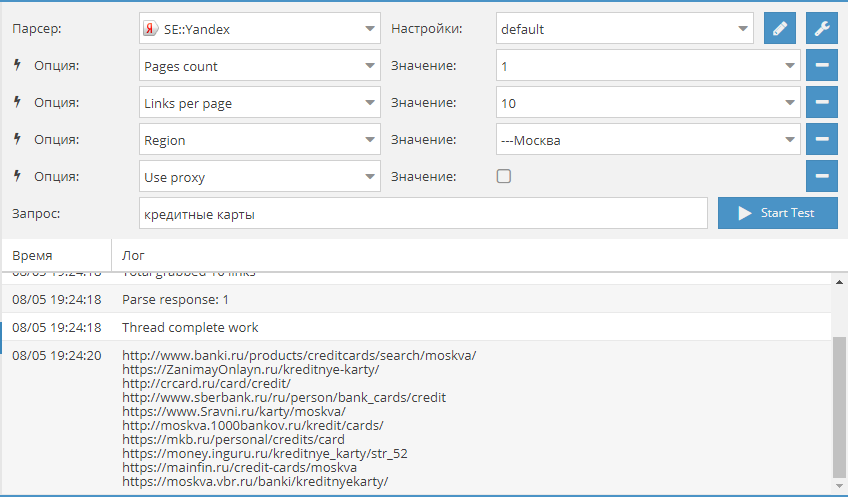 io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
import.io
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.
Webhose.io
Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape способен парсить информацию с любого веб-сайта и не требует загрузки дополнительных приложений, как и Webhose. Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.
Dexi.io
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.
Scrapinghub
Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
5. ParseHub
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.
Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.
ParseHub
ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
VisualScraper
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
7. Spinn3r
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
Spinn3r
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
8. 80legs
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.
Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.
80legs
Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
9. Scraper
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
Scraper
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
OutWit Hub
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
И самое главное — правомерность парсинга в России?
Ниже мы привели краткую выдержку из заключения наших юристов. Сразу отметим, что будет опубликована еще одна статья, где правовой вопрос парсинга будет рассмотрен более детально, а сейчас приводим информацию для тех, кто сразу хочет воспользоваться перечисленными выше инструментами!
Сразу отметим, что будет опубликована еще одна статья, где правовой вопрос парсинга будет рассмотрен более детально, а сейчас приводим информацию для тех, кто сразу хочет воспользоваться перечисленными выше инструментами!
Итак, вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что им не запрещено.
Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство, а законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах. Иными словами — вы можете парсить информацию, а вот ее дальнейшее использование может быть (а может и не быть) ограничено авторским правом!
2. Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет. Иными словами, вы не занимаетесь взломом и DDoS атакой.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции (к слову, мониторинг цен, как следствие парсинга, только повышает конкуренцию :).
При соблюдении установленных ограничений парсинг является законным!
parsingtheory
Компиляторам нужно разобрать. Парсер — это всего лишь код, поэтому, чтобы его создать, мы могли бы просто запустить его. Но теория помогает нам понять синтаксический анализ на более глубоком уровне, позволяя нам писать более качественные, быстрые и доказуемые корректные синтаксические анализаторы. Давай учить!
Что такое синтаксический анализ?
Синтаксический анализ — это процесс раскрытия вывода или дерева вывода строки из грамматики.
Например, учитывая грамматику:
$\begin{array}{lcl}
\mathit{pal} & \longrightarrow & (\texttt{«a»}\;|\;\texttt{«b»}\;|\;\texttt{«a»}\;\mathit{pal}\; \texttt{«a»}\;|\;\texttt{«b»}\;\mathit{pal}\;\texttt{«b»})? \\
\end{массив}$
мы разбираем строку $abbba$ в дерево вывода:
приятель
/ | \
/ | \
приятель
/ | \
/ | \
б приятель б
|
|
б
В реальном языке программирования мы обычно не создаем дерево вывода для каждого символа в исходной программе. Вместо этого мы сначала группируем символы в токенов и рассматриваем жетоны как символы.
Вместо этого мы сначала группируем символы в токенов и рассматриваем жетоны как символы.
TODO
Предварительная обработка исходной программы с помощью токенизации настолько распространена, настолько естественна и настолько важна, что существует своего рода отдельная (более простая) теория и практика, которая занимается этим, называемая лексический анализ. Давайте кратко поговорим об этом, прежде чем углубляться в более богатую теорию синтаксического анализа.
Лексический анализ
Токенизация или лексический анализ — это процесс формирования токенов из потока символов исходного кода. Вы в основном просматриваете поток символов посимвольно, пропуская пробелы и комментарии и собирая символы в токены. Иногда вам может понадобиться немного «заглянуть вперед» или «вернуться назад», когда вы проходите через поток символов.
Как правило, каждый токен имеет тип, лексему, позицию в строке и столбце. Типы токенов включают:
- ключевое слово
- идентификатор
- числовой литерал
- строковый литерал
- пунктуация
Лексическая грамматика является частью спецификации языка, которая показывает, как токены формируются из символов. Отрицательный взгляд вперед — обычное дело! Примером может быть:
Отрицательный взгляд вперед — обычное дело! Примером может быть:
TODO
Иногда людям полезно визуализировать, как лексер работает через конечные автоматы:
TODO
Возможно написание лексера вручную. Для простой лексической грамматики, показанной выше, самодельный лексер может быть:
TODO
В общем, лексеры занимаются такими проблемами, как:
- Чувствительность к регистру (или нечувствительность)
- Являются ли пробелы значащими
- Является ли символ новой строки значащим
- Можно ли вкладывать комментарии
Ошибки, которые могут возникнуть во время сканирования, называется лексические ошибки включают:
- Встречи символов, не входящих в алфавит языка
- Слишком много символов в слове или строке (да, такие языки существуют!)
- Незакрытый символ или строковый литерал
- Конец файла в комментарии
После написания и развертывания лексера вы можете полностью работать с потоками токенов. Синтаксический анализ теперь работает полностью на уровне грамматики фраз. Работа синтаксического анализатора состоит в том, чтобы раскрыть дерево вывода или дерево синтаксического анализа, листья которого теперь являются токенами, а не символами.
Синтаксический анализ теперь работает полностью на уровне грамматики фраз. Работа синтаксического анализатора состоит в том, чтобы раскрыть дерево вывода или дерево синтаксического анализа, листья которого теперь являются токенами, а не символами.
Подходы к синтаксическому анализу
Синтаксис языка обычно определяется с помощью CFG (или столь же мощных BNF, EBNF, Syntax Diagram) или PEG. Компилятор использует грамматику для синтаксического анализа последовательности токенов, то есть , чтобы определить, может ли строка токенов быть сгенерирована грамматикой, и создать синтаксическое дерево для последовательности токенов . Люди изучают синтаксический анализ десятилетиями! Вот некоторые вещи, которые они выяснили:
- Контекстная чувствительность слишком сложна. Отделите его. Просто сосредоточьтесь на контекстно-свободных частях языка в синтаксическом анализаторе. 93)$ время. Это слишком медленно. Возможно, нам следует искать ограниченные CFG, которые можно анализировать более эффективно.

- Есть! Люди выяснили и определили классы грамматик $LL$ и грамматик $LR$! Это ограниченные CFG, которые можно разобрать за время $\Theta(n)$. Убей!
- С середины 20-го века вокруг методов синтаксического анализа грамматик $LL$ и $LR$ было создано огромное количество теории. Механизмы $LL$ просты, но класс языков $LL$ намного меньше, чем класс $LR$. Но методы $LR$ действительно сложны для понимания и не предназначены для человеческого понимания.
- вышли на сцену в 2004 году и просто потрясающие! Они немного отличаются от CFG. Их можно разобрать за линейное время с помощью парсера packrat, но за счет большого дополнительного пространства. Ом добавляет некоторую мощность PEG (левая рекурсия), так что вы можете столкнуться со сверхлинейным временем разбора.
Колышки
Это хорошая справочная информация для начала изучения синтаксического анализа. Но подождите, во-первых, что означают $LL$ и $LR$?
- $LL(k)$ Грамматика
- Грамматика, которую можно использовать для управления самым левым выводом
читая ввод слева направо, просматривая только следующие $k$
символы и никогда не резервное копирование. - $LR(k)$ Грамматика
- Грамматика, которую можно использовать для получения самого правого вывода
читая ввод слева направо, просматривая только следующие $k$
символы и никогда не резервное копирование.
Эм, а есть более практические описания этих языковых курсов? Довольно много, да. Попробуйте эти:
- $LL(k)$
- Найдите все «точки выбора» в грамматике (их легко найти на эквивалентной синтаксической диаграмме). Определите максимальное количество жетонов, $k$, необходимое, чтобы точно знать, по какому пути следует пройти через все точки выбора. Если $k$ конечно, то это грамматика LL(k).
- $LR(k)$
- Набор языков $LR$ в точности эквивалентен набору языков, распознаваемых DPDA. Языки $LR$ — это в точности DCFL. Грамматика $LR(k)$ — это CFG для языка, являющегося DCFL.
Информационный бюллетень $LL$ и $LR$:
| Грамматика LL | Грамматика LR |
|---|---|
|
|
Вау! Это было много.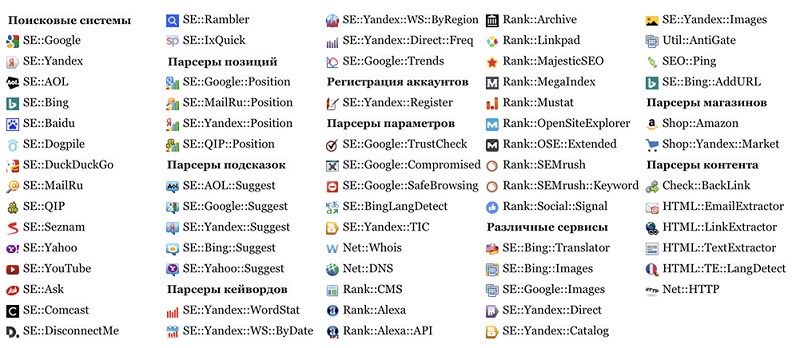 Приходят подробности. Читай дальше.
Приходят подробности. Читай дальше.
Упражнение . Почему грамматика с левой рекурсией не может быть LL(k) для любого k?
Упражнение : Дополнительные сведения о $LL$ и $LR$ см. в этой статье BNF с небольшим разделом, посвященным синтаксическому анализу.
Рекурсивный спуск
Анализ на основе таблиц
Анализ грамматик выражений
PEG предназначены для прямого анализа: нет необходимости «извлекать» какие-либо машины. Процесс сопоставления встроен в правила грамматики.
TODO
Рекомендуем прочитать:
- Статья из Википедии
- Оригинал статьи Брайана Форда
- Краткий пост в блоге о CFG и PEG
- Использование производных ПЭГ (Документ, в котором указана огромная ошибка в оригинальной статье Форда)
- Документ 2014 г., касающийся CFG и PEG
- Документ 2020 г. о вычислительной мощности ПЭГ
Реальные проблемы
Разработчик языка должен учитывать любые неясности в описании языка. Например, в C выражение
Например, в C выражение (x)-y имеет две разные синтаксические интерпретации: если x относится к типу, тогда это слепок отрицания, иначе это вычитание. Вы не можете сказать на этом этапе.
Ошибки, возникающие при синтаксическом анализе, называемые синтаксическими ошибками , возникают из-за искаженных последовательностей токенов, таких как:
-
j = 4 * (6 − x; -
i = /5 -
42 = х * 3
TODO: несинтаксические ошибки
Ресурсы
Резюме
Мы рассмотрели:
- Что такое синтаксический анализ
- Лексический и синтаксический анализы
- Различные подходы к синтаксическому анализу
- Метод рекурсивного спуска
- Синтаксический анализ на основе контекстно-свободных грамматик
- Много о синтаксическом анализе грамматики выражений ars
- Где узнать больше
Что такое разбор данных?
Прокси-серверы
Соединенные Штаты Америки
Великобритания
Япония
Канада
Германия
Посмотреть все офисы
Статус в сетиКарьера
Вернуться в блог
Сбор данных
Габия Фатенайте
13. 09.2021
09.2021
5 мин чтения 9000 3
Если вы работаете с разработкой (независимо от того, являетесь ли вы частью команды или работаете в компании, где вам нужно часто общаться с технической командой), вы, скорее всего, столкнетесь с термином парсинг данных. Проще говоря, это процесс преобразования одного формата данных в другой, более читаемый формат данных. Но это довольно простое объяснение.
В этой статье мы немного углубимся в то, что такое синтаксический анализ в программировании, и обсудим, является ли создание внутреннего анализатора данных более выгодным для бизнеса, или лучше купить решение для извлечения данных, которое уже делает разбор для вас.
Что такое анализ данных?
Анализ данных — широко используемый метод структурирования данных; таким образом, вы можете обнаружить множество различных описаний, пытаясь выяснить, что именно это такое. Чтобы упростить понимание этой концепции, мы дали ей простое определение.
Что такое разбор данных?
Анализ данных — это метод, при котором одна строка данных преобразуется в данные другого типа.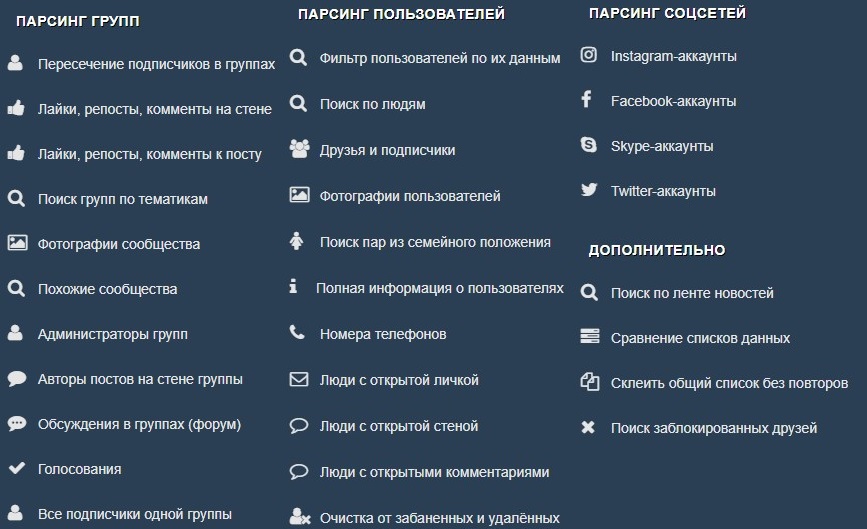 Допустим, вы получаете данные в виде необработанного HTML, синтаксический анализатор возьмет указанный HTML и преобразует его в более удобочитаемый формат данных, который можно легко прочитать и понять.
Допустим, вы получаете данные в виде необработанного HTML, синтаксический анализатор возьмет указанный HTML и преобразует его в более удобочитаемый формат данных, который можно легко прочитать и понять.
Что делает синтаксический анализатор?
Хорошо сделанный синтаксический анализатор определит, какая информация из строки HTML необходима, и в соответствии с заранее написанным кодом и правилами синтаксического анализатора выберет необходимую информацию и преобразует ее в JSON, CSV или таблицу, для пример.
Важно отметить, что сам парсер не привязан к формату данных. Это инструмент, который конвертирует один формат данных в другой, как он его конвертирует и во что, зависит от того, как был построен парсер.
Парсеры используются во многих технологиях, включая:
Java и другие языки программирования
HTML и XML
Язык интерактивных данных и язык определения объектов
9003 8
SQL и другие языки баз данных
Языки моделирования
Языки сценариев
HTTP и другие интернет-протоколы
Строить или покупать?
Теперь, когда дело доходит до деловой стороны, можно задать себе отличный вопрос: «Должна ли моя техническая команда создать собственный синтаксический анализатор или мы должны просто отдать его на аутсорсинг?»
Как правило, дешевле изготовить собственный инструмент, чем покупать готовый. Однако ответить на этот вопрос непросто, и при принятии решения о строительстве или покупке следует учитывать гораздо больше вещей.
Однако ответить на этот вопрос непросто, и при принятии решения о строительстве или покупке следует учитывать гораздо больше вещей.
Давайте рассмотрим возможности и результаты обоих вариантов.
Создание анализатора данных
Допустим, вы решили создать собственный анализатор. Есть несколько явных преимуществ при принятии этого решения:
Парсер может быть чем угодно. Он может быть адаптирован для любой требуемой работы (анализа).
Обычно дешевле создать собственный парсер.
Вы контролируете любые решения, которые необходимо принимать при обновлении и обслуживании вашего парсера.
Но, как и во всем, всегда есть обратная сторона создания собственного синтаксического анализатора:
Вам потребуется нанять и обучить целую команду для создания синтаксического анализатора.
Обслуживание парсера необходимо, что означает больше внутренних расходов и используемых временных ресурсов.
Вам нужно будет купить и построить сервер, который будет достаточно быстрым, чтобы анализировать ваши данные с нужной вам скоростью.
Быть под контролем не обязательно легко или выгодно — вам нужно тесно сотрудничать с технической командой, чтобы принимать правильные решения, чтобы создать что-то хорошее, тратя много времени на планирование и тестирование.
Самостоятельное создание имеет свои преимущества, но требует много ресурсов и времени. Особенно, если вам нужно разработать сложный парсер для разбора больших объемов. Это потребует большего обслуживания и человеческих ресурсов, а также ценных человеческих ресурсов, потому что для его создания потребуется высококвалифицированная команда разработчиков.
Покупка анализатора данных
А как насчет покупки инструмента для анализа ваших данных? Начнем с преимуществ :
Вам не нужно будет тратить деньги на человеческие ресурсы, так как все будет сделано за вас, включая обслуживание парсера и серверов.
Любые возникающие проблемы будут решаться намного быстрее, так как люди, у которых вы покупаете инструменты, обладают обширными ноу-хау и знакомы с их технологиями.
Также менее вероятно, что синтаксический анализатор выйдет из строя или возникнут проблемы в целом, поскольку он будет протестирован и улучшен в соответствии с требованиями рынка.
Вы значительно сэкономите человеческие ресурсы и свое время, так как решение о том, как создать лучший парсер, будет приниматься аутсорсингом.
Конечно, есть несколько недостатков в покупке парсера:
Теперь кажется, что есть много преимуществ просто купить парсер. Но одна вещь, которая может упростить выбор, — это подумать о том, какой парсер вам понадобится. Опытный разработчик может сделать простой парсер примерно за неделю. Но если сложный, то на это могут уйти месяцы — это много времени и ресурсов.
Это также зависит от того, являетесь ли вы крупным бизнесом, у которого есть много времени и ресурсов для создания и обслуживания синтаксического анализатора. Или вы представляете небольшой бизнес, которому нужно что-то делать, чтобы иметь возможность расти на рынке.
Или вы представляете небольшой бизнес, которому нужно что-то делать, чтобы иметь возможность расти на рынке.
Как мы это делаем: Scraper API
Здесь, в Oxylabs, у нас есть набор инструментов для сбора данных — Scraper API. Эти инструменты специально созданы для крупномасштабной очистки поисковых систем и веб-сайтов электронной коммерции. Мы подробно рассказали, что такое Scraper API и как они работают, в одной из наших статей, поэтому обязательно ознакомьтесь с ней.
Наш встроенный синтаксический анализатор ежедневно обрабатывает довольно много данных. В феврале было сделано 12 миллиардов запросов! И это еще в феврале! Согласно нашей статистике за первый квартал 2019 года, общее количество запросов выросло на 7,02% по сравнению с четвертым кварталом 2018 года. И эти цифры продолжают расти в соответствии со вторым кварталом 2019 года.
Наша техническая команда работает над этим проектом уже несколько лет. , и имея такой большой опыт, мы можем с уверенностью сказать, что созданный нами парсер может обработать любой объем данных, который может быть запрошен.
Итак, строить или покупать? Что ж, создание многолетнего опыта, доработок и обслуживания инструмента, который делает свою работу в совершенстве, — честно говоря, довольно дорого.
Подведение итогов
Надеюсь, теперь вы хорошо понимаете, что такое парсинг данных. Принимая все во внимание, имейте в виду, создаете ли вы очень сложный парсер или нет. Если вы анализируете большие объемы данных, вам потребуются хорошие разработчики в вашей команде для разработки и поддержки парсера. Но, если вам нужен менее сложный парсер меньшего размера, вероятно, лучше всего создать свой собственный. Вот практическое руководство о том, как читать и анализировать данные с помощью Python.
Также помните, если вы крупная компания с большим количеством ресурсов или небольшая компания, которой нужны правильные инструменты для поддержания роста.
Клиенты Oxylabs значительно увеличили свой рост благодаря нашим Scraper API! Если вы также ищете способы улучшить свой бизнес или у вас есть дополнительные вопросы об анализе данных, свяжитесь с нашей командой!
Люди также спрашивают
Какие инструменты необходимы для анализа данных?
После того, как инструменты веб-скрейпинга, такие как веб-скребок Python, предоставят необходимые данные, существует несколько вариантов анализа данных.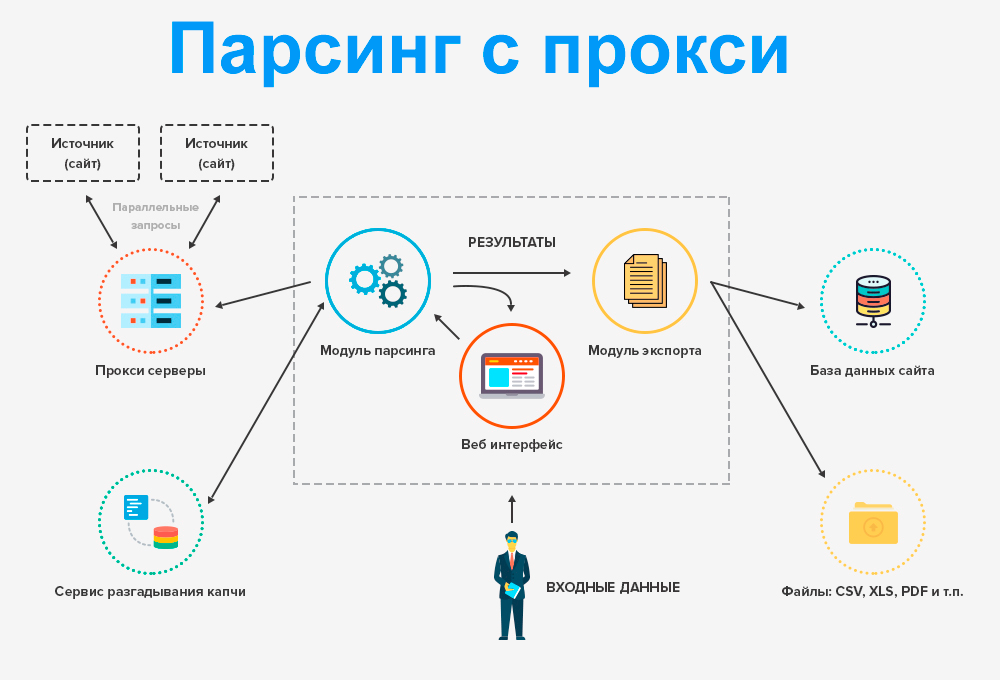 BeautifulSoup и LXML — два часто используемых инструмента для анализа данных.
BeautifulSoup и LXML — два часто используемых инструмента для анализа данных.
Как пользоваться парсером данных?
К каждому инструменту анализа данных прилагается собственное руководство. Для большинства из них потребуются некоторые технические знания, такие как понимание Python и использование Python для очистки веб-страниц.
Что такое парсинг данных?
Сбор данных — это процесс получения больших объемов данных из Интернета с использованием автоматизации и чередующихся IP-адресов.
Об авторе
Габия Фатенайте
Ведущий менеджер по маркетингу продукции
Габия Фатенайте — ведущий менеджер по маркетингу продуктов в Oxylabs. Выросшая на видеоиграх и в Интернете, она с годами находила все более и более интересной техническую сторону вещей. Поэтому, если вы когда-нибудь захотите узнать больше о прокси (или видеоиграх), не стесняйтесь обращаться к ней — она будет более чем рада ответить вам.