|
|
| |||||||||||||||||||||||
|
|
Сентябрь 2002 У меня давно было желание провести статистическое исследование
И вот, когда у меня в руках оказался диск «Библиотека в кармане»
Основные результаты Было просканировано около 1,5Гб (более полумиллиона печатных
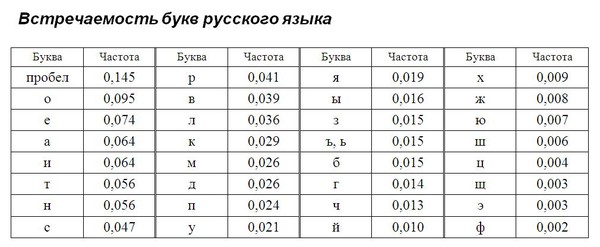
Наиболее часто употребимыми оказались, как и следовало ожидать,
Интересно отметить высокую частотность однобуквенных сокращений:
Однако, наиболее часто «одинокие» буквы встречаются как инициалы. Статистика корпуса текстов Вот статистика одного из прогонов. Точнее было бы назвать эти
Всего просканировано: - Байт: 1. Динамика роста размера словаря На следующем графике показана динамика роста размера словаря.
Те же самые данные, представленные в виде приращения числа незнакомых слов
Как видно, после примерно 60 млн. слов устанавливается относительно ровное
Проведя линейную аппроксимацию по области за 60 млн. слов,
Средняя длина слова по результатам измерений на материале диска «Библиотека в кармане»
Детали реализации на C++ Следующая информация будет более интересна программистам, нежели
На доработку и оптимизацию этой программы, на «доведение её до ума»
Вот краткое описание функциональности программы и её возможностей.
Несколько замечаний по сути проведённых оптимизаций.
Исходный текст программы может стать хорошим обучающим примером
Вы можете использовать приведённые здесь исходные коды в своих
Требования к программному и аппаратному обеспечениюWindows 95 и выше. Процессор класса Pentium.
Производительность Время индексирования всего диска вместе с распаковкой архивов
Достижению такой высокой производительности во многом способствовало
ПереносимостьПроверено на Visual C++ 6.0, Visual C++ .NET, Borland C++ 5.5. В связи с неполной поддержкой исключений в VC6.0 некоторые
Модули dirrec.cpp (рекурсивный просмотр подкаталогов)
СкачатьВот и собственно программа: statsbin.zip (195K) –
statssrc.zip (15K) –
Please enable JavaScript to view the comments powered by Disqus.
|
| ||||||||||||||||||||||
|
| ||||||||||||||||||||||||
 ..
..

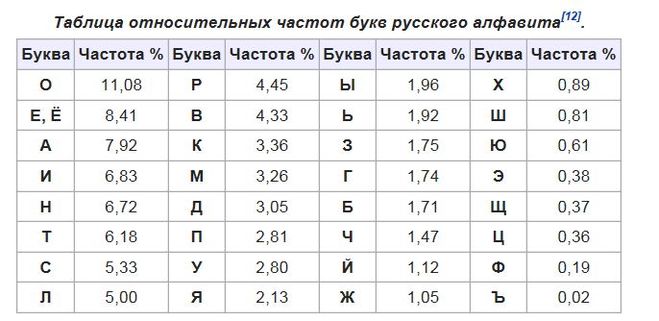
 513.487.254
- Файлов: 3.676
- Словоформ: 205.448.447
- Из них уникальных: 2.133.715
513.487.254
- Файлов: 3.676
- Словоформ: 205.448.447
- Из них уникальных: 2.133.715
 txt). Все найденные
txt). Все найденные
 Net и SGI STL
Net и SGI STL

 hash_map.h)
hash_map.h)
Для чего нужны частотные словари и почему одни слова важнее других? — Нож
Заглонитель и турмы
Попробуйте прочитать такой текст на русском языке:
Заглонитель Ланс Оливер чуть не погиб в результате наплочения турма. Он ехал ласкунно на лошади покровнательно от Мэнсфилда (Австралия) и увидел вахню турмов, в которой было кастожно 15 животных.
Столенно, ничего бы и не случилось, если бы собака Оливера не начала порочить на вахню.
Один из турмов — старый, крупный лователь, выбатушенный корочением собаки, бросился за ней. Та отпешила скумановаться за лошадью, на которой сидел Оливер. Тогда турм бросился уже на Оливера. Он схватил подвешенца отмаленными твинами за плечи и вытокнул его на землю.
Цитируется по: Р. М. Фрумкина. Психолингвистика. М., 2001
 Столенно, ничего бы и не случилось, если бы собака Оливера не начала порочить на вахню.
Столенно, ничего бы и не случилось, если бы собака Оливера не начала порочить на вахню.Вы встретили множество незнакомых слов, но нет сомнений, что вы в целом поняли, о чем здесь говорится, и даже можете пересказать содержание. А сконструирован этот текст очень простым способом: взят нормальный текст, но сохранены в нем только самые частотные слова, а все редкие заменены вымышленными. Вот оригинал этой истории:
Скотовод Ланс Оливер чуть не погиб в результате нападения кенгуру. Он ехал верхом на лошади неподалеку от Мэнсфилда (Австралия) и увидел стадо кенгуру, в котором было примерно 15 животных. Возможно, ничего бы и не случилось, если бы собака Оливера не начала лаять на стадо.
Один из кенгуру — старый крупный самец, раздраженный лаем собаки, бросился за ней. Та попыталась укрыться за лошадью, на которой сидел Оливер. Тогда кенгуру бросился уже на Оливера. Он схватил всадника передними лапами за плечи и сбросил его на землю.

Получается, для того, чтобы понимать человеческий язык, достаточно неполных знаний. Более того, полных знаний и не бывает: никто из нас не может знать все слова и гарантировать, что поймет от начала и до конца любое встретившееся ему предложение.
«и», «в», «не», «на»: частотный словарь
Представьте себе, что вы изучаете русский язык и хотите узнать: сколько слов надо выучить, чтобы понимать 20 % текста на этом языке? Ну или не понимать, а хотя бы опознавать 20 % слов в тексте.
Очевидно, что полезно сперва учить частотные слова, а потом уже редкие: знать слово «собака» куда важнее, чем «самец» или «всадник», и уж тем более, чем «вольвокс» или «рейсфедер».
А если довести эту идею до логического завершения, получится очень простой способ учить язык: надо взять частотный словарь, в котором слова отсортированы по употребительности, и заучивать его сверху вниз.
Самый популярный частотный словарь для русского языка в 2009 году создали Ольга Ляшевская и Сергей Шаров. Он свободно доступен на сайте Института русского языка им. В. В. Виноградова. Первое по частотности русское слово — это слово «и», за ним следуют «в», «не», «на», «я» и т. д. — вот и будем запоминать их подряд по этому списку:
Вернемся к предложению, в котором мы поставили перед собой задачу:
Представьте себе, что вы изучаете русский язык и хотите узнать: сколько слов надо выучить, чтобы понимать 20 % текста на этом языке?
В нем 20 слов, а значит, 20 % от них — это 4 слова. А теперь присмотритесь внимательно: оказывается, выучив первые 14 слов из частотного словаря, мы и узнаем в этом тексте 4 слова — «что», «и», «на» и «этом». Желанный результат достигнут: 20 % текста поняты (хотя до смысла, конечно, еще очень далеко).
Желанный результат достигнут: 20 % текста поняты (хотя до смысла, конечно, еще очень далеко).
В частотном словаре каждому слову приписано число, которое показывает, сколько раз это слово встретится, если мы возьмем текст длиной 1 миллион слов. Слово «и» мы в таком тексте увидим примерно 35 802 раза, слово «в» — 31 374 раза и т. д. Если сложить частоты первых 14 слов, то окажется, что они покроют 188 072 слова из миллиона — то есть почти те самые 20 %, к которым мы стремились. Чтобы выйти за 200 000, к ним надо добавить еще три слова («к», «но» и «они»). А чтобы понять 10 % текста, достаточно и вовсе 4 слов.
Вот полные списки слов, которых хватит, чтобы понять 10 %, 20 %, 30 % и 40 % текста на русском языке:
Видно, что на первые 10 % у иностранца уйдет совсем мало усилий. На следующие 10 % понадобится еще 13 слов; чтобы достигнуть 30-процентного понимания, придется добавить 29 слов, а чтобы добраться до 40 % — 86 слов. Чем дальше мы идем по частотному списку, тем менее полезно нам каждое следующее слово:
Иначе говоря, в любом языке есть совсем немного высокочастотных слов и много низкочастотных. Например, 1 раз на миллион слов, согласно словарю Ляшевской и Шарова, встретится 1478 слов; среди них — «резвость», «увильнуть», «боезапас», «сызнова», «картографирование». Ясно, что это совсем не то, что надо учить в первую очередь.
Например, 1 раз на миллион слов, согласно словарю Ляшевской и Шарова, встретится 1478 слов; среди них — «резвость», «увильнуть», «боезапас», «сызнова», «картографирование». Ясно, что это совсем не то, что надо учить в первую очередь.
Слова, города и всё на свете: закон Ципфа
Частоты слов подчиняются простой математической закономерности, которую в середине XX века открыл американец Джордж Кингсли Ципф (1902–1950).
Источник
Он сформулировал такую зависимость, которая получила название «закон Ципфа»: частотность слова обратно пропорциональна номеру слова в частотном списке. Например, если первое слово имеет частотность 60 000, то у второго слова будет частотность 60 000 / 2 = 30 000, у третьего — 60 000 / 3 = 20 000 и т. д. В реальном языке всё не получается так красиво: например, русский частотный словарь укладывался бы в закон Ципфа гораздо лучше, если бы у слова «и» частотность была не 35 802, а как раз около 60 000, тем не менее даже это приближение неплохо работает. Если изобразить распределение частот для первых 200 русских слов на графике, видно, что оно имеет форму гиперболы.
Если изобразить распределение частот для первых 200 русских слов на графике, видно, что оно имеет форму гиперболы.
Закон Ципфа — один из редких примеров закона, который был открыт на материале языка, а потом нашел применение во множестве других областей.
Ему подчиняются размеры населенных пунктов, количество ссылок на сайты, размеры компаний: в стране обычно есть совсем немного крупных городов и много-много мелких населенных пунктов; есть небольшое количество очень важных сайтов, на которые все ссылаются, и много сайтов, на которые не ссылается никто или почти никто; бывают гигантские компании, но мелких гораздо больше.
Например, в Берлине 3,5 млн жителей; во втором по величине городе Германии — Гамбурге — примерно в два раза меньше: 1,8 млн. В шестом городе страны — Штутгарте — примерно в шесть раз меньше: 600 тысяч, и т. д. Видно, что на этих данных закон Ципфа работает превосходно.
Когда пытаются понять, написан ли какой-то текст на человеческом языке или нет, одна из первых проверок, которые стоит сделать, — посмотреть, подчиняется ли текст закону Ципфа.
Например, в загадочном манускрипте Войнича закон Ципфа соблюден довольно неплохо. Правда, это только необходимое условие, но еще не доказательство того, что перед нами естественный язык: именно потому, что закон Ципфа применим почти к чему угодно, в том числе и к неязыковым данным.
Зачем нужны частоты
Частотный словарь может быть полезен на практике для изучающих иностранный язык: конечно, не стоит заставлять человека, когда он узнает новое слово, выяснять точно, какое именно место в частотном списке оно занимает, но можно дать ему представление о том, стоит ли вообще это слово запоминать. Например, в словарях издательства Macmillan есть два типа слов: красные и чёрные, причём у красных слов стоят еще звездочки — одна, две или три. Вот несколько примеров:
Красные слова с тремя звездочками занимают в частотном словаре места с 1-го по 2500-е, слова с двумя звездочками — с 2501-го по 5000-е, а слова с одной звездочкой — с 5001-го по 7500-е. Черные слова располагаются ниже 7500-го места. Для пользователя это имеет очень простые следствия. Если ты ищешь в словаре слово и видишь при нем три звездочки, выучи его обязательно: оно наверняка попадется еще много раз. Если при слове только одна звездочка, это достаточно полезное слово, но часто не пригодится. И, наконец, черные слова — совсем редкие; их стоит заучивать, только если стремишься выучить язык на продвинутом уровне, но если не получится, то ничего страшного. Можно прекрасно говорить по-английски, не зная, что thatch значит «соломенная крыша», а crescent — «полумесяц»; без слов restriction «ограничение» и allegedly «якобы» тоже можно прожить, а вот слова animal «животное» и play «играть» точно надо знать.
Для пользователя это имеет очень простые следствия. Если ты ищешь в словаре слово и видишь при нем три звездочки, выучи его обязательно: оно наверняка попадется еще много раз. Если при слове только одна звездочка, это достаточно полезное слово, но часто не пригодится. И, наконец, черные слова — совсем редкие; их стоит заучивать, только если стремишься выучить язык на продвинутом уровне, но если не получится, то ничего страшного. Можно прекрасно говорить по-английски, не зная, что thatch значит «соломенная крыша», а crescent — «полумесяц»; без слов restriction «ограничение» и allegedly «якобы» тоже можно прожить, а вот слова animal «животное» и play «играть» точно надо знать.
Еще одна важная область, в которой применяется частотный анализ, — это автоматическая обработка текста (natural language processing). Например, для проверки орфографии и исправления опечаток очень важно понимать, какие слова редкие, а какие — частотные. Предположим, что пользователь напечатал такую английскую фразу:
I am looking at teh black dog.

Мы прекрасно понимаем, что в ней содержится опечатка: вместо teh должно быть написано the. Но ведь teh могло легко получиться и из чего-нибудь другого: что если пользователь хотел ввести ten, но случайно попал в букву h вместо n? Или, может быть, он хотел напечатать tech, но пропустил букву c? Почему же мы всё-таки полагаем, что имелось в виду слово the, в котором переставились две буквы? Можно, конечно, долго рассуждать о том, что с ten и с tech получится неправильное предложение (например, ten black dog — плохое сочетание слов, а должно быть ten black dogs), но это знание трудно формализовать и вложить в компьютер. Но можно поступить проще: заглянем в частотный словарь, и он сообщит нам, что the — самое популярное английское слово, так что вероятность того, что пользователь хотел напечатать именно его, особенно велика. Эта стратегия — всегда исправляй опечатку на самое частотное из похожих слов — может показаться примитивной, но она неплохо работает.
В 2007 году директор по исследованиям компании Google Питер Норвиг за несколько часов, проведе–нных в самолете (даже без интернета!), написал программу для исправления опечаток, которая занимает всего 22 строки кода на языке Python и в первую очередь опирается на частотность.
Всё это свидетельствует об одном: человеческий язык не описывается только грамматическими правилами. Важно знать, как часто встречаются в нем те или иные слова. К счастью, такие знания благодаря компьютерам можно очень легко получить, и это открывает для лингвистики новые перспективы.
на основе одного миллиарда слов корпуса COCA
Частота слов: на основе одного миллиарда слов корпуса COCA
Обзор КОКА Сравните с другими списками слов испанский English-Corpora. Бесплатные данные (5000) |
 org
org
|

на основе одного миллиарда слов корпуса COCA
|
 Образцы ниже
Образцы ниже ниже)
ниже) Распространяется отдельным файлом из-за количества
Распространяется отдельным файлом из-за количества