Содержание
Яндекс открывает технологию машинного обучения CatBoost / Хабр
Сегодня Яндекс выложил в open source собственную библиотеку CatBoost, разработанную с учетом многолетнего опыта компании в области машинного обучения. С ее помощью можно эффективно обучать модели на разнородных данных, в том числе таких, которые трудно представить в виде чисел (например, виды облаков или категории товаров). Исходный код, документация, бенчмарки и необходимые инструменты уже опубликованы на GitHub под лицензией Apache 2.0.
CatBoost – это новый метод машинного обучения, основанный на градиентном бустинге. Он внедряется в Яндексе для решения задач ранжирования, предсказания и построения рекомендаций. Более того, он уже применяется в рамках сотрудничества с Европейской организацией по ядерным исследованиям (CERN) и промышленными клиентами Yandex Data Factory. Так чем же CatBoost отличается от других открытых аналогов? Почему бустинг, а не метод нейронных сетей? Как эта технология связана с уже известным Матрикснетом? И причем здесь котики? Сегодня мы ответим на все эти вопросы.
Термин «машинное обучение» появился еще в 50-х годах. Этот термин обозначает попытку научить компьютер решать задачи, которые легко даются человеку, но формализовать путь их решения сложно. В результате машинного обучения компьютер может демонстрировать поведение, которое в него не было явно заложено. В современном мире мы сталкиваемся с плодами машинного обучения ежедневно по многу раз, многие из нас сами того не подозревая. Оно используется для построения лент в социальных сетях, списков «похожих товаров» в интернет-магазинах, при выдаче кредитов в банках и определении стоимости страховки. На технологиях машинного обучения работает поиск лиц на фотографиях или многочисленные фотофильтры. Для последних, кстати, обычно используются нейронные сети, и о них пишут так часто, что может сложиться ошибочное мнение, будто бы это «серебряная пуля» для решения задач любой сложности. Но это не так.
Нейросети или градиентный бустинг
На самом деле, машинное обучение очень разное: существует большое количество разных методов, и нейросети – лишь один из них. Иллюстрацией этого являются результаты соревнований на платформе Kaggle, где на разных соревнованиях побеждают разные методы, причем на очень многих побеждает градиентный бустинг.
Иллюстрацией этого являются результаты соревнований на платформе Kaggle, где на разных соревнованиях побеждают разные методы, причем на очень многих побеждает градиентный бустинг.
Нейросети прекрасно решают определенные задачи – например, те, где нужно работать с однородными данными. Из однородных данных состоят, например, изображения, звук или текст. В Яндексе они помогают нам лучше понимать поисковые запросы, ищут похожие картинки в интернете, распознают ваш голос в Навигаторе и многое другое. Но это далеко не все задачи для машинного обучения. Существует целый пласт серьезных вызовов, которые не могут быть решены только нейросетями – им нужен градиентный бустинг. Этот метод незаменим там, где много данных, а их структура неоднородна.
Например, если вам нужен точный прогноз погоды, где учитывается огромное количество факторов (температура, влажность, данные с радаров, наблюдения пользователей и многие другие). Или если вам нужно качественно ранжировать поисковую выдачу – именно это в свое время и подтолкнуло Яндекс к разработке собственного метода машинного обучения.
Матрикснет
Первые поисковые системы были не такими сложными, как сейчас. Фактически сначала был просто поиск слов – сайтов было так мало, что особой конкуренции между ними не было. Потом страниц стало больше, их стало нужно ранжировать. Начали учитываться разные усложнения — частота слов, tf-idf. Затем страниц стало слишком много на любую тему, произошёл первый важный прорыв — начали учитывать ссылки.
Вскоре интернет стал коммерчески важным, и появилось много жуликов, пытающихся обмануть простые алгоритмы, существовавшие в то время. И произошёл второй важный прорыв — поисковики начали использовать свои знания о поведении пользователей, чтобы понимать, какие страницы хорошие, а какие — нет.
Лет десять назад человеческого разума перестало хватать на то, чтобы придумывать, как ранжировать документы. Вы, наверное, замечали, что количество найденного почти по любому запросу огромно: сотни тысяч, часто — миллионы результатов. Большая часть из них неинтересные, бесполезные, лишь случайно упоминают слова запроса или вообще являются спамом. Для ответа на ваш запрос нужно мгновенно отобрать из всех найденных результатов десятку лучших. Написать программу, которая делает это с приемлемым качеством, стало не под силу программисту-человеку. Произошёл следующий переход — поисковики стали активно использовать машинное обучение.
Для ответа на ваш запрос нужно мгновенно отобрать из всех найденных результатов десятку лучших. Написать программу, которая делает это с приемлемым качеством, стало не под силу программисту-человеку. Произошёл следующий переход — поисковики стали активно использовать машинное обучение.
Яндекс еще в 2009 году внедрили собственный метод Матрикснет, основанный на градиентном бустинге. Можно сказать, что ранжированию помогает коллективный разум пользователей и «мудрость толпы». Информация о сайтах и поведении людей преобразуется во множество факторов, каждый из которых используется Матрикснетом для построения формулы ранжирования. Фактически, формулу ранжирования теперь пишет машина. Кстати, в качестве отдельных факторов мы в том числе используем результаты работы нейронных сетей (к примеру, так работает алгоритм Палех, о котором рассказывали в прошлом году).
Важная особенность Матрикснета в том, что он устойчив к переобучению. Это позволяет учитывать очень много факторов ранжирования и при этом обучаться на относительно небольшом количестве данных, не опасаясь, что машина найдет несуществующие закономерности. Другие методы машинного обучения позволяют либо строить более простые формулы с меньшим количеством факторов, либо нуждаются в большей обучающей выборке.
Другие методы машинного обучения позволяют либо строить более простые формулы с меньшим количеством факторов, либо нуждаются в большей обучающей выборке.
Ещё одна важная особенность Матрикснета — в том, что формулу ранжирования можно настраивать отдельно для достаточно узких классов запросов. Например, улучшить качество поиска только по запросам про музыку. При этом ранжирование по остальным классам запросов не ухудшится.
Именно Матрикснет и его достоинства легли в основу CatBoost. Но зачем нам вообще понадобилось изобретать что-то новое?
Категориальный бустинг
Практически любой современный метод на основе градиентного бустинга работает с числами. Даже если у вас на входе жанры музыки, типы облаков или цвета, то эти данные все равно нужно описать на языке цифр. Это приводит к искажению их сути и потенциальному снижению точности работы модели.
Продемонстрируем это на примитивном примере с каталогом товаров в магазине. Товары мало связаны между собой, и не существует такой закономерности между ними, которая позволила бы упорядочить их и присвоить осмысленный номер каждому продукту. Поэтому в этой ситуации каждому товару просто присваивают порядковый id (к примеру, в соответствии с программой учета в магазине). Порядок этих чисел ничего не значит, однако алгоритм будет этот порядок использовать и делать из него ложные выводы.
Поэтому в этой ситуации каждому товару просто присваивают порядковый id (к примеру, в соответствии с программой учета в магазине). Порядок этих чисел ничего не значит, однако алгоритм будет этот порядок использовать и делать из него ложные выводы.
Опытный специалист, работающий с машинным обучением, может придумать более интеллектуальный способ превращения категориальных признаков в числовые, однако такая предварительная предобработка приведет к потере части информации и приведет к ухудшению качества итогового решения.
Именно поэтому было важно научить машину работать не только с числами, но и с категориями напрямую, закономерности между которыми она будет выявлять самостоятельно, без нашей ручной «помощи». И CatBoost разработан нами так, чтобы одинаково хорошо работать «из коробки» как с числовыми признаками, так и с категориальными. Благодаря этому он показывает более высокое качество обучения при работе с разнородными данными, чем альтернативные решения. Его можно применять в самых разных областях — от банковской сферы до промышленности.
Кстати, название технологии происходит как раз от Categorical Boosting (категориальный бустинг). И ни один кот при разработке не пострадал.
Бенчмарки
Можно долго говорить о теоретических отличиях библиотеки, но лучше один раз показать на практике. Для наглядности мы сравнили работу библиотеки CatBoost с открытыми аналогами XGBoost, LightGBM и h30 на наборе публичных датасетов. И вот результаты (чем меньше, тем лучше): https://catboost.yandex/#benchmark
Не хотим быть голословными, поэтому вместе с библиотекой в open source выложены описание процесса сравнения, код для запуска сравнения методов и контейнер с использованными версиями всех библиотек. Любой пользователь может повторить эксперимент у себя или на своих данных.
CatBoost на практике
Новый метод уже протестировали на сервисах Яндекса. Он применялся для улучшения результатов поиска, ранжирования ленты рекомендаций Яндекс.Дзен и для расчета прогноза погоды в технологии Метеум — и во всех случаях показал себя лучше Матрикснета. В дальнейшем CatBoost будет работать и на других сервисах. Не будем здесь останавливаться – лучше сразу расскажем про Большой адронный коллайдер (БАК).
В дальнейшем CatBoost будет работать и на других сервисах. Не будем здесь останавливаться – лучше сразу расскажем про Большой адронный коллайдер (БАК).
CatBoost успел найти себе применение и в рамках сотрудничества с Европейской организацией по ядерным исследованиям. В БАК работает детектор LHCb, используемый для исследования асимметрии материи и антиматерии во взаимодействиях тяжёлых прелестных кварков. Чтобы точно отслеживать разные частицы, регистрируемые в эксперименте, в детекторе существуют несколько специфических частей, каждая из которых определяет специальные свойства частиц. Наиболее сложной задачей при этом является объединение информации с различных частей детектора в максимально точное, агрегированное знание о частице. Здесь и приходит на помощь машинное обучение. Используя для комбинирования данных CatBoost, учёным удалось добиться улучшения качественных характеристик финального решения. Результаты CatBoost оказались лучше результатов, получаемых с использованием других методов.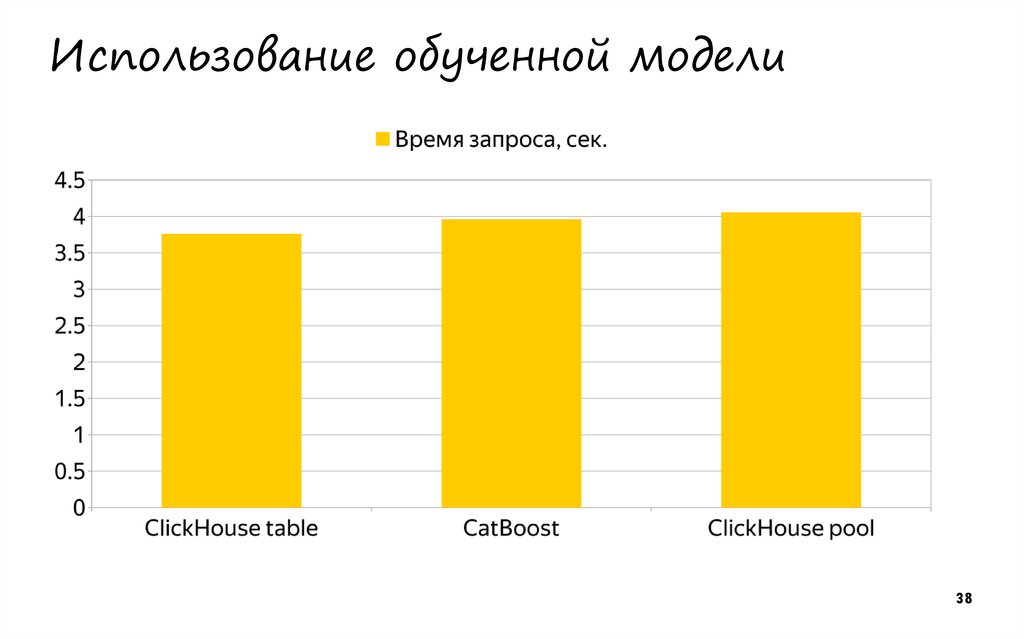
Как начать использовать CatBoost?
Для работы с CatBoost достаточно установить его на свой компьютер. Библиотека поддерживает операционные системы Linux, Windows и macOS и доступна на языках программирования Python и R. Яндекс разработал также программу визуализации CatBoost Viewer, которая позволяет следить за процессом обучения на графиках.
Более подробно все описано в нашей документации.
CatBoost — первая российская технология машинного обучения такого масштаба, которая стала доступна в open sourсe. Выкладывая библиотеку в открытый доступ, мы хотим внести свой вклад в развитие машинного обучения. Надеемся, что сообщество специалистов оценит технологию и примет участие в ее развитии.
Введение в разработку CatBoost. Доклад Яндекса / Хабр
Меня зовут Стас Кириллов, я ведущий разработчик в группе ML-платформ в Яндексе. Мы занимаемся разработкой инструментов машинного обучения, поддержкой и развитием инфраструктуры для них. Ниже — мой недавний доклад о том, как устроена библиотека CatBoost. В докладе я рассказал о входных точках и особенностях кода для тех, кто хочет его понять или стать нашим контрибьютором.
Ниже — мой недавний доклад о том, как устроена библиотека CatBoost. В докладе я рассказал о входных точках и особенностях кода для тех, кто хочет его понять или стать нашим контрибьютором.
— CatBoost у нас живет на GitHub под лицензией Apache 2.0, то есть открыт и бесплатен для всех. Проект активно развивается, сейчас у нашего репозитория больше четырех тысяч звездочек. CatBoost написан на C++, это библиотека для градиентного бустинга на деревьях решений. В ней поддержано несколько видов деревьев, в том числе так называемые «симметричные» деревья, которые используются в библиотеке по умолчанию.
В чем профит наших oblivious-деревьев? Они быстро учатся, быстро применяются и помогают обучению быть более устойчивым к изменению параметров с точки зрения изменений итогового качества модели, что сильно уменьшает необходимость в подборе параметров. Наша библиотека — про то, чтобы было удобно использовать в продакшене, быстро учиться и сразу получать хорошее качество.
Градиентный бустинг — это алгоритм, в котором мы строим простые предсказатели, которые улучшают нашу целевую функцию. То есть вместо того, чтобы сразу строить сложную модель, мы строим много маленьких моделей по очереди.
Как происходит процесс обучения в CatBoost? Расскажу, как это устроено с точки зрения кода. Сначала мы парсим параметры обучения, которые передает пользователь, валидируем их и дальше смотрим, нужно ли нам загружать данные. Потому что данные уже могут быть загружены — например, в Python или R. Далее мы загружаем данные и строим сетку из бордеров с целью квантизовать численные фичи. Это нужно, чтобы делать обучение быстрым.
Категориальные фичи мы процессим немножечко по-другому. Категориальные фичи мы в самом начале хэшируем, а потом перенумеровываем хэши от нуля до количества уникальных значений категориальной фичи, чтобы быстро считать комбинации категориальных фич.
Дальше мы запускаем непосредственно training loop — главный цикл нашего машинного обучения, где мы итеративно строим деревья. После этого цикла происходит экспорт модели.
После этого цикла происходит экспорт модели.
Сам цикл обучения состоит из четырех пунктов. Первый — мы пытаемся построить одно дерево. Дальше смотрим, какой прирост или убыль качества оно дает. Потом проверяем, не сработал ли наш детектор переобучения. Далее мы, если пришло время, сохраняем снэпшот.
Обучение одного дерева — это цикл по уровням дерева. В самом начале мы случайным образом выбираем перестановку данных, если у нас используется ordered boosting или имеются категориальные фичи. Затем мы подсчитываем на этой перестановке счетчики. Дальше мы пытаемся жадным образом подобрать хорошие сплиты в этом дереве. Под сплитами мы понимаем просто некие бинарные условия: такая-то числовая фича больше такого-то значения, либо такой-то счетчик по категориальной фиче больше такого-то значения.
Как устроен цикл жадного подбора уровней дерева? В самом начале делается бутстрап — мы перевзвешиваем либо сэмплируем объекты, после чего только выбранные объекты будут использоваться для построения дерева. Бутстрап также может пересчитываться перед выбором каждого сплита, если включена опция сэмплирования на каждом уровне.
Бутстрап также может пересчитываться перед выбором каждого сплита, если включена опция сэмплирования на каждом уровне.
Дальше мы агрегируем производные в гистограммки, так мы делаем для каждого сплит-кандидата. С помощью гистограмм мы пытаемся оценить изменение целевой функции, которое произойдет, если мы выберем этого сплит-кандидата.
Мы выбираем кандидата с лучшими скором и добавляем его в дерево. Потом мы подсчитываем статистики с использованием этого подобранного дерева на оставшихся перестановках, обновляем значение в листьях на этих перестановках, считаем значения в листьях для модели и переходим к следующей итерации цикла.
Очень сложно выделить какое-то одно место, в котором происходит обучение, так что на этом слайде — его можно использовать как некоторую точку входа — перечислены основные файлы, которые у нас применяются для обучения. Это greedy_tensor_search, в котором у нас живет сама процедура жадного подбора сплитов. Это train.cpp, где у нас находится главная фабрика CPU-обучения. Это aprox_calcer, где лежат функции обновления значений в листьях. А также score_calcer — функция оценки какого-то кандидата.
Это aprox_calcer, где лежат функции обновления значений в листьях. А также score_calcer — функция оценки какого-то кандидата.
Не менее важные части — catboost.pyx и core.py. Это код питоновской обертки, скорее всего, многие из вас будут внедрять какие-то вещи в питоновскую обертку. Наша питоновская обертка написана на Cython, Cython транслируется в C++, так что этот код должен быть быстрым.
Наша R-обертка лежит в папке R-package. Возможно, кому-то придется добавлять или исправлять какие-то опции, для опций у нас есть отдельная библиотека — catboost/libs/options.
Мы пришли из Arcadia в GitHub, поэтому у нас есть много интересных артефактов, с которыми вам придется столкнуться.
Начнем со структуры репозитория. У нас есть папка util, где лежат базовые примитивы: вектора, мапы, файловые системы, работа со строками, потоки.
У нас есть library, где лежат библиотеки общего пользования, которыми пользуются в Яндексе, — многие, не только CatBoost.
Папка CatBoost и contrib — это код сторонних библиотек, с которыми мы линкуемся.
Давайте теперь поговорим про примитивы C++, с которыми вам придется столкнуться. Первое — умные указатели. В Яндексе у нас со времен std::unique_ptr используется THolder, а вместо std::make_unique используется MakeHolder.
У нас есть свой SharedPtr. Причем он существует в двух ипостасях, SimpleSharedPtr и AtomicSharedPtr, которые отличаются типом счетчика. В одном случае он атомарный, это значит, что объектом могут владеть как будто бы несколько потоков. Так будет безопасно с точки зрения передачи между потоками.
Отдельный класс IntrusivePtr позволяет владеть объектами, унаследованными от класса TRefCounted, то есть классами, у которых внутри встроен счетчик ссылок. Это чтобы аллоцировать такие объекты за один раз, не аллоцируя дополнительно контрольный блок со счетчиком.
Также у нас своя система для ввода и вывода. IInputStream и IOutputStream — это интерфейсы для ввода и вывода. У них есть полезные методы, такие как ReadTo, ReadLine, ReadAll, в общем, всё, что можно ожидать от InputStreams. И у нас есть реализации этих стримов для работы с консолью: Cin, Cout, Cerr и отдельно Endl, который похож на std::endl, то есть он флашит поток.
И у нас есть реализации этих стримов для работы с консолью: Cin, Cout, Cerr и отдельно Endl, который похож на std::endl, то есть он флашит поток.
Еще у нас есть свои реализации интерфейсов для файлов: TInputFile, TOutputFile. Это буферизованное чтение. Они реализуют буферизованное чтение и буферизованную запись в файл, поэтому можно ими пользоваться.
У util/system/fs.h есть методы NFs::Exists и NFs::Copy, если вдруг вам что-то понадобится скопировать или проверить, что какой-то файл действительно существует.
У нас свои контейнеры. Они довольно давно переехали на использование std::vector, то есть они просто наследуются от std::vector, std::set и std::map, но у нас есть и свои THashMap и THashSet, у которых отчасти интерфейсы совместимы с unordered_map и unordered_set. Но для некоторых задач они оказались быстрее, поэтому они у нас до сих пор используются.
Ссылки на массивы — аналог std::span из C++. Правда, появился он у нас не в двадцатом году, а сильно раньше. Мы его активно используем, чтобы передавать ссылки на массивы, как будто бы аллоцированные на больших буферах, чтобы не аллоцировать временные буферы каждый раз. Допустим, для подсчета производных или каких-то аппроксов мы можем выделять память на каком-то предаллоцированном большом буфере и передавать функцию подсчета только TArrayRef. Это очень удобно, и мы много где это используем.
Мы его активно используем, чтобы передавать ссылки на массивы, как будто бы аллоцированные на больших буферах, чтобы не аллоцировать временные буферы каждый раз. Допустим, для подсчета производных или каких-то аппроксов мы можем выделять память на каком-то предаллоцированном большом буфере и передавать функцию подсчета только TArrayRef. Это очень удобно, и мы много где это используем.
В Arcadia применяется свой набор классов для работы со строками. Это, во-первых, TStingBuf — аналог str::string_view из C++17.
TString — совсем не std::sting, это CopyOnWrite-строка, поэтому нужно с ней работать довольно аккуратно. Кроме того, TUtf16String — такая же TString, только у нее базовый тип — не char, а 16-битный wchar.
И у нас есть инструменты для преобразования из строк и в строку. Это ToString, который является аналогом std::to_string и FromString в паре с TryFromString, которые позволяют превратить строку в необходимый вам тип.
У нас есть своя структура исключений, базовым исключением в аркадийных библиотеках является yexception, который наследуется от std::exception. У нас есть макрос ythrow, который добавляет информацию о месте, откуда бросилось исключение в yexception, это просто удобная обертка.
У нас есть макрос ythrow, который добавляет информацию о месте, откуда бросилось исключение в yexception, это просто удобная обертка.
Есть свой аналог std::current_exception — CurrentExceptionMessage, эта функция выводит текущее исключение в виде строки.
Есть свои макросы для asserts и verifies — это Y_ASSERT и Y_VERIFY.
И у нас есть своя встроенная сериализация, она бинарная и не предназначена для того, чтобы передавать данные между разными ревизиями. Скорее эта сериализация нужна для того, чтобы передавать данные между двумя бинарниками одинаковой ревизии, например, при распределенном обучении.
Так получилось, что у нас в CatBoost используются две версии сериализации. Первый вариант работает через интерфейсные методы Save и Load, которые сериализуют в поток. Другой вариант используется в нашем распределенном обучении, там применяется довольно старая внутренняя библиотека BinSaver, удобная для сериализации полиморфных объектов, которые должны быть зарегистрированы в специальной фабрике. Это нужно для распределенного обучения, про которое мы здесь в силу недостатка времени вряд ли успеем рассказать.
Это нужно для распределенного обучения, про которое мы здесь в силу недостатка времени вряд ли успеем рассказать.
Также у нас есть свой аналог boost_optional или std::optional — TMaybe. Аналог std::variant — TVariant. Нужно пользоваться ими.
Есть и некое соглашение, что внутри CatBoost-кода мы вместо yexception бросаем TCatBoostException. Это тот же самый yexception, только в нем всегда при бросании добавляется stack trace.
И еще мы используем макрос CB_ENSURE, чтобы удобно проверять какие-то вещи и бросать исключения, если они не выполняются. Например, мы это часто используем для парсинга опций или парсинга переданных пользователем параметров.
Ссылки со слайда: первая, вторая
Обязательно перед началом работы рекомендуем ознакомиться с code style, он состоит из двух частей. Первая — общеаркадийный code style, который лежит прямо в корне репозитория в файле CPP_STYLE_GUIDE. md. Также в корне репозитория лежит отдельный гайд для нашей команды: catboost_command_style_guide_extension.md.
md. Также в корне репозитория лежит отдельный гайд для нашей команды: catboost_command_style_guide_extension.md.
Python-код мы стараемся оформлять по PEP8. Не всегда получается, потому что для Cython кода у нас не работает линтер, и иногда там что-то разъезжается с PEP8.
Каковы особенности нашей сборки? Аркадийная сборка изначально была нацелена на то, чтобы собирать максимально герметичные приложения, то есть чтобы был минимум внешних зависимостей за счет статической линковки. Это позволяет использовать один и тот же бинарник на разных версиях Linux без рекомпиляции, что довольно удобно. Цели сборки описываются в ya.make-файлах. Пример ya.make можно посмотреть на следующем слайде.
Если вдруг вам захочется добавить какую-то библиотеку, программу или еще что-то, можно, во-первых, просто посмотреть в соседних ya.make-файлах, а во-вторых, воспользоваться этим примером. Здесь у нас перечислены самые важные элементы ya.make. В самом начале файла мы говорим о том, что хотим объявить библиотеку, дальше перечисляем единицы компиляции, которые хотим в эту библиотеку поместить. Здесь могут быть как cpp-файлы, так и, например, pyx-файлы, для которых автоматически запустится Cython, а потом компилятор. Зависимости библиотеки перечисляются через макрос PEERDIR. Здесь просто пишутся пути до папки с library либо с другим артефактом внутри, относительно корня репозитория.
Здесь могут быть как cpp-файлы, так и, например, pyx-файлы, для которых автоматически запустится Cython, а потом компилятор. Зависимости библиотеки перечисляются через макрос PEERDIR. Здесь просто пишутся пути до папки с library либо с другим артефактом внутри, относительно корня репозитория.
Есть полезная штука, GENERATE_ENUM_SERIALIZATION, необходимая для того, чтобы сгенерировать ToString, FromString методы для enum classes и enums, описанных в каком-то заголовочном файле, который вы передаете в этот макрос.
Теперь о самом важном — как скомпилировать и запустить какой-нибудь тест. В корне репозитория лежит скрипт ya, который загружает необходимые toolkits и инструменты, и у него есть команда ya make — подкоманда make, — которая позволяет собрать с ключиком -r релиз, с ключиком -d дебаг-версию. Артефакты в ней передаются далее и разделяются через пробел.
Для сборки Python я здесь сразу же указал флаги, которые могут быть полезны. Речь идет про сборку с системным Python, в данном случае с Python 3. Если вдруг на вашем ноутбуке или разработческой машине есть установленный CUDA Toolkit, то для более быстрой сборки рекомендуем указывать флаг –d have_cuda no. CUDA собирается довольно долго, особенно на 4-ядерных системах.
Если вдруг на вашем ноутбуке или разработческой машине есть установленный CUDA Toolkit, то для более быстрой сборки рекомендуем указывать флаг –d have_cuda no. CUDA собирается довольно долго, особенно на 4-ядерных системах.
Еще уже должна работать ya ide. Это инструмент, который сгенерирует для вас clion либо qt solution. И для тех, кто пришел с Windows, у нас есть Microsoft Visual Studio solution, который лежит в папке msvs.
Слушатель:
— А у вас все тесты через Python-обертку?
Стас:
— Нет, у нас отдельно есть тесты, которые лежат в папке pytest. Это тесты нашего CLI-интерфейса, то есть нашего приложения. Правда, они работают через pytest, то есть это Python-функции, в которых мы делаем subprocess check call и проверяем то, что программа не падает и правильно работает при каких-то параметрах.
Слушатель:
— А юнит-тесты на C++?
Стас:
— Юнит-тесты на C++ у нас тоже есть. Они обычно лежат в папке lib в подпапках ut. И они так и пишутся — unit test либо unit test for. Там есть примеры. Есть специальные макросы для того, чтобы объявить класс с юнит-тестами, и отдельные регистры для функции юнит-тестов.
И они так и пишутся — unit test либо unit test for. Там есть примеры. Есть специальные макросы для того, чтобы объявить класс с юнит-тестами, и отдельные регистры для функции юнит-тестов.
Слушатель:
— Для проверки того, что ничего не сломалось, лучше запускать и те, и те?
Стас:
— Да. Единственное, наши тесты в опенсорсе зеленые только на Linux. Поэтому если вы компилируетесь, например, под Mac, если там пять тестов будет падать — ничего страшного. Из-за разной реализации экспоненты на разных платформах или еще каких-то мелких различий результаты могут сильно разъезжаться.
Для примера возьмем задачку. Хочется показать какой-то пример. У нас есть файлик с задачками — open_problems.md. Решим задачку №4 из open_problems.md. Она формулируется так: если пользователь задал learning rate нулевым, то мы должны падать с TCatBoostException. Нужно добавить валидацию опций.
Для начала мы должны создать веточку, склонировать себе свой fork, склонировать origin, запулить origin, запушить origin в свой fork и дальше создать веточку и начать в ней работать.
Как вообще происходит парсинг опций? Как я уже сказал, у нас есть важная папка catboost/libs/options, где хранится парсинг всех опций.
У нас все опции хранятся в обертке TOption, которая позволяет понять, была ли опция переопределена пользователем. Если не была — она хранит в себе какое-то дефолтное значение. Вообще, CatBoost парсит все опции в виде большого JSON-словаря, который в процессе парсинга превращается во вложенные словари и вложенные структуры.
Мы каким-то образом узнали — например, поискав грепом или прочитав код, — что learning rate у нас находится в TBoostingOptions. Попробуем написать код, который просто добавляет CB_ENSURE, что наш learning rate больше чем std::numeric_limits::epsilon, что пользователь ввел нечто более-менее разумное.
Мы здесь как раз воспользовались макросом CB_ENSURE, написали какой-то код и теперь хотим добавить тесты.
В данном случае мы добавляем тест на Command Line Interface. В папке pytest у нас лежит скрипт test. py, где уже есть довольно много примеров тестов и можно просто подобрать похожий на вашу задачу, скопировать его и поменять параметры так, чтобы он начал падать либо не падать — в зависимости от переданных вами параметров. В данном случае мы просто берем и создаем простой пул из двух строчек. (Пулами мы в Яндексе называем датасет. Такая у нас особенность.) И дальше проверяем то, что наш бинарник правда падает, если передать learning rate 0.0.
py, где уже есть довольно много примеров тестов и можно просто подобрать похожий на вашу задачу, скопировать его и поменять параметры так, чтобы он начал падать либо не падать — в зависимости от переданных вами параметров. В данном случае мы просто берем и создаем простой пул из двух строчек. (Пулами мы в Яндексе называем датасет. Такая у нас особенность.) И дальше проверяем то, что наш бинарник правда падает, если передать learning rate 0.0.
Также мы добавляем в python-package тест, который находится в сatBoost/python-package/ut/medium. У нас есть еще large, большие тесты, которые связаны с тестами на сборку python wheel-пакетов.
Дальше у нас есть ключики для ya make — -t и -A. -t запускает тесты, -A заставляет запускать все тесты вне зависимости от того, какие у них теги: large или medium.
Здесь я для красоты также использовал фильтр по имени теста. Он задается с помощью опции -F и указанного дальше имени теста, которым могут быть wild char-звездочки. В данном случае я использовал test.py::test_zero_learning_rate*, потому что, посмотрев на наши тесты python-package, вы увидите: почти все функции принимают внутрь себя фикстуру task type. Это чтобы по коду наши тесты python-package выглядели одинаково и для CPU-, и для GPU-обучения и могли использоваться для тестов GPU и CPU trainer.
В данном случае я использовал test.py::test_zero_learning_rate*, потому что, посмотрев на наши тесты python-package, вы увидите: почти все функции принимают внутрь себя фикстуру task type. Это чтобы по коду наши тесты python-package выглядели одинаково и для CPU-, и для GPU-обучения и могли использоваться для тестов GPU и CPU trainer.
Дальше коммитим наши изменения и пушим их в наш форкнутый репозиторий. Публикуем пул-реквест. Он уже влился, всё хорошо.
Яндекс с открытым исходным кодом Библиотека машинного обучения CatBoost
Российский поисковый гигант выпустил собственную систему машинного обучения с обученными результатами, которые можно использовать непосредственно в системе Apple Core ML
Сердар Егулалп
старший писатель,
Информационный мир |
Геральт
(СС0)
Создатель российской поисковой системы Яндекс присоединился к Google, Amazon и Microsoft, выпустив собственную библиотеку машинного обучения с открытым исходным кодом CatBoost.
CatBoost под лицензией Apache предназначен для «повышения градиента с открытым исходным кодом в деревьях решений», согласно README репозитория GitHub. Он предоставляет способ выполнять классификацию и ранжирование данных с использованием набора механизмов принятия решений или «обучающихся», а не одного. Результаты, полученные учащимися, взвешиваются и классифицируются на основе сильных и слабых сторон каждого учащегося. Объединяя многих учащихся, CatBoost может дать лучшие результаты, чем системы принятия решений, которые полагаются на отдельных учащихся.
CatBoost поставляется с поддержкой Python и R, а также интерфейсом командной строки для управления библиотекой машинного обучения. Пакеты Python для CatBoost также включают средства визуализации данных для построения статистики тренировочного процесса. Полученные графики можно просмотреть в блокноте Jupyter или в собственном приложении для просмотра данных CatBoost.
Многие библиотеки машинного обучения уже реализуют какой-либо алгоритм повышения градиента. Пакет Python Scikit-learn имеет одну версию; XGBoost доступен для нескольких языков и платформ данных; а у Microsoft есть библиотека LightGBM в рамках проекта Distributed Machine Learning Toolkit.
Пакет Python Scikit-learn имеет одну версию; XGBoost доступен для нескольких языков и платформ данных; а у Microsoft есть библиотека LightGBM в рамках проекта Distributed Machine Learning Toolkit.
По словам Яндекса, CatBoost должен стоять отдельно от этих проектов, поскольку он предварительно настроен для работы в масштабе собственных сервисов Яндекса. Яндекс отметил, что использует CatBoost для предоставления прогнозов для своих метеорологических служб и что CatBoost был развернут в Европейской организации ядерных исследований (ЦЕРН) для уточнения результатов проведенных там экспериментов с частицами.
Обученные модели, созданные в CatBoost, можно развернуть в формате Apple Core ML для использования в приложениях MacOS, iOS, tvOS и watchOS, поддерживаемых машинным обучением.
Связанный:
- Машинное обучение
- Открытый исходный код
- Наука о данных
- Разработка программного обеспечения
Сердар Егулалп — старший писатель InfoWorld, специализирующийся на машинном обучении, контейнеризации, devops, экосистеме Python и периодических обзорах.
Copyright © 2017 IDG Communications, Inc.
Как выбрать платформу разработки с низким кодом
Яндекс с открытым исходным кодом CatBoost, библиотека машинного обучения, которую можно обучить с минимальными данными
Яндекс открыл исходный код CatBoost, библиотеки машинного обучения, которую можно обучить с минимальными данными
Лидер российского рынка поисковых систем Yandex Europe AG только что открыл исходный код новой библиотеки машинного обучения под названием CatBoost.
Компания является последней в длинной череде технологических гигантов, предлагающих платформу машинного обучения, следуя по стопам Google Inc., Facebook Inc., Microsoft Corp. и других. Однако, в то время как эти компании сосредоточились на создании нейронных сетей, систем, смоделированных на человеческом мозге, которые можно научить распознавать определенные объекты, изображения и события, CatBoost описывается как библиотека «ускорения градиента».
Повышение градиента — это направление машинного обучения, целью которого является обучение систем, когда доступно лишь ограниченное количество данных, с особым акцентом на транзакционные или исторические данные, объяснил в своем блоге руководитель отдела машинного интеллекта и исследований Яндекса Миша Биленко. почта.
Этот метод «широко применяется для решения проблем, с которыми предприятия сталкиваются каждый день, таких как обнаружение мошенничества, прогнозирование вовлеченности клиентов и ранжирование рекомендуемых элементов, таких как самые популярные веб-страницы или наиболее релевантная реклама», — сказал Биленко. «Он обеспечивает очень точные результаты даже в ситуациях, когда данных относительно мало, в отличие от сред глубокого обучения, которым необходимо учиться на огромном количестве данных».
Согласно странице CatBoost на Github, платформа предназначена для «повышения градиента с открытым исходным кодом в деревьях решений». Другими словами, он предлагает способ классификации и ранжирования данных с помощью набора механизмов принятия решений, называемых «обучающимися», а не только одного. Результаты, полученные этими учащимися, взвешиваются и классифицируются на основе сильных и слабых сторон каждого из них. Идея состоит в том, что, объединяя несколько обучающихся, CatBoost может давать более точные результаты, чем фреймворки, использующие только одного обучающегося.
Результаты, полученные этими учащимися, взвешиваются и классифицируются на основе сильных и слабых сторон каждого из них. Идея состоит в том, что, объединяя несколько обучающихся, CatBoost может давать более точные результаты, чем фреймворки, использующие только одного обучающегося.
Биленко сообщил, что Яндекс уже начал использовать CatBoost в своих сервисах. Эта структура заменяет старый алгоритм машинного обучения MatrixNet, который Яндекс использует для таких задач, как ранжирование в поисковых системах, прогнозы погоды, рекомендации и даже свой сервис Яндекс.Такси, который создается в рамках совместного предприятия стоимостью 3,72 миллиарда долларов с компанией Uber, занимающейся райдшерингом. Technologies Inc. Яндекс заявил, что переход от MatrixNet к CatBoost уже начался и должен быть завершен в течение нескольких месяцев.
Кроме того, Яндекс предоставляет CatBoost в качестве бесплатного сервиса по лицензии Apache Software Foundation, что означает, что каждый может использовать его в своих программах и сервисах.
Одной из организаций, которая уже воспользовалась этим предложением Яндекса, является ЦЕРН, расположенная в Швейцарии Европейская организация ядерных исследований, которая использует CatBoost для повышения производительности своих систем идентификации частиц. «Catboost повысит эффективность идентификации заряженных частиц, обеспечивая большую точность при выборе наших данных», — заявили Марианна Фонтана и Донал Хилл, координаторы проекта идентификации частиц в LHCb.
«Сделав CatBoost доступной в виде библиотеки с открытым исходным кодом, мы надеемся, что специалисты по данным и инженеры смогут без особых усилий получать высокоточные модели и в конечном итоге определить новый стандарт качества в машинном обучении», — сказал Биленко.
Изображение: Яндекс
Ваш голос в поддержку важен для нас, и это помогает нам делать контент БЕСПЛАТНЫМ.
1 щелчок ниже поддерживает нашу миссию по предоставлению бесплатного контента.
Присоединяйтесь к нашему сообществу на YouTube
Присоединяйтесь к сообществу, которое включает более 15 тысяч #CubeAlumni экспертов, включая генерального директора Amazon.
