Содержание
Правильный файл robots.txt для сайта на 1С-Битрикс в 2023
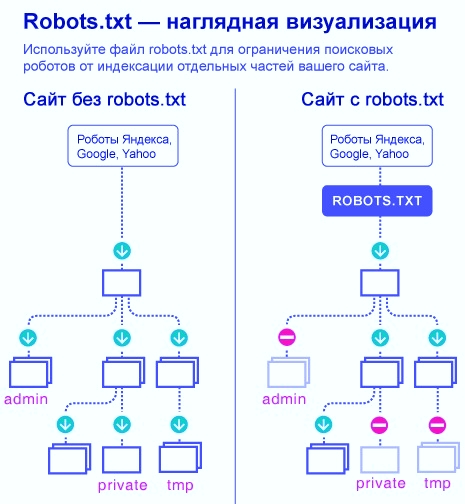
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
- Пример;
- Где найти;
- Как создать;
- Инструкция по работе;
- Синтаксис;
- Директивы;
- Как проверить.
Пример правильного файла robots.txt для сайта на 1С-Битрикс
- User-agent: *
- Disallow: /auth*
- Disallow: /basket*
- Disallow: /order*
- Disallow: /personal/
- Disallow: /search/
- Disallow: /test/
- Disallow: /ajax/
- Disallow: *index.php*
- Disallow: /*show_include_exec_time=
- Disallow: /*show_page_exec_time=
- Disallow: /*show_sql_stat=
- Disallow: *bitrix*
- Disallow: /*clear_cache=
- Disallow: /*clear_cache_session=
- Disallow: /*ADD_TO_COMPARE_LIST
- Disallow: /*ORDER_BY
- Disallow: /*print*
- Disallow: /*action*
- Disallow: /*register=
- Disallow: /*password*
- Disallow: /*login=
- Disallow: /*type=
- Disallow: /*sort=
- Disallow: /*order=
- Disallow: /*logout=
- Disallow: /*auth=
- Disallow: /*backurl=
- Disallow: /*back_url=
- Disallow: /*BACKURL=
- Disallow: /*BACK_URL=
- Disallow: /*back_url_admin=
- Disallow: /*?utm_source=
- Disallow: *?arrFilter*
- Host: https://seopulses.
 ru
ru - Sitemap: https://seopulses.ru/sitemap_index.xml
 ru
ruГде можно найти файл robots.txt и как его создать или редактировать
Чтобы проверить файл robots.txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.com/robots.txt
https://netpeak.net/robots.txt
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
- Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
- WordPress;
https://ru.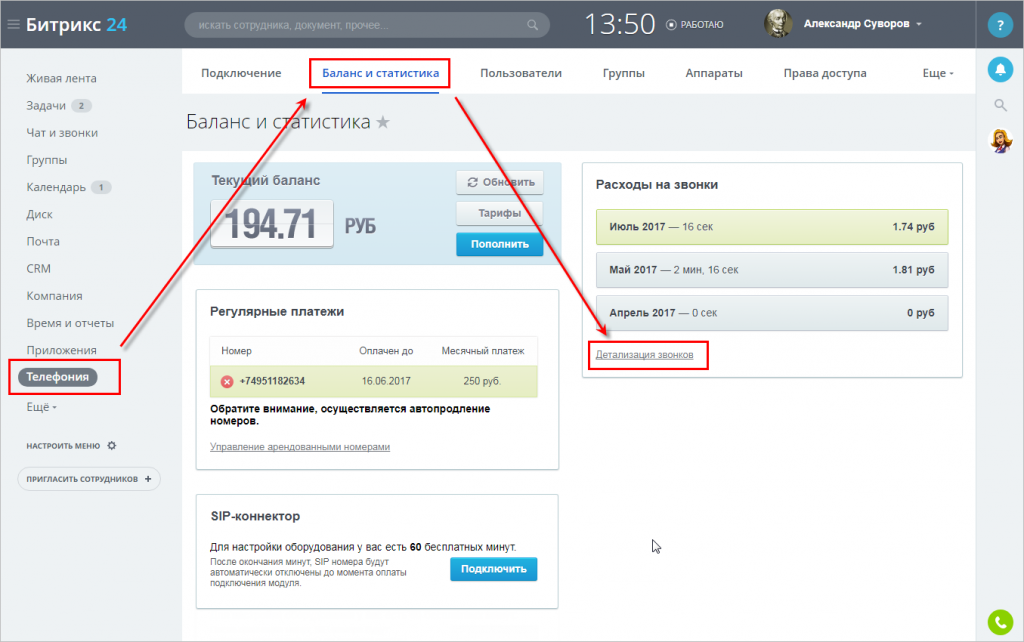 wordpress.org/plugins/pc-robotstxt/
wordpress.org/plugins/pc-robotstxt/
- Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
- Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Yandex — для обращения к поисковому роботу Яндекса;
- User-agent: Googlebot — в случае с краулером Google;
- User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Полный список роботов Яндекс:
https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.html#check-yandex-robots
И Google:
https://support.google.com/webmasters/answer/1061943?hl=ru
Синтаксис в robots.txt
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.

Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site. ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat.com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.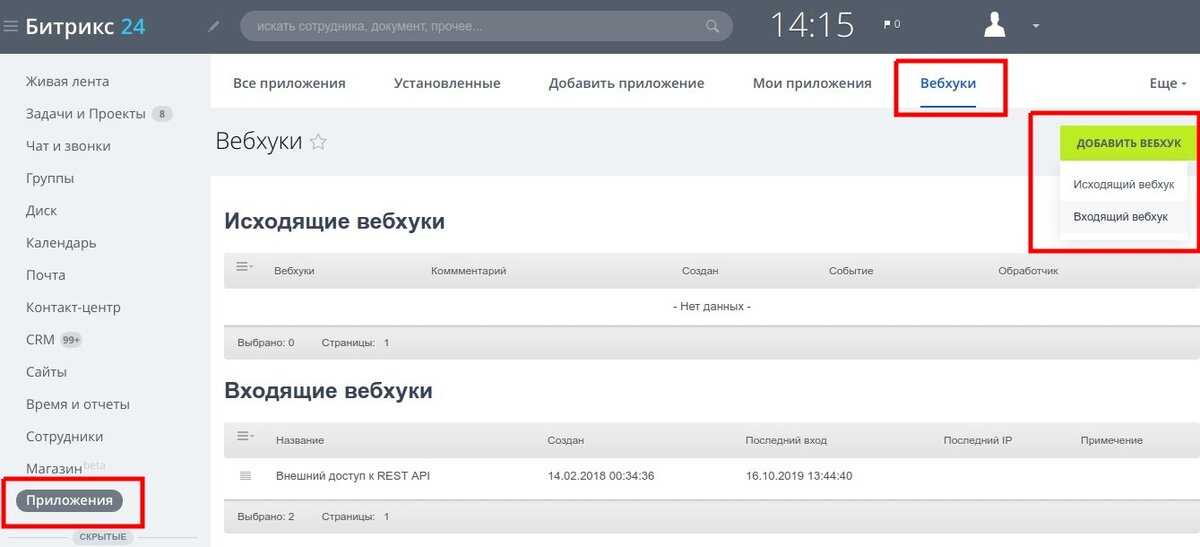
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Robots.txt для сайтов на Битрикс
В интернете можно найти много вариантов файла robots.txt. для сайтов на 1С-Битрикс, но некоторые уже устарели, а другие имеют ошибки. Предлагаем актуальный в 2019 году правильный вариант robots.txt, который учитывает особенности Битрикс последних версий, а также особенности robots.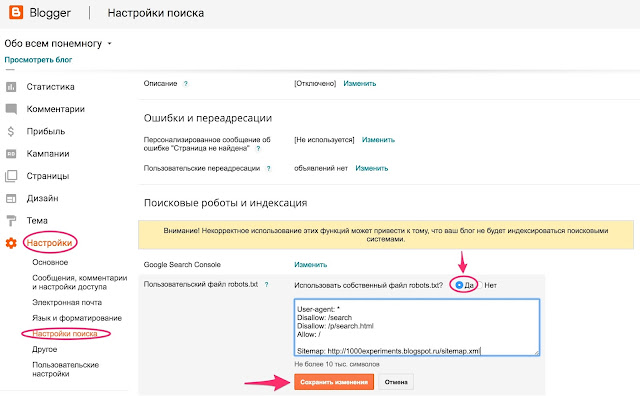 txt для популярных решений Aspro Next, Deluxe, Nextype Magnit и решений корпоративных сайтов Aspro. При подготовке помимо рекомендаций поисковых сиcтем и анализа демо сайтов на решениях мы изучили индексацию реальных сайтов и попадание страниц в исключенные.
txt для популярных решений Aspro Next, Deluxe, Nextype Magnit и решений корпоративных сайтов Aspro. При подготовке помимо рекомендаций поисковых сиcтем и анализа демо сайтов на решениях мы изучили индексацию реальных сайтов и попадание страниц в исключенные.
Особенности предлагаемого robots для сайтов Битрикс
- Учет сортировки
- Фильтрация
- Учет пагинации
- Очистка от get параметров
- Закрытие служебных страниц
- Закрытие личного кабинета
- Работа с папкой local
- Открытие для индексации необходимых поисковикам файлов стилей
- Закрытие доступа наиболее активным и бесполезным ботам и ограничение скорости обхода всем кроме Яндекс и Google для снижения нагрузки
Robots.txt — это текстовый файл, который содержит указания — параметры индексирования сайта для роботов поисковых систем. Поисковики поддерживают стандарт исключений для роботов (Robots Exclusion Protocol) с расширенными возможностями.
Назначение файла robots.txt
Как подсказывает Яндекс файл robots.txt необходим для того, чтобы запретить индексирование разделов сайта или отдельных страниц. Например, закрыть от индексации:
- страницы с конфиденциальными данными;
- страницы с результатами поиска по сайту;
- статистика посещаемости сайта;
- дубликаты страниц;
- разнообразные логи;
- сервисные служебные страницы.
Но. Не стоит забывать, что Google указывает на несколько иное назначение файла robots.txt, указывая основное назначение не запрет индексации, а снижение нагрузки на переобход сайта.
«Файл robots.txt не предназначен для блокировки показа веб-страниц в результатах поиска Google. Если на других сайтах есть ссылки на вашу страницу, содержащие ее описание, то она все равно может быть проиндексирована, даже если роботу Googlebot запрещено ее посещать. Чтобы исключить страницу из результатов поиска, следует использовать другой метод, например защиту паролем или директиву noindex.
 Если файл robots.txt запрещает роботу Googlebot обрабатывать веб-страницу, она все равно может показываться в Google. Чтобы полностью исключить страницу из Google Поиска, следует использовать другие методы.»
Если файл robots.txt запрещает роботу Googlebot обрабатывать веб-страницу, она все равно может показываться в Google. Чтобы полностью исключить страницу из Google Поиска, следует использовать другие методы.»
Пример robots.txt для Битрикс
User-Agent: *
Disallow: */index.php$
Disallow: /bitrix/
Disallow: /personal/
Disallow: */cgi-bin/
Disallow: /local/
Disallow: /test/
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: /*bitrix_include_areas=
Disallow: /*clear_cache=
Disallow: /*clear_cache_session=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*ORDER_BY
Disallow: /*?print=
Disallow: /*?list_style=
Disallow: /*?sort=
Disallow: /*?sort_by=
Disallow: /*?set_filter=
Disallow: /*?arrFilter=
Disallow: /*?order=
Disallow: /*&print=
Disallow: /*print_course=
Disallow: /*?action=
Disallow: /*&action=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: */auth/
Disallow: /*backurl=
Disallow: /*back_url=
Disallow: /*BACKURL=
Disallow: /*BACK_URL=
Disallow: /*back_url_admin=
Disallow: /*?utm_source=
Disallow: */order/
Disallow: /*download
Disallow: /test. php
php
Disallow: */filter/*/apply/
Disallow: /*setreg=
Disallow: /*logout
Disallow: */filter/
Disallow: /*back_url_admin
Disallow: /*sphrase_id
Disallow: */search/
Disallow: /*type=
Disallow: /*?product_id=
Disallow: /*?display=
Disallow: /*?view_mode=
Disallow: /*min_price=
Disallow: /*max_price=
Disallow: /*&page=
Disallow: /*?path=
Disallow: /*?route=
Disallow: /*?products_on_page=
Disallow: /*back_url_admin=
Disallow: /*?PAGEN_1=1$
Disallow: /*?PAGEN_1=1/$
Disallow: /*?new=Y
Disallow: /*?edit=
Disallow: /*?preview=
Disallow: /*SHOWALL=
Disallow: /*SHOW_ALL=
Disallow: /*SHOWBY=
Disallow: /*SPHRASE_ID=
Disallow: /*TYPE=
Disallow: /*?utm*=
Disallow: /*&utm*=
Disallow: /*?ei=
Disallow: /*?p=
Disallow: /*?q=
Disallow: /*?VIEW=
Disallow: /*?SORT_TO=
Disallow: /*?SORT_FIELD=
Disallow: /*set_filter=
Disallow: */auth.php
Disallow: /*?alfaction=
Disallow: /*?oid=
Disallow: /*?name=
Disallow: /*?form_id=
Disallow: /*&form_id=
Disallow: /*?bxajaxid=
Disallow: /*&bxajaxid=
Disallow: /*?view_result=
Disallow: /*&view_result=
Disallow: */resize_cache/
Allow: /bitrix/components/
Allow: /bitrix/cache/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Disallow: /bitrix/panel/
Allow: /local/components/
Allow: /local/cache/
Allow: /local/js/
Allow: /local/templates/
Crawl-delay: 30
Sitemap: https://XXXXCC/sitemap.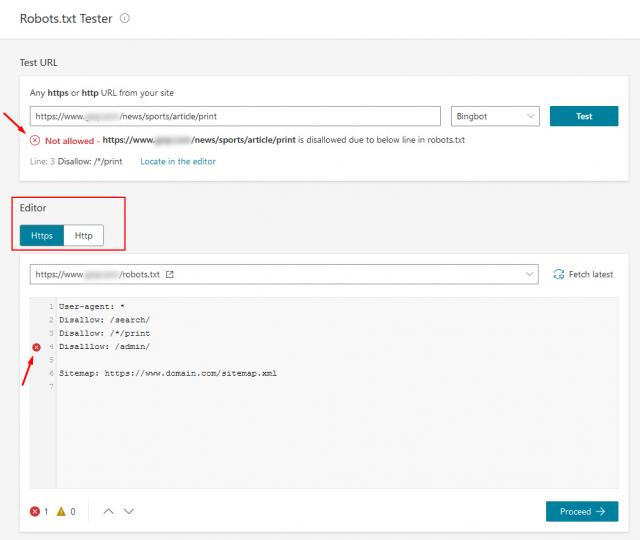 xml
xml
User-Agent: Yandex
Disallow: */index.php$
Disallow: /bitrix/
Disallow: /personal/
Disallow: */cgi-bin/
Disallow: /local/
Disallow: /test/
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: /*bitrix_include_areas=
Disallow: /*clear_cache=
Disallow: /*clear_cache_session=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*ORDER_BY
Disallow: /*?print=
Disallow: /*?list_style=
Disallow: /*?sort=
Disallow: /*?sort_by=
Disallow: /*?set_filter=
Disallow: /*?arrFilter=
Disallow: /*?order=
Disallow: /*&print=
Disallow: /*print_course=
Disallow: /*?action=
Disallow: /*&action=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: */auth/
Disallow: /*backurl=
Disallow: /*back_url=
Disallow: /*BACKURL=
Disallow: /*BACK_URL=
Disallow: /*back_url_admin=
Disallow: /*?utm_source=
Disallow: */order/
Disallow: /*download
Disallow: /test. php
php
Disallow: */filter/*/apply/
Disallow: /*setreg=
Disallow: /*logout
Disallow: */filter/
Disallow: /*back_url_admin
Disallow: /*sphrase_id
Disallow: */search/
Disallow: /*type=
Disallow: /*?product_id=
Disallow: /*?display=
Disallow: /*?view_mode=
Disallow: /*min_price=
Disallow: /*max_price=
Disallow: /*&page=
Disallow: /*?path=
Disallow: /*?route=
Disallow: /*?products_on_page=
Disallow: /*back_url_admin=
Disallow: /*?PAGEN_1=1$
Disallow: /*?PAGEN_1=1/$
Disallow: /*?new=Y
Disallow: /*?edit=
Disallow: /*?preview=
Disallow: /*SHOWALL=
Disallow: /*SHOW_ALL=
Disallow: /*SHOWBY=
Disallow: /*SPHRASE_ID=
Disallow: /*TYPE=
Disallow: /*?utm*=
Disallow: /*&utm*=
Disallow: /*?ei=
Disallow: /*?p=
Disallow: /*?q=
Disallow: /*?VIEW=
Disallow: /*?SORT_TO=
Disallow: /*?SORT_FIELD=
Disallow: /*set_filter=
Disallow: */auth.php
Disallow: /*?alfaction=
Disallow: /*?oid=
Disallow: /*?name=
Disallow: /*?form_id=
Disallow: /*&form_id=
Disallow: /*?bxajaxid=
Disallow: /*&bxajaxid=
Disallow: /*?view_result=
Disallow: /*&view_result=
Disallow: */resize_cache/
Allow: /bitrix/components/
Allow: /bitrix/cache/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Disallow: /bitrix/panel/
Allow: /local/components/
Allow: /local/cache/
Allow: /local/js/
Allow: /local/templates/
Host: https://XXXXXC
Clean-param: setreg&back_url_admin&logout&sphrase_id&action&utm_source&openstat&sort&sort_by&arrFilter&display&bxajaxid&view_mode&set_filter&alfaction&SORT_TO&SORT_FIELD&VIEW&bitrix_include_areas&clear_cache
User-Agent: Googlebot
Disallow: */index. php$
php$
Disallow: /bitrix/
Disallow: /personal/
Disallow: */cgi-bin/
Disallow: /local/
Disallow: /test/
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: /*bitrix_include_areas=
Disallow: /*clear_cache=
Disallow: /*clear_cache_session=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*ORDER_BY
Disallow: /*?print=
Disallow: /*?list_style=
Disallow: /*?sort=
Disallow: /*?sort_by=
Disallow: /*?set_filter=
Disallow: /*?arrFilter=
Disallow: /*?order=
Disallow: /*&print=
Disallow: /*print_course=
Disallow: /*?action=
Disallow: /*&action=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: */auth/
Disallow: /*backurl=
Disallow: /*back_url=
Disallow: /*BACKURL=
Disallow: /*BACK_URL=
Disallow: /*back_url_admin=
Disallow: /*?utm_source=
Disallow: */order/
Disallow: /*download
Disallow: /test. php
php
Disallow: */filter/*/apply/
Disallow: /*setreg=
Disallow: /*logout
Disallow: */filter/
Disallow: /*back_url_admin
Disallow: /*sphrase_id
Disallow: */search/
Disallow: /*type=
Disallow: /*?product_id=
Disallow: /*?display=
Disallow: /*?view_mode=
Disallow: /*min_price=
Disallow: /*max_price=
Disallow: /*&page=
Disallow: /*?path=
Disallow: /*?route=
Disallow: /*?products_on_page=
Disallow: /*back_url_admin=
Disallow: /*?PAGEN_1=1$
Disallow: /*?PAGEN_1=1/$
Disallow: /*?new=Y
Disallow: /*?edit=
Disallow: /*?preview=
Disallow: /*SHOWALL=
Disallow: /*SHOW_ALL=
Disallow: /*SHOWBY=
Disallow: /*SPHRASE_ID=
Disallow: /*TYPE=
Disallow: /*?utm*=
Disallow: /*&utm*=
Disallow: /*?ei=
Disallow: /*?p=
Disallow: /*?q=
Disallow: /*?VIEW=
Disallow: /*?SORT_TO=
Disallow: /*?SORT_FIELD=
Disallow: /*set_filter=
Disallow: */auth.php
Disallow: /*?alfaction=
Disallow: /*?oid=
Disallow: /*?name=
Disallow: /*?form_id=
Disallow: /*&form_id=
Disallow: /*?bxajaxid=
Disallow: /*&bxajaxid=
Disallow: /*?view_result=
Disallow: /*&view_result=
Disallow: */resize_cache/
Allow: /bitrix/components/
Allow: /bitrix/cache/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Disallow: /bitrix/panel/
Allow: /local/components/
Allow: /local/cache/
Allow: /local/js/
Allow: /local/templates/
User-Agent: SemrushBot
Disallow: /
User-Agent: MJ12bot
Disallow: /
User-Agent: AhrefsBot
Disallow: /
User-agent: gigabot
Disallow: /
User-agent: Gigabot/2. 0
0
Disallow: /
User-agent: msnbot
Disallow: /
User-agent: msnbot/1.0
Disallow: /
User-agent: ia_archiver
Disallow: /
User-agent: libwww-perl
Disallow: /
User-agent: NetStat.Ru Agent
Disallow: /
User-agent: WebAlta Crawler/1.3.25
Disallow: /
User-agent: Yahoo!-MMCrawler/3.x
Disallow: /
User-agent: MMCrawler/3.x
Disallow: /
User-agent: NG/2.0
Disallow: /
User-agent: slurp
Disallow: /
User-agent: aipbot
Disallow: /
User-agent: Alexibot
Disallow: /
User-agent: GameSpyHTTP/1.0
Disallow: /
User-agent: Aqua_Products
Disallow: /
User-agent: asterias
Disallow: /
User-agent: b2w/0.1
Disallow: /
User-agent: BackDoorBot/1.0
Disallow: /
User-agent: becomebot
Disallow: /
User-agent: BlowFish/1.0
Disallow: /
User-agent: Bookmark search tool
Disallow: /
User-agent: BotALot
Disallow: /
User-agent: BotRightHere
Disallow: /
User-agent: BuiltBotTough
Disallow: /
User-agent: Bullseye/1. 0
0
Disallow: /
User-agent: BunnySlippers
Disallow: /
User-agent: CheeseBot
Disallow: /
User-agent: CherryPicker
Disallow: /
User-agent: CherryPickerElite/1.0
Disallow: /
User-agent: CherryPickerSE/1.0
Disallow: /
User-agent: Copernic
Disallow: /
User-agent: CopyRightCheck
Disallow: /
User-agent: cosmos
Disallow: /
User-agent: Crescent
Disallow: /
User-agent: Crescent Internet ToolPak HTTP OLE Control v.1.0
Disallow: /
User-agent: DittoSpyder
Disallow: /
User-agent: EmailCollector
Disallow: /
User-agent: EmailSiphon
Disallow: /
User-agent: EmailWolf
Disallow: /
User-agent: EroCrawler
Disallow: /
User-agent: ExtractorPro
Disallow: /
User-agent: FairAd Client
Disallow: /
User-agent: Fasterfox
Disallow: /
User-agent: Flaming AttackBot
Disallow: /
User-agent: Foobot
Disallow: /
User-agent: Gaisbot
Disallow: /
User-agent: GetRight/4. 2
2
Disallow: /
User-agent: Harvest/1.5
Disallow: /
User-agent: hloader
Disallow: /
User-agent: httplib
Disallow: /
User-agent: HTTrack 3.0
Disallow: /
User-agent: humanlinks
Disallow: /
User-agent: IconSurf
Disallow: /
User-agent: InfoNaviRobot
Disallow: /
User-agent: Iron33/1.0.2
Disallow: /
User-agent: JennyBot
Disallow: /
User-agent: Kenjin Spider
Disallow: /
User-agent: Keyword Density/0.9
Disallow: /
User-agent: larbin
Disallow: /
User-agent: LexiBot
Disallow: /
User-agent: libWeb/clsHTTP
Disallow: /
User-agent: LinkextractorPro
Disallow: /
User-agent: LinkScan/8.1a Unix
Disallow: /
User-agent: LinkWalker
Disallow: /
User-agent: LNSpiderguy
Disallow: /
User-agent: lwp-trivial
Disallow: /
User-agent: lwp-trivial/1.34
Disallow: /
User-agent: Mata Hari
Disallow: /
User-agent: Microsoft URL Control
Disallow: /
User-agent: Microsoft URL Control - 5. 01.4511
01.4511
Disallow: /
User-agent: Microsoft URL Control - 6.00.8169
Disallow: /
User-agent: MIIxpc
Disallow: /
User-agent: MIIxpc/4.2
Disallow: /
User-agent: Mister PiX
Disallow: /
User-agent: moget
Disallow: /
User-agent: moget/2.1
Disallow: /
User-agent: MSIECrawler
Disallow: /
User-agent: NetAnts
Disallow: /
User-agent: NICErsPRO
Disallow: /
User-agent: Offline Explorer
Disallow: /
User-agent: Openbot
Disallow: /
User-agent: Openfind
Disallow: /
User-agent: Openfind data gatherer
Disallow: /
User-agent: Oracle Ultra Search
Disallow: /
User-agent: PerMan
Disallow: /
User-agent: ProPowerBot/2.14
Disallow: /
User-agent: ProWebWalker
Disallow: /
User-agent: psbot
Disallow: /
User-agent: Python-urllib
Disallow: /
User-agent: QueryN Metasearch
Disallow: /
User-agent: Radiation Retriever 1.1
Disallow: /
User-agent: RepoMonkey
Disallow: /
User-agent: RepoMonkey Bait & Tackle/v1. 01
01
Disallow: /
User-agent: RMA
Disallow: /
User-agent: searchpreview
Disallow: /
User-agent: SiteSnagger
Disallow: /
User-agent: SpankBot
Disallow: /
User-agent: spanner
Disallow: /
User-agent: SurveyBot
Disallow: /
User-agent: suzuran
Disallow: /
User-agent: Szukacz/1.4
Disallow: /
User-agent: Teleport
Disallow: /
User-agent: TeleportPro
Disallow: /
User-agent: Telesoft
Disallow: /
User-agent: The Intraformant
Disallow: /
User-agent: TheNomad
Disallow: /
User-agent: TightTwatBot
Disallow: /
User-agent: toCrawl/UrlDispatcher
Disallow: /
User-agent: True_Robot
Disallow: /
User-agent: True_Robot/1.0
Disallow: /
User-agent: turingos
Disallow: /
User-agent: TurnitinBot
Disallow: /
User-agent: TurnitinBot/1.5
Disallow: /
User-agent: URL Control
Disallow: /
User-agent: URL_Spider_Pro
Disallow: /
User-agent: URLy Warning
Disallow: /
User-agent: VCI
Disallow: /
User-agent: VCI WebViewer VCI WebViewer Win32
Disallow: /
User-agent: Web Image Collector
Disallow: /
User-agent: WebAuto
Disallow: /
User-agent: WebBandit
Disallow: /
User-agent: WebBandit/3. 50
50
Disallow: /
User-agent: WebCapture 2.0
Disallow: /
User-agent: WebCopier
Disallow: /
User-agent: WebCopier v.2.2
Disallow: /
User-agent: WebCopier v3.2a
Disallow: /
User-agent: WebEnhancer
Disallow: /
User-agent: WebSauger
Disallow: /
User-agent: Website Quester
Disallow: /
User-agent: Webster Pro
Disallow: /
User-agent: WebStripper
Disallow: /
User-agent: WebZip
Disallow: /
User-agent: WebZip
Disallow: /
User-agent: WebZip/4.0
Disallow: /
User-agent: WebZIP/4.21
Disallow: /
User-agent: WebZIP/5.0
Disallow: /
User-agent: Wget
Disallow: /
User-agent: wget
Disallow: /
User-agent: Wget/1.5.3
Disallow: /
User-agent: Wget/1.6
Disallow: /
User-agent: WWW-Collector-E
Disallow: /
User-agent: Xenu's
Disallow: /
User-agent: Xenu's Link Sleuth 1.1c
Disallow: /
User-agent: Zeus
Disallow: /
User-agent: Zeus 32297 Webster Pro V2. 9 Win32
9 Win32
Disallow: /
User-agent: Zeus Link Scout
Disallow: /
User-agent: EmailSiphon
Disallow: /
User-agent: EmailCollector
Disallow: /
Настройка robots.txt
Начиная с версии 14 модуля Поисковая оптимизация больше не требуется создавать вручную файл robots.txt для сайта. Теперь его создание можно выполнять с помощью специального генератора, который доступен на странице Управление robots.txt (Маркетинг > Поисковая оптимизация > Настройка robots.txt). Форма, представленная на данной странице, позволяет создать, управлять и следить за файлом robots.txt вашего сайта. В админпанели Битрикс robots.txt можно сформировать в автоматическом режиме или исправить вручную. Настройки в админпанели Битрикса доступны по адресу /bitrix/admin/seo_robots.php?lang=ru
Если в системе несколько сайтов, то с помощью кнопки контекстной панели не забывайте переключаться к нужному сайту, для которого необходимо просмотреть/создать файл robots. txt.
txt.
На закладке «Общие правила» создаются инструкции, которые действуют для всех поисковых систем (ботов). Генерация необходимых правил осуществляется с помощью кнопок:
На закладках «Яндекс и Google» настраиваются правила для ботов Яндекса и Google соответственно. Специальные правила для конкретных ботов настраиваются аналогично общим правилам, для них не задается только базовый набор правил и путь к файлу карты сайта. Кроме того, с помощью ссылок, доступных внизу формы, вы можете ознакомиться с документацией Яндекса и Google по использованию файла robots.txt.
Частые ошибки в robots.txt
Закрытие страниц пагинации.
- В предлагаемом варианте файла страницы открыты, исключен только дубль первой страницы, которая часто открывается как с параметром PAGEN так и без него. Все остальные страницы пагинации не имеют запрета на индексацию.
Леонтьева Ольга, специалист по маркетингу APRIORUM GROUP
Страницы пагинации стоит оставлять открытыми для индексирования, но закрывать их дубли.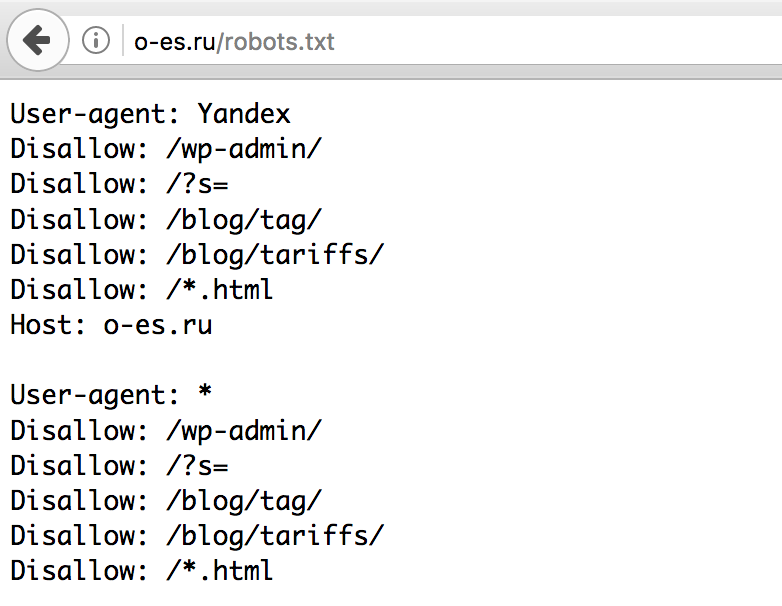 Дубли части создаются при использовании на сайте выбора «Показывать по» или сортировок. Также необходимо правильно организовать закрытие дублей при наличии выборки постранично и «показать все» одновременно. Дополнительно желательно убрать дублирование описания категории на страницах пагинации кроме первой, а также добавить уникализирующее дополнение с номером страниц в мета-теги (это может быть например «Стр. 2 из 100» или «25 запчастей из 1000» или «Страница 2 каталога»).
Дубли части создаются при использовании на сайте выбора «Показывать по» или сортировок. Также необходимо правильно организовать закрытие дублей при наличии выборки постранично и «показать все» одновременно. Дополнительно желательно убрать дублирование описания категории на страницах пагинации кроме первой, а также добавить уникализирующее дополнение с номером страниц в мета-теги (это может быть например «Стр. 2 из 100» или «25 запчастей из 1000» или «Страница 2 каталога»).
Пропуски строк
- Недопустимо наличие пустых переводов строки между директивами User-agent, Disallow и Allow.
Неправильный регистр имени файла
- Название файла пишется без использования верхнего регистра.
Неправильный регистр путей в файле
- Робот учитывает регистр в написании подстрок (имя или путь до файла, имя робота) и не учитывает регистр в названиях директив.
Закрытие от индексации самого файла robots
- В этом случае поисковые роботы не учитывают директивы файла.

Использование кириллицы
- Использование кириллицы запрещено в файле robots.txt и HTTP-заголовках сервера.
Для указания имен доменов используйте Punycode.
Неверный протокол
- Протокол, указываемый для sitemap, необходимо обновлять после перевода сайта с http на https.
Дополнительные особенности
Crawl-Delay
- Вместо Crawl-Delay Яндекс рекомендует вместо директивы использовать настройку скорости обхода в Яндекс.Вебмастере.
Директивы для Google с 2019 года
- С 1 сентября 2019г. Google прекратил следовать директивам, которые не поддерживаются и не опубликованы в robots exclusion protocol. Изменения были анонсированы в блоге компании.
Динамический роботс для мультирегиональности или мультисайтовости
- Инструкции по настройке robots для сайтов с мультисайтовостью на поддоменах (в том числе многогородовости) можно найти в уроках 1С-Битрикс и, например, инструкциях к решениям Aspro.
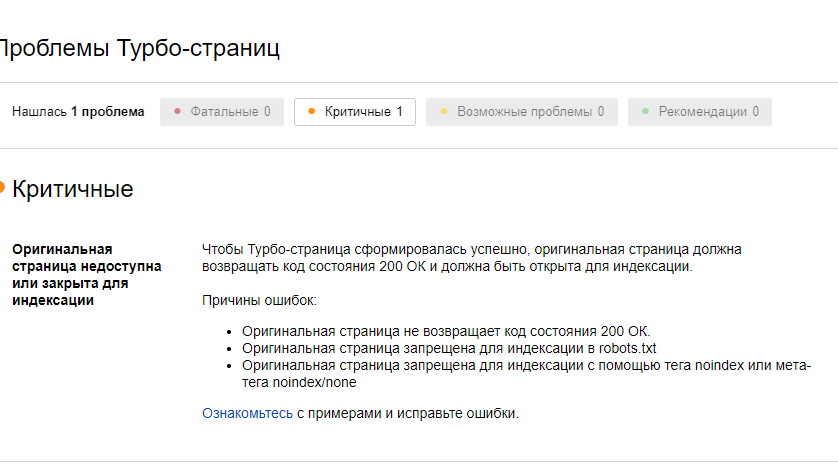
Проверка robots.txt
- После размещения файла желательно выполнить проверку robots.txt (например, проверить robots.txt онлайн можно инструментом Яндекс Вебмастер).
Частый вопрос про директиву Disallow
Часто задают вопрос равнозначны ли директивы:
Disallow: /auth/
Disallow: */auth/
Disallow: /auth
Disallow: /auth/*
Директивы не совсем равнозначны. Например, Disallow: /auth/ запрещает именно раздел http://site.ru/auth/ (начиная от первого уровня чпу), при этом страницы вида https://site.ru/info/auth/help/page останутся доступны при использовании такой директивы. Disallow: /auth/* — альтернативная запись директивы. Директива Disallow: /auth запретит все ссылки, которые начинаются с адреса http://site.ru/auth, например, страница http://site.ru/authentication тоже попадет под запрет. Директива Disallow: */auth/ корректно запретит страницу к индексированию на любом уровне.
Правильный Robots.txt для сайтов на Битрикс в 2022 году
| User-agent: Яндекс | |
| Разрешить: /search/map.php | |
| Запретить: /*&bxajaxid= | |
| Запретить: /*&print= | |
| Запретить: /*/галерея/*заказ=* | |
| Запретить: /*/поиск/ | |
| Запретить: /*/slide_show/ | |
| Запретить: /*?bxajaxid= | |
| Запретить: /*?print= | |
| Запретить: /*?utm_source= | |
| Запретить: /*действие= | |
| Запретить: /*аутентификация= | |
| Запретить: /*back_url= | |
| Запретить: /*BACK_URL= | |
| Запретить: /*back_url_admin= | |
| Запретить: /*backurl= | |
| Запретить: /*BACKURL= | |
| Запретить: /*bitrix_*= | |
| Запретить: /*change_password= | |
| Запретить: /*clear_cache*= | |
| Запретить: /*forgot_password= | |
| Запретить: /*логин= | |
| Запретить: /*выход= | |
| Запретить: /*ORDER_BY | |
| Запретить: /*PAGE_NAME= | |
| Запретить: /*PAGEN_* | |
| Запретить: /*print | |
| Запретить: /*регистр= | |
| Запретить: /*show_all= | |
| Запретить: /*show_include_exec_time= | |
| Запретить: /*show_page_exec_time= | |
| Запретить: /*show_sql_stat= | |
| Запретить: /*ПОКАЗАТЬ | |
| Запретить: /auth/ | |
| Запретить: /bitrix/ | |
| Запретить: /личный/ | |
Хост: domain. ru ru | |
| # Хост: https://domain.ru | |
| Карта сайта: http://domain.ru/sitemap.xml | |
| Агент пользователя: * | |
| Разрешить: /search/map.php | |
| Запретить: /*&bxajaxid= | |
| Запретить: /*&print= | |
| Запретить: /*/галерея/*заказ=* | |
| Запретить: /*/поиск/ | |
| Запретить: /*/slide_show/ | |
| Запретить: /*?bxajaxid= | |
| Запретить: /*?print= | |
| Запретить: /*?utm_source= | |
| Запретить: /*действие= | |
| Запретить: /*аутентификация= | |
| Запретить: /*back_url= | |
| Запретить: /*BACK_URL= | |
| Запретить: /*back_url_admin= | |
| Запретить: /*backurl= | |
| Запретить: /*BACKURL= | |
| Запретить: /*bitrix_*= | |
| Запретить: /*change_password= | |
| Запретить: /*clear_cache*= | |
| Запретить: /*forgot_password= | |
| Запретить: /*логин= | |
| Запретить: /*выход= | |
| Запретить: /*ORDER_BY | |
| Запретить: /*PAGE_NAME= | |
| Запретить: /*PAGEN_* | |
| Запретить: /*print | |
| Запретить: /*регистр= | |
| Запретить: /*show_all= | |
| Запретить: /*show_include_exec_time= | |
| Запретить: /*show_page_exec_time= | |
| Запретить: /*show_sql_stat= | |
| Запретить: /*ПОКАЗАТЬ | |
| Запретить: /auth/ | |
| Запретить: /bitrix/ | |
| Запретить: /личный/ |
Руководство по Robots.
 txt — как создать идеальный файл robots.txt для SEO
txt — как создать идеальный файл robots.txt для SEO
Что такое robots.txt?
Robots.txt — это текстовый файл, содержащий рекомендации по сканированию для ботов. Это часть протокола исключения роботов (REP), группы веб-стандартов, которые регулируют то, как боты просматривают, получают доступ, индексируют и представляют контент пользователям. Файл содержит инструкции (директивы), с помощью которых вы можете ограничить доступ ботов к определенным разделам, страницам и файлам или указать адрес Sitemap.
Большинство основных поисковых систем, таких как Google, Bing и Yahoo, начинают сканирование веб-сайтов, проверяя файл robots.txt и следуя предписанным рекомендациям.
Почему файл robots.txt важен?
Большинству веб-сайтов, ориентированных в основном на Google, может не понадобиться файл robots.txt. Это связано с тем, что Google рассматривает их исключительно как рекомендации, а Googlebot обычно находит и индексирует все важные страницы независимо от них.
Robots.txt содержит рекомендации для поисковых ботов по навигации по сайту
Следовательно, если этот файл не будет создан, это не будет критической ошибкой. В этом случае поисковые роботы будут считать, что ограничений нет, и они могут свободно сканировать.
Несмотря на это, есть 3 основные причины, по которым вам действительно следует использовать robots.txt:
- Он оптимизирует краулинговый бюджет . Если у вас большой сайт, важно, чтобы поисковые роботы просканировали все важные страницы. Однако иногда сканеры находят и индексируют вспомогательные страницы, например страницы фильтров, игнорируя при этом основные. Вы можете исправить эту ситуацию, заблокировав несущественные страницы через robots.txt.
- Скрывает непубличные страницы . Не все на вашем сайте нужно индексировать. Хорошим примером являются страницы авторизации или тестирования. Хотя объективно они должны существовать, вы можете заблокировать их с помощью файла robots. txt, чтобы они не попадали в индекс поисковых систем и были недоступны для случайных людей.
- Предотвращает индексирование изображений и PDF-файлов . Есть несколько способов предотвратить индексацию страниц без использования robots.txt. Однако ни один из них не работает хорошо, когда дело доходит до медиафайлов. Поэтому, если вы не хотите, чтобы поисковые системы индексировали изображения или PDF-файлы на вашем сайте, проще всего заблокировать их с помощью файла robots.txt.
 txt, чтобы они не попадали в индекс поисковых систем и были недоступны для случайных людей.
txt, чтобы они не попадали в индекс поисковых систем и были недоступны для случайных людей.Требования к файлу
Для корректной обработки файла поисковыми ботами необходимо соблюдать следующие правила:
- Он должен находиться в корневом каталоге сайта.
- Он должен называться robots.txt и быть доступен по адресу https://yoursite.com/robots.txt.
- Допускается только один такой файл на сайт.
- Кодировка UTF-8.
Синтаксис robots.txt
Директивы
Файл robots. txt включает две основные директивы — User-agent и Disallow , но есть и дополнительные, такие как Allow и Sitemap . Давайте подробнее рассмотрим, какую информацию они передают и как правильно ее добавить.
txt включает две основные директивы — User-agent и Disallow , но есть и дополнительные, такие как Allow и Sitemap . Давайте подробнее рассмотрим, какую информацию они передают и как правильно ее добавить.
С помощью правильных директив вы можете заблокировать отдельные страницы или весь сайт
User-agent
Это обязательная директива. Он определяет, к каким поисковым ботам применяются правила.
Существует множество роботов, способных сканировать веб-сайты, наиболее распространенными из которых являются боты поисковых систем.
Некоторые из ботов Google включают:
- Googlebot;
- Googlebot-изображение;
- Googlebot-Новости.
Полный список User-Agent , используемый поисковыми системами, можно найти в их документации. Для Google это выглядит так.
Имейте в виду, что некоторые сканеры могут иметь более одного токена пользовательского агента. Для корректного применения правила важно, чтобы маркер соответствовал только одному сканеру.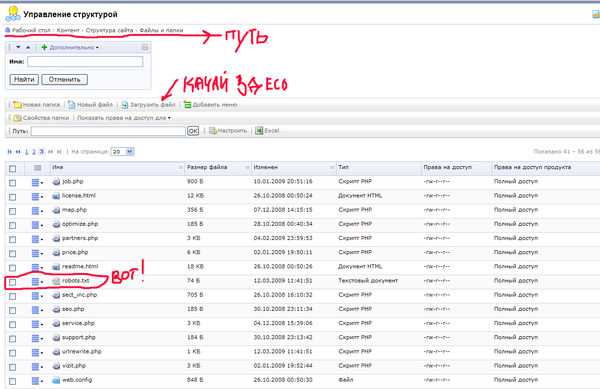
Чтобы обратиться к конкретному боту, например Googlebot Image, вам необходимо ввести его имя в поле Агент пользователя строка:
Агент пользователя: Googlebot-Image
Если вы хотите применить правила ко всем ботам, используйте звездочку (*). Пример:
User-agent: *
Disallow
Указывает на страницу и каталог корневого домена, которые указанный User-agent не может сканировать. Используйте директиву Disallow , чтобы запретить доступ ко всему сайту, каталогу или определенной странице.
1. Если вы хотите ограничить доступ ко всему сайту, добавьте косую черту ( /). Например, чтобы запретить всем роботам доступ ко всему сайту, в файле robots.txt необходимо указать следующее:
User-agent: * Disallow: /
Вам может понадобиться использовать такую комбинацию, если ваш сайт находится на ранних стадиях разработки, когда вы хотите, чтобы он отображался в результатах поиска полностью завершенным.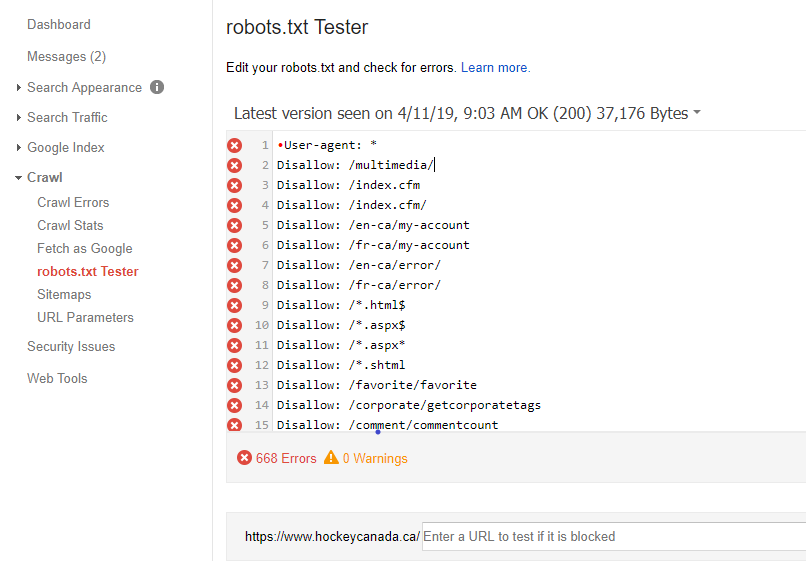
2. Чтобы ограничить доступ к содержимому каталога, используйте его имя, за которым следует косая черта. Например, чтобы запретить всем ботам доступ к каталог блога, в файле нужно написать следующее:
User-agent: * Disallow: /blog/
3. Если вам нужно закрыть конкретную страницу, вы должны указать ее URL без хоста. Например, чтобы закрыть страницу https://yoursite.com/blog/website.html , вы должны написать в файле следующее:
User-agent: * Запретить: /blog/website.html
Разрешить
Указывает страницу и каталог корневого домена, которые могут быть просканированы указанным User-agent и считается необязательной директивой. Если ограничение не указано, то по умолчанию боты могут беспрепятственно сканировать сайт. Таким образом, следующее является совершенно необязательным:
User-agent: * Разрешить: /
Однако вам нужно будет использовать эту директиву, чтобы переопределить ограничение директивы Disallow. По сути, его можно использовать для сканирования части ограниченного раздела или сайта. Например, если вы хотите ограничить доступ ко всем страницам в /blog/ каталог кроме https://yoursite.com/blog/website.html , вам нужно будет указать следующее:
По сути, его можно использовать для сканирования части ограниченного раздела или сайта. Например, если вы хотите ограничить доступ ко всем страницам в /blog/ каталог кроме https://yoursite.com/blog/website.html , вам нужно будет указать следующее:
User-agent: * Запретить: /блог/ Разрешить: /blog/website.html
Карта сайта
Эта необязательная директива служит для указания местоположения файла Sitemap.xml сайта. Если на вашем сайте несколько файлов Sitemap, вы можете указать их все.
Обязательно укажите полный URL-адрес файла Sitemap.xml. Директиву можно разместить в любом месте файла, но чаще всего это делается в самом конце. Файл robots.txt со ссылками на несколько Sitemap.xml будет выглядеть так:
Агент пользователя: * Карта сайта: https://yoursite.com.com/sitemap1.xml Карта сайта: https://yoursite.com.com/sitemap2.xml
Специальные символы $, *, /, #
1. Символ звездочки (*) обозначает любую последовательность символов. В приведенном ниже примере использование звездочки запрещает доступ ко всем URL-адресам, содержащим слово веб-сайт :
В приведенном ниже примере использование звездочки запрещает доступ ко всем URL-адресам, содержащим слово веб-сайт :
User-agent: * Disallow: /*website
Этот специальный символ добавляется в конце каждой строки по умолчанию. Таким образом, два приведенных ниже примера означают, по сути, одно и то же:
Агент пользователя: * Disallow: /website*
Пользовательский агент: * Disallow: /website
2. Чтобы переопределить звездочку (*), вы должны включить знак доллара ($) в конце правила.
Например, чтобы запретить доступ к /website , но разрешить его /website.html , вы можете написать:
User-agent: * Disallow: /website$
3. Косая черта — это основной символ, обычно встречающийся в каждой директиве Allow и Disallow. С его помощью вы можете запретить доступ к /blog/ и ее содержимое или все страницы, начинающиеся с /blog .
Пример директивы, запрещающей доступ ко всей /блог/ категории:
User-agent: * Disallow: /blog/
Пример директивы, запрещающей доступ ко всем страницам, начинающимся с /blog :
User-agent: * Запретить: /blog
4. Знак номера (#) используется для добавления комментариев внутри файла для себя, пользователей или других веб-мастеров. Поисковые роботы проигнорируют эту информацию.
Знак номера (#) используется для добавления комментариев внутри файла для себя, пользователей или других веб-мастеров. Поисковые роботы проигнорируют эту информацию.
Агент пользователя: * Запретить: /блог #это не так сложно, как может показаться :)
Пошаговое руководство по созданию robots.txt
1. Создайте файл robots.txt
Для этого можно использовать любой текстовый редактор, например как блокнот. Если ваш текстовый редактор предложит вам выбрать кодировку при сохранении файла, обязательно выберите UTF-8.
2. Добавить правила для роботов
Правила — это инструкции для поисковых ботов, указывающие, какие разделы сайта можно сканировать. В своих рекомендациях Google рекомендует учитывать следующее:
- Файл robots.txt содержит одну или несколько групп.
- Каждая группа начинается со строки User-agent . Это определяет, к какому роботу относятся правила.
- Каждая группа может включать несколько директив, но по одной на строку.
- Поисковые роботы обрабатывают группы сверху вниз. Пользовательский агент может следовать только одному наиболее подходящему для него набору правил, который будет обрабатываться в первую очередь.
- По умолчанию агенту пользователя разрешено сканировать любые страницы и каталоги, которые не заблокированы правилом запрета.
- Правила чувствительны к регистру.
- Строки, не соответствующие ни одной из директив, будут игнорироваться.
 Это определяет, к какому роботу относятся правила.
Это определяет, к какому роботу относятся правила.3. Загрузите файл robots.txt в корневой каталог
После создания сохраните файл robots.txt на компьютере, затем загрузите его в корневой каталог вашего сайта и сделайте его доступным для поисковых систем.
4. Проверить наличие и правильность файла robots.txt
Чтобы проверить, доступен ли файл, вам необходимо открыть браузер в режиме инкогнито и посетить https://yoursite. com/robots.txt . Если вы видите содержимое и оно соответствует тому, что вы указали, вы можете приступить к проверке корректности директив.
com/robots.txt . Если вы видите содержимое и оно соответствует тому, что вы указали, вы можете приступить к проверке корректности директив.
Вы можете протестировать файл robots.txt с помощью специального инструмента в Google Search Console. Имейте в виду, что его можно использовать только для файлов robots.txt, которые уже доступны на вашем сайте.
Проверив Google Search Console, вы можете убедиться, что все директивы добавлены правильно
Шаблоны robots.txt для различных CMS
Если на вашем сайте установлена CMS, обратите внимание на страницы, которые она генерирует, особенно на те, которые не должны индексироваться поисковыми системами. Чтобы этого не произошло, нужно закрыть их в robots.txt. Поскольку это распространенная проблема, существуют шаблоны файлов для сайтов, использующих различные популярные CMS. Вот некоторые из них.
Robots.txt для WordPress
User-Agent: * Запретить: /wp-login.
 php
Запретить: /wp-register.php
Запретить: /xmlrpc.php
Запретить: /template.html
Запретить: /wp-admin
Запретить: /wp-includes
Запретить: /wp-контент
Разрешить: /wp-content/uploads/
Запретить: /тег
Запретить: /категория
Запретить: /архив
Запретить: */трекбэк/
Запретить: */канал/
Запретить: */комментарии/
Запретить: /?feed=
Запретить: /?s=
Разрешить: /wp-content/*.css*
Разрешить: /wp-content/*.jpg
Разрешить: /wp-content/*.gif
Разрешить: /wp-content/*.png
Разрешить: /wp-content/*.js*
Разрешить: /wp-includes/js/
Карта сайта: http://yoursite.com/sitemap.xml
php
Запретить: /wp-register.php
Запретить: /xmlrpc.php
Запретить: /template.html
Запретить: /wp-admin
Запретить: /wp-includes
Запретить: /wp-контент
Разрешить: /wp-content/uploads/
Запретить: /тег
Запретить: /категория
Запретить: /архив
Запретить: */трекбэк/
Запретить: */канал/
Запретить: */комментарии/
Запретить: /?feed=
Запретить: /?s=
Разрешить: /wp-content/*.css*
Разрешить: /wp-content/*.jpg
Разрешить: /wp-content/*.gif
Разрешить: /wp-content/*.png
Разрешить: /wp-content/*.js*
Разрешить: /wp-includes/js/
Карта сайта: http://yoursite.com/sitemap.xml Robots.txt для Joomla
User-agent: * Запретить: /администратор/ Запретить: /кеш/ Запретить: /компоненты/ Запретить: /изображения/ Запретить: /включает/ Запретить: /установка/ Запретить: /язык/ Запретить: /библиотеки/ Запретить: /медиа/ Запретить: /модули/ Запретить: /плагины/ Запретить: /шаблоны/ Запретить: /tmp/ Запретить: /xmlrpc/ Разрешить: /templates/*.css Разрешить: /templates/*.
 js
Разрешить: /media/*.png
Разрешить: /media/*.js
Разрешить: /modules/*.css
Разрешить: /modules/*.js
Карта сайта: http://yoursite.com/sitemap.xml
js
Разрешить: /media/*.png
Разрешить: /media/*.js
Разрешить: /modules/*.css
Разрешить: /modules/*.js
Карта сайта: http://yoursite.com/sitemap.xml Robots.txt для Битрикс
User-agent: * Запретить: /*index.php$ Запретить: /bitrix/ Запретить: /авторизация/ Запретить: /личные/ Запретить: /загрузить/ Запретить: /поиск/ Запретить: /*/поиск/ Запретить: /*/slide_show/ Запретить: /*/галерея/*порядок=* Запретить: /*?* Запретить: /*&print= Запретить: /*регистр= Запретить: /*forgot_password= Запретить: /*change_password= Запретить: /*логин= Запретить: /*выйти= Запретить: /*аутентификация= Запретить: /*действие=* Запретить: /*bitrix_*= Запретить: /*backurl=* Запретить: /*BACKURL=* Запретить: /*back_url=* Запретить: /*BACK_URL=* Запретить: /*back_url_admin=* Запретить: /*print_course=Y Запретить: /*COURSE_ID= Разрешить: /bitrix/*.css Разрешить: /bitrix/*.js Карта сайта: http://yoursite.com/sitemap.xml
Некоторые практические вещи, о которых вы могли не знать
Проиндексировано, но заблокировано robots.
 txt
txt
Иногда вы можете увидеть это предупреждение в Google Search Console. Это происходит, когда Google воспринимает директивы, изложенные в robots.txt, как рекомендации, а не как правила, и фактически игнорирует их. И хотя представители Google не видят в этом критической проблемы, на самом деле это может привести к тому, что будет проиндексировано множество ненужных страниц.
Экран «Проиндексировано, но заблокировано robots.txt» в Google Search Console
Чтобы решить эту проблему, следуйте этим рекомендациям:
❓ Определите, нужно ли индексировать эти страницы. Посмотрите, какую информацию они содержат и нужны ли они для привлечения пользователей из поиска.
✅ Если вы не хотите, чтобы эти страницы блокировались, найдите директиву, отвечающую за это, в вашем файле robots.txt. Если ответ не очевиден без сторонних инструментов, вы можете сделать это с помощью тестового инструмента robots.txt.
Результаты после проверки того, какая директива блокирует URL-адрес
Обновите файл robots. txt, не включая эту директиву. Кроме того, вы можете указать URL-адрес, который вы хотите проиндексировать, с помощью Разрешить , если вам нужно скрыть другие менее полезные URL-адреса.
txt, не включая эту директиву. Кроме того, вы можете указать URL-адрес, который вы хотите проиндексировать, с помощью Разрешить , если вам нужно скрыть другие менее полезные URL-адреса.
❌Robots.txt — не самый надежный механизм, если вы хотите заблокировать эту страницу для поиска Google. Чтобы избежать индексации, удалите предыдущую строку, использовавшуюся для этого, в файле robots.txt и добавьте на страницу метамета «noindex» .
Важно! Для без индекса , файл robots.txt не должен блокировать доступ к странице для поисковых роботов. В противном случае боты не смогут обработать код страницы и не обнаружат метатег noindex . В результате содержимое этой страницы по-прежнему будет отображаться в результатах поиска, если, например, другие сайты предоставляют на него ссылки.
Если вам нужно закрыть сайт на время с кодом 503, не делайте этого для robots.txt
Когда сайт находится на капитальном обслуживании или есть другие важные причины, вы можете временно приостановить или отключить его, таким образом предотвращая доступ как для ботов, так и для пользователей.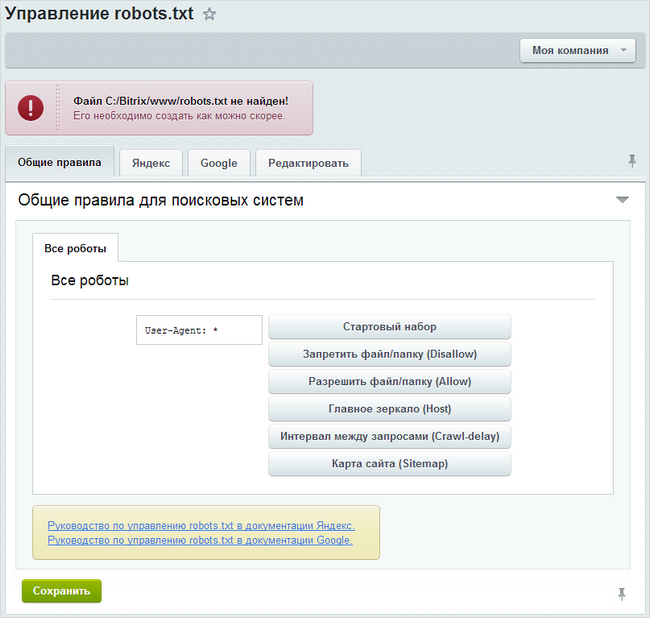 Для этого они используют 503 код ответа сервера.
Для этого они используют 503 код ответа сервера.
Однако Джон Мюллер, советник по поиску в Google, показал в теме Twitter, что вам нужно сделать и проверить, чтобы временно приостановить работу вашего сайта.
По словам Джона, файл robots.txt никогда не должен возвращать 503 , поскольку робот Google будет считать, что сайт полностью заблокирован через robots.txt. Для этого файл robots.txt должен возвращать 200 OK, имея в файле все необходимые директивы, или 404 .
Если файл robots.txt передается с ошибкой 503, роботы будут считать, что сайт полностью заблокирован robots.txt
Заключение
Robots.txt — полезный инструмент для формирования взаимодействия между роботами поисковых систем и вашим сайтом. При правильном использовании это может положительно повлиять на рейтинг сайта, позволяя вам эффективно управлять индексацией ваших документов.
Мы надеемся, что это руководство поможет вам понять, как работают файлы robots.