Содержание
Что такое Big Data и почему их называют «новой нефтью»
Тренды
Телеканал
Pro
Инвестиции
Мероприятия
РБК+
Новая экономика
Тренды
Недвижимость
Спорт
Стиль
Национальные проекты
Город
Крипто
Дискуссионный клуб
Исследования
Кредитные рейтинги
Франшизы
Газета
Спецпроекты СПб
Конференции СПб
Спецпроекты
Проверка контрагентов
РБК Библиотека
Подкасты
ESG-индекс
Политика
Экономика
Бизнес
Технологии и медиа
Финансы
РБК КомпанииРБК Life
РБК
Тренды
Фото: Mint Images / Shutterstock
Смартфоны предлагают нам загрузить все данные в облако, а большие компании вроде Google и «Яндекса» — воспользоваться своими экосистемами. Проще говоря, мы живем в эпоху Big Data. Но что это значит на самом деле?
Проще говоря, мы живем в эпоху Big Data. Но что это значит на самом деле?
1
Что такое Big Data?
Big Data или большие данные — это структурированные или неструктурированные массивы данных большого объема. Их обрабатывают при помощи специальных автоматизированных инструментов, чтобы использовать для статистики, анализа, прогнозов и принятия решений.
Сам термин «большие данные» предложил редактор журнала Nature Клиффорд Линч в спецвыпуске 2008 года [1]. Он говорил о взрывном росте объемов информации в мире. К большим данным Линч отнес любые массивы неоднородных данных более 150 Гб в сутки, однако единого критерия до сих пор не существует.
«Лиза Алерт» использует Big Data, чтобы находить пропавших людей
До 2011 года анализом больших данных занимались только в рамках научных и статистических исследований. Но к началу 2012-го объемы данных выросли до огромных масштабов, и возникла потребность в их систематизации и практическом применении.
Всплеск интереса к большим данным в Google Trends
С 2014 на Big Data обратили внимание ведущие мировые вузы, где обучают прикладным инженерным и ИТ-специальностям.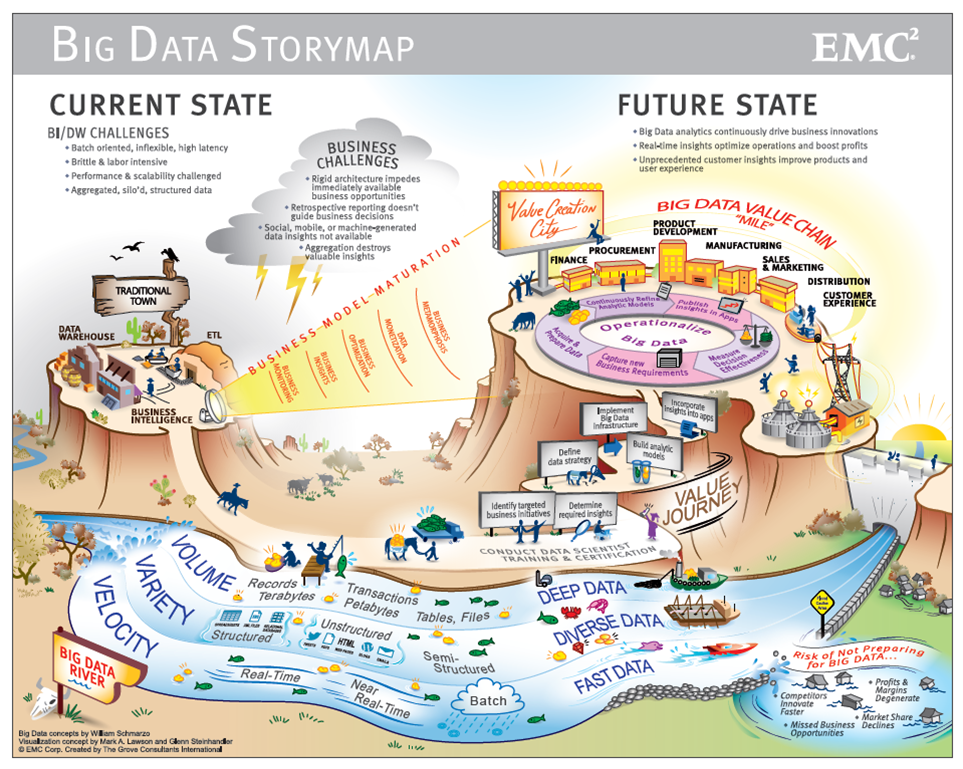 Затем к сбору и анализу подключились ИТ-корпорации — такие, как Microsoft, IBM, Oracle, EMC, а затем и Google, Apple, Facebook и Amazon. Сегодня большие данные используют крупные компании во всех отраслях, а также — госорганы. Подробнее об этом — в материале «Кто и зачем собирает большие данные?»
Затем к сбору и анализу подключились ИТ-корпорации — такие, как Microsoft, IBM, Oracle, EMC, а затем и Google, Apple, Facebook и Amazon. Сегодня большие данные используют крупные компании во всех отраслях, а также — госорганы. Подробнее об этом — в материале «Кто и зачем собирает большие данные?»
2
Какие есть характеристики Big Data?
Компания Meta Group предложила основные характеристики больших данных [2]:
- Volume — объем данных: от 150 Гб в сутки;
- Velocity — скорость накопления и обработки массивов данных. Большие данные обновляются регулярно, поэтому необходимы интеллектуальные технологии для их обработки в режиме онлайн;
- Variety — разнообразие типов данных. Данные могут быть структурированными, неструктурированными или структурированными частично. Например, в соцсетях поток данных не структурирован: это могут быть текстовые посты, фото или видео.
Сегодня к этим трем добавляют еще три признака [3]:
- Veracity — достоверность как самого набора данных, так и результатов его анализа;
- Variability — изменчивость.
 У потоков данных бывают свои пики и спады под влиянием сезонов или социальных явлений. Чем нестабильнее и изменчивее поток данных, тем сложнее его анализировать;
У потоков данных бывают свои пики и спады под влиянием сезонов или социальных явлений. Чем нестабильнее и изменчивее поток данных, тем сложнее его анализировать; - Value — ценность или значимость. Как и любая информация, большие данные могут быть простыми или сложными для восприятия и анализа. Пример простых данных — это посты в соцсетях, сложных — банковские транзакции.
 У потоков данных бывают свои пики и спады под влиянием сезонов или социальных явлений. Чем нестабильнее и изменчивее поток данных, тем сложнее его анализировать;
У потоков данных бывают свои пики и спады под влиянием сезонов или социальных явлений. Чем нестабильнее и изменчивее поток данных, тем сложнее его анализировать;
3
Как работает Big Data: как собирают и хранят большие данные?
Большие данные необходимы, чтобы проанализировать все значимые факторы и принять правильное решение. С помощью Big Data строят модели-симуляции, чтобы протестировать то или иное решение, идею, продукт.
Главные источники больших данных:
- интернет вещей (IoT) и подключенные к нему устройства;
- соцсети, блоги и СМИ;
- данные компаний: транзакции, заказы товаров и услуг, поездки на такси и каршеринге, профили клиентов;
- показания приборов: метеорологические станции, измерители состава воздуха и водоемов, данные со спутников;
- статистика городов и государств: данные о перемещениях, рождаемости и смертности;
- медицинские данные: анализы, заболевания, диагностические снимки.

С 2007 года в распоряжении ФБР и ЦРУ появилась PRISM — один из самых продвинутых сервисов, который собирает персональные данные обо всех пользователях соцсетей, а также сервисов Microsoft, Google, Apple, Yahoo и даже записи телефонных разговоров.
Современные вычислительные системы обеспечивают мгновенный доступ к массивам больших данных. Для их хранения используют специальные дата-центры с самыми мощными серверами.
Как выглядит современный дата-центр
Помимо традиционных, физических серверов используют облачные хранилища, «озера данных» (data lake — хранилища большого объема неструктурированных данных из одного источника) и Hadoop — фреймворк, состоящий из набора утилит для разработки и выполнения программ распределенных вычислений. Для работы с Big Data применяют передовые методы интеграции и управления, а также подготовки данных для аналитики.
4
Big Data Analytics — как анализируют большие данные?
Благодаря высокопроизводительным технологиям — таким, как грид-вычисления или аналитика в оперативной памяти, компании могут использовать любые объемы больших данных для анализа. Иногда Big Data сначала структурируют, отбирая только те, что нужны для анализа. Все чаще большие данные применяют для задач в рамках расширенной аналитики, включая искусственный интеллект.
Иногда Big Data сначала структурируют, отбирая только те, что нужны для анализа. Все чаще большие данные применяют для задач в рамках расширенной аналитики, включая искусственный интеллект.
Выделяют четыре основных метода анализа Big Data [4]:
1. Описательная аналитика (descriptive analytics) — самая распространенная. Она отвечает на вопрос «Что произошло?», анализирует данные, поступающие в реальном времени, и исторические данные. Главная цель — выяснить причины и закономерности успехов или неудач в той или иной сфере, чтобы использовать эти данные для наиболее эффективных моделей. Для описательной аналитики используют базовые математические функции. Типичный пример — социологические исследования или данные веб-статистики, которые компания получает через Google Analytics.
Антон Мироненков, управляющий директор «X5 Технологии»:
«Есть два больших класса моделей для принятия решений по ценообразованию. Первый отталкивается от рыночных цен на тот или иной товар. Данные о ценниках в других магазинах собираются, анализируются и на их основе по определенным правилам устанавливаются собственные цены.
Данные о ценниках в других магазинах собираются, анализируются и на их основе по определенным правилам устанавливаются собственные цены.
Второй класс моделей связан с выстраиванием кривой спроса, которая отражает объемы продаж в зависимости от цены. Это более аналитическая история. В онлайне такой механизм применяется очень широко, и мы переносим эту технологию из онлайна в офлайн».
2. Прогнозная или предикативная аналитика (predictive analytics) — помогает спрогнозировать наиболее вероятное развитие событий на основе имеющихся данных. Для этого используют готовые шаблоны на основе каких-либо объектов или явлений с аналогичным набором характеристик. С помощью предикативной (или предиктивной, прогнозной) аналитики можно, например, просчитать обвал или изменение цен на фондовом рынке. Или оценить возможности потенциального заемщика по выплате кредита.
3. Предписательная аналитика (prescriptive analytics) — следующий уровень по сравнению с прогнозной.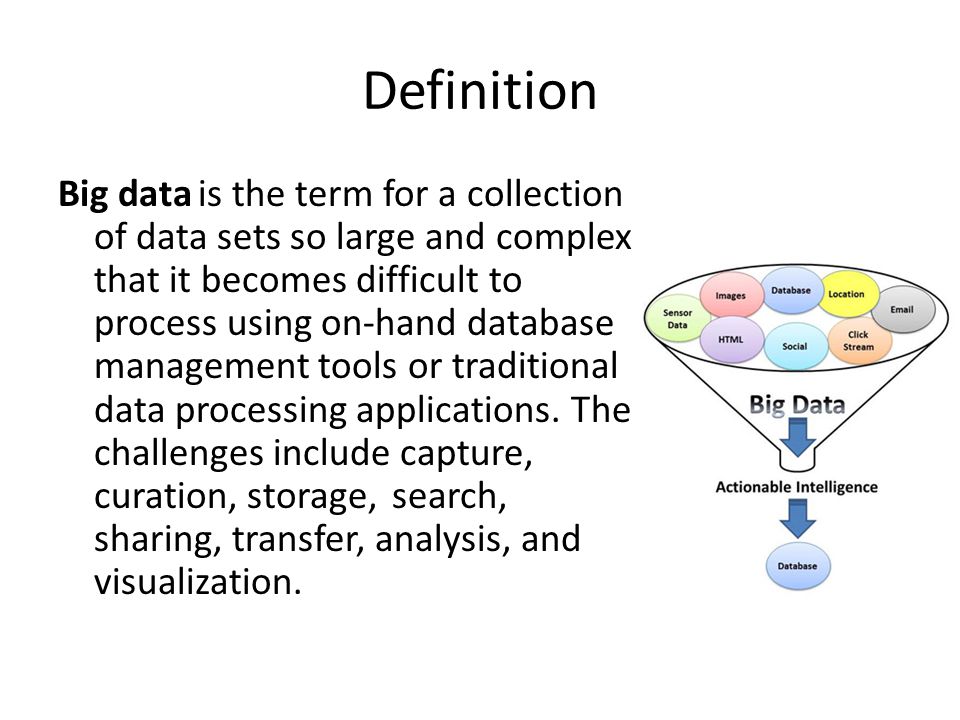 С помощью Big Data и современных технологий можно выявить проблемные точки в бизнесе или любой другой деятельности и рассчитать, при каком сценарии их можно избежать их в будущем.
С помощью Big Data и современных технологий можно выявить проблемные точки в бизнесе или любой другой деятельности и рассчитать, при каком сценарии их можно избежать их в будущем.
Сеть медицинских центров Aurora Health Care ежегодно экономит $6 млн за счет предписывающей аналитики: ей удалось снизить число повторных госпитализаций на 10% [5].
4. Диагностическая аналитика (diagnostic analytics) — использует данные, чтобы проанализировать причины произошедшего. Это помогает выявлять аномалии и случайные связи между событиями и действиями.
Например, Amazon анализирует данные о продажах и валовой прибыли для различных продуктов, чтобы выяснить, почему они принесли меньше дохода, чем ожидалось.
Данные обрабатывают и анализируют с помощью различных инструментов и технологий [6] [7]:
- Cпециальное ПО: NoSQL, MapReduce, Hadoop, R;
- Data mining — извлечение из массивов ранее неизвестных данных с помощью большого набора техник;
- ИИ и нейросети — для построения моделей на основе Big Data, включая распознавание текста и изображений. Например, оператор лотерей «Столото» сделал большие данные основой своей стратегии в рамках Data-driven Organization. С помощью Big Data и искусственного интеллекта компания анализирует клиентский опыт и предлагает персонифицированные продукты и сервисы;
- Визуализация аналитических данных — анимированные модели или графики, созданные на основе больших данных.
 Например, оператор лотерей «Столото» сделал большие данные основой своей стратегии в рамках Data-driven Organization. С помощью Big Data и искусственного интеллекта компания анализирует клиентский опыт и предлагает персонифицированные продукты и сервисы;
Например, оператор лотерей «Столото» сделал большие данные основой своей стратегии в рамках Data-driven Organization. С помощью Big Data и искусственного интеллекта компания анализирует клиентский опыт и предлагает персонифицированные продукты и сервисы;
Примеры визуализации данных (data-driven animation)
Как отметил в подкасте РБК Трендов менеджер по развитию IoT «Яндекс.Облака» Александр Сурков, разработчики придерживаются двух критериев сбора информации:
- Обезличивание данных делает персональную информацию пользователей в какой-то степени недоступной;
- Агрегированность данных позволяет оперировать лишь со средними показателями.
Чтобы обрабатывать большие массивы данных в режиме онлайн используют суперкомпьютеры: их мощность и вычислительные возможности многократно превосходят обычные. Подробнее — в материале «Как устроены суперкомпьютеры и что они умеют».
Подробнее — в материале «Как устроены суперкомпьютеры и что они умеют».
Big Data и Data Science — в чем разница?
Data Science или наука о данных — это сфера деятельности, которая подразумевает сбор, обработку и анализ данных, — структурированных и неструктурированных, не только больших. В ней используют методы математического и статистического анализа, а также программные решения. Data Science работает, в том числе, и с Big Data, но ее главная цель — найти в данных что-то ценное, чтобы использовать это для конкретных задач.
5
В каких отраслях уже используют Big Data?
Павел Иванченко, руководитель по IoT «МегаФона»:
«IoT-решение из области так называемого точного земледелия — это когда специальные метеостанции, которые стоят в полях, с помощью сенсоров собирают данные (температура, влажность) и с помощью передающих радио-GSM-модулей отправляют их на IoT-платформу. На ней посредством алгоритмов big data происходит обработка собранной с сенсоров информации и строится высокоточный почасовой прогноз погоды. Клиент видит его в интерфейсе на компьютере, планшете или смартфоне и может оперативно принимать решения».
Клиент видит его в интерфейсе на компьютере, планшете или смартфоне и может оперативно принимать решения».
Подробнее — в материале «Умные» комбайны и дроны-геологи: как цифровизация меняет экономику».
6
Big Data в России и мире
По данным компании IBS [8], в 2012 году объем хранящихся в мире цифровых данных вырос на 50%: с 1,8 до 2,7 Збайт (2,7 трлн Гбайт). В 2015-м в мире каждые десять минут генерировалось столько же данных, сколько за весь 2003 год.
По данным компании NetApp, к 2003 году в мире накопилось 5 Эбайтов данных (1 Эбайт = 1 млрд Гбайт). В 2015-м — более 6,5 Збайта, причем тогда большие данные использовали лишь 17% компаний по всему миру [9]. Большую часть данных будут генерировать сами компании, а не их клиенты. При этом обычный пользователь будет коммуницировать с различными устройствами, которые генерируют данные, около 4 800 раз в день.
Первыми Big Data еще пять лет назад начали использовать в ИТ, телекоме и банках. Именно в этих сферах скапливается большой объем данных о транзакциях, геолокации, поисковых запросах и профилях в Сети.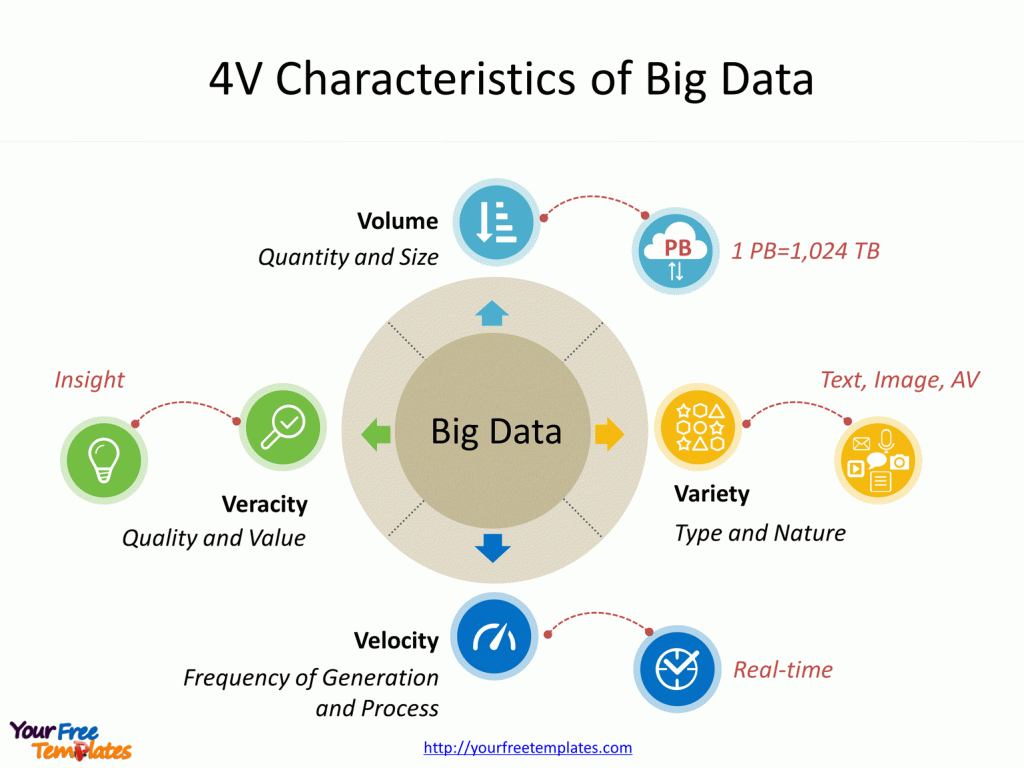 В 2019 году прибыль от использования больших данных оценивались в $189 млрд [10] — на 12% больше, чем в 2018-м, при этом к 2022 году она ежегодно будет удваиваться.
В 2019 году прибыль от использования больших данных оценивались в $189 млрд [10] — на 12% больше, чем в 2018-м, при этом к 2022 году она ежегодно будет удваиваться.
Сейчас в США с большими данными работает более 55% компаний [11], в Европе и Азии — около 53%. Только за последние пять лет распространение Big Data в бизнесе выросло в три раза.
Как большие данные помогают онлайн-кинотеатрам подбирать персональные рекомендации
Мировыми лидерами по сбору и анализу больших данных являются США и Китай. Так, в США еще при Бараке Обаме правительство запустило шесть федеральных программ по развитию больших данных на общую сумму $200 млн. Главными потребителями Big Data считаются крупные корпорации, однако их деятельность по сбору данных ограничена в некоторых штатах — например, в Калифорнии.
В Китае действует более 200 законов и правил, касающихся защиты личной информации. С 2019 года все популярные приложения для смартфонов начали проверять и блокировать, если они собирают данные о пользователях вопреки законам. В итоге данные через местные сервисы собирает государство, и многие из них недоступны извне.
В итоге данные через местные сервисы собирает государство, и многие из них недоступны извне.
С 2018 года в Евросоюзе действует GDPR — Всеобщий регламент по защите данных. Он регулирует все, что касается сбора, хранения и использования данных онлайн-пользователей. Когда закон вступил в силу год назад, он считался самой жесткой в мире системой защиты конфиденциальности людей в Интернете.
Подробнее — в материале «Цифровые войны: как искусственный интеллект и большие данные правят миром».
В России рынок больших данных только зарождается. К примеру, сотовые операторы делятся с банками информацией о потенциальных заемщиках [12]. Среди корпораций, которые собирают и анализируют данные — «Яндекс», «Сбер», Mail.ru. Появились специальные инструменты, которые помогают бизнесу собирать и анализировать Big Data — такие, как российский сервис Ctrl2GO.
7
Big Data в бизнесе
Большие данные полезны для бизнеса в трех главных направлениях:
- Запуск продуктов и сервисов, которые точнее всего «выстрелят» по потребностям целевой аудитории;
- Анализ клиентского опыта в отношении продукта или услуги, чтобы улучшить их;
- Привлечение и удержание клиентов с помощью аналитики.

Большие данные помогают MasterCard предотвращать мошеннические операции со счетами клиентов на сумму более $3 млрд в год [13]. Они позволяют рекламодателям эффективнее распределять бюджеты и размещать рекламу, которая нацелена на самых разных потребителей.
Крупные компании — такие, как Netflix, Procter & Gamble или Coca-Cola — с помощью больших данных прогнозируют потребительский спрос. 70% решений в бизнесе и госуправлении принимается на основе геоданных. Подробнее — в материале о том, как бизнес извлекает прибыль из Big Data.
8
Каковы проблемы и перспективы Big Data?
Главные проблемы:
- Большие данные неоднородны, поэтому их сложно обрабатывать для статистических выводов. Чем больше требуется параметров для прогнозирования, тем больше ошибок накапливается при анализе;
- Для работы с большими массивами данных онлайн нужны огромные вычислительные мощности. Такие ресурсы обходятся очень дорого, и пока что доступны только большим корпорациям;
- Хранение и обработка Big Data связаны с повышенной уязвимостью для кибератак и всевозможных утечек. Яркий пример — скандалы с профилями Facebook;
- Сбор больших данных часто связан с проблемой приватности: не все хотят, чтобы каждое их действие отслеживали и передавали третьим лицам. Герои подкаста «Что изменилось» объясняют, почему конфиденциальности в Сети больше нет, и технологическим гигантам известно о нас все;
- Большие данные используют в своих целях не только корпорации, но и политики: например, чтобы повлиять на выборы.
 Яркий пример — скандалы с профилями Facebook;
Яркий пример — скандалы с профилями Facebook;
Плюсы и перспективы:
- Большие данные помогают решать глобальные проблемы — например, бороться с пандемией, находить лекарства от рака и предотвращать экологический кризис;
- Big Data — хороший инструмент для создания умных городов и решения проблемы транспорта;
- Большие данные помогают экономить средства даже на государственном уровне: например, в Германии вернули в бюджет около €15 млрд [14], обнаружив, что часть граждан получают пособие по безработице без всяких оснований. Их вычислили с помощью транзакций.
 Их вычислили с помощью транзакций.
Их вычислили с помощью транзакций.
Как Big Data и ИИ меняют наше представление о справедливости
В ближайшем будущем большие данные станут главным инструментом для принятия решений — начиная с сетевых бизнесов и заканчивая целыми государствами и международными организациями [15].
Обновлено 02.03.2021
Текст
Людмила Клейменова,
Ася Зуйкова
что это такое, характеристики, технология сбора, обработки и анализа больших данных
Big Data: что это такое, характеристики, технология сбора, обработки и анализа больших данных
Динамический коллтрекинг
Стоимость
8 800 555 55 22
- Вернуться в Глоссарий
Пред. статья
статья
AIDA
След. статья
BTL
Оглавление
Другие популярные термины
И
Искусственный интеллект
Что такое искусственный интеллект — расскажем в статье простыми словами. Каким бывает искусственный интеллект. Принципы работы и технологии искусственного интеллекта. Как применить ИИ в бизнесе
Пред. статья
AIDA
След. статья
BTL
Выберите букву алфавита
Весь алфавит
Весь алфавит
А
Б
В
Г
Д
Е
З
И
К
Л
М
Н
О
П
Р
С
У
Ф
Э
Ю
Я
A
B
C
E
G
L
M
P
Q
R
S
U
W
Виртуальная АТС
- Голосовое меню (IVR)
- Запись разговоров
- Интеграция с LDAP
- Конференцсвязь
- Многоканальные номера
- Поддержка
- Подключение
- Статистика и мониторинг
Коллтрекинг
- О продукте
- Как подключить
- Решения
- Возможности
- Стоимость
- Сквозная аналитика
- Мультиканальная аналитика
Контакт-центр
- Исходящий обзвон
- Оценка эффективности работы
- Поддержка
- Подключение
- Управление клиентским сервисом
Решения
- IP-Телефония
- Телефонизация офиса
- Бесплатный вызов 8-800
- Для стартапов
- Диспетчеризация ЖКХ ТСЖ и УК
 org/SiteNavigationElement»>
org/SiteNavigationElement»>Бизнес-кейсы
Партнерам
Поддержка
О компании
Почему MANGO OFFICE
Наша команда
Наши достижения
Карьера
Пресс-центр
Блог «Бизнес-рецепты»
Мероприятия
Наши клиенты
Отзывы
Что такое большие данные? | Оракул
Определены большие данные
Что именно относится к большим данным?
Большие данные — это данные, содержащие большее разнообразие, поступающие в возрастающих объемах и с большей скоростью. Это также известно как три Vs.
Это также известно как три Vs.
Проще говоря, большие данные — это более крупные и сложные наборы данных, особенно из новых источников данных. Эти наборы данных настолько объемны, что традиционное программное обеспечение для обработки данных просто не может ими управлять. Но эти огромные объемы данных можно использовать для решения бизнес-задач, с которыми раньше вы не могли справиться.
Загрузить электронную книгу «Эволюция больших данных и данных Lakehouse»
Три V больших данных
| Объем | Количество данных имеет значение. С большими данными вам придется обрабатывать большие объемы неструктурированных данных низкой плотности. Это могут быть данные неизвестного значения, такие как потоки данных Twitter, потоки кликов на веб-странице или в мобильном приложении или оборудование с датчиками. Для некоторых организаций это могут быть десятки терабайт данных. Для других это могут быть сотни петабайт. |
| Скорость | Скорость — это высокая скорость, с которой данные принимаются и (возможно) обрабатываются. Обычно самая высокая скорость потоков данных напрямую поступает в память, а не записывается на диск. Некоторые интеллектуальные продукты с доступом в Интернет работают в режиме реального времени или почти в реальном времени и требуют оценки и действий в режиме реального времени. Обычно самая высокая скорость потоков данных напрямую поступает в память, а не записывается на диск. Некоторые интеллектуальные продукты с доступом в Интернет работают в режиме реального времени или почти в реальном времени и требуют оценки и действий в режиме реального времени. |
| Разнообразие | Разнообразие относится ко многим доступным типам данных. Традиционные типы данных были структурированы и идеально подходили для реляционной базы данных. С появлением больших данных данные поступают в новые неструктурированные типы данных. Неструктурированные и частично структурированные типы данных, такие как текст, аудио и видео, требуют дополнительной предварительной обработки для получения значения и поддержки метаданных. |
Ценность и достоверность больших данных
За последние несколько лет появились еще два V: ценность и достоверность . Данные имеют внутреннюю ценность. Но это бесполезно, пока это значение не будет обнаружено. Не менее важно: насколько правдивы ваши данные и насколько вы можете на них полагаться?
Не менее важно: насколько правдивы ваши данные и насколько вы можете на них полагаться?
Сегодня большие данные стали капиталом. Подумайте о некоторых крупнейших технологических компаниях мира. Большая часть ценности, которую они предлагают, исходит от их данных, которые они постоянно анализируют для повышения эффективности и разработки новых продуктов.
Недавние технологические прорывы позволили в геометрической прогрессии снизить стоимость хранения данных и вычислений, упрощая и удешевляя хранение большего объема данных, чем когда-либо прежде. Благодаря увеличению объема больших данных, которые стали дешевле и доступнее, вы можете принимать более точные и точные бизнес-решения.
Ценность больших данных заключается не только в их анализе (что является еще одним преимуществом). Это целый процесс исследования, который требует проницательных аналитиков, бизнес-пользователей и руководителей, которые задают правильные вопросы, распознают закономерности, делают обоснованные предположения и предсказывают поведение.
Но как мы сюда попали?
История больших данных
Хотя сама концепция больших данных является относительно новой, истоки больших наборов данных восходят к 1960-м и 70-м годам, когда мир данных только начинался с первых центров обработки данных и разработки реляционной базы данных.
Примерно в 2005 году люди начали понимать, сколько данных пользователи генерируют через Facebook, YouTube и другие онлайн-сервисы. В том же году была разработана Hadoop (платформа с открытым исходным кодом, созданная специально для хранения и анализа больших наборов данных). NoSQL также начал набирать популярность в это время.
Разработка сред с открытым исходным кодом, таких как Hadoop (а в последнее время и Spark), была необходима для роста больших данных, поскольку они упрощают работу с большими данными и удешевляют их хранение. С тех пор объем больших данных резко вырос. Пользователи по-прежнему генерируют огромные объемы данных, но это делают не только люди.
С появлением Интернета вещей (IoT) все больше объектов и устройств подключаются к Интернету, собирая данные о моделях использования клиентов и производительности продукта. Появление машинного обучения произвело еще больше данных.
Появление машинного обучения произвело еще больше данных.
Хотя большие данные зашли далеко, их полезность только начинается. Облачные вычисления еще больше расширили возможности больших данных. Облако предлагает по-настоящему эластичную масштабируемость, когда разработчики могут просто запускать специальные кластеры для тестирования подмножества данных. Базы данных графов также становятся все более важными благодаря их способности отображать огромные объемы данных таким образом, чтобы сделать аналитику быстрой и всеобъемлющей.
Загрузить электронную книгу с примерами использования графов
Преимущества больших данных:
- Большие данные позволяют получить более полные ответы, поскольку у вас больше информации.
- Более полные ответы означают большую уверенность в данных, а это означает совершенно другой подход к решению проблем.
Сценарии использования больших данных
Большие данные могут помочь вам решить ряд бизнес-задач, от взаимодействия с клиентами до аналитики. Здесь только несколько.
Здесь только несколько.
| Разработка продукта | Такие компании, как Netflix и Procter & Gamble, используют большие данные для прогнозирования потребительского спроса. Они строят прогностические модели для новых продуктов и услуг, классифицируя ключевые атрибуты прошлых и текущих продуктов или услуг и моделируя взаимосвязь между этими атрибутами и коммерческим успехом предложений. Кроме того, P&G использует данные и аналитику из фокус-групп, социальных сетей, тестовых рынков и ранних продаж в магазинах для планирования, производства и запуска новых продуктов. |
| Профилактическое обслуживание | Факторы, которые могут предсказать механические неисправности, могут быть глубоко скрыты в структурированных данных, таких как год, марка и модель оборудования, а также в неструктурированных данных, которые охватывают миллионы записей журнала, данные датчиков, сообщения об ошибках и температуру двигателя. Анализируя эти признаки потенциальных проблем до того, как они возникнут, организации могут более эффективно развертывать техническое обслуживание и максимизировать время безотказной работы деталей и оборудования. |
| Отдел обслуживания клиентов | Гонка за покупателями началась. Более четкое представление о клиентском опыте сейчас возможно как никогда раньше. Большие данные позволяют собирать данные из социальных сетей, посещений веб-сайтов, журналов вызовов и других источников, чтобы улучшить взаимодействие и получить максимальную отдачу. Начните предоставлять персонализированные предложения, сократите отток клиентов и заранее решайте проблемы. |
| Мошенничество и соблюдение требований | Когда дело доходит до безопасности, это не просто несколько хакеров-мошенников — вам противостоят целые команды экспертов. Ландшафты безопасности и требования соответствия постоянно развиваются. Большие данные помогают выявлять закономерности в данных, которые указывают на мошенничество, и объединять большие объемы информации, чтобы намного быстрее составлять отчетность для регулирующих органов. |
| Машинное обучение | Машинное обучение сейчас является горячей темой. И данные — особенно большие данные — являются одной из причин этого. Теперь мы можем обучать машины, а не программировать их. Доступность больших данных для обучения моделей машинного обучения делает это возможным. И данные — особенно большие данные — являются одной из причин этого. Теперь мы можем обучать машины, а не программировать их. Доступность больших данных для обучения моделей машинного обучения делает это возможным. |
| Операционная эффективность | Операционная эффективность не всегда может быть в новостях, но это область, в которой большие данные оказывают наибольшее влияние. С помощью больших данных вы можете анализировать и оценивать производство, отзывы и возвраты клиентов, а также другие факторы, чтобы сократить простои и предвидеть будущие потребности. Большие данные также можно использовать для улучшения процесса принятия решений в соответствии с текущим рыночным спросом. |
| Привод инноваций | Большие данные могут помочь вам внедрять инновации, изучая взаимозависимости между людьми, учреждениями, организациями и процессами, а затем определяя новые способы использования этих идей. Используйте аналитику данных для улучшения решений, касающихся финансов и планирования. Изучите тенденции и то, что клиенты хотят предоставлять новым продуктам и услугам. Внедрить динамическое ценообразование. Есть бесконечные возможности. Изучите тенденции и то, что клиенты хотят предоставлять новым продуктам и услугам. Внедрить динамическое ценообразование. Есть бесконечные возможности. |
Проблемы с большими данными
Несмотря на то, что большие данные сулят многообещающие результаты, не обошлось и без проблем.
Во-первых, большие данные… большие. Хотя для хранения данных были разработаны новые технологии, объемы данных удваиваются примерно каждые два года. Организации по-прежнему изо всех сил стараются не отставать от своих данных и находить способы их эффективного хранения.
Но недостаточно просто хранить данные. Данные должны использоваться, чтобы быть ценными, и это зависит от курирования. Чистые данные или данные, которые имеют отношение к клиенту и организованы таким образом, чтобы обеспечить содержательный анализ, требуют большой работы. Специалисты по данным тратят от 50 до 80 процентов своего времени на сбор и подготовку данных, прежде чем их можно будет использовать.
Наконец, технологии больших данных меняются быстрыми темпами. Несколько лет назад Apache Hadoop был популярной технологией, используемой для обработки больших данных. Затем в 2014 году был представлен Apache Spark. Сегодня комбинация двух фреймворков кажется лучшим подходом. Идти в ногу с технологиями больших данных — постоянная задача.
Узнайте больше о больших данных:
Узнайте больше о больших данных в Oracle
Как работают большие данные
Большие данные дают вам новые идеи, которые открывают новые возможности и бизнес-модели. Начало работы включает три ключевых действия:
1. Интеграция
Большие данные объединяют данные из множества разрозненных источников и приложений. Традиционные механизмы интеграции данных, такие как извлечение, преобразование и загрузка (ETL), обычно не справляются с этой задачей. Требуются новые стратегии и технологии для анализа больших наборов данных в терабайтном или даже петабайтном масштабе.
Во время интеграции вам необходимо ввести данные, обработать их и убедиться, что они отформатированы и доступны в форме, с которой ваши бизнес-аналитики могут начать работу.
2. Управление
Большие данные требуют хранения. Ваше решение для хранения может быть в облаке, локально или в том и другом месте. Вы можете хранить свои данные в любой форме и приводить к этим наборам данных желаемые требования к обработке и необходимые механизмы обработки по запросу. Многие люди выбирают решение для хранения в зависимости от того, где в настоящее время находятся их данные. Облако постепенно набирает популярность, потому что оно поддерживает ваши текущие требования к вычислительным ресурсам и позволяет увеличивать ресурсы по мере необходимости.
3. Анализ
Ваши инвестиции в большие данные окупаются, когда вы анализируете свои данные и действуете на них. Получите новую ясность благодаря визуальному анализу ваших разнообразных наборов данных. Изучайте данные дальше, чтобы делать новые открытия. Поделитесь своими выводами с другими. Создавайте модели данных с помощью машинного обучения и искусственного интеллекта. Заставьте свои данные работать.
Изучайте данные дальше, чтобы делать новые открытия. Поделитесь своими выводами с другими. Создавайте модели данных с помощью машинного обучения и искусственного интеллекта. Заставьте свои данные работать.
Лучшие практики работы с большими данными
Чтобы помочь вам в вашем путешествии с большими данными, мы собрали несколько ключевых рекомендаций, о которых вам следует помнить. Вот наши рекомендации по созданию успешной основы для работы с большими данными.
| Согласование больших данных с конкретными бизнес-целями | Более обширные наборы данных позволяют делать новые открытия. С этой целью важно обосновывать новые инвестиции в навыки, организацию или инфраструктуру с сильным бизнес-ориентированным контекстом, чтобы гарантировать текущие инвестиции и финансирование проекта. Чтобы определить, находитесь ли вы на правильном пути, спросите, как большие данные поддерживают и реализуют ваши основные бизнес-и ИТ-приоритеты. Примеры включают в себя понимание того, как фильтровать веб-журналы, чтобы понять поведение электронной торговли, определение мнений из социальных сетей и взаимодействия со службой поддержки, а также понимание методов статистической корреляции и их релевантности для клиентов, продуктов, производственных и технических данных. |
| Облегчить нехватку навыков с помощью стандартов и управления | Одним из самых больших препятствий на пути получения выгоды от ваших инвестиций в большие данные является нехватка навыков. Вы можете снизить этот риск, обеспечив включение технологий, соображений и решений, связанных с большими данными, в свою программу управления ИТ. Стандартизация вашего подхода позволит вам управлять затратами и эффективно использовать ресурсы. Организации, внедряющие решения и стратегии для работы с большими данными, должны заранее и часто оценивать свои требования к навыкам и должны заранее выявлять любые потенциальные пробелы в навыках. Их можно решить путем обучения/обучения существующих ресурсов, найма новых ресурсов и привлечения консультационных фирм. |
| Оптимизация передачи знаний с помощью центра передового опыта | Используйте подход центра передового опыта для обмена знаниями, контроля и управления проектными коммуникациями. Вне зависимости от того, являются ли большие данные новой или расширяющейся инвестицией, «мягкие» и «жесткие» затраты могут быть распределены по всему предприятию. Использование этого подхода может помочь расширить возможности больших данных и общую зрелость информационной архитектуры более структурированным и систематическим образом. Использование этого подхода может помочь расширить возможности больших данных и общую зрелость информационной архитектуры более структурированным и систематическим образом. |
| Максимальная отдача заключается в согласовании неструктурированных данных со структурированными | Самостоятельный анализ больших данных, безусловно, полезен. Но вы можете получить еще больше информации для бизнеса, соединив и интегрировав большие данные низкой плотности со структурированными данными, которые вы уже используете сегодня. Независимо от того, собираете ли вы большие данные о клиентах, продуктах, оборудовании или окружающей среде, цель состоит в том, чтобы добавить больше релевантных точек данных в основные сводки и аналитические сводки, что позволит сделать более точные выводы. Например, есть разница в различении настроений всех клиентов и только ваших лучших клиентов. Вот почему многие рассматривают большие данные как неотъемлемое расширение существующих возможностей бизнес-аналитики, платформы хранения данных и информационной архитектуры. Имейте в виду, что аналитические процессы и модели больших данных могут выполняться как людьми, так и машинами. Возможности анализа больших данных включают статистику, пространственный анализ, семантику, интерактивное обнаружение и визуализацию. Используя аналитические модели, вы можете сопоставлять различные типы и источники данных, чтобы проводить ассоциации и делать важные открытия. |
| Спланируйте свою исследовательскую лабораторию для повышения производительности | Обнаружить значение ваших данных не всегда просто. Иногда мы даже не знаем, что ищем. Это ожидаемо. Менеджмент и ИТ должны поддерживать это «отсутствие направления» или «отсутствие четких требований». В то же время аналитикам и специалистам по данным важно тесно сотрудничать с бизнесом, чтобы понять основные пробелы в бизнес-знаниях и требованиях. Для интерактивного изучения данных и экспериментов со статистическими алгоритмами вам нужны высокопроизводительные рабочие области. |
| Согласование с облачной операционной моделью | Процессам и пользователям больших данных требуется доступ к широкому набору ресурсов как для повторяющихся экспериментов, так и для выполнения производственных заданий. Решение для работы с большими данными включает в себя все области данных, включая транзакции, основные данные, справочные данные и сводные данные. Аналитические песочницы должны создаваться по требованию. Управление ресурсами имеет решающее значение для обеспечения контроля над всем потоком данных, включая предварительную и последующую обработку, интеграцию, обобщение в базе данных и аналитическое моделирование. Хорошо спланированная стратегия подготовки и безопасности частного и общедоступного облака играет неотъемлемую роль в поддержке этих меняющихся требований. |

 Убедитесь, что среды песочницы имеют необходимую поддержку и должным образом управляются.
Убедитесь, что среды песочницы имеют необходимую поддержку и должным образом управляются.Что такое большие данные? | Оракул Индия
Определены большие данные
Что именно относится к большим данным?
Большие данные — это данные, содержащие большее разнообразие, поступающие в возрастающих объемах и с большей скоростью. Это также известно как три Vs.
Это также известно как три Vs.
Проще говоря, большие данные — это более крупные и сложные наборы данных, особенно из новых источников данных. Эти наборы данных настолько объемны, что традиционное программное обеспечение для обработки данных просто не может ими управлять. Но эти огромные объемы данных можно использовать для решения бизнес-задач, с которыми раньше вы не могли справиться.
Загрузить электронную книгу «Эволюция больших данных и данных Lakehouse»
Три V больших данных
| Объем | Количество данных имеет значение. С большими данными вам придется обрабатывать большие объемы неструктурированных данных низкой плотности. Это могут быть данные неизвестного значения, такие как потоки данных Twitter, потоки кликов на веб-странице или в мобильном приложении или оборудование с датчиками. Для некоторых организаций это могут быть десятки терабайт данных. Для других это могут быть сотни петабайт. |
| Скорость | Скорость — это высокая скорость, с которой данные принимаются и (возможно) обрабатываются. Обычно самая высокая скорость потоков данных напрямую поступает в память, а не записывается на диск. Некоторые интеллектуальные продукты с доступом в Интернет работают в режиме реального времени или почти в реальном времени и требуют оценки и действий в режиме реального времени. Обычно самая высокая скорость потоков данных напрямую поступает в память, а не записывается на диск. Некоторые интеллектуальные продукты с доступом в Интернет работают в режиме реального времени или почти в реальном времени и требуют оценки и действий в режиме реального времени. |
| Разнообразие | Разнообразие относится ко многим доступным типам данных. Традиционные типы данных были структурированы и идеально подходили для реляционной базы данных. С появлением больших данных данные поступают в новые неструктурированные типы данных. Неструктурированные и частично структурированные типы данных, такие как текст, аудио и видео, требуют дополнительной предварительной обработки для получения значения и поддержки метаданных. |
Ценность и достоверность больших данных
За последние несколько лет появились еще два V: ценность и достоверность . Данные имеют внутреннюю ценность. Но это бесполезно, пока это значение не будет обнаружено. Не менее важно: насколько правдивы ваши данные и насколько вы можете на них полагаться?
Не менее важно: насколько правдивы ваши данные и насколько вы можете на них полагаться?
Сегодня большие данные стали капиталом. Подумайте о некоторых крупнейших технологических компаниях мира. Большая часть ценности, которую они предлагают, исходит от их данных, которые они постоянно анализируют для повышения эффективности и разработки новых продуктов.
Недавние технологические прорывы позволили в геометрической прогрессии снизить стоимость хранения данных и вычислений, упрощая и удешевляя хранение большего объема данных, чем когда-либо прежде. Благодаря увеличению объема больших данных, которые стали дешевле и доступнее, вы можете принимать более точные и точные бизнес-решения.
Ценность больших данных заключается не только в их анализе (что является еще одним преимуществом). Это целый процесс исследования, который требует проницательных аналитиков, бизнес-пользователей и руководителей, которые задают правильные вопросы, распознают закономерности, делают обоснованные предположения и предсказывают поведение.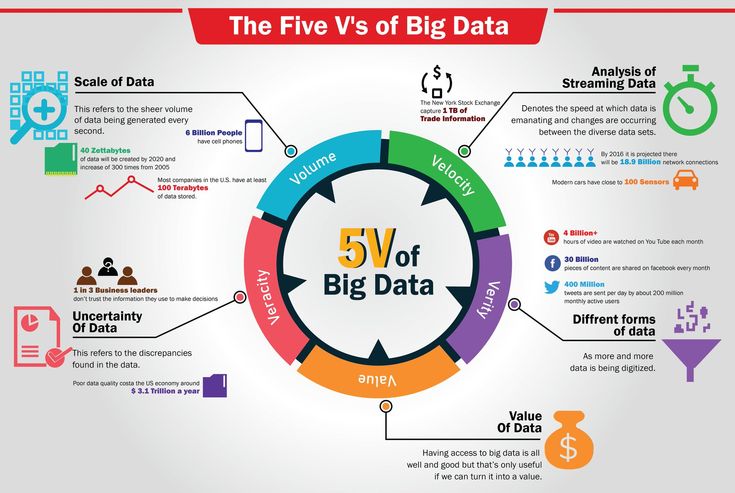
Но как мы сюда попали?
История больших данных
Хотя сама концепция больших данных является относительно новой, истоки больших наборов данных восходят к 1960-м и 70-м годам, когда мир данных только начинался с первых центров обработки данных и разработки реляционной базы данных.
Примерно в 2005 году люди начали понимать, сколько данных пользователи генерируют через Facebook, YouTube и другие онлайн-сервисы. В том же году была разработана Hadoop (платформа с открытым исходным кодом, созданная специально для хранения и анализа больших наборов данных). NoSQL также начал набирать популярность в это время.
Разработка сред с открытым исходным кодом, таких как Hadoop (а в последнее время и Spark), была необходима для роста больших данных, поскольку они упрощают работу с большими данными и удешевляют их хранение. С тех пор объем больших данных резко вырос. Пользователи по-прежнему генерируют огромные объемы данных, но это делают не только люди.
С появлением Интернета вещей (IoT) все больше объектов и устройств подключаются к Интернету, собирая данные о моделях использования клиентов и производительности продукта. Появление машинного обучения произвело еще больше данных.
Появление машинного обучения произвело еще больше данных.
Хотя большие данные зашли далеко, их полезность только начинается. Облачные вычисления еще больше расширили возможности больших данных. Облако предлагает по-настоящему эластичную масштабируемость, когда разработчики могут просто запускать специальные кластеры для тестирования подмножества данных. Базы данных графов также становятся все более важными благодаря их способности отображать огромные объемы данных таким образом, чтобы сделать аналитику быстрой и всеобъемлющей.
Загрузить электронную книгу с примерами использования графов
Преимущества больших данных:
- Большие данные позволяют получить более полные ответы, поскольку у вас больше информации.
- Более полные ответы означают большую уверенность в данных, а это означает совершенно другой подход к решению проблем.
Сценарии использования больших данных
Большие данные могут помочь вам решить ряд бизнес-задач, от взаимодействия с клиентами до аналитики. Здесь только несколько.
Здесь только несколько.
| Разработка продукта | Такие компании, как Netflix и Procter & Gamble, используют большие данные для прогнозирования потребительского спроса. Они строят прогностические модели для новых продуктов и услуг, классифицируя ключевые атрибуты прошлых и текущих продуктов или услуг и моделируя взаимосвязь между этими атрибутами и коммерческим успехом предложений. Кроме того, P&G использует данные и аналитику из фокус-групп, социальных сетей, тестовых рынков и ранних продаж в магазинах для планирования, производства и запуска новых продуктов. |
| Профилактическое обслуживание | Факторы, которые могут предсказать механические неисправности, могут быть глубоко скрыты в структурированных данных, таких как год, марка и модель оборудования, а также в неструктурированных данных, которые охватывают миллионы записей журнала, данные датчиков, сообщения об ошибках и температуру двигателя. Анализируя эти признаки потенциальных проблем до того, как они возникнут, организации могут более эффективно развертывать техническое обслуживание и максимизировать время безотказной работы деталей и оборудования. |
| Отдел обслуживания клиентов | Гонка за покупателями началась. Более четкое представление о клиентском опыте сейчас возможно как никогда раньше. Большие данные позволяют собирать данные из социальных сетей, посещений веб-сайтов, журналов вызовов и других источников, чтобы улучшить взаимодействие и получить максимальную отдачу. Начните предоставлять персонализированные предложения, сократите отток клиентов и заранее решайте проблемы. |
| Мошенничество и соблюдение требований | Когда дело доходит до безопасности, это не просто несколько хакеров-мошенников — вам противостоят целые команды экспертов. Ландшафты безопасности и требования соответствия постоянно развиваются. Большие данные помогают выявлять закономерности в данных, которые указывают на мошенничество, и объединять большие объемы информации, чтобы намного быстрее составлять отчетность для регулирующих органов. |
| Машинное обучение | Машинное обучение сейчас является горячей темой. И данные — особенно большие данные — являются одной из причин этого. Теперь мы можем обучать машины, а не программировать их. Доступность больших данных для обучения моделей машинного обучения делает это возможным. И данные — особенно большие данные — являются одной из причин этого. Теперь мы можем обучать машины, а не программировать их. Доступность больших данных для обучения моделей машинного обучения делает это возможным. |
| Операционная эффективность | Операционная эффективность не всегда может быть в новостях, но это область, в которой большие данные оказывают наибольшее влияние. С помощью больших данных вы можете анализировать и оценивать производство, отзывы и возвраты клиентов, а также другие факторы, чтобы сократить простои и предвидеть будущие потребности. Большие данные также можно использовать для улучшения процесса принятия решений в соответствии с текущим рыночным спросом. |
| Привод инноваций | Большие данные могут помочь вам внедрять инновации, изучая взаимозависимости между людьми, учреждениями, организациями и процессами, а затем определяя новые способы использования этих идей. Используйте аналитику данных для улучшения решений, касающихся финансов и планирования. Изучите тенденции и то, что клиенты хотят предоставлять новым продуктам и услугам. Внедрить динамическое ценообразование. Есть бесконечные возможности. Изучите тенденции и то, что клиенты хотят предоставлять новым продуктам и услугам. Внедрить динамическое ценообразование. Есть бесконечные возможности. |
Проблемы с большими данными
Несмотря на то, что большие данные сулят многообещающие результаты, не обошлось и без проблем.
Во-первых, большие данные… большие. Хотя для хранения данных были разработаны новые технологии, объемы данных удваиваются примерно каждые два года. Организации по-прежнему изо всех сил стараются не отставать от своих данных и находить способы их эффективного хранения.
Но недостаточно просто хранить данные. Данные должны использоваться, чтобы быть ценными, и это зависит от курирования. Чистые данные или данные, которые имеют отношение к клиенту и организованы таким образом, чтобы обеспечить содержательный анализ, требуют большой работы. Специалисты по данным тратят от 50 до 80 процентов своего времени на сбор и подготовку данных, прежде чем их можно будет использовать.
Наконец, технологии больших данных меняются быстрыми темпами. Несколько лет назад Apache Hadoop был популярной технологией, используемой для обработки больших данных. Затем в 2014 году был представлен Apache Spark. Сегодня комбинация двух фреймворков кажется лучшим подходом. Идти в ногу с технологиями больших данных — постоянная задача.
Узнайте больше о больших данных:
Узнайте больше о больших данных в Oracle
Как работают большие данные
Большие данные дают вам новые идеи, которые открывают новые возможности и бизнес-модели. Начало работы включает три ключевых действия:
1. Интеграция
Большие данные объединяют данные из множества разрозненных источников и приложений. Традиционные механизмы интеграции данных, такие как извлечение, преобразование и загрузка (ETL), обычно не справляются с этой задачей. Требуются новые стратегии и технологии для анализа больших наборов данных в терабайтном или даже петабайтном масштабе.
Во время интеграции вам необходимо ввести данные, обработать их и убедиться, что они отформатированы и доступны в форме, с которой ваши бизнес-аналитики могут начать работу.
2. Управление
Большие данные требуют хранения. Ваше решение для хранения может быть в облаке, локально или в том и другом месте. Вы можете хранить свои данные в любой форме и приводить к этим наборам данных желаемые требования к обработке и необходимые механизмы обработки по запросу. Многие люди выбирают решение для хранения в зависимости от того, где в настоящее время находятся их данные. Облако постепенно набирает популярность, потому что оно поддерживает ваши текущие требования к вычислительным ресурсам и позволяет увеличивать ресурсы по мере необходимости.
3. Анализ
Ваши инвестиции в большие данные окупаются, когда вы анализируете свои данные и действуете на них. Получите новую ясность благодаря визуальному анализу ваших разнообразных наборов данных. Изучайте данные дальше, чтобы делать новые открытия. Поделитесь своими выводами с другими. Создавайте модели данных с помощью машинного обучения и искусственного интеллекта. Заставьте свои данные работать.
Изучайте данные дальше, чтобы делать новые открытия. Поделитесь своими выводами с другими. Создавайте модели данных с помощью машинного обучения и искусственного интеллекта. Заставьте свои данные работать.
Лучшие практики работы с большими данными
Чтобы помочь вам в вашем путешествии с большими данными, мы собрали несколько ключевых рекомендаций, о которых вам следует помнить. Вот наши рекомендации по созданию успешной основы для работы с большими данными.
| Согласование больших данных с конкретными бизнес-целями | Более обширные наборы данных позволяют делать новые открытия. С этой целью важно обосновывать новые инвестиции в навыки, организацию или инфраструктуру с сильным бизнес-ориентированным контекстом, чтобы гарантировать текущие инвестиции и финансирование проекта. Чтобы определить, находитесь ли вы на правильном пути, спросите, как большие данные поддерживают и реализуют ваши основные бизнес-и ИТ-приоритеты. Примеры включают в себя понимание того, как фильтровать веб-журналы, чтобы понять поведение электронной торговли, определение мнений из социальных сетей и взаимодействия со службой поддержки, а также понимание методов статистической корреляции и их релевантности для клиентов, продуктов, производственных и технических данных. |
| Облегчить нехватку навыков с помощью стандартов и управления | Одним из самых больших препятствий на пути получения выгоды от ваших инвестиций в большие данные является нехватка навыков. Вы можете снизить этот риск, обеспечив включение технологий, соображений и решений, связанных с большими данными, в свою программу управления ИТ. Стандартизация вашего подхода позволит вам управлять затратами и эффективно использовать ресурсы. Организации, внедряющие решения и стратегии для работы с большими данными, должны заранее и часто оценивать свои требования к навыкам и должны заранее выявлять любые потенциальные пробелы в навыках. Их можно решить путем обучения/обучения существующих ресурсов, найма новых ресурсов и привлечения консультационных фирм. |
| Оптимизация передачи знаний с помощью центра передового опыта | Используйте подход центра передового опыта для обмена знаниями, контроля и управления проектными коммуникациями. Вне зависимости от того, являются ли большие данные новой или расширяющейся инвестицией, «мягкие» и «жесткие» затраты могут быть распределены по всему предприятию. Использование этого подхода может помочь расширить возможности больших данных и общую зрелость информационной архитектуры более структурированным и систематическим образом. Использование этого подхода может помочь расширить возможности больших данных и общую зрелость информационной архитектуры более структурированным и систематическим образом. |
| Максимальная отдача заключается в согласовании неструктурированных данных со структурированными | Самостоятельный анализ больших данных, безусловно, полезен. Но вы можете получить еще больше информации для бизнеса, соединив и интегрировав большие данные низкой плотности со структурированными данными, которые вы уже используете сегодня. Независимо от того, собираете ли вы большие данные о клиентах, продуктах, оборудовании или окружающей среде, цель состоит в том, чтобы добавить больше релевантных точек данных в основные сводки и аналитические сводки, что позволит сделать более точные выводы. Например, есть разница в различении настроений всех клиентов и только ваших лучших клиентов. Вот почему многие рассматривают большие данные как неотъемлемое расширение существующих возможностей бизнес-аналитики, платформы хранения данных и информационной архитектуры. Имейте в виду, что аналитические процессы и модели больших данных могут выполняться как людьми, так и машинами. Возможности анализа больших данных включают статистику, пространственный анализ, семантику, интерактивное обнаружение и визуализацию. Используя аналитические модели, вы можете сопоставлять различные типы и источники данных, чтобы проводить ассоциации и делать важные открытия. |
| Спланируйте свою исследовательскую лабораторию для повышения производительности | Обнаружить значение ваших данных не всегда просто. Иногда мы даже не знаем, что ищем. Это ожидаемо. Менеджмент и ИТ должны поддерживать это «отсутствие направления» или «отсутствие четких требований». В то же время аналитикам и специалистам по данным важно тесно сотрудничать с бизнесом, чтобы понять основные пробелы в бизнес-знаниях и требованиях. Для интерактивного изучения данных и экспериментов со статистическими алгоритмами вам нужны высокопроизводительные рабочие области. |

