Содержание
Вордстат (Wordstat) Яндекс — как работать с парсером, чтобы проводить подбор статистики ключевых слов и как выгрузить популярные запросы в Эксель
Как производится подбор статистики по запросам и парсинг ключевых слов в Яндекс Вордстат (Wordstat)? Как с ним работать? Как собрать семантическое ядро сайта через данный парсер? И что такое операторы: плюс, минус, восклицательный знак, кавычки и скобки? Давайте сегодня разберем все эти вопросы.
Оглавление:
Онлайн Парсер Wordstat — что это и зачем он нужен
Как работать с Вордстатом
Как выгрузить слова из Вордстата в Эксель
Что такое операторы
Кавычки
Восклицательный знак
Квадратные скобки
Плюс
Минус
Круглые скобочки
Ответы на часто задаваемые вопросы
Что такое десктопы
Как производится массовая проверка частотности запросов
Как убрать капчу
Как посмотреть историю запросов
Заключительный результат
Онлайн Парсер Wordstat — что это и зачем он нужен
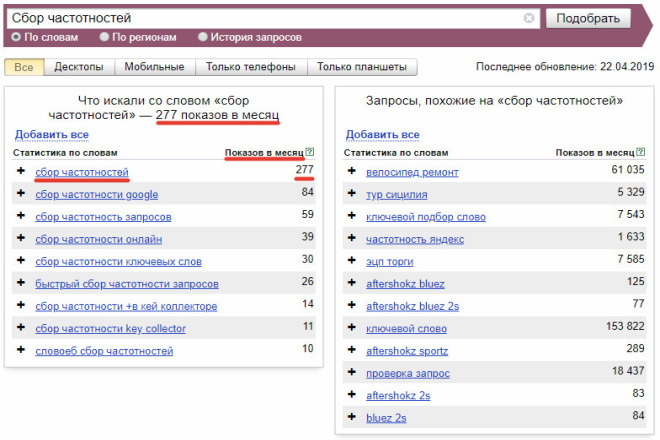
Вордстат — это сервис, рассчитанный для сбора статистики ключевых запросов по заданным городам и техническим устройствам, которые пользователи вбивают в поисковой строке Яндекса. Иными словами, с помощью данного парсера вы получаете сведения о базовой или точной частности, а также количестве слов по необходимой теме.
Иными словами, с помощью данного парсера вы получаете сведения о базовой или точной частности, а также количестве слов по необходимой теме.
На сегодняшний день Wordstat является очень полезным инструментом в услугах по SEO-оптимизации сайта или его конкретной страницы. Помимо этого, с помощью данного сервиса вы сможете провести анализ любой интересующей вас отрасли и более детально понять насколько она популярна среди других пользователей. Разумеется, SEO-специалисты пользуются множеством других сервисов помимо него, но, в большинстве случаев, первичный анализ по предоставленной информации от клиента, начинается именно с этого парсера. Конечно Вордстат — это не совсем парсер, так как, он является внутренним сервисом Яндекса, который предоставляет сведения о количестве запросов пользователей в самой поисковой системе.
Базовая частотность — это общая информация, которую вы получаете, когда пишите запрос в Вордстате без синтаксиса, склонения и точной словоформы. Она демонстрирует общее число всех слов или словосочетаний, в которых присутствуют фразы, входящие в данный запрос в любых словоформах и очереди.
Она демонстрирует общее число всех слов или словосочетаний, в которых присутствуют фразы, входящие в данный запрос в любых словоформах и очереди.
Точная частотность — это число обращений человека с определенным словом или словосочетанием к поисковой системе в период 30 дней.
Помимо этого, используя Вордстат, вы можете без труда определить сезонность и региональность ключевых слов. В принципе, вот такой незамысловатый сервис. Давайте теперь рассмотрим детали того, как пользоваться Wordstat.
Как работать с Вордстатом
Как же осуществляется проверка частотности ключевых слов в Вордстате? Для начала давайте начнем с простого и понятного примера.
Перед тем, как начать работу в данном сервисе вам необходимо в нем зарегистрироваться (то есть иметь аккаунт в Яндексе).
Регистрация в Вордстате
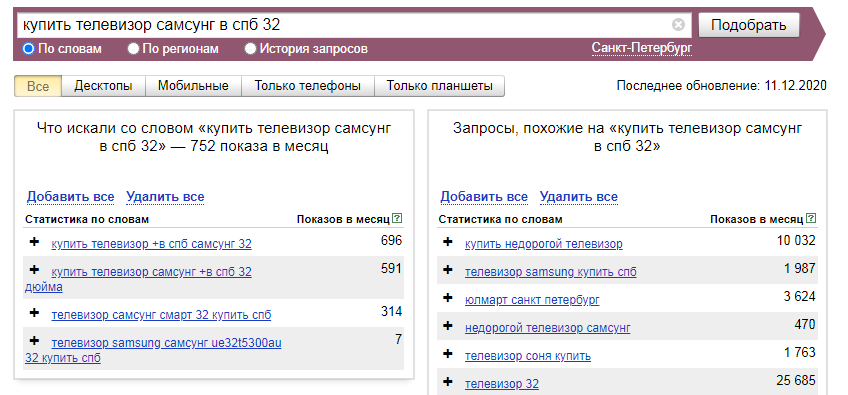
Затем можете «вбивать» запрос, который вас интересует в поисковую строку. Для того, чтобы рассмотреть функционал сервиса, давайте возьмем часто задаваемый вопрос пользователей: «ремонт телефонов».
Как работать с Вордстатом
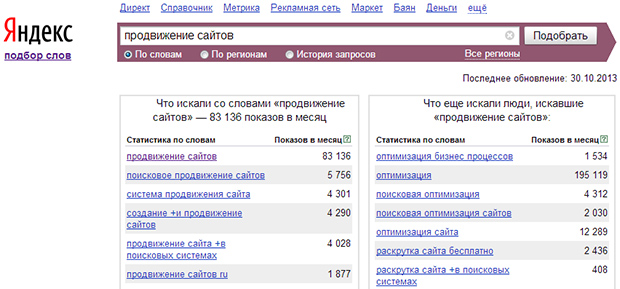
Как вы могли заметить, выдача разделяется на 2 колонки:
- Левая колонка — демонстрируется вся статистика по словам, которые вбивают в связке с «ремонт телефонов». Следовательно, цифра, которая показывает частотность запроса, не относится непосредственно к двум искомым словам, а демонстрирует общее количество запросов, подсчитывая все нижеуказанные словоформы, расположенные под данным словосочетанием. Для сбора точной частотности необходимо использовать вспомогательные операторы.
- Правая колонка — отображаются схожие смысловые запросы с указанной тематикой. У вас может возникнуть вполне логичный вопрос: «Каким образом система определяет аналогичность запросов?». Не вдаваясь в подробности, выглядит это так: Wordstat собирает всю информацию о каждом пользователе: какие запросы он вбивал и в какой период времени, а затем, проводит некий анализ, сопоставляя схожие запросы друг с другом у большинства пользователей за последние 30 дней.
 Пример: в период 30-и дней 100 человек запросило: «разработка интернет магазина». Из них 40 человек запросило: «продвижение сайта». В следствии чего, система отслеживает одинаковые запросы у одних и тех же пользователей и генерирует готовое решение в правую колонку подсказок.
Пример: в период 30-и дней 100 человек запросило: «разработка интернет магазина». Из них 40 человек запросило: «продвижение сайта». В следствии чего, система отслеживает одинаковые запросы у одних и тех же пользователей и генерирует готовое решение в правую колонку подсказок.
 Пример: в период 30-и дней 100 человек запросило: «разработка интернет магазина». Из них 40 человек запросило: «продвижение сайта». В следствии чего, система отслеживает одинаковые запросы у одних и тех же пользователей и генерирует готовое решение в правую колонку подсказок.
Пример: в период 30-и дней 100 человек запросило: «разработка интернет магазина». Из них 40 человек запросило: «продвижение сайта». В следствии чего, система отслеживает одинаковые запросы у одних и тех же пользователей и генерирует готовое решение в правую колонку подсказок.Как выгрузить слова из Вордстата в Эксель
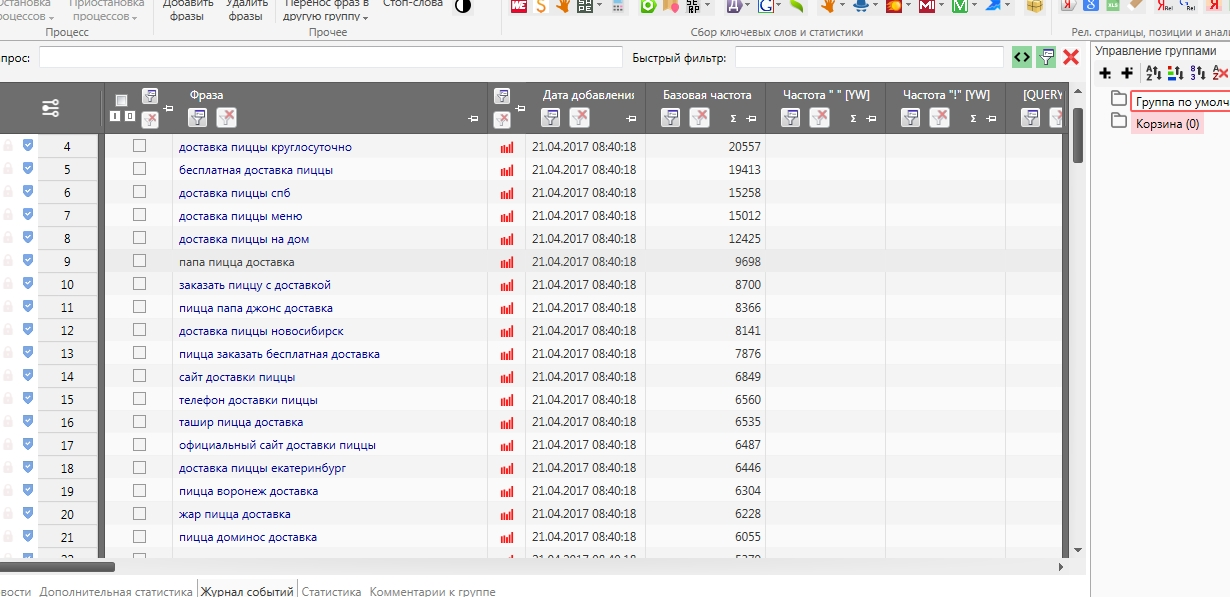
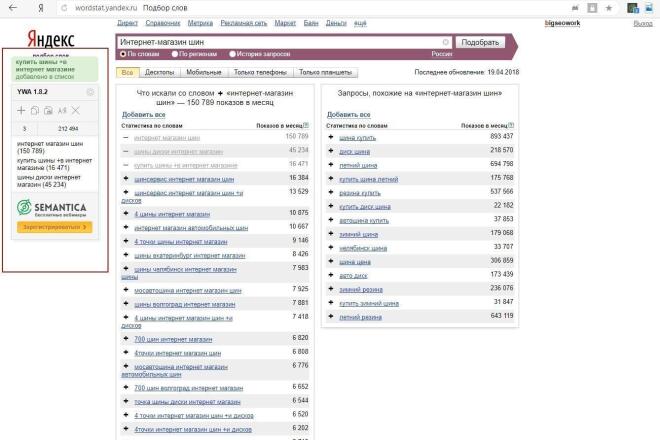
Здесь все очень просто. Вам необходимо:
- Установить специальное расширение для браузера.
- На странице Wordstat, в левом углу у вас появится окно.
- Затем вводите необходимый запрос.
- Напротив каждого слова или словосочетания, полученных в выдаче, вы увидите иконку «+».
- Вам нужно нажимать на «+», расположенный около каждого интересующего вас запроса, таким образом данные слова будут попадать в окно.
- В верху окна находятся две иконки — скопировать с частотностью и без нее.
- Выберите нужный вам способ копирования, затем вставьте в Эксель.
Как выгрузить слова из Водстата в Эксель
Разумеется, вы можете просто их копировать без вспомогательных сервисов, однако у вас уйдет на это чуть больше времени. Разобравшись с базовым функционалом данного сервиса, давайте рассмотрим, как правильно осуществлять подбор ключевых слов для точного вхождения по поисковой фразе.
Разобравшись с базовым функционалом данного сервиса, давайте рассмотрим, как правильно осуществлять подбор ключевых слов для точного вхождения по поисковой фразе.
Что такое операторы
Для уточнения информации по результатам выдачи ключевых слов, необходимо понять, что такое операторы.
Операторы — это специализированные символы, являющие вспомогательным инструментом для определения точной частотности искомого запроса. Перечень операторов:
- кавычки;
- плюс;
- минус;
- восклицательный знак;
- круглые скобочки;
- квадратные скобки.
Кавычки
« » — с помощью данного оператора, вы получите сведения именно о том количестве слов, сколько вписывали в запрос без дополнительных словоформ. То есть, если вы написали: «ремонт телефонов», то информации по: «ремонт мобильных телефонов» не будет. Но данный оператор не фиксирует словосочетание, от склонений, множественной и единственной формы. То есть, вам будут демонстрироваться сведения по: «ремонту телефонов»; «телефонов ремонт» и так далее.
То есть, вам будут демонстрироваться сведения по: «ремонту телефонов»; «телефонов ремонт» и так далее.
Пример использования: «ремонт телефонов».
Вордстат — слова в кавычках
Восклицательный знак
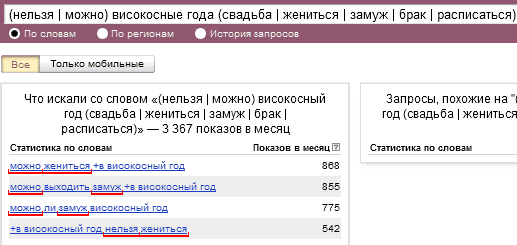
! — определяет форму запроса. Другими словами, вы получите точную информацию именно о словосочетании: «ремонт телефонов», без склонения, падежа, числа и времени, таких как: «ремонту телефонов»; «ремонта телефонам» и так далее. Также нельзя забывать о том, что восклицательный знак должен ставиться перед каждым словом, без отступов.
Пример использования: !ремонт !телефонов.
Вордстат — восклицательный знак перед словом
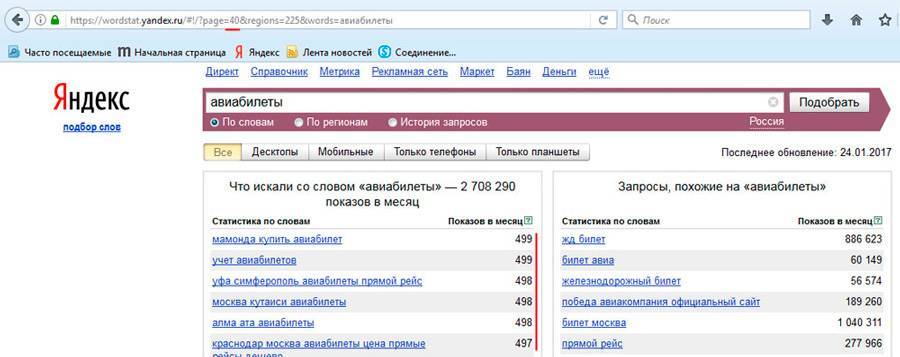
Квадратные скобки
[ ] — показывает порядок слов в запросе. Этот оператор актуально использовать для изучения запросов в отношении билетов из одного города в другой. Например, если вы хотите узнать количество людей, которым интересно путешествие из Санкт-Петербурга в Москву, а не наоборот, то данный оператор вам окажет помощь в этом. Так как, количество запросов «билеты Санкт-Петербург — Москва» составляет 5 916 за последние 30 дней, а: «билеты Москва — Санкт-Петербург» составляет 14 528 за последние 30 дней. Следовательно, как вы сами могли заметить показатели сильно разнятся и без данного уточнения, вы получили бы в корне не верные цифры по искомому запросу. Возвращаясь к примеру: «ремонт телефонов», с помощью этого оператора, вы сможете понять порядок слов и более детально провести анализ запросов в данной области, для дальнейшего формирования рекламного объявления или составления заголовков на продающей странице.
Так как, количество запросов «билеты Санкт-Петербург — Москва» составляет 5 916 за последние 30 дней, а: «билеты Москва — Санкт-Петербург» составляет 14 528 за последние 30 дней. Следовательно, как вы сами могли заметить показатели сильно разнятся и без данного уточнения, вы получили бы в корне не верные цифры по искомому запросу. Возвращаясь к примеру: «ремонт телефонов», с помощью этого оператора, вы сможете понять порядок слов и более детально провести анализ запросов в данной области, для дальнейшего формирования рекламного объявления или составления заголовков на продающей странице.
Пример использования: [ремонт телефонов].
Вордстат — слова в квадратных скобках
Плюс
«+» — существуют некоторые слова и предлоги, которые Wordstat не учитывает. Данный оператор принудительно делает такие слова видимыми для сервиса.
Пример использования: ремонт телефонов +это.
Вордстат — плюс перед словом
Минус
«-» — в свою очередь, убирает не нужные слова, находящиеся в списке выдачи.
Пример использования: ремонт телефонов -дешево -центр — цена.
Вордстат — минус перед словом
Круглые скобочки
«( | )» — позволяют сгруппировать поисковые фразы.
Пример использования: ремонт (телефонов | компьютеров).
Вордстат — слова в круглых скобках
Ответы на часто задаваемые вопросы
Очень часто мы слышим нижеуказанные вопросы от начинающих SEO-оптимизаторов и маркетологов. Поэтому решили сформировать перечень кратких ответов на них.
Что такое десктопы
Выбирая раздел «десктопы», вы даете команду сервису — показывать только сведения о поисковых запросах с ноутбуков и компьютеров.
Что такое десктопы в Вордстате
Как производится массовая проверка частотности запросов
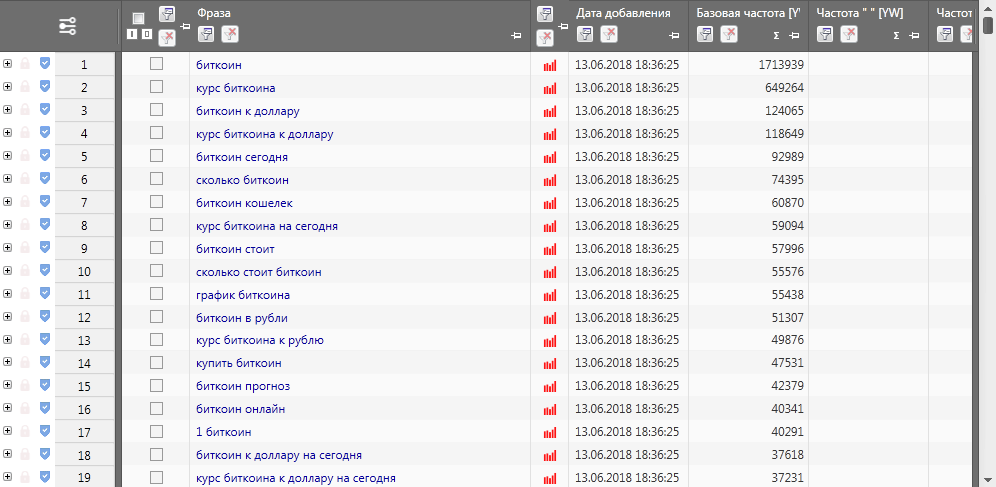
Здесь все зависит от тематики и объема базовой частоты запросов. Другими словами, совершая данную процедуру, вы проводите детальный анализ каждого слова. Тем самым, вам необходимо собрать все классы частотностей запросов:
- высокочастотные — больше 10 000 запросов за 30 дней;
- среднечастотные — от 1000 до 10 000 запросов за 30 дней;
- низкочастотные — меньше 1 000 запросов за 30 дней.

Однако, данные разделения условные, все зависит от тематики запросов. Поэтому, в некоторых случаях, с помощью вышеуказанного расширения, вы производите подбор необходимых запросов и переносите их в Excel. Иногда количество слов по интересующей вас тематике слишком большое и лучше воспользоваться вспомогательными программами для составления семантического ядра, такими как, Key Collector.
Как убрать капчу
Если вы хотите отключить капчу вам нужно:
- Установить adblock.
- Зайти на сервис Wordstat.
- Нажать кнопку adblock, расположенную в верхнем правом углу.
- И выключить adblock находясь на странице Вордстата.
Как посмотреть историю запросов
Если вы хотите посмотреть историю запросов, вам требуется кликнуть на белый кружек, расположенный справа от словосочетания «История запросов», которое находится под поисковой строкой Вордстата.
Как посмотреть история запросов в Вордстате
Как вы могли заметить, диаграмма демонстрирует сведения по месяцам, при этом вы можете узнать выдачу по неделям.![]()
Абсолютное значение — это практическое определение запросов в разное время.
Относительное значение — это соотношение запросов по выбранным ключевым словам к общему количеству запросов в Яндексе. Простыми словами, на этой диаграмме демонстрируется популярность ключевого слова по отношению ко всем остальным.
История запросов может сильно помочь при продаже сезонных товаров, к примеру аренде водных видов транспорта, так как, выдача летом и зимой может кардинально отличаться.
Заключительный результат
В заключении давайте посмотрим, как целиком выглядит точная частотность запроса в Вордстате.
Пример использования: «[!ремонт !телефонов +это]».
Вордстат — заключительный результат
Таким образом, вы получайте наиболее точную информацию по искомому запросу. То есть фиксируйте запрос в отношении числа, времени, склонения, количества дополнительных слов и последовательности. Если у вас остались вопросы по прочитанному материалу — напишите нам в комментариях и мы вам ответим.
#Обзоры
#Кто и что
Yandex.Wordstat – Key Collector
Программа поддерживает работу с сервисом Yandex.Wordstat.
- Пакетный сбор фраз
- Сбор частот
- Сбор данных сезонности
- Вопросы и ответы
Пакетный сбор фраз
Пакетный сбор позволяет собрать новые фразы по списку запросов.
Сбор выполняется из левой или правой колонок результатов. В процессе сбора в таблицу записываются фразы вместе с базовой частотой.
Дополнительные виды частот снимаются отдельно.
В зависимости от популярности запроса сервис выдает до 40 страниц выдачи по 50 результатов (суммарно до 2000 запросов). В редких случаях выдается до 45 страниц.
Инструмент поддерживает стандартные функции окна пакетного сбора фраз.
Выдача по запросу не всегда содержит исходный запрос. Включите опцию принудительного добавления запросов, если хотите добавлять в выдачу исходный запрос.
Параметры сбора
База данных
Вы можете указать предпочтительный тип базы данных, по которой сервис выдает статистику.
Как правило, рекомендуется собирать фразы без ограничений по типу устройств.
Регион
Вы можете задать таргетинг.
Как правило, для максимального охвата выдачи рекомендуется не использовать настройки региональности. Выбор региона может потребоваться при оценке нишевого спроса в каком-либо регионе.
Инструмент поддерживает функцию автоматического назначения региона для одноименных с названиями регионов групп.
Режим сбора
Вы можете выбрать источник данных: левую, правую или обе колонки.
Интегрировать минус-слова в запросы
Программа может автоматически присоединять к исследуемым запросам минус-слова из выбранного списка.
Использование минус-слов позволяет сократить объем выдачи, сделать ее более точной. При исследовании высокочастотных запросов, выдача которых целиком не помещается в лимит 40 страниц выдачи, минус-слова могут помочь собрать дополнительные результаты, т.к. за счет выброса ненужных фраз появится место для эффективных.
Сервис предъявляет набор требований к минус-словам по их длине, кол-ву, отсутствие недопустимых символов и т.
д. Программа не выполняет предварительную проверку минус-слов, поэтому следите за валидностью списка минус-слов самостоятельно.Если выдачи по запросу не оказалось, возможно, проблема в минус-словах, которые полностью отсекают все результаты. Проверьте запрос в браузере вручную, чтобы убедиться, что по нему есть непустой результат.
Добавлять «+» оператор к словам
Сервис может игнорировать предлоги, союзы и другие несущественные по его мнению слова при формировании выдачи по запросу.
Иногда наличие предлога принципиально важно в контексте составления семантического ядра.
Например, при подготовке ядра по информационному сайту в раздел справки важно наличие предлога «как»: «как установить программу»,«как обработать запросы» и т.д.
Для того чтобы сервис принудительно учитывал какое-либо из слов в запросе, его необходимо зафиксировать оператором +:
- +как установить программу
- +как обработать запросы
- +как +сделать пиццу
Не всегда имеется возможность вручную расставлять оператор + перед часто употребимыми предлогами и словами.
Рассматриваемая опция позволяет автоматически добавлять оператор + перед словами из указанного пользователем списка перед отправкой их в сервис.
Другими словами, вы задаете запрос «как установить», а программа отправляет на исследование запрос «+как установить», добавляя оператор + автоматически, если «как» присутствует в списке слов для модификации.

 д. Программа не выполняет предварительную проверку минус-слов, поэтому следите за валидностью списка минус-слов самостоятельно.
д. Программа не выполняет предварительную проверку минус-слов, поэтому следите за валидностью списка минус-слов самостоятельно.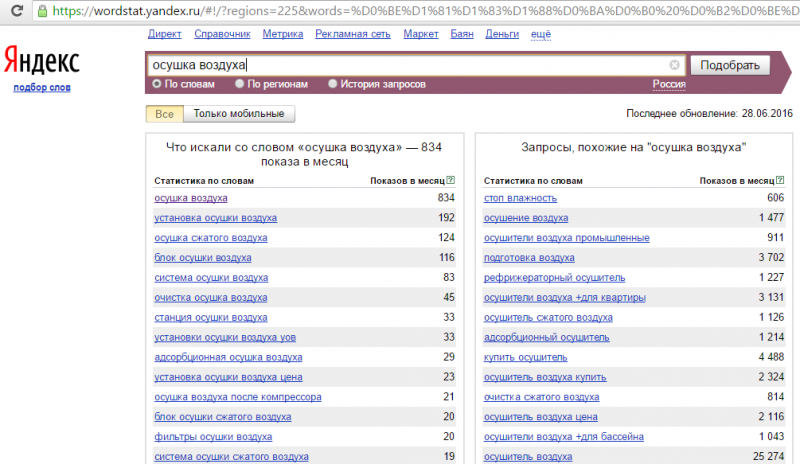
Настройки
Добавлять в таблицу фразы с частотами от … до …
Данное ограничение позволяет отсечь на этапе сбора фразы с заведомого ненужными в ваших задачах частотами.
В теории опция может сэкономить время обработки запросов, если верхний предел будет ограничивать проход по дополнительным страницам выдачи.
Если не использовать опцию, то всегда можно воспользоваться встроенными фильтрами уже после завершения сбора фраз.
Мы не рекомендуем ограничивать выдачу по частотам (особенно по нижней границе), т.к. это может привести к случайному игнорированию хороших запросов.
Записывать {доп. значение} для добавляемых фраз и их расширений
В процессе сбора фраз вы можете использовать разные или общие целевые группы для добавления результатов.
Программа позволяет указать произвольное дополнительное значение, которое будет добавляться в указанную текстовую колонку для всех результатов, относящихся к тому или иному запросу.
Например, в качестве доп. значения можно указать сам исходный запрос или страницу сайта. В дальнейшем по этому значению можно выполнить поиск, сортировку и фильтрацию, определять, откуда пришел запрос и т.
п.- газовая сварка {газовая сварка}
- рецепт соленых огурцов {https://ru.wikipedia.org/wiki/Солёные_огурцы}
Не забывайте заключить доп. значение в фигурные скобки { }
Если вы хотите вводить запросы, содержащие двоеточие, то для корректной работы режима автоматического распределения по группам добавьте двойные кавычки вокруг значений, чтобы символ двоеточия не воспринимался как разделитель пары группа:ключ:
- «газовая сварка {http://site.com}«
- «рецепт соленых огурцов {https://ru.wikipedia.org/wiki/Солёные_огурцы}«

 п.
п.Сбор частот
Сбор частот позволяет оценить популярность запросов.
Сервис выдает кол-во показов запроса за последние 30 дней.
Статистика обновляется не ежедневно, поэтому не воспринимайте этот период буквально.
Сервис поддерживает различные операторы поиска, поэтому программа способна получать несколько видов частот.
- Базовая частота
- Фразовая частота
- Точная фразовая частота
- Точная фразовая частота с порядком
- Частота по маске
Программа автоматически добавляет нужные операторы при сборе того или иного вида частот (добавлять операторы вручную к текст запросов не требуется).
Базовая частота
Базовая частота соответствует широкому типу вхождения слов. Для выполнения запроса достаточно отправить сам запрос в исходном виде:
- свежий хлеб
- условная вероятность
- теорема Байеса
В результатах могут быть учтены и другие фразы, косвенно относящиеся к запросу «свежий хлеб» в широком соответствии: купить свежий хлеб, свежий ржаной хлеб, рецепт хлеба, свежая выпечка и др.
Фразовая частота
Фразовая частота фиксирует состав слов в искомом запросе, и показы считаются для словосочетания целиком. Для выполнения запроса необходимо добавить двойные кавычки:
- «свежий хлеб»
- «теорема Байеса»
- «плотность распределения»
В результатах к запросу «свежий хлеб» будут учтены только фразы с тем же набором слов:: свежий хлеб, хлеба свежего и др.
Точная фразовая частота
Точная фразовая частота фиксирует не только состав, но и словоформы слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе и взять его в двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе: свежий хлеб, хлеб свежий (порядок не фиксируется).
Точная фразовая частота с порядком
Точная фразовая с порядком частота фиксирует состав, словоформы и порядок следования слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе, взять его в и двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе и том же порядке следования: свежий хлеб.
Частота по маске
Вы можете самостоятельно определить маску запроса, используя поддерживаемые сервисом операторы.
Маска запроса должна содержать фрагмент QUERY, который при сборе частот будет заменяться на текст исследуемого запроса.
Например, маска !QUERY трансформирует запрос, добавляя к словам оператор !, а маска «!QUERY» добавляет оператор !, оператор и кавычки (что соответствует точной фразовой частоте с порядком).
Параметры сбора
Параметры сбора идентичны параметрам пакетного сбора фраз.
Настройки
Не снимать частоты для фраз с базовой равной или ниже, чем
Иногда можно сократить время сбора уточняющих видов частот, если заведомо известна их нижняя желаемая граница.
Так как уточняющие виды частот для одного и того же запроса по определению всегда меньше либо равны базовой частоты, а базовая частота часто выдается бонусом при пакетном сборе фраз, можно автоматически пропустить некоторые запросы, если их базовая частота меньше некоторого порога (и уточняющие виды частоты тоже будут меньше этого порога).
Автоматически записывать 0 в колонки частот » » и «!», если базовая частота равна 0
Так как уточняющие виды частот всегда меньше либо равны базовой частоте, то можно сделать вывод о том, что если фраза имеет нулевую базовую частоту, то и уточняющие частоты этой фразы будут нулевыми (т.
е. сбор выполнять не требуется, и можно заочно проставить 0 в ячейки частот).Маска запросов пользовательского формата
Здесь вы можете определить маску запросов для сбора уточняющих видов частот.
При сборе точных видов частот пытаться преобразовать фразы в валидные
Сервис накладывает определенные ограничения по использованию операторов поиска. Например, нельзя совместно использовать минус-слова внутри фразового оператора » «.
Использование этой опции позволяет программе автоматически пытаться преобразовать запрос в валидный перед отправкой его в сервис:
- удаляются минус-слова
- перед оператором + не добавляется оператор !
- перед оператором ! не добавляется дублирующий оператор !
Обработка происходит «за кулисами», неявно для пользователя.
Несмотря на удаление минус-слов, например, частота для скорректированного запроса будет записана в ячейку фразы, которая эти минус-слова содержит.Сохранять историю частот
Программа может опционально хранить в проекте историю изменений частот, с которой можно в дальнейшем ознакомиться на вкладке дополнительной статистики: посмотреть ее в табличном виде и отобразить на графике.
 е. сбор выполнять не требуется, и можно заочно проставить 0 в ячейки частот).
е. сбор выполнять не требуется, и можно заочно проставить 0 в ячейки частот). Несмотря на удаление минус-слов, например, частота для скорректированного запроса будет записана в ячейку фразы, которая эти минус-слова содержит.
Несмотря на удаление минус-слов, например, частота для скорректированного запроса будет записана в ячейку фразы, которая эти минус-слова содержит.Сбор истории частот
Сбор истории частот позволяет оценить популярность запросов в интервале времени.
Сервис выдает историю запросов за период до 2 лет с группировкой по неделям или месяцам. Поддерживается статистика только по базовой частоте (получить историю по уточняющим видам частот нельзя).
При сборе данных программа делает предсказания относительно сезонности запросов, вычисляя пиковые значения частот и проверяя, повторяются ли они год к году. Также вычисляются медиана и среднее арифметическое за период.
Например, запрос «новогодние украшения» имеет ярко выраженный всплеск популярности зимой.
Расширенную статистику в деталях можно посмотреть на вкладке дополнительной статистики.
Параметры сбора
Параметры сбора идентичны параметрам пакетного сбора фраз.
Настройки
При сборе «по месяцам» рассматривать период
В процессе сбора статистики вычисляются медиана и среднее арифметическое значений.
В этой опции вы можете ограничить период, за который будут рассматриваться значения при вычислении этих метрик в процессе сбора истории показов в режиме группировки по месяцам.
Эта настройка не влияет на процесс определения критерия сезонности: признак прогнозируется по данным за весь период.
При сборе «по неделям» рассматривать период
В процессе сбора статистики вычисляются медиана и среднее арифметическое значений.
В этой опции вы можете ограничить период, за который будут рассматриваться значения при вычислении этих метрик в процессе сбора истории показов в режиме группировки по неделям.
Эта настройка не влияет на процесс определения критерия сезонности: признак прогнозируется по данным за весь период.
Дополнять историю
Сервис выдает статистику за период до 2 лет (в режиме группировки по месяцам).
При сборе статистики программа очищает прежние данные по частотам за период и записывает актуальные.
Если включить эту опцию, программа будет дополнять ранее собранные данные истории частот вновь полученными данными.
Вкладка дополнительной статистики
Для просмотра расширенной статистики активируйте вкладку дополнительной статистики Yandex.Wordstat (1) и выберите фразу в таблице (2).
Панель содержит график истории показов, табличное представление данных с возможностью копирования в буфер обмена. Здесь также можно переключиться между источниками данных (3), отобразив собственноручно собранную историю частот из проекта.
Если панель скрыта, вы можете вернуть ее на вкладке инструментов «Вид — Дополнительные панели».
Слишком большое кол-во открытых вкладок дополнительной статистики может привести к замедлению работы интерфейса программы. Рекомендуем закрывать ненужные вкладки и открывать их при необходимости.
Рекомендуем закрывать ненужные вкладки и открывать их при необходимости.
Вопросы и ответы
- Почему из левой колонки собирается только 2000 фраз?
- Почему не собираются фразы вплоть до частоты 0?
- Почему не добавляются запросы?
- Какие существуют ограничения по минус-словам?
Почему из левой колонки собирается только 2000 фраз? Я задаю популярный запрос!
Дело в том, что сервис выдает максимум до 40 страниц выдачи по 50 результатов. 40 * 50 = 2000 фраз. Иногда сервис позволяет заглянуть на 41 или даже 42 страницу, но это скорее исключение.
Даже при исследовании популярных запросов вы не сможете получить все запросы разом. Например, по запросу «купить» нельзя скачать все коммерческие запросы по всем тематикам мира. Для этого придется уточнить исследуемый запрос.
Если вы не можете самостоятельно придумать уточняющие запросы, и вам неоткуда их взять, вы можете использовать результаты выдачи по более широкому запросу в качестве входных запросов для следующего углубленного исследования.
Программа может автоматически выполнить такой анализ, если задать ненулевую глубину запроса в панели настроек окна пакетного сбора фраз.
Будьте осторожны при использовании этой функции, т.к. уже на глубине 1 дополнительно пройтись по 2000 фразам, полученным на нулевой итерации, займет крайне много времени!
Вместо автоматического глубинного исследования для популярных запросов мы рекомендуем просмотреть список полученных фраз на нулевой итерации, сразу удалить лишние запросы, потом скопировать в буфер обмена оставшиеся (через контекстное меню к заголовку колонки «Фраза») и вставить их в окно пакетного анализа.
При таком подходе вы не только сократите время обработки запросов, получите меньше мусора, но и получите полный контроль на процессом: статистику выполнения, возможность приостановки и возобновления парсинга.
Почему не собираются фразы вплоть до частоты 0?
Часто пользователи ожидают, что по некоторому запросу Wordstat всегда выдает полный список запросов в порядке убывания кол-ва показов вплоть до 0. Однако, сервис может не иметь полной выдачи: фразы могут закончиться на любой частоте.
Однако, сервис может не иметь полной выдачи: фразы могут закончиться на любой частоте.
Например, при исследовании ВЧ запросов выдача часто ограничена кол-вом страниц (40 страниц — базовое техническое ограничение самого сервиса), а при исследовании СЧ и НЧ запросов выдача может оборваться в любой момент, не доходя до фраз с частотой 0.
Другими словами, сервис не гарантирует, что исследуемому запросу с частотой 20 000 будет, например, 15 страниц выдачи, где на последней странице фразы будут иметь частоту 1 или 0. Напротив, фразы могут закончиться на любой странице, и последняя фраза в отчете может иметь базовую частоту 2400 или любую другую.
Убедиться в этом можно, выполнив проверочный запрос вручную через браузер и пролистав выдачу до последней страницы.
Почему не добавляются запросы, хотя в журнале событий нет ошибок?
Возможно, по исследуемому запросу просто нет выдачи. Или неверно используются минус-слова.
Рекомендуем ознакомиться со списком причин отсутствия результатов при парсинге и добавлении запросов.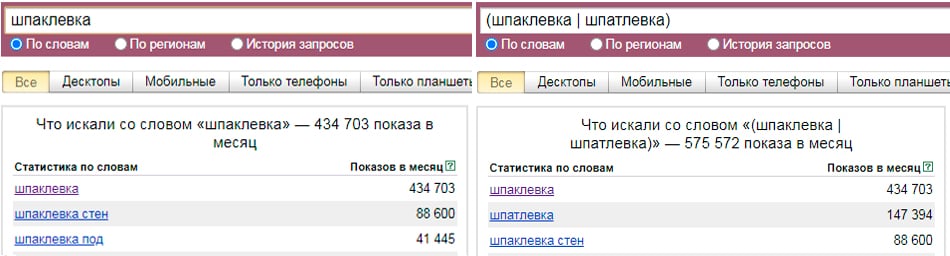
Какие существуют ограничения по минус-словам?
Программа не накладывает ограничения на минус-слова. Но их накладывает сам сервис.
Например, нельзя совершать слишком длинные запросы, использовать слишком большой список минус-слов, использовать составные фразы в минус-словах, некорректно использовать операторы поиска и некоторые спец. символы.
Мы не можем перечислить все правила составления минус-слов, т.к. они формируются на стороне самого сервиса. Если он выдает ошибку при анализе запроса, то проверьте корректность списка минус-слов, устраните все найденные ошибки.
Для диагностики скопируйте результирующий запрос с минус-словами из журнала событий в окне программы и вставьте его вручную через браузер.
Рекомендуем не использовать слишком длинные списки минус-слов. Также нет смысла добавить одни и те же слова в разных склонениях, если вы используете широкую минусацию (сервис самостоятельно учтет словоформы).
последние новые функции интеллектуального анализа текста
Новые функции WordStat 6.
 1
1
- Новый многоязычный пользовательский интерфейс (английский, французский и испанский)
- Улучшенная лингвистическая поддержка со встроенными словарями и тезаурусами для пяти языков (английский, французский, испанский, немецкий и португальский) для помощи в разработке таксономий и словарей для контент-анализа
- Повышение скорости обработки на 50 % по сравнению с предшественником, что позволяет анализировать до 30 миллионов слов в минуту
Новые функции WordStat 6
1. НОВАЯ ФУНКЦИЯ АВТОМАТИЧЕСКИХ ПРЕДЛОЖЕНИЙ
На странице частоты дополнительная панель (справа) автоматически показывает для выбранных элементов (слов или категорий контента) все связанные оставшиеся слова (синонимы, антонимы, гипонимы). , гиперонимы, слова с одинаковым основанием и т. д.), что позволяет выбрать релевантные слова и отнести их к категории. Обратите внимание, что эта функция полностью функциональна только при анализе документа на английском языке.
 При анализе документов на других языках на панели будут отображаться слова с похожей корневой формой.
При анализе документов на других языках на панели будут отображаться слова с похожей корневой формой.2. ИНТЕГРИРОВАННАЯ ФУНКЦИЯ ПЕРЕТАСКИВАНИЯ В СЛОВАРЬ
Редактор словаря с перетаскиванием был заменен новой панелью перетаскивания, доступной в левой части страниц «Частоты», «Перекрестная таблица» и «Поиск фраз», что упрощает назначение словарь категорий, список исключений и новый список замещения. Назначения в новую категорию можно выполнить, перетащив один или несколько элементов на значок дерева НОВАЯ КАТЕГОРИЯ.
3. КЛАСТЕРИЗАЦИЯ И АНАЛИЗ СООТВЕТСТВИЙ ФРАЗ
Теперь можно выполнять кластерный анализ и анализ соответствий фраз без необходимости сохранять их в словарь категорий. Диалог также позволяет добавлять в этот список часто встречающиеся слова и сохранять извлеченные фразы в новый словарь.
4. Гистограмма с накоплением и пузырьковая диаграмма
Две новые диаграммы были добавлены для отображения связи между кодами и переменными: столбчатая диаграмма с накоплением позволяет отображать относительную или абсолютную частоту кодирований путем их суммирования для каждого класса категориальной или числовой переменной.
Пузырьковая диаграмма представляет собой графическое представление кросс-таблиц, в которых относительные частоты представлены кружками разного диаметра. Этот тип диаграммы позволяет быстро идентифицировать высокочастотные и низкочастотные ячейки и, таким образом, особенно полезен для презентационных целей. Многие функции диаграммы можно настроить, чтобы выделить конкретные результаты. Строки и столбцы можно свободно перемещать или удалять, и можно настроить цвет каждой ячейки, а также используемые шрифты.
 Он позволяет быстро показать отношение частей к целому или подчеркнуть сумму нескольких кодов.
Он позволяет быстро показать отношение частей к целому или подчеркнуть сумму нескольких кодов.5. ИЗМЕНЕННЫЙ ДИАГРАММ БЛИЗОСТИ
График близости теперь создает графику высокой четкости и теперь может использоваться для отображения близости от более чем одного ключевого слова с помощью двойных и сложенных гистограмм.
6. УЛУЧШЕННЫЕ МНОГОМЕРНЫЕ ГРАФИКИ МАСШТАБИРОВАНИЯ
Теперь можно отображать частоту терминов в 2D- и 3D-графиках MDS, используя пузырьковых графиков .
 Кроме того, новый алгоритм ограниченной кластеризации теперь позволяет сохранять структуру кластеризации на многомерных графиках масштабирования, что значительно упрощает интерпретацию 2D- и 3D-карт MDS и делает ее более согласованной с решениями кластеризации.
Кроме того, новый алгоритм ограниченной кластеризации теперь позволяет сохранять структуру кластеризации на многомерных графиках масштабирования, что значительно упрощает интерпретацию 2D- и 3D-карт MDS и делает ее более согласованной с решениями кластеризации.7. УЛУЧШЕННЫЕ ДЕНДРОГРАММЫ
Теперь можно отображать частоты терминов вместе с дендрограммами, используя гистограмму.
8. ПЕРЕКРЕСТНАЯ СТАБИЛИЗАЦИЯ ПО ДВУМ ПЕРЕМЕННЫМ
Страница КРОССТАБИЛЬНАЯ СТАБИЛИЗАЦИЯ теперь позволяет исследовать взаимосвязь между словами или категориями контента и комбинированными значениями двух переменных (например, пол x возраст).
9. АВТОМАТИЧЕСКИЙ ПОИСК И КОДИРОВАНИЕ КАТЕГОРИЙ СОДЕРЖАНИЯ
Новая кнопка на странице ЧАСТОТЫ позволяет получить все абзацы или предложения, соответствующие любой из категорий контента, и прикрепить к ним соответствующий код QDA Miner.
 Если у определенной категории контента нет соответствующих кодов в кодовой книге проекта, автоматически будет создана новая.
Если у определенной категории контента нет соответствующих кодов в кодовой книге проекта, автоматически будет создана новая.10. НОВАЯ ФУНКЦИЯ ЗАМЕНЫ
Функция предварительной обработки лемматизации была заменена более гибким процессом замены. Этот новый процесс не только поддерживает существующие процедуры лемматизации, но и позволяет пользователям создавать собственный процесс замены для лемматизации текста на языке, который в настоящее время не поддерживается WordStat, или автоматически исправлять орфографические ошибки без изменения исходных документов. Процесс замены может также использоваться для предварительной категоризации и использоваться в сочетании со словарем категоризации.
11. ФУНКЦИЯ ОТМЕНЫ РЕДАКТИРОВАНИЯ СЛОВАРОВ
Все изменения, внесенные в список исключений, словарь категорий и новый процесс замены, теперь отслеживаются и могут быть отменены.
12. УЛУЧШЕННЫЕ ЛИНГВИСТИЧЕСКИЕ РЕСУРСЫ
Внутренние лингвистические ресурсы для английского языка были значительно улучшены благодаря обновлению до WordNet 3 и добавлению третьего тезауруса.

13. ПОДДЕРЖКА МЕНЕДЖЕРА ОТЧЕТОВ
WordStat теперь объединяет функции диспетчера отчетов, представленные в QDA Miner 3.0, что позволяет хранить в одном месте документы, таблицы, графику и текстовые результаты, созданные QDA Miner и WordStat. Менеджер отчетов структурирован как планировщик (аналогично средству просмотра выходных данных SPSS), что позволяет легко просматривать элементы, редактировать их, реорганизовывать и создавать черновые версии отчетов.
Кнопки, подобные этой, были добавлены во многие диалоговые окна для автоматического сохранения таблиц, диаграмм и текста в диспетчере отчетов. Удерживая нажатой клавишу Shift при нажатии этой кнопки, откроется диалоговое окно, в котором можно настроить заголовок и ввести описание сохраненного элемента.
14. УЛУЧШЕННОЕ ИЗВЛЕЧЕНИЕ ФРАЗ
Реализован новый алгоритм удаления избыточных или лишних последовательностей слов.
15.
 УЛУЧШЕННАЯ ПАНЕЛЬ ПЕРЕКРЫТИЯ ФРАЗ
УЛУЧШЕННАЯ ПАНЕЛЬ ПЕРЕКРЫТИЯ ФРАЗ
Теперь можно выполнять операции над фразами, перечисленными в панели перекрытия (перетаскивание в словарь, получение списка KWIC или удаление их)
16. УЛУЧШЕННЫЙ ЭКСПОРТ СТАТИСТИКИ ДАННЫХ
Диалоговое окно для экспорта статистики данных на диск было улучшено за счет новых опций для выбора переменных, которые будут добавлены в отчет, и возможности экспорта вхождений категорий содержимого в полиномиальные переменные. Панель параметров также позволяет предварительно просмотреть данные для экспорта.
17. СТАТИСТИКА ПОКРЫТИЯ ДОКУМЕНТОВ И СЛОВАРОВ
На странице ЧАСТОТЫ появилась новая кнопка, позволяющая получить различную статистику документа (количество слов, предложений, абзацев, слов в предложении и т.д.) и оценить охват словарь контент-анализа (процент слов, предложений, абзацев, документов и дел, содержащих элементы по категориям).
18.
 ЭКСПОРТ ДАННЫХ СОВМЕСТНОСТИ В ПРОГРАММУ ДЛЯ АНАЛИЗА СОЦИАЛЬНЫХ СЕТЕЙ
ЭКСПОРТ ДАННЫХ СОВМЕСТНОСТИ В ПРОГРАММУ ДЛЯ АНАЛИЗА СОЦИАЛЬНЫХ СЕТЕЙ
Данные о совпадениях теперь можно экспортировать в популярные программы для анализа социальных сетей, такие как UCINET, Pajek, NetDraw и NetMiner.
19. ЭКСПОРТ В ФАЙЛЫ SPSS
Все таблицы и матрицы данных теперь можно экспортировать непосредственно в файлы данных SPSS .SAV.
20. ВЕРТИКАЛЬНЫЕ МЕТКИ НА ТАБЛИЦАХ И ГРАФИКАХ
В различные диаграммы и таблицы добавлена новая кнопка для отображения меток столбцов или на нижней оси вертикально, а не горизонтально.
21. СОЗДАНИЕ КАТЕГОРИЙ QDA MINER CODEBOOK
В диалоговом окне поиска ключевых слов с помощью WordStat 5.1 можно было назначить существующий код QDA Miner извлеченным текстовым сегментам. Также можно было добавлять новые коды, но нельзя было создавать новые категории в кодовой книге. WordStat 6 теперь позволяет добавлять категории в существующую кодовую книгу QDA Miner или создавать новую кодовую книгу.
22. СПИСОК KWIC ДЛЯ НЕСКОЛЬКИХ ЗАПИСЕЙ
Определяемое пользователем поле редактирования в диалоговом окне «Ключевое слово в контексте» теперь поддерживает спецификацию нескольких записей (разделенных точкой с запятой). Выбор нескольких строк таблицы и вызов списка KWIC также приведет к созданию списка KWIC для всех выбранных элементов.
23. ПОДДЕРЖКА ДИСКРИПТОРОВ КЕЙСОВ QDA MINER
Поддержка дескрипторов кейсов QDA Miner позволяет определять более подробные метки кейсов на основе нескольких переменных.
24. ВЫБОР НЕЗАВИСИМЫХ ПЕРЕМЕННЫХ
Новая опция теперь позволяет выбирать новые независимые переменные без необходимости возвращаться в QDA Miner или Simstat.
25. ВЫБОР ПО КОЛИЧЕСТВУ ЭЛЕМЕНТОВ
Новая опция позволяет ограничить количество извлекаемых элементов до определенного числа (например, выбрать 100 наиболее часто встречающихся слов или 200 элементов с наибольшим значением TFxIDF).

26. ВОЗМОЖНОСТЬ УКАЗАНИЯ СПЕЦИАЛЬНЫХ ВСТРОЕННЫХ СИМВОЛОВ
Новая опция позволяет идентифицировать специальные символы, которые будут распознаваться как неотъемлемые части слова (или токена) при условии, что они непосредственно окружены с обеих сторон другими допустимые символы. Например, ввод точки и знака @ в этом списке сохранит адреса электронной почты нетронутыми и извлечет их. При вводе точки и запятых в этом списке и знака $ в другом списке допустимых символов будут получены такие элементы, как 1000 долларов или 3,1415. Слова в конце предложений по-прежнему будут извлекаться без знака точки, поскольку за этой точкой, вероятно, будет следовать пробел или возврат каретки (таким образом, они не будут окружены буквенно-цифровыми символами).
27. ВОЗМОЖНОСТЬ ПОВТОРНОГО ПРИМЕНЕНИЯ ПРЕДЫДУЩИХ ОРФОПРАФИЧЕСКИХ ИСПРАВЛЕНИЙ
Все замены орфографических ошибок, выполненные в тексте с помощью функции «неизвестные слова», автоматически сохраняются.
 При использовании этой же функции в новой текстовой коллекции программа автоматически предложит повторно применить исправления, сделанные ранее.
При использовании этой же функции в новой текстовой коллекции программа автоматически предложит повторно применить исправления, сделанные ранее.28. НОВЫЙ АЛГОРИТМ ДЛЯ УСКОРЕННОГО АНАЛИЗА СООТВЕТСТВИЙ
Мы реализовали гораздо более быстрый алгоритм анализа соответствий. См. результаты синхронизации ниже.
РАЗМЕР
ВРЕМЯ ВЫЧИСЛЕНИЯ
WORDSTAT 5.1ВРЕМЯ ВЫЧИСЛЕНИЙ
WORDSTAT 6.0283 случая x 10 переменных
1,28 секунды
0,00 секунды
854 случая x 10 переменных
34,1 секунды
0,03 секунды
1377 наблюдений x 10 переменных
2 минуты 28 секунд
0,05 секунды
2027 случаев x 10 переменных
20 минут 2 секунды
0,06 секунды
3089 случаев x 10 переменных
1 час 34 минуты 8 секунд
0,11 секунды
29.
 УЛУЧШЕННЫЙ КОНСТРУКТОР СЛОВАРОВ
УЛУЧШЕННЫЙ КОНСТРУКТОР СЛОВАРОВ
Конструктор словарей был улучшен несколькими способами. Теперь он использует последнюю версию WordNet 3.0 (предыдущая версия использовала WordNet 1.7). Добавлена новая опция для отображения только слов, присутствующих в вашей текстовой коллекции (остаточные слова). Это также примерно в два раза быстрее, чем предыдущие версии.
30. УЛУЧШЕННОЕ ДИАЛОГОВОЕ ОКНО ОСНОВНЫХ ПРЕДЛОЖЕНИЙ
Функция «Основные предложения» была переработана. Теперь он предоставляет больше предложений и позволяет фильтровать предложения, чтобы отображать только слова, которые в настоящее время находятся в текущей коллекции документов. Скорость этой функции также значительно улучшилась.
31. ИНТЕРАКТИВНЫЙ ДВУХМЕРНЫЙ ДИАГРАММА СООТВЕТСТВИЙ
Теперь можно щелкнуть правой кнопкой мыши по ключевому слову в корреспонденции и получить список ключевых слов в контексте или поиск ключевых слов.
 Можно также использовать щелчок правой кнопкой мыши, чтобы удалить ключевое слово или класс категориальной переменной и пересчитать анализ соответствия, что позволяет легко удалить выбросы и отобразить взаимосвязь между оставшимися элементами.
Можно также использовать щелчок правой кнопкой мыши, чтобы удалить ключевое слово или класс категориальной переменной и пересчитать анализ соответствия, что позволяет легко удалить выбросы и отобразить взаимосвязь между оставшимися элементами.32. УЛУЧШЕННАЯ ОБРАБОТКА ДАТ
При выборе переменной даты на странице кросс-таблицы появляется диалоговое окно, позволяющее сгруппировать все даты по десятилетиям, годам, месяцам, кварталам или дням недели.
33. УЛУЧШЕННАЯ КОМАНДА «ДОБАВИТЬ В КАТЕГОРИИ»
При выборе нескольких слов или фраз в таблице и последующем выборе команды ДОБАВИТЬ В СЛОВАРЬ КАТЕГОРИИ теперь предлагается добавить их все сразу в одну категорию.
34. УЛУЧШЕННОЕ ДИАЛОГОВОЕ ОКНО ДЛЯ ДОБАВЛЕНИЯ ЭЛЕМЕНТОВ В СЛОВАРЬ
Новое диалоговое окно позволяет назначать элементы в новую категорию за один шаг (пользователям больше не нужно сначала создавать категорию, а затем назначать слова или фразы).
 в эту вновь созданную категорию).
в эту вновь созданную категорию).35. ИЗМЕНЕННЫЙ ДИЗАЙН СТРАНИЦЫ СЛОВАРОВ
Более легкая для изучения и использования страница словаря.
36. ИЗМЕНЕННЫЙ ДИАЛОГ ФИЛЬТРАЦИИ КЕЙСОВ
Более простой в использовании диалог фильтрации кейсов, аналогичный QDA MINer (с возможностью вызова предыдущих диалогов фильтрации).
37. УПРОЩЕННАЯ НАСТРОЙКА АНАЛИЗА СООТВЕТСТВИЙ
Настройка графиков соответствий теперь проще благодаря новому диалоговому окну для базового редактирования.
38. НАЗНАЧЕНИЕ КАТЕГОРИЙ ИЗ ДИАЛОГА KWIC
Теперь можно назначить слово или фразу категории со страницы KWIC, поместив курсор редактирования текстового поля под таблицей на слово, которое нужно классифицировать, или выбрав фразу, а затем щелкните ее правой кнопкой мыши.
39. НОВЫЕ СРАВНЕНИЯ С ТЕКСТОВЫМ КОРПУСОМ
Новые файлы данных о частоте слов для сравнения любой текстовой коллекции с частотами слов в Британском национальном корпусе и Открытом американском национальном корпусе
Анализ частоты слов
, автоматическая классификация документов
С помощью WordStat аналитики данных могут быстро извлекать ценные результаты текстовой аналитики из больших коллекций документов, таких как отзывы клиентов, электронные письма, открытые ответы, стенограммы интервью, отчеты об инцидентах, патенты, юридические документы, блоги, веб-сайты и многое другое..png) Вот список функций анализа контента и анализа текста в WordStat:
Вот список функций анализа контента и анализа текста в WordStat:
Импорт из многих источников
WordStat позволяет напрямую импортировать контент на нескольких языках из многих источников:
- Импорт документов: Word, PDF, HTML, PowerPoint, RTF, TXT, XPS, ePUB, ODT, WordPerfect.
- Импорт файлов данных: Excel, CSV, TSV, Access
- Импорт из статистического программного обеспечения : Stata, SPSS
- Импорт из социальных сетей: Facebook, Twitter, Reddit, YouTube, RSS
- Импорт из писем: Outlook, Gmail, MBox
- Импорт из веб-опросов: Qualtrics, SurveyMonkey, SurveyGizmo, QuestionPro, Voxco, Triple-s
- Импорт из инструментов управления ссылками : Endnote, Mendeley, Zotero, RIS
- Импорт графики: BMP, WMF, JPG, GIF, PNG. Автоматически извлекать любую информацию, связанную с этими изображениями, такую как географическое положение, название, описание, авторов, комментарии и т. д., и преобразовывать их в переменные
- Импорт из баз данных XML
- Соединение с базой данных ODBC доступно.
- Импорт проектов из качественное программное обеспечение: файлы NVivo, Atlas.ti, Qdpx
- Импорт и анализ многоязычных документов включая языки с письмом справа налево
- Отслеживайте определенную папку и автоматически импортируйте любые документы и изображения, хранящиеся в этой папке, или отслеживайте изменения в исходном исходном файле или онлайн-сервисах.
 д., и преобразовывать их в переменные
д., и преобразовывать их в переменные.
Организуйте свои данные
Несколько функций позволяют легко организовать ваши данные таким образом, чтобы упростить процесс анализа:
- Быстро группируйте, маркируйте, сортируйте, добавляйте, удаляйте документы или находите дубликаты.
- Присвойте своим документам переменные вручную или автоматически с помощью мастера преобразования документов, например: дату, автора или демографические данные, такие как возраст, пол или местонахождение.
- Легко переупорядочивайте, добавляйте, удаляйте, редактируйте и перекодируйте переменные.
- Фильтрация обращений на основе значений переменных.

Быстрое извлечение смысла с помощью режима проводника
Быстрое и простое извлечение смысла из больших объемов текстовых данных с помощью режима проводника, специально разработанного для тех, у кого мало опыта анализа текста.
Определите наиболее часто встречающиеся слова и фразы и извлеките наиболее важные темы из ваших документов с помощью инструмента моделирования тем. В любой момент вы можете переключиться в экспертный режим, который дает вам доступ ко всем функциям WordStat.
Изучите содержимое документа с помощью Text Mining
За несколько секунд изучите содержимое больших объемов неструктурированных данных и извлеките полезную информацию:
- Извлеките наиболее часто встречающиеся слова, фразы, выражения.
- Быстро извлекайте темы, используя кластеризацию или двухмерное и трехмерное многомерное масштабирование слов или фраз.
- Легко определить все ключевые слова, которые совпадают с целевым ключевым словом, используя график близости.
- Исследуйте отношения между словами или понятиями с помощью функции анализа ссылок.
- Уточнить анализ, применяя критерий совпадения ключевых слов (в случае, предложении, абзаце, окне из n слов, пользовательском сегменте), а также методы кластеризации (близость первого и второго порядка, выбор мер подобия).
- Исследуйте сходство между концепциями или документами, используя иерархическую кластеризацию, многомерное масштабирование, анализ связей и график близости.
Использование моделирования тем для извлечения наиболее значимых тем
Получите краткий обзор наиболее значимых тем из очень больших коллекций текстов, используя современное автоматическое извлечение тем, применяя комбинацию обработки естественного языка и статистический анализ (NNMF или факторный анализ) не только слов, но и фраз и связанных слов (включая орфографические ошибки).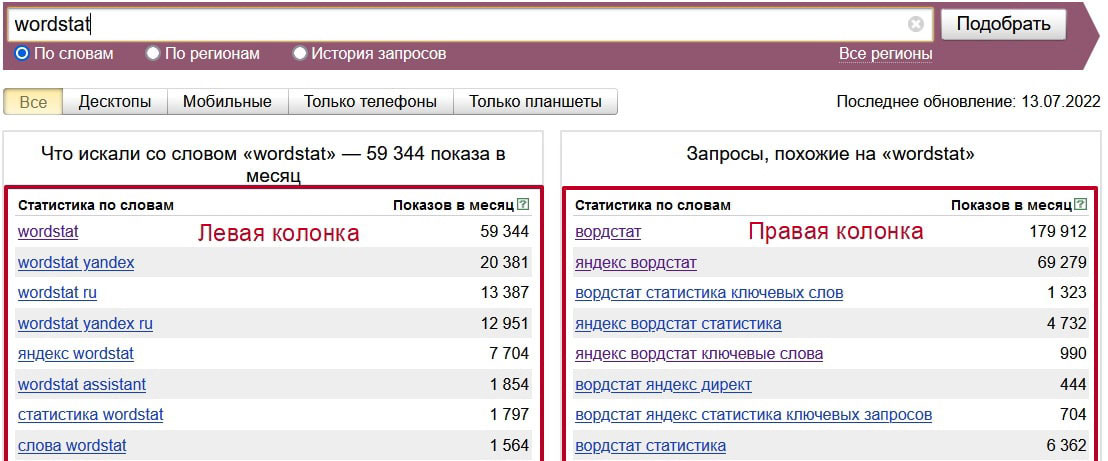
В то время как в иерархическом кластерном анализе слово может появляться только в одном кластере, моделирование темы может привести к тому, что слово будет связано с более чем одной темой, характеристика, которая более реалистично отражает многозначный характер некоторых слов, а также множественность слов. контексты употребления слов.
Исследуйте связи
Исследуйте связи между словами или понятиями, используя сетевой график. Выявляйте основные шаблоны и структуры совпадений, используя три типа макета: многомерное масштабирование, график, основанный на силе, и круговой макет.
Графики являются интерактивными и могут использоваться для изучения взаимосвязей и извлечения текстовых сегментов, связанных с определенными соединениями.
Связывание текста со структурированными данными
Изучение отношений между неструктурированным текстом и структурированными данными:
- Определение временных тенденций, различий между подгруппами или оценка взаимосвязей с рейтингами или другими видами категориальных или числовых данных с помощью статистических и графических инструментов ( таблица отклонений, анализ соответствий, тепловые карты, пузырьковые диаграммы и др. ).
- Оцените взаимосвязь между встречаемостью слова и номинальными или порядковыми переменными, используя различные меры ассоциации: хи-квадрат, отношение правдоподобия, Тау-а, Тау-b, Тау-с, симметричный Сомерс D, асимметричный Сомерс Dxy и Dyx, гамма, R человека, Rho Спирмена.
 ).
).Категоризация текстовых данных с помощью словарей
Автоматизация полнотекстового анализа с помощью существующих словарей или создание собственной модели категоризации слов и фраз.
В словаре можно реализовать логические (И, ИЛИ, НЕ) и правила близости (РЯДОМ, ПОСЛЕ, ДО) и использовать формулы регулярных выражений для быстрого извлечения конкретной информации из текстовых данных.
Управляемая словарем лемматизация и выделение корней доступны на нескольких языках, а опция автоматической замены слов позволяет заменять несколько слов целевым ключевым словом. Определенный пользователем список стоп-слов доступен на нескольких языках, чтобы избежать при анализе несущественных частых слов, таких как он, она, оно и т.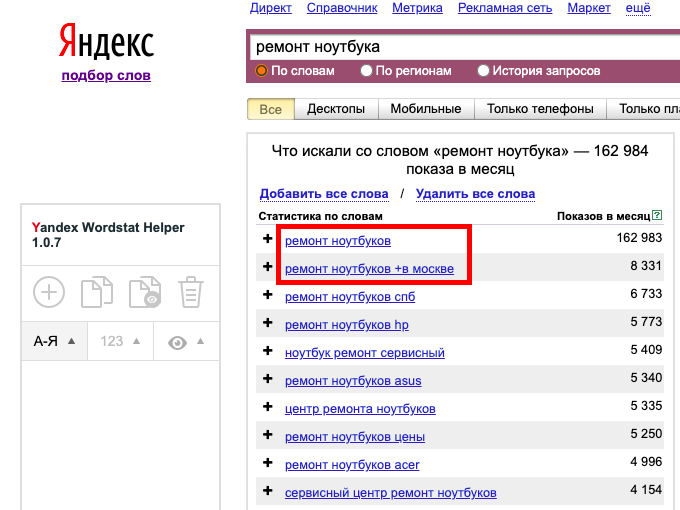 д.
д.
Получите уникальную помощь в создании словаря
Получите действительно уникальную компьютерную помощь в создании таксономии с инструментами для извлечения общих фраз и технических терминов и для быстрого выявления в вашей текстовой коллекции орфографических ошибок и связанных слов (синонимы, антонимы, холонимы, меронимы, гиперонимы, гипонимы).
Автоматическая классификация текстовых данных с помощью машинного обучения
Разработка и оптимизация моделей автоматической классификации документов с использованием наивного байесовского алгоритма и метода K-ближайших соседей. Существует множество методов проверки, которые пользователи могут выбрать: «Оставить, но один», n-кратная перекрестная проверка, разделенная выборка. Модуль экспериментов можно использовать для простого сравнения моделей прогнозирования и точной настройки моделей классификации.
Модели классификации можно сохранить на диск и применить позже в QDA Miner, в автономной служебной программе классификации документов, в программе командной строки или в библиотеке программирования.
Возврат к исходному документу одним щелчком мыши
Проверьте или углубитесь в свой анализ, вернувшись к тексту практически любой функции, диаграммы или графика, используя поиск ключевых слов или ключевое слово в контексте для извлечения предложений, абзацев. или целые документы. Это особенно полезно при построении таксономий или для устранения неоднозначности смысла слов.
Полученные текстовые сегменты можно сортировать по ключевому слову или любой независимой переменной. Вы можете прикреплять коды QDA Miner к полученным сегментам или экспортировать их на диск в табличном формате (Excel, CSV и т. д.) или в виде текстовых отчетов (MS Word, RTF и т. д.).
Выполнение качественного кодирования
Объедините WordStat с современным инструментом качественного кодирования (QDA Miner) для более точного исследования данных или более глубокого анализа конкретных документов или извлеченных текстовых сегментов, когда это необходимо. .
Преобразование неструктурированного текста в интерактивные карты (картографирование ГИС)
Соотнесение неструктурированных текстовых данных с географической информацией и создание интерактивных графиков точек данных, тематических карт и тепловых карт, а также веб-служба геокодирования для преобразования названий местоположений, почтовых индексов и IP-адреса в широту и долготу.