Содержание
Алгоритмы поиска, которые должен знать каждый специалист по обработке и анализу данных | by not eisenheim | NOP::Nuances of Programming
В последние годы алгоритмы для решения задач автоматического планирования и диспетчеризации стали вновь популярными в области машинного обучения. Понимание принципов их работы поможет увеличить производительность ваших моделей. К тому же, благодаря разработке таких мощных вычислительных технологий, как квантовых компьютеров, вскоре вновь будет использоваться искусственный интеллект, основанный на поиске.
Алгоритм поиска — это не то же, что и поисковая служба
Поиск в рамках искусственного интеллекта — это процесс перемещения из исходного состояния в целевое через промежуточные.
Почти любая задача в рамках искусственного интеллекта может быть сформулирована при помощи этих терминов:
- Состояние — потенциальные исходы в задаче.
- Переход — смена одного состояния другим.

- Исходное состояние — состояние системы на момент начала поиска. С него мы начинаем поиск.
- Промежуточное состояние — состояние, в которое совершается переход на пути от исходного к целевому.
- Целевое состояние — состояние, при достижении которого поиск останавливается.
- Область поиска — множество состояний.

Неинформированный поиск используется в том случае, когда нет информации о стоимости перехода из одного состояния в другое.
Существует три главных классических алгоритма неинформированного поиска:
- Поиск в глубину — обходит область поиска, используя LIFO-стек для определения следующей вершины.
Преимущества: хорошо работает в глубоких графах, эффективен по памяти.
Недостатки: есть вероятность зацикливания. - Поиск в глубину с итеративным углублением— обходит область поиска, используя LIFO-стек для определения следующей вершины. Когда алгоритм достигает заранее заданной глубины, он очищает стек, увеличивает счётчик достижения предельной глубины и запускает поиск заново из текущей вершины.
- Поиск в ширину — обходит область поиска, используя FIFO-очередь для определения следующей вершины.
 Когда алгоритм достигает заранее заданной глубины, он очищает стек, увеличивает счётчик достижения предельной глубины и запускает поиск заново из текущей вершины.
Когда алгоритм достигает заранее заданной глубины, он очищает стек, увеличивает счётчик достижения предельной глубины и запускает поиск заново из текущей вершины.Информированный поиск используется в том случае, когда мы знаем точную стоимость или же оценку стоимости смены состояний.
- UCS — обходит область поиска, используя очередь с приоритетом и текущий счёт. Текущий счёт для каждого состояния — стоимость достижения состояния из его родителя, то есть, из предыдущего состояния.
- A* — обходит область поиска, используя очередь с приоритетом и текущий счёт. Текущий счёт для каждого состояния — стоимость достижения состояния через его родителя в пути и эвристическая оценка стоимости перехода из текущей вершины в целевую.
Допустимое значение эвристической оценки должно удовлетворять следующим двум условиям: во-первых, эвристическая оценка должна быть меньше минимальной стоимости перехода из текущей вершины в целевую; во-вторых, она должна быть меньше эвристической оценки каждой из родительских вершин и стоимости достижения состояния в текущем пути. - IDA* — версия поиска A* с итеративным углублением.

Алгоритмы локального поиска используются в том случае, когда существует несколько возможных целевых состояний, но некоторые из них лучше других, то есть, возникает необходимость найти лучший из нескольких. Они довольно часто используются для оптимизации алгоритмов машинного обучения.
- Поиск восхождением к вершине — жадный итеративный алгоритм, выбирающий следующим состоянием наименее затратное, пока оно не достигнет локального максимума.
- Алгоритм имитации отжига — имитирует физический процесс, восходя к вершине, пока не достигнет локального максимума. При его достижении используется функция “температуры”, которая определяет: стоит ли окончить поиск или продолжать его в попытке найти лучшее решение.
- GSAT — алгоритм поиска восхождением к вершине на конъюнктивной нормальной форме. Для каждого возможного параметра подбирается случайное множество булевых значений. Если эти значения удовлетворяют предусловиям целевого состояния, то работа алгоритма завершена. Если же нет, то значения инвертируются таким образом, чтобы выражение соответствовало максимальному числу предусловий. Процесс повторяется заново с новым случайным множеством значений для ранее инвертированных переменных.
- Генетический алгоритм — генерируется исходная популяция состояний, из которой выбирается часть с наибольшим значением функции приспособленности. Оставшиеся состояния рандомно объединяются, немного мутируют, а затем вновь производится отбор лучших решений в следующее поколение.
- Лучевой поиск — UCS с сохранением значений правдоподобной вероятности значений текущего и предыдущего шага модели. На каждом шаге алгоритм отбирает N наиболее вероятных состояний для дальнейшего поиска.
- Метод Монте-Карло — рандомизированный алгоритм поиска, который возвращает лучшее приближение верного результата поиска. Он довольно быстрый, но не точный.
 Если эти значения удовлетворяют предусловиям целевого состояния, то работа алгоритма завершена. Если же нет, то значения инвертируются таким образом, чтобы выражение соответствовало максимальному числу предусловий. Процесс повторяется заново с новым случайным множеством значений для ранее инвертированных переменных.
Если эти значения удовлетворяют предусловиям целевого состояния, то работа алгоритма завершена. Если же нет, то значения инвертируются таким образом, чтобы выражение соответствовало максимальному числу предусловий. Процесс повторяется заново с новым случайным множеством значений для ранее инвертированных переменных. Он довольно быстрый, но не точный.
Он довольно быстрый, но не точный.- Лас-Вегас — как и предыдущий, рандомизированный алгоритм, однако он прекращает свою работу лишь в том случае, если найден верный результат. Таким образом, алгоритм всегда точный, но зачастую медленный.
// алгоритм Лас-Вегас
repeat:
k = RandInt(n)
if A[k] == 1,
return k;
- Атлантик Сити — ограниченный вероятностный алгоритм поиска с полиномиальным временем работы. Он объединяет в себе сильные и слабые стороны алгоритмов Монте-Карло и Лас-Вегас.
Перевод статьи Aaron (Ari) Bornstein: AI Search Algorithms Every Data Scientist Should Know
6 алгоритмов, которые должен знать каждый разработчик
Я разработчик, и вы должны знать, что я не большой фанат структур данных и алгоритмов. Если вы такой же, не переживайте, после работы над многими проектами (маленькими и большими) я обнаружил шесть важных алгоритмов, которые должен знать каждый разработчик, и эти шесть почти всегда решат любую проблему в вашей разработке.
Что это за 6 значимых алгоритмов?
1. Алгоритмы сортировки
Что такое сортировка? Это алгоритм, который упорядочивает элементы в списке.
Важные алгоритмы сортировки:
- Пузырьковая сортировка. Пузырьковая сортировка — это самый простой алгоритм сортировки, который работает путем многократной замены соседних элементов, если они не следуют в порядке.
- Сортировка слиянием. Сортировка слиянием — это метод сортировки, использующий стратегию «разделяй и властвуй».
- Быстрая сортировка. Быстрая сортировка — это популярный алгоритм сортировки, который в среднем выполняет n log n сравнений при сортировке массива из n элементов. Это более эффективный и быстрый алгоритм сортировки.
- Сортировка кучей. Сортировка кучей работает путем визуализации элементов массива как особого типа полного двоичного дерева, известного как куча.
2. Алгоритмы поиска
Что такое поиск? Это алгоритм, который находит элемент в наборе данных.
Важные алгоритмы поиска:
- Двоичный поиск. Двоичный поиск использует стратегию «разделяй и властвуй», в которой отсортированный список делится на две половины, а элемент сравнивается со средним элементом списка. Если совпадение найдено, возвращается местоположение среднего элемента.
- Поиск в ширину (Breadth-First Search, BFS). Поиск в ширину — это алгоритм обхода графа, который начинается с корневого узла и исследует все соседние узлы.
- Поиск в глубину (Depth-First Search, DFS). Алгоритм поиска в глубину начинается с первого узла графа и продолжает идти все глубже и глубже, пока мы не найдем целевой узел или узел без дочерних элементов.
3. Динамическое программирование
Динамическое программирование — это алгоритмический метод решения задачи оптимизации путем разбиения ее на более простые подзадачи и использования того факта, что оптимальное решение общей проблемы зависит от оптимального решения ее подзадач.
4. Алгоритм рекурсии
Рекурсия — это метод решения проблем, при котором решение зависит от решений более мелких экземпляров одной и той же проблемы. Вычисление факториалов — классический пример рекурсивного программирования.
Каждая рекурсивная программа следует одной и той же базовой последовательности шагов:
- Создайте алгоритм. Для старта рекурсивным программам обычно требуется начальное значение. Это достигается либо с помощью параметра, переданного в функцию, либо путем предоставления нерекурсивной функции шлюза, которая устанавливает начальные значения для рекурсивного вычисления.
- Проверьте, соответствуют ли текущие обрабатываемые значения нужному варианту. Если это так, обработайте значение и верните его.
- Перефразируйте решение с точки зрения меньшей или более простой подзадачи или подзадач.
- Примените алгоритм к подзадаче.
- Чтобы сформулировать ответ, объедините результаты.
- Верните результаты.

5. Разделяй и властвуй
Алгоритм «разделяй и властвуй» (Divide and Conquer) рекурсивно делит проблему на две или более подзадачи того же или связанного типа, пока они не станут достаточно простыми для элементарного решения.
Алгоритм «разделяй и властвуй» состоит из вычислений с использованием трех шагов, перечисленных ниже.
- Divide. Разделите исходную проблему на подзадачи.
- Conquer. Рекурсивно решайте каждую подзадачу по одной за раз.
- Объедините. Соедините решения подзадач, чтобы получить решение всей проблемы.
6. Хеширование
Хеширование — это метод или процесс, использующий хеш-функцию для отображения ключей и значений произвольной длины в строках заданного размера. Это сделано для более быстрого доступа к элементам. Эффективность отображения определяется эффективностью хеш-функции.
Вывод
Имея так много доступных алгоритмов различной сложности, трудно определить, какие из них действительно важны для понимания. Это часто сводится к личным предпочтениям и точке зрения, но в этой статье мы выделили некоторые алгоритмы, о которых должны знать все разработчики.
Это часто сводится к личным предпочтениям и точке зрения, но в этой статье мы выделили некоторые алгоритмы, о которых должны знать все разработчики.
Если вы нашли опечатку — выделите ее и нажмите Ctrl + Enter! Для связи с нами вы можете использовать [email protected].
Что такое алгоритм поиска?
Вернуться к блогу
16 октября 2018 г.
Алгоритм поиска — это уникальная формула, которую поисковая система использует для извлечения определенной информации, хранящейся в структуре данных, и определения значимости веб-страницы и ее содержимого. Алгоритмы поиска уникальны для их поисковой системы и определяют ранжирование веб-страниц в результатах поиска.
Общие типы алгоритмов поиска
Поисковые системы используют специальные алгоритмы, основанные на размере и структуре их данных, для получения возвращаемого значения.
Алгоритм линейного поиска
Алгоритмы линейного поиска считаются самыми основными из всех алгоритмов поиска, поскольку для их реализации требуется минимальный объем кода.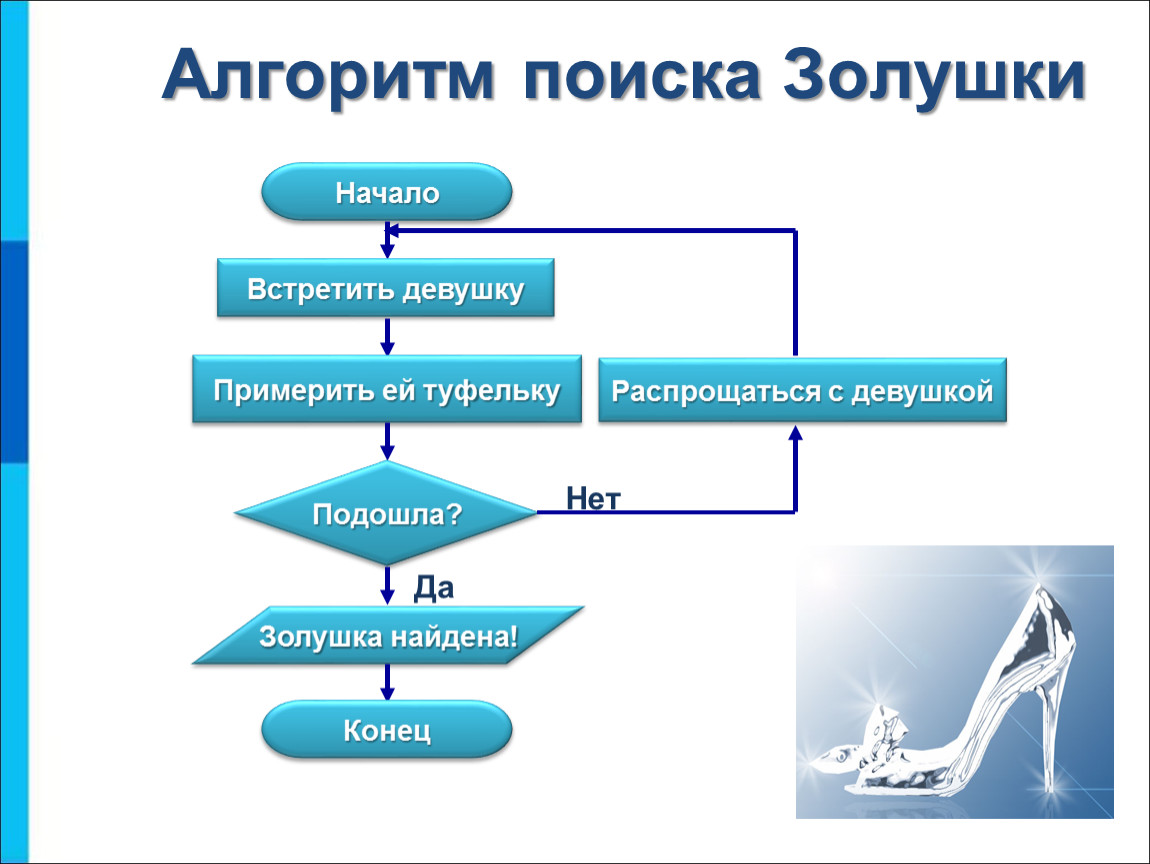 Алгоритмы линейного поиска, также известные как последовательный поиск, представляют собой простейшую формулу для алгоритмов поиска. Алгоритмы линейного поиска лучше всего подходят для коротких списков, которые неупорядочены и не отсортированы. Чтобы найти то, что ищется, алгоритм просматривает элементы в виде списка. Как только он доберется до искомого элемента, поиск будет завершен. Линейный поиск не является распространенным способом поиска, поскольку это довольно неэффективный алгоритм по сравнению с другими доступными алгоритмами поиска.
Алгоритмы линейного поиска, также известные как последовательный поиск, представляют собой простейшую формулу для алгоритмов поиска. Алгоритмы линейного поиска лучше всего подходят для коротких списков, которые неупорядочены и не отсортированы. Чтобы найти то, что ищется, алгоритм просматривает элементы в виде списка. Как только он доберется до искомого элемента, поиск будет завершен. Линейный поиск не является распространенным способом поиска, поскольку это довольно неэффективный алгоритм по сравнению с другими доступными алгоритмами поиска.
Простой пример алгоритма линейного поиска:
Допустим, вы встречаетесь со своей подругой Стефани сегодня вечером в кино на премьере нового фильма. Она предлагает купить билет и подождать в очереди, пока в театре не будет свободных мест. Как только вы приходите в театр, вы замечаете, что очередь длинная, и вы понятия не имеете, где находится ваш друг в очереди. Тем не менее, вы знаете, как выглядит Стефани, поэтому по пути вы начинаете с конца очереди и сканируете лицо каждого человека в поисках своей подруги. Как только вы найдете ее, вы встанете в очередь рядом с ней. Вы только что следовали алгоритму линейного поиска. Очередь длинная, а люди беспорядочные, поэтому лучший способ найти того, кого вы ищете, — это просканировать очередь от одного конца до другого.
Как только вы найдете ее, вы встанете в очередь рядом с ней. Вы только что следовали алгоритму линейного поиска. Очередь длинная, а люди беспорядочные, поэтому лучший способ найти того, кого вы ищете, — это просканировать очередь от одного конца до другого.
Алгоритм бинарного поиска
Алгоритм бинарного поиска, в отличие от алгоритмов линейного поиска, использует упорядочение списка. Этот алгоритм является лучшим выбором, когда в алисте есть термины, расположенные в порядке возрастания размера. Алгоритм начинается с середины списка. Если цель ниже средней точки, то она исключает верхнюю половину списка; если цель выше средней точки, то вырезается нижняя половина списка. Для больших баз данных алгоритмы бинарного поиска будут давать гораздо более быстрые результаты, чем алгоритмы линейного поиска.
Двоичный поиск использует цикл или рекурсию, чтобы разделить область поиска пополам после выполнения сравнения.
Алгоритмы бинарного поиска состоят из трех основных разделов, чтобы определить, какую половину списков следует исключить и как просмотреть оставшуюся часть списка. Предварительная обработка отсортирует коллекцию, если она еще не упорядочена. Двоичный поиск использует цикл или рекурсию, чтобы разделить область поиска пополам после выполнения сравнения. Постобработка определяет, какие переменные-кандидаты остаются в пространстве поиска.
Предварительная обработка отсортирует коллекцию, если она еще не упорядочена. Двоичный поиск использует цикл или рекурсию, чтобы разделить область поиска пополам после выполнения сравнения. Постобработка определяет, какие переменные-кандидаты остаются в пространстве поиска.
Простой пример алгоритма бинарного поиска:
Вы ищете свой любимый синий свитер в гардеробной. Вы согласовали цвет своей одежды справа налево на основе стандартной теории цвета ROYGBIV. Вы открываете дверь и идете прямо в середину вашего шкафа, где находится ваша зеленая одежда, и вы автоматически отбрасываете первую половину вариантов, так как они не близки к тем вариантам цвета, которые вы ищете. Как только вы исключили половину своих вариантов, вы понимаете, что ваш выбор синей одежды велик и составляет большую часть второй половины вариантов одежды, поэтому вы переходите к середине раздела синего / индиго. Вы можете исключить индиго и фиолетовые цвета. Оттуда все, что у вас осталось, это зеленый и синий, и вы можете выбрать свой любимый синий свитер из оставшейся одежды. Сократив количество вариантов одежды вдвое, вы сможете вдвое сократить время поиска, чтобы сузить свой выбор до любимого синего свитера.
Оттуда все, что у вас осталось, это зеленый и синий, и вы можете выбрать свой любимый синий свитер из оставшейся одежды. Сократив количество вариантов одежды вдвое, вы сможете вдвое сократить время поиска, чтобы сузить свой выбор до любимого синего свитера.
Как поисковые алгоритмы влияют на поисковую оптимизацию
Алгоритмы поиска помогают определить рейтинг веб-страницы в конце поиска, когда отображаются результаты.
Каждая поисковая система использует определенный набор правил, чтобы помочь определить, является ли веб-страница реальной или спамом, и будут ли содержимое и данные на странице представлять интерес для пользователя. Результаты этого процесса в конечном итоге определяют рейтинг сайта на странице результатов поисковой системы.
Несмотря на то, что каждый набор правил и формул алгоритма различается, поисковые системы используют релевантность, индивидуальные факторы и факторы вне страницы для определения рейтинга страницы в результатах поиска.
Актуальность
Поисковые системы выполняют поиск по содержимому веб-страницы и тексту в поисках ключевых слов и их местонахождения на веб-сайте. Если ключевые слова встречаются в заголовке страницы, заголовке и первых нескольких предложениях на странице сайта, то эта страница будет ранжироваться по этому ключевому слову лучше, чем другие сайты. Поисковые системы могут сканировать, чтобы увидеть, как ключевые слова используются в тексте страницы, и определить, соответствует ли страница тому, что вы ищете. Частота ключевых слов, которые вы ищете, повлияет на релевантность сайта. Если ключевые слова вставлены в текст сайта и он не течет естественным образом, поисковые системы пометят это как наполнение ключевыми словами. Наполнение ключевыми словами снижает релевантность сайта и ухудшает рейтинг страницы в результатах поиска.
Индивидуальные факторы
Поскольку алгоритмы поиска специфичны для поисковых систем, индивидуальные факторы исходят из способности каждой поисковой системы использовать собственный набор правил для применения алгоритма поиска. Поисковые системы имеют разные наборы правил для того, как они ищут и сканируют сайты; за добавление штрафа сайтам за спам ключевых слов; и сколько сайтов они индексируют. В результате, если вы выполните поиск «домашнего декора» в Google, а затем снова в Bing, вы увидите две разные страницы результатов. Google индексирует больше страниц, чем Bing, и чаще, и в результате показывает другой набор результатов для поисковых запросов.
Поисковые системы имеют разные наборы правил для того, как они ищут и сканируют сайты; за добавление штрафа сайтам за спам ключевых слов; и сколько сайтов они индексируют. В результате, если вы выполните поиск «домашнего декора» в Google, а затем снова в Bing, вы увидите две разные страницы результатов. Google индексирует больше страниц, чем Bing, и чаще, и в результате показывает другой набор результатов для поисковых запросов.
Факторы вне страницы
Внешние факторы, которые помогают поисковым системам определять рейтинг страницы, включают в себя такие вещи, как гиперссылки и измерение кликов. Измерения количества кликов могут помочь поисковой системе определить, сколько людей посещают сайт, сразу ли они покидают сайт, сколько времени они проводят на сайте и что ищут. Плохие факторы вне страницы могут снизить релевантность сайта и рейтинг SEO, поэтому важно учитывать эти элементы и работать над их улучшением, если это необходимо.
Как только вы лучше поймете, как работают поисковые алгоритмы, их роль в поисковой оптимизации и рейтинге сайта, вы сможете внести необходимые изменения в сайт, чтобы улучшить его рейтинг. В Volusion наша команда специалистов по поисковой оптимизации (SEO) может помочь вам внести коррективы и настроить ваш сайт так, чтобы он был должным образом оптимизирован для поисковых систем. Свяжитесь с нами сегодня, и мы поможем вам начать SEO-продвижение ваших сайтов!
В Volusion наша команда специалистов по поисковой оптимизации (SEO) может помочь вам внести коррективы и настроить ваш сайт так, чтобы он был должным образом оптимизирован для поисковых систем. Свяжитесь с нами сегодня, и мы поможем вам начать SEO-продвижение ваших сайтов!
Готовы вывести оптимизацию электронной коммерции на новый уровень? Узнайте, как Volusion может помочь вам увеличить посещаемость и продажи вашего магазина!
Похожие темы
SEO
Будьте в курсе
Подпишитесь на информационный бюллетень Volusion
Получите больше отраслевых идей, советов и эксклюзивных предложений, отправленных прямо на ваш почтовый ящик.
При подписке произошла ошибка. Попробуйте обновить страницу и отправить еще раз.
Спасибо за подписку!
Все, что вам нужно знать
Часто я концентрируюсь на определенных стратегиях для выполнения определенных функций.
Как написать привлекательный текст, чтобы занять место в голосовом поиске?
Какие структурированные данные позволяют легко выигрывать?
Такие вещи.
Эти важные вопросы часто освещаются здесь, в Search Engine Journal, в очень полезных статьях.
Но важно не только понимать, какие тактики могут помочь вам в рейтинге. Вы должны понять как это работает.
Понимание структуры, в которой функционирует стратегия, имеет первостепенное значение для понимания не только того, почему эта стратегия работает, но и того, как и чего она пытается достичь.
Ранее мы обсуждали, как поисковые системы сканируют и индексируют информацию.
В этой главе рассматриваются основы работы алгоритмов поиска.
Что такое алгоритм? Рецепт
Если вы спросите Google, что такое алгоритм, вы обнаружите, что сам движок (и почти все остальные) определяет его как «процесс или набор правил, которым необходимо следовать при вычислениях или других операциях по решению проблем».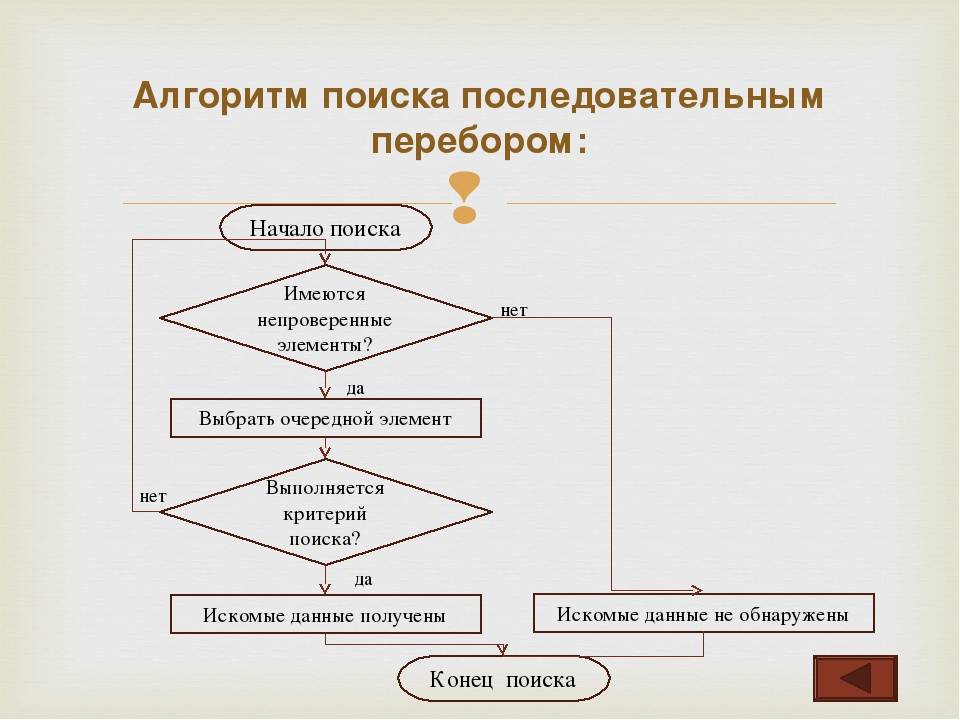 , особенно с помощью компьютера».
, особенно с помощью компьютера».
Если вы берете что-то из этого определения, очень важно понять, чем оно не является в нашем контексте.
Алгоритм — это , а не формула.
Чтобы осознать разницу, почему она важна и что делает каждый из них, давайте на минутку задумаемся о еде, которую я мог бы положить на свою обеденную тарелку сегодня вечером.
Возьмем мое любимое блюдо:
- Ростбиф
- Хрен
- Йоркширский пудинг
- Зеленая фасоль
- Картофельное пюре
- Соус
(Правильно, мы, канадцы, едим больше, чем путин и кленовый сироп, хотя и то, и другое прекрасно, хотя, возможно, и не вместе.)
Ростбиф должен быть приправлен и идеально приготовлен.
Приправа в сочетании с жареным мясом может служить примером формулы – сколько каждого ингредиента необходимо для производства продукта.
Второй используемой формулой будет количество времени и температура, в течение которой должно быть приготовлено жаркое, учитывая его вес. То же самое будет происходить для каждого элемента в списке.
То же самое будет происходить для каждого элемента в списке.
На самом базовом уровне у нас было бы 12 формул (6 элементов x 2 — одна для измерений, а другая для времени и продолжительности приготовления в зависимости от объема), составляющих алгоритм, заданный для создания одного из любимых блюд Дейва.
Мы даже не включаем различные формулы и алгоритмы, необходимые для производства самих ингредиентов, таких как разведение коровы или выращивание картофеля.
Давайте добавим еще одну формулу — формулу для расчета количества различных продуктов, которые я хотел бы иметь на своей тарелке.
Итак, теперь у нас есть алгоритм для выполнения этой очень важной задачи. Фантастика!
Теперь нам просто нужно персонализировать этот алгоритм, чтобы остальная часть моей семьи тоже наслаждалась едой.
Мы должны учитывать, что каждый человек индивидуален и может хотеть разное количество каждого ингредиента и разные приправы.
Итак, добавляем формулу для каждого человека. Хорошо.
Хорошо.
Алгоритм алгоритмов
Что, черт возьми, общего у алгоритма поиска и обеденного стола?
Гораздо больше, чем вы думаете.
Давайте посмотрим на несколько основных характеристик веб-сайта для сравнения. («Немногие» означает далеко не все. Например, даже не близко.)
- URL-адреса
- Содержание
- Внутренние ссылки
- Внешние ссылки
- Изображения
- Скорость
Как мы видели с нашим алгоритмом обеда, каждая из этих областей далее делится с использованием разных формул и, по сути, разных подалгоритмов.
Было бы лучше, если бы мы думали об этом не как алгоритм , а как алгоритмов .
Также важно иметь в виду, что, несмотря на множество алгоритмов и бесчисленное количество формул, существует еще и алгоритм.
Его работа заключается в том, чтобы определить, как эти другие взвешиваются для получения окончательных результатов, которые мы видим в поисковой выдаче.
Таким образом, совершенно законно признать, что наверху существует какой-то тип алгоритма — так сказать, единый алгоритм, управляющий всеми — но всегда признают, что существует бесчисленное множество других алгоритмов, и обычно это те алгоритмы, о которых мы думаем, когда рассматриваем их влияние на результаты поиска.
Теперь вернемся к нашей аналогии.
У нас есть множество различных характеристик оцениваемого веб-сайта, так же как у нас есть ряд продуктов питания, которые должны оказаться на нашей обеденной тарелке.
Чтобы получить желаемый результат, мы должны иметь большое количество формул и подалгоритмов для создания каждого элемента на пластине и мастер-алгоритм для определения количества и размещения каждого элемента.
Знакомо?
Когда мы думаем об «алгоритме Google», на самом деле мы имеем в виду огромный набор алгоритмов и формул, каждый из которых предназначен для выполнения одной конкретной функции и собран вместе с помощью ведущего или, осмелюсь сказать, «ядра». Алгоритм размещения результатов.
Алгоритм размещения результатов.
Итак, у нас есть:
- Алгоритмы вроде Panda, помогающие Google оценивать, фильтровать, наказывать и награждать контент на основе определенных характеристик, и этот алгоритм, вероятно, включает в себя множество других алгоритмов.0134
- Алгоритм Penguin для оценки ссылок и устранения там спама. Но этот алгоритм, безусловно, требует данных от других ранее существовавших алгоритмов, которые отвечают за оценку ссылок, и, вероятно, некоторых новых алгоритмов, которым поручено понять общие характеристики ссылочного спама, чтобы более крупный алгоритм Penguin мог выполнять свою работу.
- Алгоритмы для конкретных задач.
- Алгоритмы организации.
- Алгоритмы, отвечающие за сбор всех данных и размещение их в контексте, который дает желаемый результат, поисковую выдачу, которую пользователи сочтут полезной.
Вот и все. Так работают алгоритмы поиска.
Почему алгоритмы поиска используют сущности
Одной из областей поиска, которая в последнее время привлекает достаточное внимание, хотя и недооценивается, является идея сущностей.
Для контекста объект определяется Google как:
«Вещь или концепция, которая является единственной, уникальной, четко определенной и различимой».
Итак, в нашей аналогии с обедом есть я. Я сущность.
Каждый член моей семьи тоже самодостаточен. На самом деле, моя семейная ячейка представляет собой самостоятельную сущность.
Таким образом, жаркое и каждый ингредиент, входящий в него, также являются самостоятельными сущностями.
Как и йоркширский пудинг, как и мука, которая пошла на его приготовление.
Google видит мир как совокупность сущностей. И вот почему:
За обеденным столом у меня четыре отдельных сущности, у которых будет состояние «еда» и множество потребляемых сущностей.
Такая классификация всех нас имеет много преимуществ для Google по сравнению с простой оценкой нашей деятельности как набора слов.
Каждое едящее существо теперь может назначать ему то, что находится на его тарелке (ростбиф, хрен, стручковая фасоль, картофельное пюре, йоркширский пудинг, но не соус для существа xyz1234567890).
Google использует этот тип классификации для оценки веб-сайта.
Думайте о каждой сущности, сидящей за столом, как о странице.
Глобальная сущность, которая представляет всех нас (давайте назовем эту сущность «Дэвис»), будет посвящена «ужину с ростбифом», но каждая отдельная сущность, представляющая отдельного человека (или страницу в нашей аналогии), отличается.
Таким образом, Google может легко классифицировать и оценивать взаимосвязь веб-сайтов и мира в целом.
По сути, поисковые системы не обязаны оценивать только один веб-сайт — они должны ранжировать их все.
Сущность «Дэвис» говорит об «ужине с ростбифом», но сущность по соседству (назовем эту сущность «Робинсоны») говорит о «жарком».
Теперь, если внешнее лицо, известное как «Халявщик», хочет определить, где поесть, варианты могут быть оценены как «Халявщик» на основе его предпочтений или запроса.
В чем (на мой взгляд) реальная ценность сущностей заключается в том, что происходит на следующий день.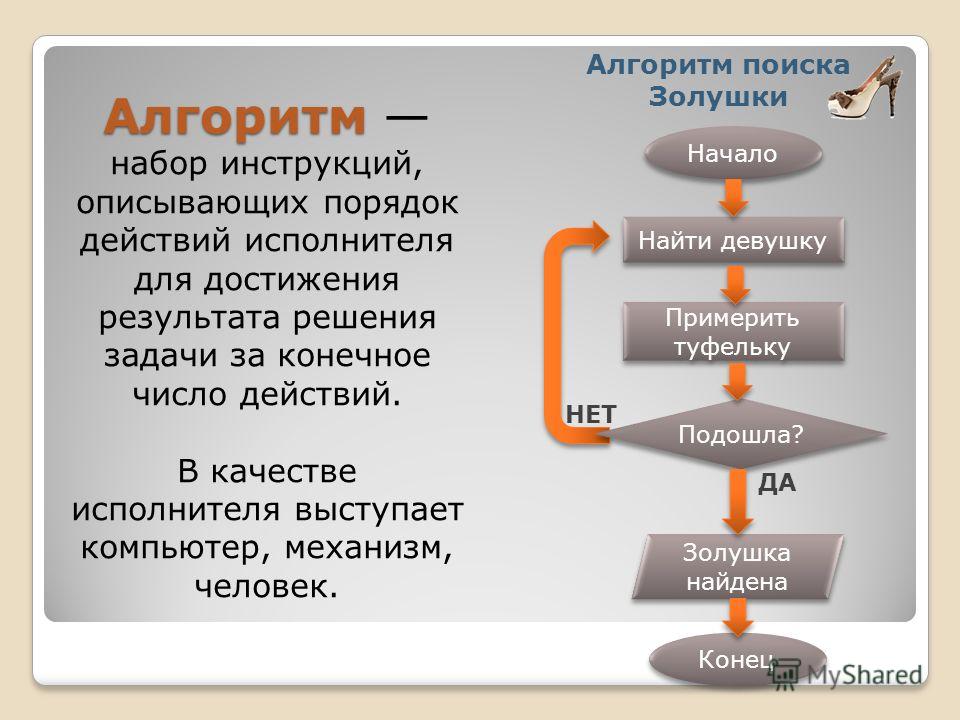 У нас есть остатки.
У нас есть остатки.
Путем обработки сущности «ростбиф» с использованием другой формулы и добавления сущностей хлеб, сыр и лук мы имеем:
Как алгоритмы поиска используют сущности
Хорошо, может показаться неочевидным, насколько это важно для понимания алгоритмов поиска и того, как сущности работают таким образом.
Понимая, какую очевидную ценность имеет видение Google содержания веб-сайта в целом, вы можете спросить, почему для Google важно понимать, что мой ростбиф и соус из говядины связаны между собой и фактически взяты из одной и той же основной сущности. .
Вместо этого давайте рассмотрим, как Google понимает, что веб-страница посвящена ростбифу. Давайте также рассмотрим, что на него ссылается другая страница, и эта страница посвящена соусу из говядины.
В этом сценарии невероятно важно, чтобы Google знал, что ростбиф и соус из говядины готовятся из одной и той же основной сущности.
Они могут назначить релевантность этой ссылке на основе связности этих объектов.
До того, как идея сущностей вошла в поиск, поисковым системам приходилось присваивать релевантность на основе близости слов, плотности и других элементов, которые легко неверно интерпретировать и которыми легко манипулировать.
Сущностями гораздо труднее манипулировать.
Либо страница посвящена объекту, либо нет.
Просматривая веб-страницы и отображая распространенные способы связи сущностей, поисковые системы могут предсказать, какие отношения должны иметь наибольший вес.
Итак, как работают алгоритмы поиска?
Итак, мы многое рассмотрели, и вы, вероятно, проголодались. Вы хотите, чтобы некоторые вынос.
Контекст имеет значение
Важно понимать, как работают алгоритмы, чтобы применять контекст к тому, что вы испытываете/читаете.
Когда вы слышите об обновлении алгоритма, важно знать, что то, что обновляется, скорее всего, является маленьким кусочком очень большой головоломки.
Знание этого помогает интерпретировать, какие аспекты сайта или мира корректируются в обновлении и как эта корректировка вписывается в общую задачу движка.
Сущности очень важны
Кроме того, очень важно понимать, что сущности:
- Сегодня играют огромную роль в поисковых алгоритмах.
- Имеют собственные алгоритмы.
- Со временем будет играть все более важную роль.
Знание этого поможет вам понять не только, какой контент является ценным (насколько близки те объекты, о которых вы пишете?), но и какие ссылки, скорее всего, будут оценены более благоприятно.
И это только пара преимуществ.
Все зависит от намерения пользователя
Алгоритмы поиска работают как большой набор других алгоритмов и формул, каждая из которых имеет свою цель и задачу для получения результатов, которыми удовлетворится пользователь.
На самом деле, существуют алгоритмы для отслеживания именно этого аспекта результатов и внесения корректировок, когда считается, что рейтинговые страницы не удовлетворяют намерения пользователя, исходя из того, как пользователи взаимодействуют с ними.