Содержание
Как включить мониторинг доступности сайта в Яндекс.Метрике
6702
| How-to | – Читать 3 минуты |
Прочитать позже
ЧЕК-ЛИСТ: МОНИТОРИНГ
Инструкцию одобрил SEO Classifieds Specialist в Netpeak
Ирина Цымбал
Оповещение о недоступности сайта используется, чтобы автоматически приостановить действующие рекламные кампании в Яндекс.Директе. Настроить уведомления можно в Яндекс.Метрике.
Мониторинг доступности в Яндексе
Проблемы с сайтом могут возникнуть в любой момент, поэтому подобный функционал Яндекс.Метрики поможет не потерять деньги на рекламу.
Если вы не воспользуетесь инструментом Мониторинг доступности в период перегрузки сервера или при других ошибках на сервере, то пользователи будут продолжать получать платные объявления из контекстной рекламы. Совершая переходы на ваш сайт, они будут покидать его, так как ничего не увидят, кроме окна ошибки. Ваш бюджет будет тратиться впустую.
Ваш бюджет будет тратиться впустую.
Алгоритм инструмента состоит в том, что Яндекс отслеживает посещения сайта и когда возникают сильные колебания, он запрашивает главную страницу. Если корректный код 200 ОК не получен, вам приходит об этом уведомление.
Важно! Уведомление о недоступности сайта работает правильно только при условии более 100 посещений в неделю, иначе алгоритм не будет корректен.
Перейдите в Яндекс.Метрику:
Теперь нажимаем на шестеренку, которая расположена в правом углу счетчика:
Попадете в окно настроек счетчика, где нужен раздел Уведомления:
Теперь настройте получение уведомления. Установите удобное время, когда вы согласны получать оповещение и способ: почта или телефон.
Спустя время у вас появится новый отчет, который будет вести журнал результатов проверок. Учтите, что некоторые файлы robots.txt могут не разрешать обращаться к серверу сайта незнакомым user agent. Тогда возможно ложное срабатывание уведомления. Мониторинг осуществляет робот с именем:
Тогда возможно ложное срабатывание уведомления. Мониторинг осуществляет робот с именем:
Поэтому во избежание ложных срабатываний,отредактируйте директивы в файле robots.txt.
Результаты мониторинга недоступности
Яндекс учитывает в отчете периодичность доступности либо недоступности сайта. Это так называемый uptime, который означает процент времени, когда сайт был доступен, а код ответа сервера корректен. Таблицу ошибок посмотрите в технической поддержке:
Заключение
Система может автоматически прекратить показы Директа пользователям до восстановления работы сайта, чтобы не потратить впустую бюджет рекламной компании. Мониторинг доступности сайта можно включить через Яндекс.Метрику.
Для этого перейдите в панель счетчика, выберите настройки и раздел уведомлений. В данном разделе — выберите удобный способ получения уведомления: почта или телефон. Яндекс будет периодически запрашивать главную страницу сайта, если заметит аномальные для его статистики изменения.
Препятствием для корректной работы счетчика может стать:
- посещаемость ниже 100 пользователей в неделю;
- директива в файле robots.txt, которая запрещает обращение к серверу.
«Список задач» — готовый to-do лист, который поможет вести учет
о выполнении работ по конкретному проекту. Инструмент содержит готовые шаблоны с обширным списком параметров по развитию проекта, к которым также можно добавлять собственные пункты.
Начать работу со «Списком задач»
Сэкономьте время на изучении Serpstat
Хотите получить персональную демонстрацию сервиса, тестовый период или эффективные кейсы использования Serpstat?
Оставьте заявку и мы свяжемся с вами 😉
Оцените статью по 5-бальной шкале
5 из 5 на основе 3 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
How-to
Denys Kondak
Как добавить сайт в сервис мониторинга доступности — сравнение бесплатных систем
How-to
Denys Kondak
Как добавить сайт в Веб-мастер Bing
How-to
Denys Kondak
Как удалить пустые страницы на сайте
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Настройка отложенных уведомлений в Zabbix
Home » Мониторинг » Zabbix » Настройка отложенных уведомлений в Zabbix
Zerox
Обновлено: 21.01.2019
Zabbix
19 комментариев
9,678 Просмотры
Небольшая заметка по функционалу заббикса, который может быть кому-то вообще не знаком. Речь пойдет об отложенных уведомлениях (оповещениях) в системе мониторинга zabbix. Например, если вы отложили отправку сообщения на 5 минут, а триггер сработал и завершился за 3 минуты, вы об этом не получите уведомления, но информация о событии останется в системе.
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужно пройти вступительный тест.
Курс не для новичков, для поступления нужно пройти вступительный тест.
Содержание:
- 1 Введение
- 2 Отложенное оповещение
- 3 Проверка отложенных уведомлений
- 4 Заключение
Введение
Косвенно данную тему я затрагивал в статье про повторяющиеся уведомления в zabbix. Основа для настроек одна и та же. Очень подробно этот вопрос освещен в официальной документации, в разделе Эскалации. Рекомендую ознакомиться, там все показано на примерах.
Я же кратко на своем примере покажу, как отложить отправку оповещения на 5 минут. Иногда надоедают какие-то триггеры, приходится их отключать, чтобы не спамили. Но если триггер отключить, то информации по нему не будет вообще никакой. Чаще всего хочется отключить именно уведомление, а не сам триггер. В таком случае, информация о его срабатывании сохранится в истории системы мониторинга.
Одни из вариантов решения этой проблемы — добавление исключения в дефолтное правило оповещений, которое чаще всего остается после настройки.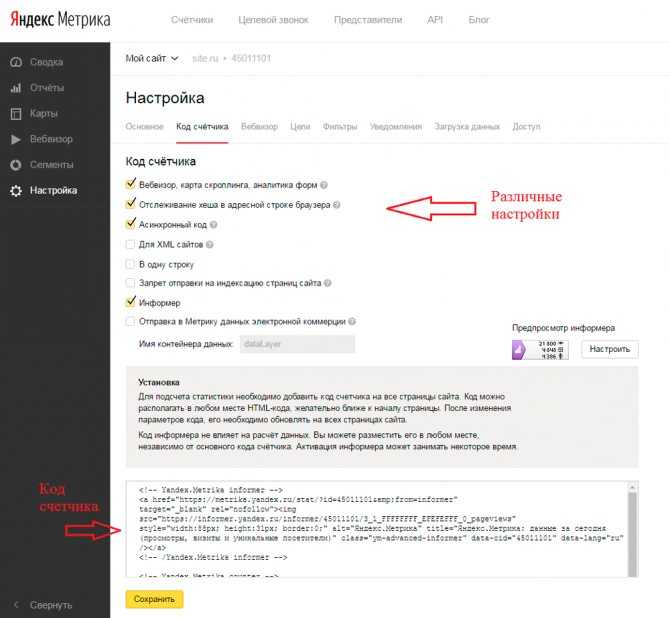 То есть можно сделать вот так:
То есть можно сделать вот так:
Оповещения о триггерах с указанными названиями отправляться не будут. Я просто привел пример одного из подходов. Дальше расскажу, как сделать так, чтобы если триггер сработал и завершился в течении 5 минут, оповещение о нем не придет. Если же за 5 минут триггер не выключится, то оповещение будет отправлено.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
Отложенное оповещение
Для настройки отложенного оповещения идем в web интерфейс zabbix сервера, в раздел Configuration -> Actions и выбираем правило оповещения, которое будем изменять. Я для примера возьму дефолтное правило Report problems to Zabbix administrators.
Я для примера возьму дефолтное правило Report problems to Zabbix administrators.
Идем во вкладку Operations и меняем Default operation step duration на 5m, если вы хотите отложить отправку оповещения на 5 минут. Далее редактируем шаг исполнения. В разделе Steps ставим значения 2 — 2. Изначально там стоит 1 — 1. То есть мы указываем, выполнить отправление со второго шага, а длину шага ранее установили в 5 минут.
Вот и все. Я показал на простом примере, как отложить отправку оповещения о событии в zabbix.
Проверка отложенных уведомлений
Для проверки отложенного уведомления, достаточно дождаться срабатывания какого-нибудь триггера. Вот мои примеры, когда оповещение не было отправлено вовсе, так как триггер работал менее 5 минут. И рядом же пример отправки уведомления только через 5 минут после срабатывания триггера.
Последнее событие длилось 1 минуту. Во время бэкапа сайта сработал триггер на нехватку места. После завершения бэкапа, скрипт подчистил за собой следы и места стало достаточно. Все случилось в течении 1 минуты, так что оповещения я вообще не получил.
Все случилось в течении 1 минуты, так что оповещения я вообще не получил.
Второе событие длилось 6 минут. Оповещение было отправлено только через 5 минут после срабатывания триггера.
Заключение
Таким нехитрым способом вы можете контроллировать количество оповещений от системы мониторинга. Чем их меньше, тем лучше. Оставлять нужно только то, что действительно критично и требует внимания. Спам бесполезных оповещений снижает бдительность и приводит к тому, что на оповещения просто перестают реагировать. Это неправильно, не нужно доводить до такого состояния. Калибровка системы мониторинга, чтобы она стала помощником, требует постоянных усилий и внимания. Но без нее никуда.
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите подробнее программу по ссылке.
Помогла статья? Подписывайся на telegram канал автора
Анонсы всех статей, плюс много другой полезной и интересной информации, которая не попадает на сайт.
Скачать pdf
Tags zabbix мониторинг
Автор Zerox
Владимир, системный администратор, автор сайта.
Люблю настраивать сервера, изучать что-то новое, делиться знаниями, писать интересные и полезные статьи.
Открыт к диалогу и сотрудничеству. Если вам интересно узнать обо мне побольше, то можете послушать интервью. Запись на моем канале — https://t.me/srv_admin/425 или на сайте в контактах.
Предыдущая IT аудит информационной системы
Следующая Монетизация ИТ блога, сколько можно заработать на информационном сайте
Управление метриками и уведомлениями об инцидентах
Управление метриками и уведомлениями об инцидентах
Предыдущий
Следующий
Для корректного отображения этого контента должен быть включен JavaScript
 org/» typeof=»BreadcrumbList»>
org/» typeof=»BreadcrumbList»>Вы можете выполнять следующие задачи для управления мониторингом и уведомлением об инцидентах:
Просмотр ошибок сбора метрик
Редактирование параметров метрики и коллекции
Редактирование конфигурации мониторинга
Приостановка уведомлений мониторинга
Приостановка мониторинга для обслуживания
Завершение отключения или отключения мониторинга
Просмотр ошибок сбора метрик
Ошибки сбора метрик обычно возникают из-за проблем с установкой или конфигурацией. Вы можете просмотреть ошибки для сервера.
Вы можете просмотреть ошибки для сервера.
- Щелкните Сервер системной инфраструктуры на странице Все цели.
- Щелкните имя цели, чтобы открыть домашнюю страницу.
- Щелкните Сервер системной инфраструктуры в верхнем левом углу страницы. Нажмите «Мониторинг», затем нажмите «Ошибки сбора метрик».
Редактирование настроек метрик и коллекций
На вкладке «Метрики» отображаются все отслеживаемые атрибуты. Представление по умолчанию — это метрики с пороговыми значениями. Для этих типов отслеживаемых атрибутов можно изменить оператор сравнения, пороговые значения, корректирующее действие и расписание сбора.
- Щелкните Сервер системной инфраструктуры на странице Все цели.
- Щелкните имя цели, чтобы открыть домашнюю страницу.
- Щелкните Сервер системной инфраструктуры в верхнем левом углу страницы. Нажмите «Мониторинг», затем нажмите «Настройки показателей и сбора».

- Изменить пороговые значения или расписание сбора. Если поле порога пусто, предупреждение для этой метрики отключено.
- Нажмите значок «Изменить», чтобы открыть дополнительные настройки.
Перейдите на вкладку Другие собранные элементы, чтобы просмотреть отслеживаемые атрибуты без порога. Вы можете изменить период сбора данных для этих атрибутов или отключить мониторинг.
- Нажмите OK, чтобы сохранить изменения.

Редактирование конфигурации мониторинга
- Щелкните Сервер инфраструктуры системы на странице Все цели.
- Щелкните имя цели, чтобы открыть домашнюю страницу.
- Щелкните Сервер системной инфраструктуры в верхнем левом углу страницы. Щелкните Настройка цели.
- Щелкните Конфигурация мониторинга.

Приостановка уведомлений мониторинга
Отключение позволяет временно подавлять уведомления для цели. Агент продолжает следить за целью, находящейся под отключением. Вы можете просмотреть фактическое состояние цели вместе с индикацией того, что цель в настоящее время находится в режиме понижения напряжения.
Вы можете отключить сервер.
- Щелкните Сервер системной инфраструктуры на странице Все цели.
- Щелкните имя цели, чтобы открыть домашнюю страницу.
- Щелкните Сервер системной инфраструктуры в верхнем левом углу страницы. Щелкните Управление.
- Нажмите «Создать затемнение».
- Введите имя для события понижения напряжения.
- Выберите причину из меню и при необходимости добавьте комментарии.
- Выберите параметры, чтобы определить, как будут выполняться задания и период обслуживания.
- Нажмите «Отправить».
Приостановка мониторинга для обслуживания
Отключения позволяют приостановить мониторинг одной или нескольких целей для выполнения операций обслуживания. Чтобы поместить цель под затемнение, вы должны иметь по крайней мере привилегию Blackout Target для цели. Если вы выберете хост, то по умолчанию все цели на этом хосте будут включены в блокировку. Точно так же, если вы выберете цель, в которой есть элементы, то по умолчанию все элементы будут включены в затемнение.
- Щелкните Сервер системной инфраструктуры на странице Все цели.
- Щелкните имя цели, чтобы открыть домашнюю страницу.
- Щелкните Сервер системной инфраструктуры в верхнем левом углу страницы. Щелкните Управление.
- Нажмите «Создать затемнение».
- Выберите причину из меню.
- При необходимости добавьте комментарии.
- Нажмите «Отправить».
Завершение отключения или отключения мониторинга
Вы можете завершить отключение или отключение сервера.
- Щелкните Сервер системной инфраструктуры на странице Все цели.
- Щелкните имя цели, чтобы открыть домашнюю страницу.
- Щелкните Сервер системной инфраструктуры в верхнем левом углу страницы. Щелкните Управление.
- Щелкните «Завершить затемнение» или «Завершить затемнение».
Введение в предупреждения | Cloud Monitoring
Оповещение своевременно сообщает о проблемах в ваших облачных приложениях, поэтому вы
может решить проблемы быстро.
В Cloud Monitoring политика предупреждений описывает обстоятельства
в соответствии с которым вы хотите получать уведомления и как вы хотите получать уведомления. Эта страница
предоставляет обзор политик предупреждений.
Политики предупреждений, которые используются для отслеживания данных метрик, собранных
Облачный мониторинг называется 9Политики предупреждений на основе метрик 0149.
Большая часть документации Cloud Monitoring о
политики предупреждений предполагают, что вы используете политики предупреждений на основе метрик.
Чтобы узнать, как настроить политику оповещения на основе метрик, попробуйте
Быстрый старт для Compute Engine.
Вы также можете создать политики предупреждений на основе журналов , которые уведомляют вас, когда
конкретное сообщение появляется в ваших журналах. Эти политики не основаны на
метрики.
Это содержимое не применяется к политикам оповещения на основе журналов.
Сведения о политиках оповещения на основе журналов см.
Мониторинг ваших журналов.
Как работает оповещение
Каждая политика оповещения определяет следующее:
Условия, которые описывают, когда ресурс или группа
ресурсов, находится в состоянии, которое требует от вас ответа. предупреждение
политика должна иметь хотя бы одно условие; однако вы можете настроить политику
содержать несколько условий.Например, вы можете настроить условие следующим образом:
Задержка ответа HTTP превышает две секунды в течение как минимум пяти минут.
В этом примере условие отслеживает метрику
Задержка ответа HTTP и указывает, когда значения метрики
требуют от вас ответа. Условие соответствует , когда ресурс или
группа ресурсов находится в состоянии, которое требует от вас ответа.Каналы уведомлений, которые описывают, кто должен быть уведомлен о действии
требуется. В оповещение можно включить несколько каналов уведомлений.
политика. Облачный мониторинг поддерживает облачное мобильное приложение и Pub/Sub в
дополнение к обычным каналам уведомлений. Полный список
поддерживаемые каналы и информацию о том, как настроить эти каналы, см.
Варианты уведомлений.Например, вы можете настроить политику оповещения по электронной почте.
[email protected]и отправить сообщение Slack на канал
#моя-группа-поддержки.Документация, которую вы хотите включить в уведомление. Документация
Поле поддерживает обычный текст, Markdown и переменные.Например, вы можете включить в свою политику предупреждений следующее:
документация:## ответы о задержке HTTP Это оповещение создано проектом ${project} с использованием переменная $${проект}.
 предупреждение
предупреждение
После настройки политики предупреждений на основе показателей Мониторинг
постоянно следит за условиями этой политики. Вы не можете настроить
условия, подлежащие мониторингу только в течение определенных периодов времени.
Когда условия этой политики соблюдены,
Мониторинг создает инцидент и отправляет
уведомление о создании инцидента. Это уведомление включает сводку
информацию об инциденте, ссылку на страницу сведений о политике , чтобы
Вы можете расследовать инцидент,
и любую указанную вами документацию.
Если инцидент открыт и Мониторинг определяет, что
условия политики на основе метрик больше не выполняются, то
Мониторинг
автоматически закрывает инцидент и отправляет уведомление о закрытии.
Пример
Вы развертываете веб-приложение на экземпляре виртуальной машины (ВМ) Compute Engine.
это работает веб-приложение. Пока вы ожидаете ответа HTTP
задержка колебаться, вы хотите, чтобы ваша служба поддержки реагировала, когда
приложение имеет высокую задержку в течение значительного периода времени.
Чтобы ваша служба поддержки была уведомлена, когда ваше приложение
высокие задержки, вы создаете следующую политику предупреждений:
Если задержка ответа HTTP превышает две секунды в течение как минимум пяти минут, затем откройте инцидент и отправьте электронное письмо в службу поддержки.
В этой политике предупреждений условием является мониторинг
Задержка ответа HTTP.
Если эта задержка превышает две секунды непрерывно в течение пяти минут, то
условие выполнено, и инцидент создан.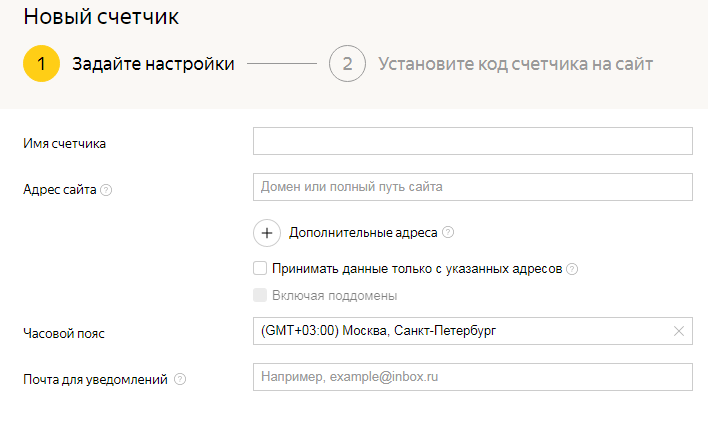 Временный всплеск задержки
Временный всплеск задержки
не приводит к выполнению условия или созданию инцидента.
Ваше веб-приложение становится популярным, а задержка ответа растет
свыше двух секунд. Вот как реагирует ваша политика предупреждений:
Мониторинг запускает пятиминутный таймер при получении
Измерение задержки HTTP выше двух секунд.Если каждый показатель задержки, полученный в течение следующих пяти минут, выше
чем две секунды, то таймер истекает. Когда таймер истекает,
Мониторинг помечает условие как выполненное, открывает
инцидент, и он отправляет электронное письмо в вашу службу поддержки.Ваша группа поддержки получает электронное письмо, входит в консоль Google Cloud,
и подтверждает получение уведомления.В соответствии с документацией в уведомлении по электронной почте ваша группа поддержки
в состоянии устранить причину задержки. Через несколько минут HTTP
задержка ответа снижается до менее чем двух секунд.Когда мониторинг получает измерение задержки HTTP
менее чем за две секунды он закрывает инцидент и отправляет уведомление
вашей группе поддержки, что инцидент закрыт.

Если задержка превышает две секунды и остается выше этого значения
порог за пять минут,
затем открывается новый инцидент и отправляется уведомление.
Как добавить политику предупреждений
Вы можете добавить политику предупреждений на основе метрик в свой проект Google Cloud с помощью
Консоль Google Cloud, API мониторинга облака или интерфейс командной строки Google Cloud:
При использовании консоли Google Cloud вы можете включить
рекомендуемое оповещение или вы можете создать оповещение, начав с
Предупреждения страница облачного мониторинга.Рекомендуемые оповещения доступны для некоторых продуктов Google Cloud. Эти оповещения
требуют минимальной настройки, такой как добавление каналов уведомлений.
Например, страница Pub/Sub Lite Темы содержит ссылки на предупреждения, которые
настроены, чтобы уведомлять вас, когда вы достигаете предела квоты. Сходным образом,
страница VM Instances изнутри
Ссылки мониторинга на политики предупреждений, настроенные на
контролировать использование памяти и задержку сети этих экземпляров.Любую политику, созданную с помощью консоли Google Cloud, можно
также изменять и просматривать с помощью консоли Google Cloud или
API облачного мониторинга. Cloud Monitoring API позволяет создавать оповещения
политики, которые отслеживают соотношение показателей. Когда эти политики используют
Фильтры мониторинга, вы не можете просматривать или изменять их с помощью
Облачная консоль Google.Для получения информации о том, как создать политику предупреждений при запуске на
Оповещения на странице Cloud Monitoring, см.
Создание политик предупреждений с помощью консоли Google CloudКогда вы используете Cloud Monitoring API напрямую или когда вы используете Google Cloud CLI,
вы можете создавать, просматривать и изменять политики предупреждений. Вы можете создавать условия
которые отслеживают соотношение метрик с помощью Cloud Monitoring API или
Облачный интерфейс командной строки Google. Когда вы используете Cloud Monitoring API, вы можете указать
отношение с помощью языка запросов мониторинга (MQL) или с помощью мониторинга
фильтры. Пример политики, использующей мониторинг
фильтры, см. Метрическое соотношение.Для получения дополнительной информации об использовании Cloud Monitoring API и Google Cloud CLI,
видеть
Создание политик предупреждений с помощью Cloud Monitoring API или Google Cloud CLI.
 Сходным образом,
Сходным образом, Вы можете создавать условия
Вы можете создавать условия Cloud Monitoring поддерживает выразительный текстовый язык,
можно использовать с консолью Google Cloud и API мониторинга облака. За
информацию об использовании этого языка с предупреждениями см.
Создание политик предупреждений с помощью языка запросов мониторинга (MQL).
Вы можете добавить политику оповещения на основе журнала в свой проект Google Cloud, используя
Обозреватель журналов в Cloud Logging или с помощью API мониторинга.
Это содержимое не применяется к политикам оповещения на основе журналов.
Сведения о политиках оповещения на основе журналов см.
Мониторинг ваших журналов.
Как управлять политиками предупреждений
Для получения информации о том, как просмотреть список предупреждений на основе показателей вашего проекта.
политики и способы изменения этих политик см. в следующих разделах:
- Управление политиками предупреждений с помощью консоли Google Cloud
- Управление политиками предупреждений с помощью Cloud Monitoring API или Google Cloud CLI
Сведения об управлении политиками предупреждений на основе журналов см.
Использование оповещений на основе журнала.
Для создания политик предупреждений требуется авторизация
В этом разделе описываются роли или разрешения, необходимые для создания политики предупреждений.
Для получения подробной информации об управлении идентификацией и доступом (IAM) для
Облачный мониторинг, см. Контроль доступа.
Контроль доступа.
Каждая роль IAM имеет идентификатор и имя. Идентификаторы ролей имеют
form roles/monitoring.editor и передаются в качестве аргументов
Google Cloud CLI при настройке контроля доступа. Для получения дополнительной информации см.
Предоставление, изменение и отзыв доступа.
В консоли Google Cloud отображаются имена ролей, например Редактор мониторинга.
Требуемые роли консоли Google Cloud
Чтобы создать политику предупреждений,
ваше имя роли IAM для проекта Google Cloud должно
быть одним из следующих:
- Редактор мониторинга
- Мониторинг администратора
- Владелец проекта
Для просмотра списка ролей и связанных с ними разрешений см.
Роли.
Требуемые разрешения API
Чтобы использовать Cloud Monitoring API для создания политики предупреждений,
ваш идентификатор роли IAM для проекта Google Cloud должен
быть одним из следующих:
-
roles/monitoring.: этот идентификатор роли предоставляет alertPolicyEditor
минимальные разрешения, необходимые для создания политики предупреждений. Больше подробностей
об этой роли см. в разделе Предопределенные роли предупреждений. -
роли/мониторинг.редактор -
роли/monitoring.admin -
роли/владелец
 alertPolicyEditor
alertPolicyEditor Чтобы определить разрешение, необходимое для определенного метода Cloud Monitoring API,
видеть
Разрешения API облачного мониторинга.
Чтобы просмотреть список ролей и связанных с ними разрешений, см.
Роли.
Определение вашей роли
Чтобы определить свою роль для проекта с помощью консоли Google Cloud,
выполните следующие действия:
Откройте консоль Google Cloud и выберите проект Google Cloud:
Перейдите в облачную консоль Google.
Чтобы просмотреть свою роль, нажмите IAM & admin .
Ваша роль на том же
строка в качестве вашего имени пользователя.
 Ваша роль на том же
Ваша роль на том же Чтобы определить разрешения на уровне вашей организации, обратитесь в
администратор.
Затраты, связанные с политиками предупреждений
Нет затрат, связанных с использованием политик предупреждений. Для информации
о ценах на проверки работоспособности см. в разделе Цены на облачный мониторинг
резюме.
На использование вами политик предупреждений и проверок работоспособности распространяются следующие ограничения:
| Категория | Значение | Тип политики 1 |
|---|---|---|
| Политики предупреждений (сумма метрик и журналов) по области метрик 2 | 500 | Метрическая, журнал |
| Условия для политики предупреждений | 6 | Метрическая система |
| Максимальный период времени, который оценивается условием отсутствия метрики 3 | 1 день | Метрическая система |
| Максимальный период времени, который оценивается условием порога метрики 3 | 23 часа 30 минут | Метрическая система |
| Каналы уведомлений на политику предупреждений | 16 | Метрическая, журнал |
| Максимальная частота уведомлений | 1 уведомление каждые 5 минут для каждого оповещения на основе журнала | Журнал |
| Максимальное количество уведомлений | 20 уведомлений в день для каждого оповещения на основе журнала | Журнал |
| Максимальное количество одновременно открытых инцидентов на политику предупреждений | 5000 | Метрическая система |
| Период, по истечении которого инцидент без новых данных автоматически закрывается | 7 дней | Метрическая система |
| Максимальная продолжительность инцидента, если он не закрыт вручную | 7 дней | Журнал |
| Сохранение закрытых инцидентов | 13 месяцев | Неприменимо |
| Сохранение открытых инцидентов | Бессрочный | Неприменимо |
| Каналы уведомлений по области метрик | 4000 | Неприменимо |
| Проверки времени безотказной работы по области метрик 4 | 100 | Неприменимо |
| Максимальное количество эхо-запросов ICMP на одну общедоступную проверку работоспособности | 3 | Неприменимо |
1 Метрика: политика предупреждений на основе данных метрик; Журнал: политика оповещения на основе сообщений журнала (оповещения на основе журнала)
2 Apigee и
Гибрид Apigee глубоко
интегрирован с облачным мониторингом. Лимит предупреждений для
Лимит предупреждений для
все уровни подписки Apigee — Standard, Enterprise и Enterprise
Плюс — то же, что и для Cloud Monitoring: 500 на область метрик.
3 Максимальный период времени, который оценивается условием, представляет собой сумму
период выравнивания и значения окна длительности. Например, если период согласования
установлен на 15 часов, а окно продолжительности установлено на 15 часов, то для
оценить состояние.
4 Это ограничение распространяется на количество проверок работоспособности
конфигурации. Каждая конфигурация проверки работоспособности включает временной интервал
между проверками состояния указанного ресурса. Видеть
Управление проверками работоспособности для получения дополнительной информации.
Полную информацию о ценах см.
Цены на операционный пакет Google Cloud.
Что дальше
Для получения информации о задержке уведомления и о том, как выбрать
параметры политики предупреждений влияют на отправку уведомлений,
см.
