Содержание
Операторы Яндекс Wordstat (Вордстат) – описание принципов работы
#Общие вопросы
#Яндекс Вордстат
#106
Февраль’19
Февраль’19
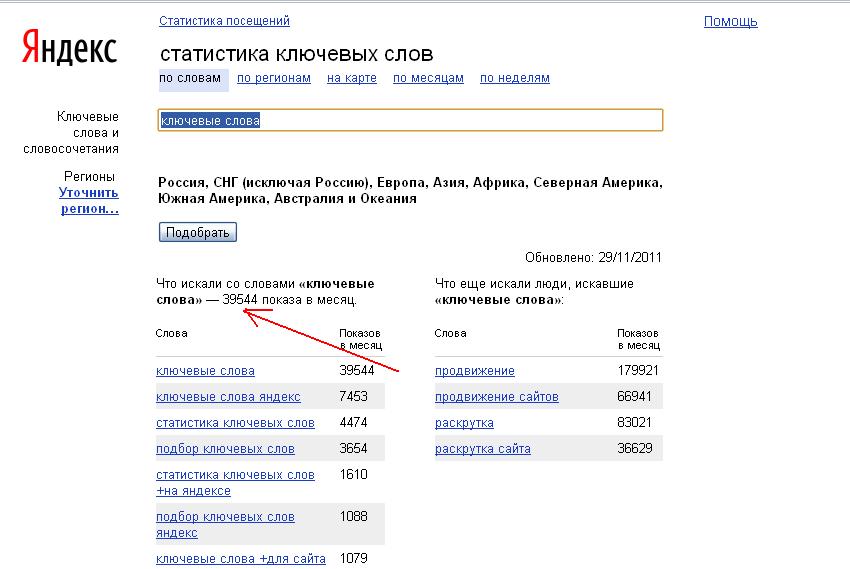
Яндекс Вордстат — сервис, предоставляющий статистику поисковых запросов, вводимых в поисковую систему Яндекс.
Если просто ввести слово или словосочетание, в результатах будет приведена статистика по тому, сколько раз пользователи вводили данную фразу в течение месяца и какие еще слова вводят вместе с данной фразой. Частота показов в данном случае включает все запросы, в которых присутствовала данная фраза.
Для работы с данным сервисом существуют специальные операторы, использование которых позволяет получать другие данные.
Оператор кавычки «» — фиксирует число слов. Фраза, введенная в кавычках, показывает частоту данного запроса без учета других слов. Но учитывается любой порядок слов в запросе и все окончания.
- Указано количество запросов, содержащих только указанные фразы (без учета словоформы и порядка слов).
- Общее количество запросов, содержащее указанные слова.
Оператор Восклицательный знак «!» — указывается перед словом и фиксирует окончание. В статистике будут показаны данные по числу показов именно в том виде, без учета других словоформ.
- Указано общее число запросов, содержащее указанные фразы.
- Число запросов, содержащее указанные слова с зафиксированной словоформой «окно».
Оператор Плюс «+» — фиксирует стоп-слова. Изначально служебные части речи, местоимения и предлоги не учитываются сервисом. Чтобы зафиксировать предлог, необходимо перед ним добавить +
- В первом случае предлог не учитывается и показана частота ввода фраз без его учета..
- Добавив «+» мы зафиксировали стоп-слово и получили частоту запросов, содержащих предлог.
Оператор Минус «-» — исключает из списка запросы, указанные после оператора
- В данном примере мы исключили из статистики все запросы, содержащие слова установка, регулировка, шторы, жалюзи, ремонт.

Оператор Квадратные скобки «[]» — фиксирует порядок слов в запросе.
- В первом примере порядок слов не учитывается и статистика показывается по всем запросам, содержащим данные слова.
- Добавив данный оператор, статистика содержит только фразы, задаваемые в указанном порядке.
Оператор группировки «()» — используется для задания сложных запросов.
Оператор Или «|» — позволяет использовать несколько фраз в запросе.
- Такой запрос покажет все запросы содержащие слово телевизоры и любое из слов указанных в скобках (samsung или самсунг).
Операторы можно группировать между собой, например чтобы получить точную частоту фразы в определенной словоформе и заданном порядке слов, необходимо задать следующий запрос:
Похожее
Контент
Параметры
Использование скрытого контента на сайте
Факторы ранжирования
Поведенческие
Правильное оформление форм на сайте
Контент
Параметры
#140
Использование скрытого контента на сайте
Август’19
1452
1
Факторы ранжирования
Поведенческие
#139
Правильное оформление форм на сайте
Август’19
2838
1
Факторы ранжирования
Поведенческие
#138
Оформление 404 страницы
Август’19
1549
2
Общие вопросы
Продвижение сайта
#137
Как продвигать сайт визитку?
Август’19
1648
2
Оптимизация сайта
Внутренняя перелинковка
#136
Поиск 404 ошибок на сайте
Август’19
1695
Общие вопросы
Продвижение сайта
#135
Почему у сайта разные позиции?
Июль’19
2297
Оптимизация сайта
Внутренняя перелинковка
#134
Циклические ссылки на сайте
Июль’19
8258
Оптимизация сайта
Индексация
#133
Атрибут rel=canonical
Декабрь’22
11240
22
Факторы ранжирования
Коммерческие
#132
Как правильно оформить страницу «Контакты»
Июль’19
2526
10
Общие вопросы
Продвижение сайта
#131
Поиск поддоменов сайта
Июль’19
2232
10
Общие вопросы
Продвижение сайта
#130
Как вирусы влияют на позиции сайта
Июль’19
2631
11
Ключевые запросы
Виды запросов
#129
Каннибализация запросов
Июль’19
8187
10
Системы аналитики
Яндекс Метрика
#128
Фильтрация визитов роботов на сайт
Июль’19
9046
13
Общие вопросы
Продвижение сайта
#127
Неактуальные страницы товаров на сайте – что делать
Июль’19
2512
12
Системы аналитики
Google Analytics
#126
(not set) и (not provided) в отчетах Google Analytics
Июль’19
3898
11
Яндекс Вордстат (Yandex WordStat) – статистика ключевых слов
Обучение в IMBA
Мы собрали для тебя подробный список терминов, методик и
инструментов, которые встречаются в учебных программах.
«Яндекс.Вордстат»
(wordstat.yandex.ru) – это бесплатный статистический сервис для оценки
пользовательских интересов, сбора семантического ядра для поискового
продвижения и контекстной рекламы. С помощью «Вордстата» можно узнать,
насколько часто поисковая система обрабатывала запросы с определенной
или похожей ключевой фразой. Чтобы эффективность демонстрации рекламы
была высокой, следует сделать определенную территориальную привязку
(вкладка «Уточнить регион…»). Так реклама будет показываться тем
пользователям, чей IP-адрес подходит под заданный регион.
Как пользоваться Yandex Wordstat
1. Авторизуемся с любого аккаунта «Яндекса».
2.
В поле для поиска нужно ввести ключевое слово или фразу. После клика по
кнопке «Подобрать» система wordstat.Яндекс.ru сформирует статистику
ключевых фраз. По умолчанию сервис учитывает любую морфологию, поэтому и
запросы можно формировать в любой форме.
Результат анализа формируется на основе релевантных пользовательских запросов в «Яндексе» за последние 30 дней.
3.
В левой части отчета отражается частотность запросов, в которые входит
целевое слово в любых словоформах. В правой колонке можно увидеть
похожие тематические фразы.
4. Вкладка «По регионам» дает
возможность оценить востребованность ключевого словосочетания в
отдельных больших или ограниченных локациях.
В колонке «Региональная популярность» показатель 100 % можно
приравнять к условному нулю. Если цифры будут больше, то популярность
можно считать повышенной, а если меньше, то пониженной.
5. По
умолчанию сервис Yandex Wordstat рассчитывает статистику по всем
регионам своего охвата. Для более точной подборки слов нужно выбрать
определенную географическую локацию в настройках.
6. Статистику слов в «Яндексе» можно уточнить с помощью фильтра
платформ. Это дает возможность оценить спрос по запросу отдельно для
пользователей ПК, ноутбуков, планшетов или смартфонов.
7.
Опция «История запросов» предусмотрена для оценки сезонной популярности
отдельных тем, товаров или услуг. На примере ниже можно увидеть, что
На примере ниже можно увидеть, что
спрос на квадрокоптеры резко увеличивается к новогодним праздникам, но
потом постепенно спадает до начала теплого сезона.
Особенности работы с семантикой
В сервисе
«Яндекс.Вордстат» статистика формируется с учетом всех похожих фраз, что
сильно размывает результаты по конкретному запросу. Чтобы получать
точные аналитические данные, нужно пользоваться специальными операторами
языка запросов:
- + – в ключевой фразе учитываются предлоги и союзы;
- _ – исключение из поиска слов после этого знака;
- «» – фраза в кавычках должна быть найдена в прямом вхождении;
- () – с помощью этого оператора слова собираются в группы;
- ! – выводится точная информация.
Синонимы:
Все
термины
на букву «Я»
Все термины
Яндекс — Технологии — Осмысление поисковых запросов
Когда кому-то задают вопрос, в игру вступает целый ряд мыслительных процессов, прежде чем можно будет дать ответ. Когда пользователь вводит поисковый запрос в строку поиска, поисковая система выполняет целый ряд действий, чтобы получить ответ.
Когда пользователь вводит поисковый запрос в строку поиска, поисковая система выполняет целый ряд действий, чтобы получить ответ.
Первое, что делает поисковая система, это определяет язык, с которым ей приходится иметь дело. Следующим шагом является анализ поисковых слов, чтобы определить, какие слова и словоформы следует искать в Интернете. Искать точную комбинацию слов [Аптеки Торонто] может быть недостаточно, так как страницы со словами «Аптеки Торонто» или «Аптеки в Торонто», скорее всего, также будут релевантными. Он также должен выяснить, какие слова и в каких формах следует игнорировать.
Вся процедура — определение языка, анализ слов, сопоставление синонимов и т. д. — занимает доли секунды.
Анализ запроса начинается с идентификации языка.
Английское «подарок» с таким же успехом может оказаться немецким «яд» — «Подарок». Чтобы поисковая система знала, какой язык используется, она ищет в поисковом запросе отличительные буквы, их комбинации или определенные слова. Поисковый запрос [Gift der Scorpione] извлекает информацию о яде скорпиона на немецком языке, а [подарок для скорпиона] извлекает ссылки на веб-сайты с идеями подарков на день рождения для людей, чей астрологический знак — Скорпион.
Поисковый запрос [Gift der Scorpione] извлекает информацию о яде скорпиона на немецком языке, а [подарок для скорпиона] извлекает ссылки на веб-сайты с идеями подарков на день рождения для людей, чей астрологический знак — Скорпион.
Немецкое слово ‘ein’ выглядит в точности как американское [EIN], которое интерпретируется поисковиком как ‘идентификационный номер работодателя’ и возвращает, соответственно, информацию о системе социального обеспечения США, а [ein team ein Ziel !] выводит результаты поиска на немецком языке, связанные со слоганом сборной Германии по футболу – «одна команда, один гол».
Хотя ожидается, что поисковая система классифицирует [San José de Arimatea] как испанский запрос и ответит информацией об Иосифе Аримафейском на испанском языке, [San Jose Sharks] должен выдавать результаты о калифорнийской хоккейной команде.
Также полезно знать регион пользователя при попытке определить его язык. Знание того, что поисковый запрос исходит, скажем, из Севильи, приведет к тому, что поисковая система поверит, что язык поиска, скорее всего, испанский.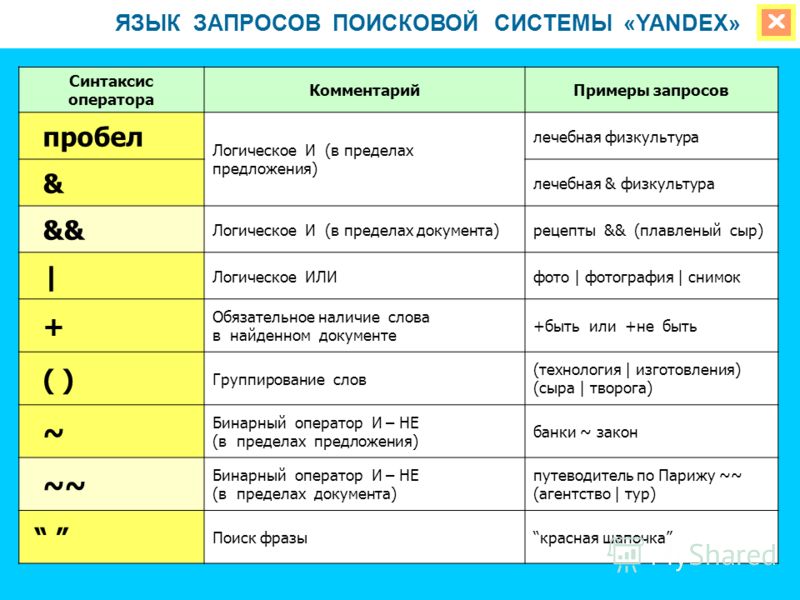
Определив язык запроса, поисковая система просматривает структуру каждого условия поиска, чтобы расширить пул потенциально совпадающих результатов поиска. Вместо того, чтобы искать только точное совпадение, поисковая система использует свои знания о правилах формирования слов, чтобы найти все страницы, содержащие различные формы поискового термина. Если кто-то, кто ищет «Унесенные ветром», введет в поле поиска [go with the wind], он все равно найдет отсылки к фильму. Помимо точных совпадений по запросу [стальной нож], в результатах поиска также есть ссылки на страницы с «стальными ножами», «ножами» и даже «ножом» и «стальными ножами».
Анализируя поисковый запрос, Яндекс составляет для каждого слова список всех возможных грамматических форм.
Некоторые слова могут звучать и выглядеть одинаково, но означать разные вещи. При обработке поискового запроса с такими словами поисковая система предлагает результаты для всех возможных значений. Например, пользователи, которые ищут [Замок], увидят как изображения, так и ссылки на страницы об укрепленных, преимущественно средневековых зданиях, а также информацию о популярном телесериале вместе со ссылками на страницы, где его можно посмотреть в потоковом режиме.
Если поисковая система ограничит свой поиск исключительно поиском страниц со словами, которые точно соответствуют условиям поиска, будет упущено много полезной информации, относящейся к поисковому запросу пользователя. Часто существует более одного способа сослаться на что-либо. Говоря об одном и том же, например, в разных источниках может использоваться как сокращенная, так и полная версия термина или названия. Отвечая на поисковый запрос, Яндекс добавляет к исходным условиям поиска все возможные варианты этих слов. Выдавая результаты поиска по поисковому запросу [Массачусетский технологический институт], Яндекс также добавляет страницы, содержащие «MIT», и наоборот.
Точно так же поисковая система должна искать различные способы написания чисел (например, «Карл Первый» и «Карл I»), близкородственные однокоренные слова, альтернативные варианты написания и синонимы. К поисковому запросу [латышский язык] система добавляет «Латвия», а для [лингвистика] будет включать «лингвистически» и «лингвистически».
Выбирая, какие слова добавить, а какие опустить, Яндекс смотрит, как часто каждое слово в запросе встречается с другими словами — как в запросах пользователей, так и в общем пуле документов. Статистика сочетания слов говорит поисковой системе, что пользователь, ищущий «галстук-бабочку», действительно хочет найти сайты о галстуках в форме банта, а не информацию о приспособлениях для наклона или снарядов для стрельбы из стрел.
Однокоренные слова и синонимы взяты из словарей и справочных ресурсов, часть из которых Яндекс выпускает специально для таких ситуаций.
Анализируя запрос, поисковая система всегда проверяет его грамматически правильность. По статистике Яндекса, около 12% запросов содержат ошибки — опечатки, орфографические ошибки и тарабарщину из-за неправильной раскладки клавиатуры. Если поиск ограничивается только тем, что написано в поле поиска, пользователь не получит искомого ответа, потому что в большинстве случаев контент сайта написан корректно. В случае слов, которые часто пишутся неправильно, или запросов, на которые нет хорошего ответа, поисковая система сразу же исправляет запрос и показывает ответы на исправленную версию — также, конечно, предупреждая пользователя о том, что запрос был исправлен. Таким образом, [Asassin’s Creed] автоматически исправляется, и поисковая система будет искать «Assassin’s Creed».
Таким образом, [Asassin’s Creed] автоматически исправляется, и поисковая система будет искать «Assassin’s Creed».
В некоторых случаях трудно сказать, допустил ли пользователь ошибку. В таких ситуациях Яндекс спрашивает, не ошибся ли пользователь и хочет ли он видеть ответы на исправленную версию запроса. Поисковик знает, что [Tokio Hotel] — это музыкальная группа, а [гостиницы в Токио] относятся к проживанию в столице Японии. Если запрос [tokyo hotel], поисковая система показывает ответы на обе версии запроса на одной странице и предлагает возможность сузить его до одной или другой, нажав на нужное написание.
Эта работа с ошибками и весь процесс лингвистического анализа происходит за доли секунды. За это время система успевает определить язык запроса, проанализировать каждое слово, найти синонимы и общие сочетания, а затем, наконец, решить, какие именно слова нужно найти.
Алгоритм искусственного интеллекта Яндекса — человеческий уровень
Автор Анастасия Курмакаева
Содержание
- 1 Палех
- 2 Королев
- 3 Андромеда
- 4 Выводы
Сегодня мы поговорим о том, как эволюционировал поисковый алгоритм Яндекса за последние несколько лет и его ключевых обновлениях, ставших переломными в том, как поисковая система анализирует поисковые запросы и возвращает результаты, основанные на потребностях пользователей. Палех (2016), Королев (2017) и Андромеда (2018) полагаются на искусственный интеллект нейронных сетей, чтобы лучше понять намерение поиска , сделав еще один шаг от анализа простых ключевых слов к пониманию их означает .
Палех (2016), Королев (2017) и Андромеда (2018) полагаются на искусственный интеллект нейронных сетей, чтобы лучше понять намерение поиска , сделав еще один шаг от анализа простых ключевых слов к пониманию их означает .
Несмотря на монополию Google в большинстве стран мира, доля рынка Яндекса в России по-прежнему превышает долю калифорнийского гиганта . Учитывая неудержимое расширение и технологическое развитие первого, не похоже, что что-то изменится в ближайшие годы.
🎯 По данным SEJournal, в 2019 году 52% русскоязычных пользователей по-прежнему предпочитают использовать Яндекс, в отличие от 46% интернет-пользователей, которые выбирают Google.
В том же интервью с командой Яндекса, опубликованном в SEJournal, мы также выяснили, что проникновение мобильного поиска и голосового поиска становится все более значительным среди российских пользователей, составляя соответственно 56% и 20% от общего числа.
Палех
После внедрения Палеха в ноябре 2016 года Яндекс продолжает совершенствовать и совершенствовать алгоритм поиска на основе нейронных сетей, чтобы иметь возможность давать ответы на более сложные поисковые намерения и поисковые запросы с помощью машинного обучения, уделяя особое внимание длиннохвостым . Его первый выпуск был ограничен, так как он мог анализировать только заголовки веб-страниц, но не их содержимое в целом. Он также был значительно медленнее, чем его преемник (мы поговорим об этом через секунду), обрабатывая около 40% из 280 миллионов ежедневных запросов к поисковой системе.
Технология « семантических векторов », используемая Палехом, основана на дистрибутивной семантике. Как они объясняют в своем блоге на русском языке, слова миллиардов запросов конвертируются в числа, вернее, в группы по 300 чисел. Они распределяются по 300-мерному пространству, где каждый документ имеет свой собственный вектор. Если числа, соответствующие запросу, находятся рядом с числами, соответствующими документу в том же пространстве, результат считается релевантным.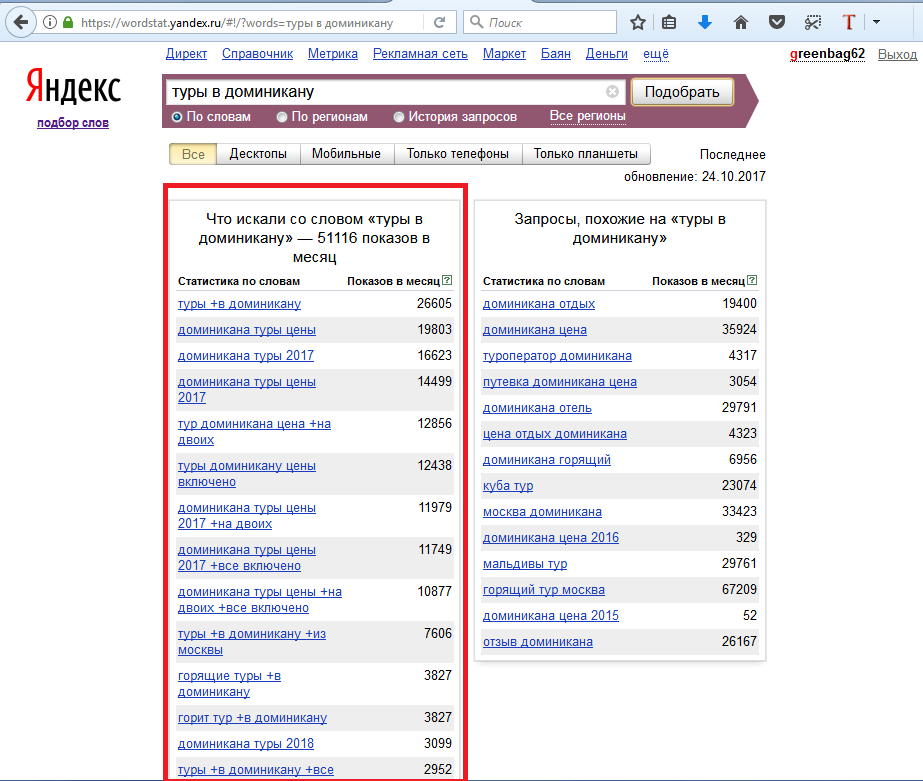 Чем ближе они друг к другу, тем более релевантным будет результат, который поисковая система возвращает пользователю.
Чем ближе они друг к другу, тем более релевантным будет результат, который поисковая система возвращает пользователю.
Небольшая местность Палех в России послужила источником вдохновения для названия алгоритма, который использует свой своеобразный герб, представляющий огненную птицу благодаря ее очень отчетливому длинному хвосту.
Яндекс распределяет длинных хвостов ключевых слов по различным категориям, от менее до более конкретных. Наиболее релевантные запросы и результаты не всегда будут иметь общие слова, что действительно усложняет работу поисковой системы. Например:
- Поисковые запросы, где человек не помнит название недавно просмотренного фильма, но в памяти запечатлелась одна конкретная сцена: «фильм о человеке, который выращивает картошку на другой планете». > Марсианин.
- Люди, чаще дети, которые толком не понимают, как им пользоваться поисковой системой, и говорят с ней, как с самостоятельным существом: «Яндекс, дайте мне, пожалуйста, рекомендации крутые игры для планшетов с феями» > Цель их поиска, вероятно, можно выразить на странице с рекомендациями фэнтезийных игр для мобильных платформ iOS или Android.
И здесь алгоритм нужно научить понимать и отвечать на более естественные и «человеческие» запросы.
Яндекс предоставляет для нас, смертных, следующее графическое представление в двух измерениях, чтобы объяснить, как работает Палех:
Королев
Почти год спустя, в августе 2017 года, произошло очередное большое обновление алгоритма ИИ Яндекса: Королев.
Королёв строит на Палехе, но ещё мощнее. В то время как предыдущее обновление было сосредоточено только на теге заголовка, чтобы найти соответствие между поисковым запросом, введенным пользователем, и результатами, Korolyov читает и анализирует все содержимое страницы , чтобы получить гораздо более точные результаты, соответствующие поисковому запросу пользователя. И это еще не все: его возможности обработки документов в реальном времени умножаются в тысячу раз. Более того, будучи системой на основе ИИ, ее нейронная сеть продолжает учиться благодаря тщательному анализу поведения пользователя при представлении результатов.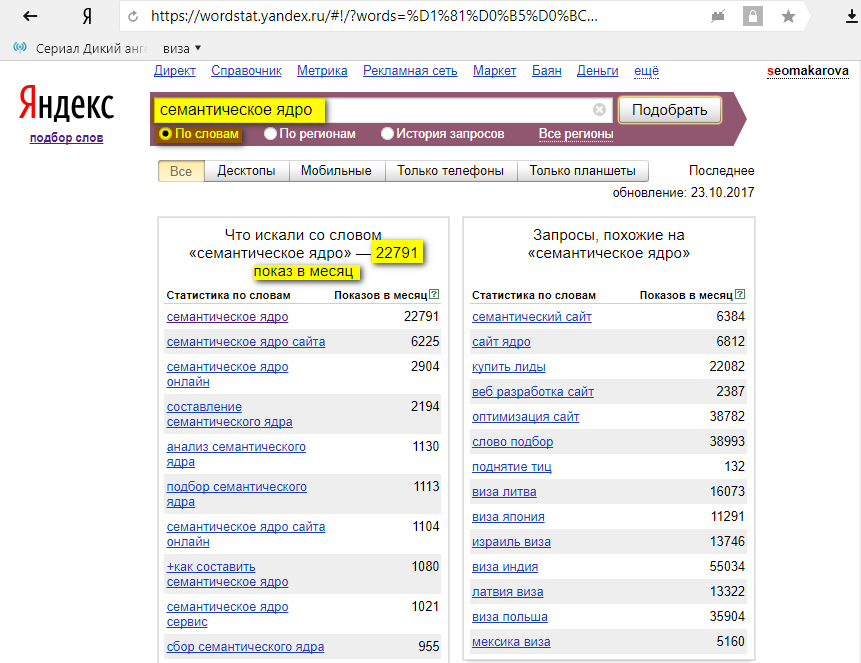 Он сравнивает текущий запрос с другими запросами, которые ранее приводили пользователя к тому же контенту. Или он учитывает время, которое пользователь провел на странице после того, как попал туда через X-запрос, среди других показателей релевантности.
Он сравнивает текущий запрос с другими запросами, которые ранее приводили пользователя к тому же контенту. Или он учитывает время, которое пользователь провел на странице после того, как попал туда через X-запрос, среди других показателей релевантности.
С другой стороны, расчет семантического вектора выполняется на этапе индексации, что позволяет поисковой системе быстро и эффективно устанавливать связи. Это обеспечивает значительную экономию ресурсов, поскольку алгоритму достаточно обработать фрагмент контента только один раз, чтобы иметь возможность сравнить вектор запроса с векторами контента, которые он уже знает.
В том же году, когда был выпущен Королев, Яндекс также запустил своего ИИ-помощника: Алису. Этот выпуск увеличил использование голосового поиска в поисковой системе.
Андромеда
В 2018 году наступает Андромеда. Это последнее обновление внесло новые улучшения в поисковую систему, дальнейшее развитие и обогащение возможностей обучения интеллектуального алгоритма . Это делает поиск информации гораздо более интуитивным и простым для пользователей, а контент, представленный в результатах, гораздо более актуальным, надежным и поступающим из более качественных источников.
Это делает поиск информации гораздо более интуитивным и простым для пользователей, а контент, представленный в результатах, гораздо более актуальным, надежным и поступающим из более качественных источников.
Мы также видим появление новых функций, таких как быстрые ответы . Эта функциональность заключается в предоставлении прямых и четких результатов на простые запросы. Например:
- Когда [праздник]
- Какие футбольные команды играют сегодня.
- Кафе рядом со мной.
Еще одна новая функция — Яндекс Эксперт , где пользователи могут задавать вопросы на самые разные темы настоящим экспертам, если не находят подходящего ответа на свой запрос в результатах поиска.
Выводы
Что мы можем извлечь из пути, по которому Яндекс идет последние несколько лет? Как это влияет на SEO в России? Короче говоря, мы не видим больших различий между Google и Яндексом в этом отношении.
- Создание релевантного и качественного контента по-прежнему жизненно важно для процветания веб-сайта.
