Содержание
Wordstat Yandex — статистика по ключевым словам от Яндекса
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
A
B
C
D
E
F
G
H
I
J
K
L
M
N
O
P
Q
R
S
T
U
V
W
X
Y
Z
0-9
Оглавление
Статистика Яндекс Wordstat
История запросов
W
Вордстат (Яндекс Wordstat) – инструмент для поиска популярных пользовательских запросов в поисковой системе. Принадлежит компании Яндекс и является абсолютно бесплатным.
Изначально сервис был придуман для специалистов по контекстной рекламе – чтобы они могли понять, сколько показов объявлений они получат, выбрав тот или иной запрос в качестве ключевого слова. Но наряду со специалистами по контексту Яндекс Вордстат также популярен среди SEO-специалистов, контент-маркетологов и т.д.
Официальный сайт Вордстат Яндекс – https://wordstat.yandex.ru/. Перед тем как начать работу с сервисом, необходимо залогиниться (или создать аккаунт) в Яндексе. Авторизованные пользователи могут сразу начинать вводить в строку поиска ключевое слово и смотреть его популярность.
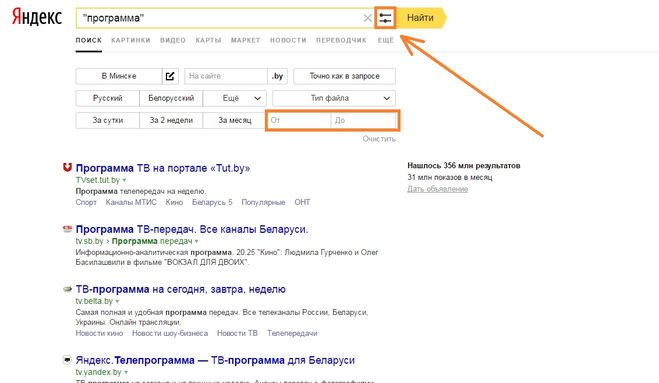
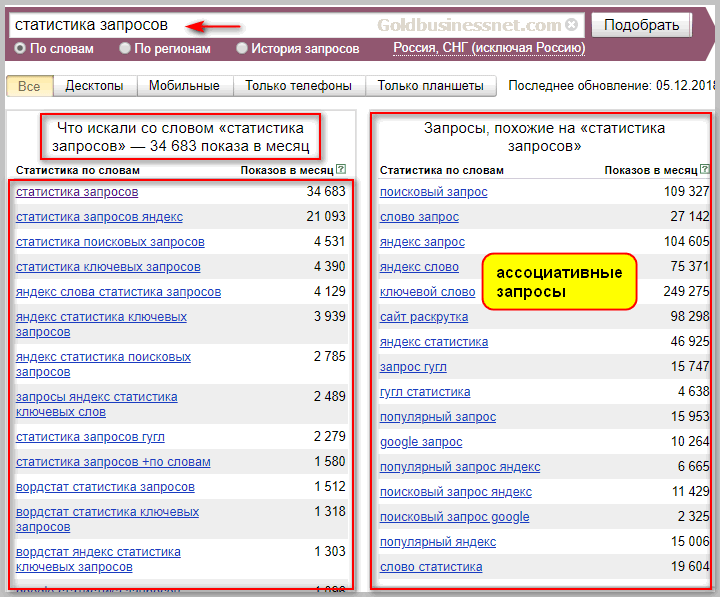
В результатах подбора Яндекс Wordstat отображается следующая информация по ключевому запросу:
- «Что искали со словом «…» –n показов в месяц» – число пользовательских запросов в поиск Яндекса с данным словом.
 Для расчета система использует данные за последние 30 дней. Причем в этих расчетах используется только статистика из основного поиска Яндекса, запросы пользователей, сделанные на поиске РСЯ, не учитываются.
Для расчета система использует данные за последние 30 дней. Причем в этих расчетах используется только статистика из основного поиска Яндекса, запросы пользователей, сделанные на поиске РСЯ, не учитываются. - В левой колонке также представлена статистика по показам ключевых слов, которые включают в себя запрос, и прогнозируемые показы по ним.
- В правой колонке представлены запросы, похожие на тот, что задал пользователь, и прогнозируемые по ним показы.
 Для расчета система использует данные за последние 30 дней. Причем в этих расчетах используется только статистика из основного поиска Яндекса, запросы пользователей, сделанные на поиске РСЯ, не учитываются.
Для расчета система использует данные за последние 30 дней. Причем в этих расчетах используется только статистика из основного поиска Яндекса, запросы пользователей, сделанные на поиске РСЯ, не учитываются.
По умолчанию в Вордстат-статистике учитываются все города и регионы. Определенный регион для подбора данных можно выбрать, нажав «Все регионы»:
Также можно отфильтровать общую статистику по популярности и спросу в разных регионах:
В Яндекс Wordstat доступны срезы по типам устройств пользователей:
- Срез «Десктопы» для запросов, введенных с компьютеров и ноутбуков,
- Срез «Мобильные» для запросов, введенных с планшетов и смартфонов,
- Срез «Только телефоны» – запросы исключительно со смартфонов,
- Срез «Только планшеты» – запросы, введенные только с планшетов.

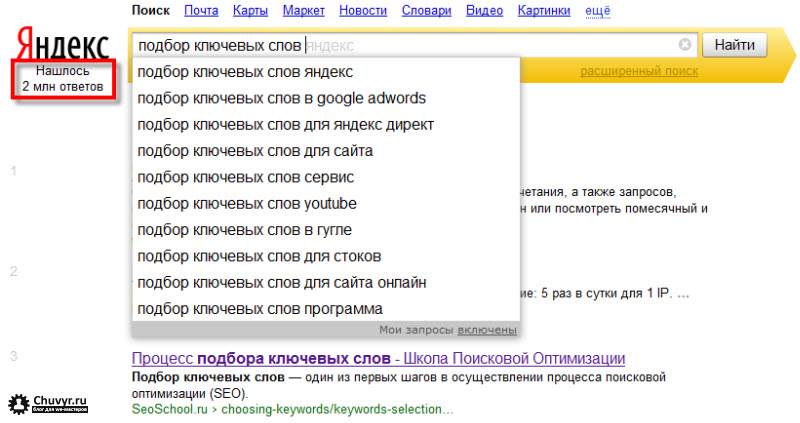
В Wordstat Yandex для уточнения запроса можно использовать минус-слова, минус-фразы и дополнительные операторы, они поддерживаются во вкладках По словам и По регионам.
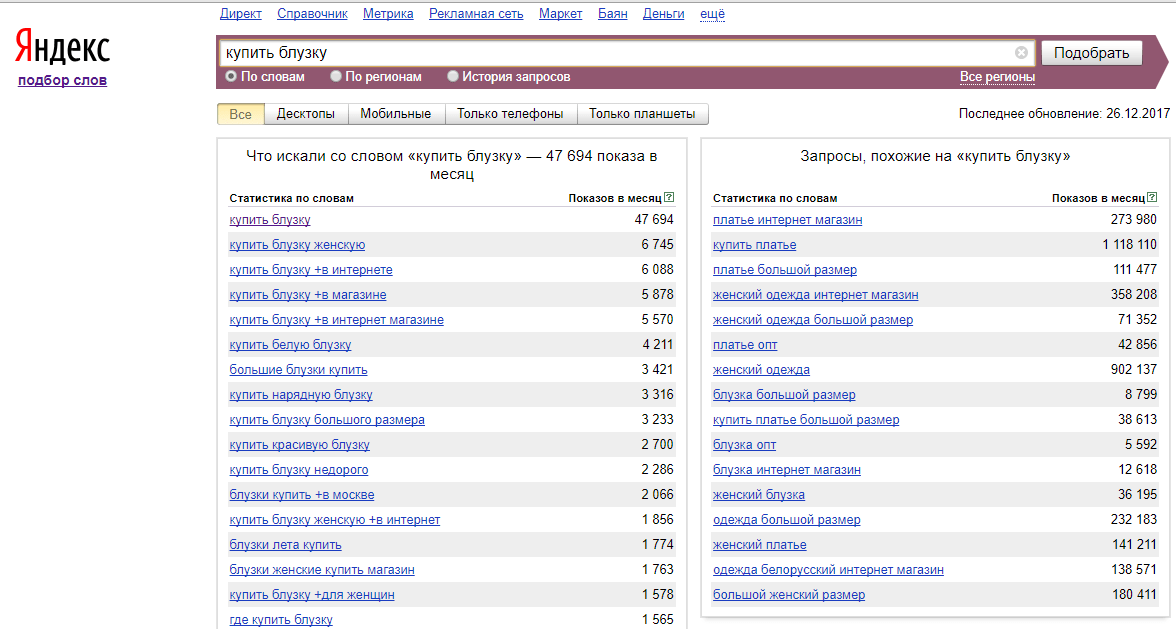
История запросов
Вкладка История запросов пригодится для отслеживания динамики пользовательского интереса к определенной тематике – здесь можно посмотреть помесячный или понедельный срез статистики показов по заданному запросу. Используются данные за последние два года. Интерес пользователей представлен в виде графика.
- Статистика доступна в абсолютных и относительных значениях,
- В данном отчете не работают операторы языка запросов.
Синонимы:
нет
Все термины на букву «W»
Все термины в глоссарии
(Голосов: 8, Рейтинг: 4. | ||||
 5)
5)Все операторы поиска Яндекс и Google, включая секретные.
Продвижение
Люди редко пользуются языком запросов поисковых систем и зря – с помощью пары простых операторов можно значительно сузить поиск и найти желаемое намного быстрей. А для работников SEO не знать об операторах поисковых систем – вообще позор. Синтаксис поисковых систем Яндекс и Гугл очень прост.
Содержание:
- Операторы общие для Яндекс и Google
- Операторы для Яндекса
- Документные операторы Яндекс
- Секретные операторы Яндекс
- Операторы для Google
- Документные операторы Google
- Операторы для Bing
Операторы поисковых запросов помогают получить полезную информацию об индексации сайта, выявить проблемы и даже разобраться в нюансах работы поисковых алгоритмов. В данной статье все операторы поиска без примеров, но зато они здесь ВСЕ и будут дополняться (или удаляться), чтобы информация была актуальна.
Рассмотрю только Google и Яндекс, ведь в основном все работают с ними, остальные поисковики подтягиваются как-то сами.
Общие для Яндекс и Гугл операторы.
Стоит добавить, что если Яндекс точно следует операторам, то Google может их проигнорировать, если посчитает, что есть результаты лучше.
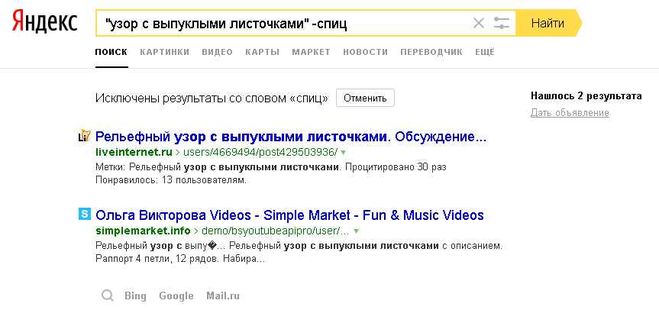
- Оператор “+” и “-“ — Поиск документов, которые обязательно содержат (или обязательно не содержат) указанное слово. Можно использовать несколько операторов в одном запросе, причем как «минус», так и «плюс»
- Поиск по цитате, оператор кавычки «» — Поисковая система будет искать точное совпадение фразы. Можно использовать несколько раз в одном запросе. Даже можно добавить «минус» перед одним из запросов.
- Оператор “*” звездочка — Яндекс: Используется для указания пропущенного слова в цитате. Одна звездочка – одно слово. Применяется только с оператором «кавычки». Гугл: Используется для указания пропущенных слов в запросе. В справке указано, что словА, но на практике – любое количество слов.
- Оператор «|» — Поиск страниц содержащих любое из слов связанных этим оператором.
- Оператор “~” тильда — Яндекс: ищет документы, в которых слово указанное после оператора не содержится в одном предложении со словом до оператора. Гугл: ищет документы с указанным словом и его синонимами.
 В справке указано, что словА, но на практике – любое количество слов.
В справке указано, что словА, но на практике – любое количество слов.Операторы поиска для Яндекса
- «!» — Поиск документов, где слово содержится только в заданной форме. Можно искать даже слова с заглавными буквами.
- «!!» — Поиск документов, где слово содержится в любой форме, в любом падеже.
- «&» амперсант — Поиск документов, где слова связанные оператором находятся в одном предложении.
- «&&» двойной амперсант — Тоже самое, только слова в пределах одного документа.
- «<<» — Поиск слов в пределах документа, но релевантность (она влияет на положение в результатах поиска) рассчитывает только по первому слов (которое до оператора)
Оператор /n , где n максимальное расстояние между заданными словами
Поиск документов, в которых заданные слова располагаются в пределах n слов друг относительно друга и в обратном порядке следования.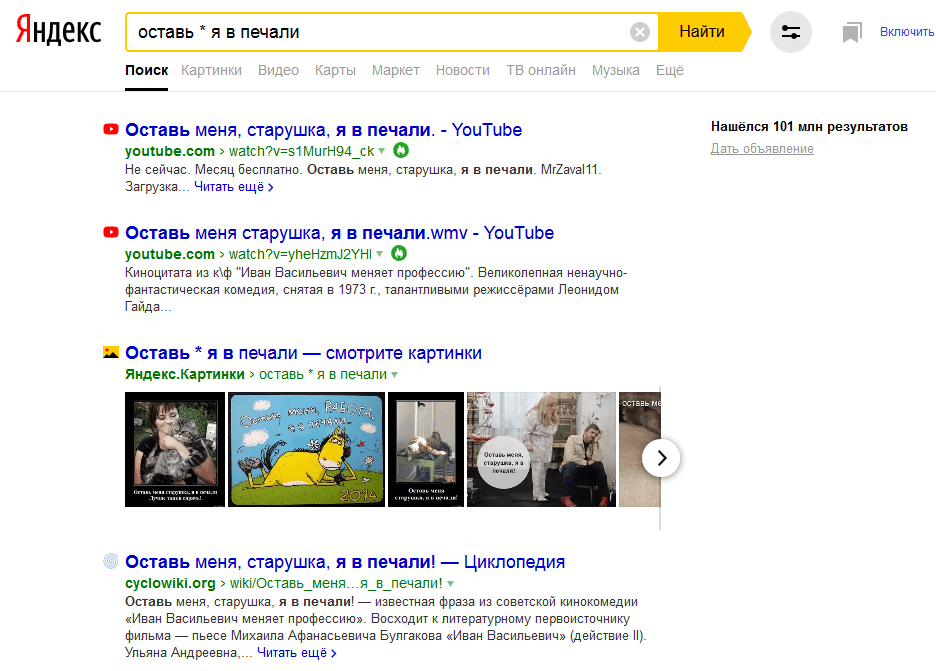
Дополнительно можно задать прямой (+) или обратный (—) порядок следования слов в найденных документах.
Оператор /(m n), где
m — минимальное расстояние между заданными словами, n — максимальное расстояние между заданными словами
Поиск документов, в которых заданные слова располагаются на расстоянии не менее m и не болееn слов друг относительно друга.
Дополнительно можно задать прямой (+) или обратный (—) порядок следования слов в найденных документах.
Оператор && /n,
Где n — максимальное расстояние между предложениями, содержащими слова запроса
Поиск документов, в которых слова запроса (разделенные оператором) располагаются в пределах n предложений друг относительно друга.
Порядок, в котором идут слова запроса, не учитывается.
Оператор скобки ()
Группировка слов при сложных запросах.
Внутри заключенной в скобки группы также могут быть использованы любые операторы.
Документные операторы Яндекса
- title: — поиск по заголовкам страниц
- url: — поиск по страницам на заданном URL, например url:aiwastudio.ru/blog/*
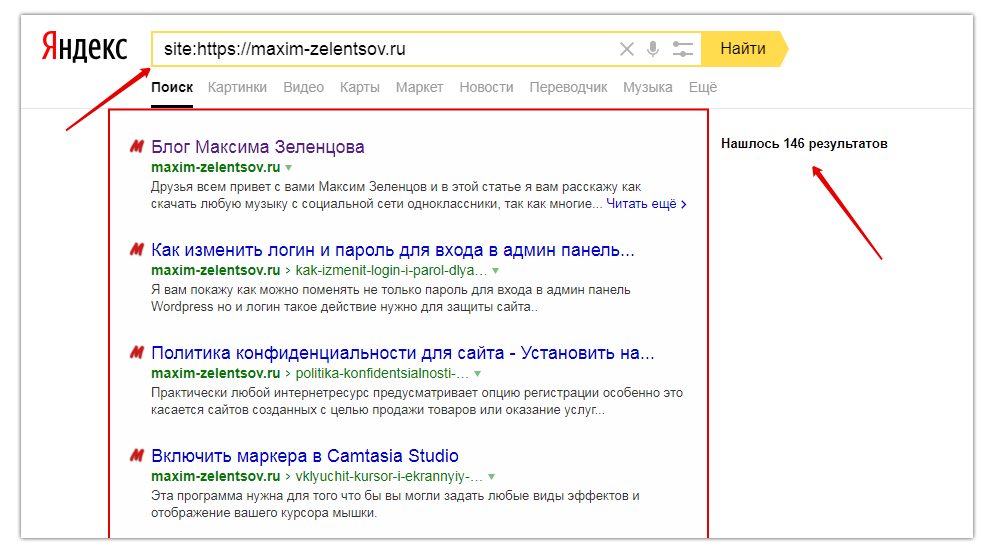
- site: — Поиск по всем поддоменам и страницам указанного сайта.
- inurl: — Поиск по страницам, размещенным на данном хосте. Идентичен оператору url: с заданным именем хоста.
- domain: — Поиск по страницам, расположенным на заданном домене.
- mime: -Поиск по документам в заданном типе файла.
- lang: — Поиск по страницам на заданном языке
- date: — Поиск по страницам с ограничением по дате их последнего изменения. Год изменения указывается обязательно. Месяц и день можно заменить символом *.
- cat: Поиск по страницам сайтов, зарегистрированных в Яндекс.Каталоге, тематическая рубрика или регион которых совпадают с заданным.
Перечисленные выше операторы не обязательно запоминать, т.к. расширенные поиск Яндекса по сути является интерфейсом к этим операторам. Т.е. вы сможете выбирать настройки поисковой формы и получать результат, как будто вводили операторы вручную.
Теперь недокументированные операторы:
- Intext – ищет только те документы, текст которых содержит слова запроса, т.е. не в метатегах или еще где-то, а именно в тексте.
- image – ищет все документы, в которых содержится изображение с заданным именем.
- Anchormus – ищет ссылки на музыкальные файлы, содержащие указанный запрос в анкоре
- Linkmus – ищет все страницы, с которые есть ссылка на указанный музыкальный файл
- Inlink – для поиска в тексте ссылок
- Linkint – поиск внутренних ссылок на определенный документ
- Anchorint – поиск документов, содержащих указанный запрос в текстах своих ссылок на свои внутренние документы
- idate — ищет документы с заданной датой последней индексации.
- style – поиск по значению атрибута stylesheet тега link
- applet – поиск по значению атрибута code тега applet:
- script — поиск по значению атрибута src тега script
- object – поиск по содержимому атрибутов тега object
- action – поиск по значению атрибута action тега form
- profile – поиск по значению атрибута profile тега head
- inpos — поиск текста в пределах заданных позиций элементов на странице(inpos:0..100)
Операторы поиска для Google
- Оператор «..» две точки — Используется для поиска диапазонов между числами.
- Оператор «@» — Для поиска по тегам в соц. Сетях
- Оператор «#» — Поиск по хештегам
Документные операторы Google
- site: аналогично Яндексу ищет по указанному сайту или домену
- link: поиск страниц, ссылающихся на указанный сайт
- related: поиск страниц со схожим содержимым
- info: С помощью этого оператора можно получить сведения о веб-адресе, в том числе ссылки на кешированную версию страницы, похожие сайты, а также страницы, ссылающиеся на указанную вами.
- cache: просмотр кешированной версии страницы
- filetype: поиск в указанных типах файлов, можно указать расширение
- movie: поиск информации о фильмах
- daterange: поиск страниц проиндексированных за указанный промежуток времени
- allintitle: поиск страниц, у которых слова из запроса находятся в title
- intitle: тоже самое, но часть запроса может содержаться и в другой части страниц
- allinurl: поиск страниц, содержащих все слова запроса в url
- inurl: тоже самое, но для одного слова
- allintext: только в тексте
- intext: для одного слова
- allinanchor: поиск по словам в анкорах
- inanchor:
- define: поиск страниц с определением указанного слова
Если есть чем дополнить, или какие-то операторы уже не работают – пишите в комментариях.
Операторы поисковой системы Bing
- contains: Оставляет результаты с сайтов, которые содержат ссылки на типы файлов, которые вы указываете
- ext: Возвращает только веб-страницы с расширением, которое вы указываете
- filetype: Возвращает только веб-страницы, созданные с типом файла, который вы указываете
- inanchor: или inbody: или intitle: эти ключевые слова возвращают веб-страницы с заданным термином в метаданных, например якоре, тексте и названии сайта
- ip: Находит сайты, которые размещены по определенному IP-адресу
- language: Возвращает веб-страницы на определенном языке
- loc: или location: Возвращает веб-страницы из определенной страны илирегиона
- prefer: Дает приоритет условию поиска или другому оператору, чтобы cосредоточить результаты поиска.
- site: Возвращает веб-страницы, которые принадлежат указанному сайту.
- feed: Находит каналы RSS или Atom на веб-сайте по терминам, которые вы ищете.
- hasfeed: Находит веб-страницы с каналами RSS или Atom на веб-сайте по терминам, которые вы ищете.
- url: Проверяет, есть ли указанный домен или веб-адрес в индексе Bing.

← Программа для раскрутки страниц ВконтактеSEO правила для создания сайта →
специалист по SEO продвижению
google rich snippets — Микроданные для словаря: могу ли я использовать yandex
спросил
Изменено
6 лет, 1 месяц назад
Просмотрено
285 раз
Я готов использовать микроданные/микроформат/и т. д. для той части моего веб-сайта, которая представляет собой онлайн-словарь. По сути, я просто хочу пометить слово и определение, чтобы помочь поисковым системам получить наиболее важные данные на каждой странице, принадлежащей словарю, и, возможно, заставить Google использовать их как «расширенные фрагменты» на странице результатов.
д. для той части моего веб-сайта, которая представляет собой онлайн-словарь. По сути, я просто хочу пометить слово и определение, чтобы помочь поисковым системам получить наиболее важные данные на каждой странице, принадлежащей словарю, и, возможно, заставить Google использовать их как «расширенные фрагменты» на странице результатов.
Основная проблема заключается в том, что трудно найти специальный словарь для слов и определений (но не проблема для рецептов, фильмов и отелей), и я не уверен, нужно ли мне использовать дерево «http://schema.org/Article» для моей лексикографической работы. (На мой взгляд, имеет смысл пометить что-то, когда оно достаточно конкретное).
Нашел кое-что интересное в яндексе, для слов и энциклопедии, хочу спросить что делать. Смотрите там:
https://yandex.ru/support/webmaster/microdata/what-is-microdata.xml?lang=ru
https://yandex.com/support/webmaster/microdata/term-definition-markup.xml
Похоже, это очень похоже на мою просьбу. Но извините, я не знаю, что такое Яндекс. .. будет ли он работать с Google?
.. будет ли он работать с Google?
Вот и спрашиваю, эта страница от яндекса рабочая модель, используется до сих пор, какие плюсы и минусы? Сможет ли Google использовать специальный словарь Яндекса и понимать мои данные с тегами Яндекса? стоит ли использовать этот словарь для онлайн-словаря, или я пропустил что-то еще более полезное?
(http://webmaster.yandex.ru/vocabularies/term-def.xml, который должен быть адресом словаря, дает мне 404).
Еще один вопрос, пожалуйста: могу ли я писать (дублировать) наиболее важные данные в заголовке, что-то вроде (я думаю, что да, потому что инструмент тестирования микроданных Google доказывает, что может извлекать данные из этого кода):
Просто хочу отметить, что мне было интересно, хотя и не приятно, эти тесные обсуждения :
- https://webmasters. stackexchange.com/questions/55073/what-meta-tag-or-structured-data-should-i-use-for-a-dictionary-web-application
- schema.org и онлайн-словарь
 stackexchange.com/questions/55073/what-meta-tag-or-structured-data-should-i-use-for-a-dictionary-web-application
stackexchange.com/questions/55073/what-meta-tag-or-structured-data-should-i-use-for-a-dictionary-web-application- микроданные
- google-rich-snippets
- словарь
- yandex
Яндекс — это российская версия Google, и обычно они оба распознают и уважают реализации результатов поиска друг друга.
Эти статьи, на которые вы ссылаетесь, невероятно устарели; Я рекомендую вам искать более свежие источники, предпочтительно там, где определяемый термин использует правильный элемент HTML.
Вот адрес Яндекса с ошибкой 404, Wayback Machine — ваш друг!
Вернемся к более свежей документации/ресурсам, в данном случае правильным элементом по состоянию на 05.10.2016 является элемент . Я знаю, что вы хотите добавить семантику, но семантика — это подходящее место для начала, и я бы продолжил это, пометив весь словарь в элементе списка определений и поместив определение, обернутое в элементе определения, в
<дд> с.
Я бы не стал тратить время на поиск идеальной онтологии; реализовать [rel=»tag» микроформат для всех определений], вы всегда можете вернуться и добавить более желаемое.
Я написал об этом сообщение в блоге, но гораздо более ценным ресурсом является глоссарий HTML5 Doctor’s Glossary. распознать схему «просмотр-источник» мне не под силу)
Дополнительные ссылки/ресурсы:
Примеры определений микроформатов содержат несколько очень интересных идей/фрагментов кода
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Почему Яндекс называется Яндекс?
С более чем двадцатью тремя миллионами поисковых запросов в секунду неудивительно, что Google доминирует в том, как мы находим информацию. Что менее очевидно, так это то, что Google работает по всему миру с локализованными движками, созданными на 123 различных языках, от Багамских островов до Греции и Японии. Доступ к этим локализованным механизмам можно легко получить, введя код домена верхнего уровня (ccTLD) соответствующей страны. Например, если вы находитесь в России, вместо ввода google.com в браузере вы вводите google.ru. Но то, что у людей есть возможность «погуглить» по всему миру, не означает, что это всегда их первый выбор. На самом деле в России чаще встречается «его Яндекс» (Яндекс это). Яндекс — одна из крупнейших интернет-компаний в Европе, управляющая самой популярной поисковой системой в России, контролирующая 63% рынка, в то время как доля Google составляет около 26%. Доминирование Яндекса коренится в том, что движок был создан русскими для русских. Их локальная направленность приводит к более эффективному анализу намерений запроса, что приводит к лучшему разрешению запросов и общему улучшению качества поиска.
Что менее очевидно, так это то, что Google работает по всему миру с локализованными движками, созданными на 123 различных языках, от Багамских островов до Греции и Японии. Доступ к этим локализованным механизмам можно легко получить, введя код домена верхнего уровня (ccTLD) соответствующей страны. Например, если вы находитесь в России, вместо ввода google.com в браузере вы вводите google.ru. Но то, что у людей есть возможность «погуглить» по всему миру, не означает, что это всегда их первый выбор. На самом деле в России чаще встречается «его Яндекс» (Яндекс это). Яндекс — одна из крупнейших интернет-компаний в Европе, управляющая самой популярной поисковой системой в России, контролирующая 63% рынка, в то время как доля Google составляет около 26%. Доминирование Яндекса коренится в том, что движок был создан русскими для русских. Их локальная направленность приводит к более эффективному анализу намерений запроса, что приводит к лучшему разрешению запросов и общему улучшению качества поиска. Вы также можете возразить, что российские правила конкуренции и нормативно-правовая база не благоприятствуют Google.
Вы также можете возразить, что российские правила конкуренции и нормативно-правовая база не благоприятствуют Google.
Штаб-квартира компании находится в Москве, у нее есть поисковые ресурсы в Беларуси, Казахстане, Украине и Турции, а в 2010 году они запустили английскую версию. Судя по опыту конечного пользователя (в этом посте я не буду вдаваться в технические подробности), движки очень похожи, оба содержат домашние страницы без отвлекающих факторов, оба имеют ограниченное количество синих ссылок на страницах результатов поисковой системы (SERP) и оба отображают контекстную рекламу в верхней части страницы.
Почему он называется Яндекс?
До основания Яндекса Аркадий Волож и Аркадий Борковский занимались поисковыми технологиями в небольшой компании «Аркадия», разрабатывая программы для поиска по Библии, Классификатору товаров и услуг и Международному классификатору патентов». В 1993 году «Аркадия» стала подразделением компании CompTek International, которую также основал Аркадий Волож. Аркадия запустила новую версию поисковой программы, и они хотели дать ей оригинальное имя. Илья сел за лист бумаги и стал записывать слова, описывающие суть программы, проводя мозговой штурм вокруг слов «поиск» и «индекс». Так появилось слово «Яндекс»: сокращение от «Еще один iNdEXer». Волож предложил заменить первые две английские буквы русской буквой Я («Я»), которая соответствует английскому личному местоимению «I», сделав «Яндекс» двуязычным каламбуром на «индекс».
Аркадия запустила новую версию поисковой программы, и они хотели дать ей оригинальное имя. Илья сел за лист бумаги и стал записывать слова, описывающие суть программы, проводя мозговой штурм вокруг слов «поиск» и «индекс». Так появилось слово «Яндекс»: сокращение от «Еще один iNdEXer». Волож предложил заменить первые две английские буквы русской буквой Я («Я»), которая соответствует английскому личному местоимению «I», сделав «Яндекс» двуязычным каламбуром на «индекс».
СМОТРИТЕ ТАКЖЕ: Почему DuckDuckGo называется DuckDuckGo?
Согласно их сайту, «Яндекс как компания появился в 2000 году, через три года после запуска веб-портала yandex.ru. На тот момент в штате новой компании было всего 25 имен, и все данные, которые обрабатывал Яндекс, могли уместиться на одном сервере». Как и Google, Яндекс разработал впечатляющее портфолио продуктов, включая карты, браузеры, электронную почту, облачные сервисы, музыкальные сервисы и многое другое. Яндекс стал прибыльным в 2002 году, получая большую часть своих доходов от контекстной рекламы, и стал публичным на фондовой бирже NASDAQ в 2011 году.