Содержание
Проверка количества проиндексированных на сайте страниц в поисковых системах Яндекс и Google
Проверка количества проиндексированных страниц сайта и получение их списка может показаться на первый взгляд достаточно простой задачей, но есть некоторые нюансы, о которых расскажем ниже.
Самые простые способы посмотреть индексацию любого сайта – операторы в поисковых системах Яндекс и Google. В Google это оператор site:site.ru (где вместо site.ru нужно указать анализируемый сайт). В Яндексе последнее время оператор site:site.ru перестал корректно работать, поэтому на данный момент количество страниц можно проверить с помощью оператора url:http://www.site.ru/* (с указанием www если сайт индексируется с www и наоборот).
Примеры:
Как узнать число новых страниц на сайте или число страниц, проиндексированных за определенный период
В Яндексе можно нажать на иконку расширенного поиска и выбрать диапазон дат:
В Google аналогичные настройки можно сделать через “инструменты->за период”:
Но не все так просто как кажется на первый взгляд.
Рассмотрим более точные методы проверки способы как получить больше информации для каждой поисковой системы.
Google Search Console
Часто в Google число страниц, выдаваемое через оператор site: сильно отличается от реального числа проиндексированных страниц. Сотрудники Google отвечают по этому поводу что конструкция site:site.ru всего лишь результат пустого поиска по сайту и не обязана выдавать все страницы сайта.
Также в поиске отображаются неиндексируемые страницы, запрещенные в robots.txt, на которые есть внешние ссылки. Это тоже искажает результат.
Более точно узнать число проиндексированных страниц в Google можно имея доступ к Google Search Console в разделе “статус индексирования”.
К сожалению, в данном отчете данные также могут не совпадать с реальными из-за применения фильтров. Разница может доходить до десятков-ста процентов.
Еще один способ, который считается одним из наиболее точных – отчет “Файлы Sitemap”. Здесь указано точное число индексируемых страниц, но с учетом что все полезные страницы были добавлены в файлы sitemap. xml.
xml.
Яндекс Вебмастер
В Яндекс.Вебмастере содержатся достаточно точные данные по индексации сайта. Количество страниц, с динамикой можно посмотреть в разделе “страницы в поиске”.
Также в Яндекс.Вебмастере можно получить выгрузку страниц со статусами, включая индексацию, которая, правда ограничена 50.000 страницами. Пример выгрузки:
Выгрузку можно скачать в уже описанном выше отчете “страницы в поиске”.
Альтернативные способы проверки индексации сайта
Иногда перечисленные методы не подходят, тогда можно использовать альтернативные.
- Парсинг сайта (например, через программу Screaming Frog) и постраничная проверка индексации в Google/Yandex. Например, через сервис https://www.rush-analytics.ru/ -> “проверка индексации”. Минусы: не все страницы в индексе могут иметь ссылки из меню или страниц сайта, можно как дополнение использовать способы описанные в пунктах 2,3 ниже.
- Страницы, на которые есть органический трафик из перечисленных операционных систем (можно посмотреть через системы статистики Яндекс. Метрика и Google.Analytics).
- Страницы на которые есть внешние ссылки. Внешние ссылки можно получить через такие сервисы как Ahrefs.com.
 Метрика и Google.Analytics).
Метрика и Google.Analytics). Автор статьи:
Андрей Ставский
Руководитель SEO отдела
Смотреть все статьи Андрей Ставский
Как узнать сколько страниц проиндексировано в Яндекс и Google? – Проверить индексацию страниц поисковиками
Определить количество проиндексированных страниц в Яндекс или Google можно несколькими способами: с помощь специального запроса или посмотреть статистику в панели вебмастера
Tilda Publishing
Главная > Статьи > Как определить количество страниц в поиске?
Как узнать количество проиндексированных страниц с помощью запроса
В поисковой строке Яндекс или Гугл нужно набрать запрос следующего типа: site:домен.рф, где домен.рф – это адрес интересующего вас сайта. Например:
Например:
Проверка количества страниц в поисковой выдаче Яндекс с помощью запроса
Такой же запрос действует и в Google:
Проверка количества проиндексированных страниц в Goggle с помощью специального запроса
Гугл обычно показывает в поиске больше результатов. Это связано с тем, что Google быстрее добавляет новые страницы в поисковую выдачу.
Статистика индексирования в консоли вебмастера Яндекс и Google
Статистику индексирования и количество страниц можно посмотреть в консоли вебмастера:
Проверка количества проиндексированных страниц в консоли вебмастера
По данным консоли в поиске Яндекс 126 страниц, а с помощью запроса мы обнаружили 129. По данным техподдержки Яндекса – значение, которое мы видим в поиске – достовернее. А разница в количестве страниц может зависеть от настроек браузера, типа устройства и проведения работ на стороне Яндекса.
Также можно обратить внимание, что поисковой системой загружено больше страниц, чем добавлено в поиск. Загруженные страницы – это все страницы сайта, о которых известно поисковой систем, страницы в поиске – это все, что выводится в поиск.
Загруженные страницы – это все страницы сайта, о которых известно поисковой систем, страницы в поиске – это все, что выводится в поиск.
Страницы, которые не попадают в поиск:
- Дубликаты,
- Заспамленные страницы,
- Закрытые от индексирования.
- Содержащие бесполезный контент.
Также страницы могут не попадать в индекс по техническим ошибкам на стороне Яндекса. Если вы уверены, что на сайте ошибок нет, страница качественная, а в поиск она все никак не попадает – пишите в поддержку.
Как проверить проиндексированность конкретной страницы?
В Яндексе можно использовать поисковый оператор «url:». После двоеточия нужно указать полную ссылку страницы:
Как узнать проиндексирована ли страница в Яндексе?
В Яндексе оператор URL позволяет также проверять проиндексированность отдельных разделов сайта. Для этого нужно набрать в строке поиска такую конструкцию – url:домен. рф/раздел1/* — звездочка обозначает любое количество любых символов, поэтому в ответ на такой запрос Яндекс отобразить все страницы, ссылки которых начинаются на домен.рф/раздел1/, т.е. отобразить все проиндексированные страницы в первом разделе.
рф/раздел1/* — звездочка обозначает любое количество любых символов, поэтому в ответ на такой запрос Яндекс отобразить все страницы, ссылки которых начинаются на домен.рф/раздел1/, т.е. отобразить все проиндексированные страницы в первом разделе.
Чтобы определить проиндексирована ли страница в Google, нужно воспользоваться оператором «site:», а после двоеточия указать полную ссылку на страницу:
Проверка индексации страницы в Google
Следите за тем, чтобы количество страниц в поиске Яндекс и Google было примерно одинаковым. Поисковые системы использую разные алгоритмы, поэтому разница в индексе может достигать 10-15%. Если у вас разница больше, нужно провести SEO-аудит и выяснить причину.
Поисковая оптимизация сайта на WIX
Продвижение сайта на WIX вполне реально. Конструктор соответствует минимальным требованиям для базовой оптимизации. При правильном подходе возможно вывести сайт на WIX в топ
Какую CMS лучше выбрать для интернет-магазина?
Выбор правильного движка для интернет-магазина отразиться на работе сайта, поисковой оптимизации, удобстве проекта для пользователей и бюджете на разработку
Что такое движок сайта?
Движок сайта – это программное обеспечение, которое позволяет управлять контентом сайта без знания языков программирования
Что такое посадочная страница?
Посадочная страница – это страница входа посетителей на ваш сайт, спроектированная таким образом, чтобы получать максимум заявок от посетителей
Базовый аудит рекламных кампаний в Яндекс Директ
Быстрый аудит рекламных кампаний в Яндекс Директе можно использовать в качестве проверки профессионализма агентства или фрилансера, который настраивал рекламу
Настройка корректировки ставок в системе контекстной рекламы Яндекс Директ
Корректировка ставок в Яндекс Директ позволяет уменьшать или увеличивать стоимость клика в зависимости от признаков целевой аудитории. Правильная корректировка ставок в Директе
Правильная корректировка ставок в Директе
Бесплатная консультация
Мы создаем и раскручиваем сайты, ведем аналитику и размещаем рекламу в интернете. Задайте нам вопрос по любой из этих тем
| Написать |
Малоценные страницы или страницы с низким спросом — Веб-мастер. Справка
База данных поиска Яндекса содержит данные о многочисленных страницах. Пользовательский поисковый запрос может возвращать большое количество результатов, релевантных в большей или меньшей степени.
Алгоритм может принять решение не включать страницу в результаты поиска, если спрос на эту страницу, вероятно, будет низким. Например, это может произойти, если страница является дубликатом уже известных роботу страниц, если на странице нет контента или если ее контент не полностью соответствует запросам пользователей. Алгоритм автоматически проверяет страницы на регулярной основе, поэтому его решение включать или не включать определенную страницу в поиск может меняться со временем.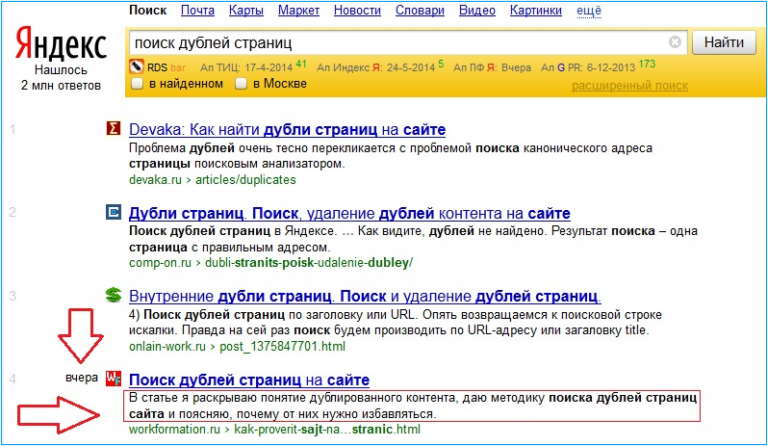
Чтобы просмотреть страницы, исключенные из результатов поиска, откройте Яндекс.Вебмастер, перейдите в раздел Индексирование → Страницы в поиске (Исключенные страницы) и найдите страницы со статусом «Малоценная или маловостребованная страница».
При выборе страниц алгоритм учитывает множество факторов. Исходя из этого, страницы, исключенные из результатов поиска, можно разделить на следующие типы:
Страница может считаться малоценной, если она является дубликатом другой страницы или не содержит контента, видимого роботу.
- Как исправить
Проверьте содержимое страницы и ее доступность для робота:
Убедитесь, что заголовки страницы (название, h2, h3 и т.д.) указаны правильно и хорошо описывают ее содержимое.
Проверьте наличие важного содержимого в виде изображения.
Убедитесь, что сценарии JS не используются для отображения важного содержимого.
Проверьте ответ сервера, чтобы увидеть HTML-код страницы в том виде, в каком его получает робот.Убедитесь, что iframe не используется для отображения содержимого.
Если страница не имеет значения, ее лучше скрыть от индексации:
Если страница дублирует содержимое других страниц сайта, используйте директиву rel=»canonical» для указания исходную страницу или указать несущественные GET-параметры в директиве Clean-param в файле robots.txt. Вы также можете отключить индексирование страниц с помощью перенаправления HTTP 301, инструкций в файле robots.txt, метатега noindex или HTTP-заголовка.
Если страница техническая и не содержит полезного контента, запретите ее индексацию с помощью директивы Disallow в robots.txt, метатега noindex или HTTP-заголовка.
 Проверьте ответ сервера, чтобы увидеть HTML-код страницы в том виде, в каком его получает робот.
Проверьте ответ сервера, чтобы увидеть HTML-код страницы в том виде, в каком его получает робот. Робот Яндекса проверяет, востребован ли контент страницы. Наш алгоритм оценивает каждую страницу, чтобы выяснить, появится ли она в результатах поиска на тех позициях, где ее могут найти пользователи. Если на странице нет ошибок в HTML-коде, есть контент, но в поиске нет ни пользователей, ни запросов, на которые она могла бы ответить, эта страница может быть исключена из результатов поиска как малозапрашиваемая.
Если на странице нет ошибок в HTML-коде, есть контент, но в поиске нет ни пользователей, ни запросов, на которые она могла бы ответить, эта страница может быть исключена из результатов поиска как малозапрашиваемая.
- Как исправить
Если некоторые страницы исключаются из результатов поиска, несмотря на наличие контента, обратите внимание на этот контент. Он может не соответствовать запросам пользователей. В этом случае попробуйте отредактировать контент, чтобы он лучше соответствовал интересам пользователей.
Поставьте себя на место потенциальных посетителей сайта. Как бы вы попытались найти информацию по заданной теме? Какой поисковый запрос вы могли бы использовать? Для поиска актуальных тем используйте сервис статистики ключевых слов, а также инструменты на следующих страницах Яндекс.Вебмастера: Статистика запросов, Управление группами и Рекомендуемые запросы.
Алгоритм не ограничивает сайт в результатах поиска. Например, если какая-либо ранее исключенная страница обновляется и становится доступной для отображения в результатах поиска, алгоритм проверяет ее снова.
Примечание. У Яндекса нет квот на количество страниц, которые должны быть включены в индекс. Все страницы, которые алгоритм считает полезными для пользователей, индексируются независимо от их количества.
Смотрите наши рекомендации:
Какие ответы дает ваш сайт?
Представление информации на сайте
Страницы иногда появляются и исчезают из результатов поиска
Наш алгоритм регулярно проверяет все страницы, почти каждый день. Результаты поиска могут меняться, поэтому может меняться и релевантность страниц в результатах поиска, даже если их содержание остается прежним. В этом случае алгоритм может решить исключить страницы из поиска или вернуть их.
Страницы настроены на выдачу кода ответа HTTP 403/404 или используется элемент noindex, но ссылки исключены как малозапросные
Алгоритм не переиндексирует страницы, а проверяет содержимое страниц, которые в данный момент находятся в базе данных. Если страницы ранее были доступны, ответили кодом статуса 200 OK и были проиндексированы, алгоритм может продолжать индексировать их до тех пор, пока робот снова не посетит эти страницы и не отследит изменения в коде ответа.
Если страницы ранее были доступны, ответили кодом статуса 200 OK и были проиндексированы, алгоритм может продолжать индексировать их до тех пор, пока робот снова не посетит эти страницы и не отследит изменения в коде ответа.
Если вы хотите, чтобы такие страницы удалялись быстрее, запретите им индексацию в файле robots.txt сайта. После этого ссылки автоматически исчезнут из базы робота в течение двух недель.
Если это сделать не удается, см. рекомендации в разделе Индексирование.
На сайте есть похожие страницы, но одна страница включена в результаты поиска, а другая нет
При проверке страниц алгоритм оценивает очень большое количество факторов ранжирования и индексации. Решения для разных страниц, даже с очень похожим содержанием, могут различаться. Возможно, что похожие страницы отвечают на один и тот же запрос пользователя, поэтому алгоритм включает в результаты поиска только ту страницу, которую он считает наиболее релевантной.
На нашем сайте есть страницы, которые не должны быть проиндексированы, но они исключены как страницы с низким спросом
Количество исключенных таким образом страниц не оказывает негативного влияния на рейтинг сайта. Однако, если эти страницы удалить как маловостребованные, они остаются доступными и могут принимать участие в поиске. Это означает, что алгоритм может включить их в результаты поиска. Если вы уверены, что такие страницы не нужны в поиске, лучше запретить их индексацию.
Почему дубликаты были исключены как страницы с низким спросом?
Содержимое страниц может незначительно отличаться или динамически меняться, поэтому такие ссылки не могут считаться дубликатами. Однако из-за схожести контента страницы могут конкурировать друг с другом в поиске и дублировать друг друга, что делает одну из них менее популярной.
Расскажите, о чем ваш вопрос, чтобы мы могли направить вас к нужному специалисту:
Страницы с разным содержанием могут считаться дубликатами, если они ответили роботу сообщением об ошибке (например, в случае страницы-заглушки на сайте). Проверьте, как страницы реагируют сейчас. Если страницы возвращают другой контент, отправьте их на переиндексацию — так они быстрее вернутся в результаты поиска.
Проверьте, как страницы реагируют сейчас. Если страницы возвращают другой контент, отправьте их на переиндексацию — так они быстрее вернутся в результаты поиска.
Чтобы предотвратить исключение страниц из поиска, если сайт временно недоступен, настройте код ответа HTTP 503.
Как оптимизировать краулинговый бюджет для Google и Яндекс
Поисковые системы не обновляют свои базы данных мгновенно. Процесс индексации может занять недели или даже месяцы. Это определенно не будет хорошо для SEO. Давайте разберемся, что такое краулинговый бюджет и почему его нужно оптимизировать.
Что такое краулинговый бюджет
Краулинговый бюджет — это количество страниц, которые бот поисковой системы просматривает на вашем сайте за один раз. Другими словами, он показывает, сколько новых и обновленных страниц вы можете предоставить поисковому роботу за одно посещение.
Этот номер может немного меняться, но он достаточно стабилен. Важно понимать, что лимит отличается от сайта к сайту. Старый и популярный сайт сканируется постоянно, а любой новый веб-ресурс сканируется частично и с задержками.
Старый и популярный сайт сканируется постоянно, а любой новый веб-ресурс сканируется частично и с задержками.
Причина проста: ресурсы поисковых систем ограничены. Никогда не будет достаточно центров обработки данных, чтобы мгновенно отслеживать каждое изменение на миллиардах веб-сайтов по всему миру. Особенно когда речь идет о бесполезных и непопулярных веб-ресурсах. Когда бот сканирует некачественные страницы, краулинговый бюджет уменьшается. Это негативно повлияет на ранжирование вашего сайта.
Какое это вообще имеет значение: поисковый робот сканирует заданное количество страниц случайным образом. Вы не можете вручную заставить его сканировать определенные URL-адреса. Например, ваша страница «О нас» может получить больше просмотров, чем новая категория продуктов с новейшими предложениями.
Можете ли вы повлиять на поисковые системы, чтобы улучшить свой краулинговый бюджет? Да, в некоторой степени. Ниже мы рассмотрели основные методы оптимизации краулингового бюджета.
Как работает веб-сканирование
Робот поисковой системы получает список URL-адресов на вашем веб-сайте для сканирования и время от времени сканирует их. Как создается этот список? Он формируется на основе следующих элементов:
- Внутренние ссылки на вашем сайте, включая инструменты навигации.
- Карта сайта в формате XML (sitemap.xml).
- Внешние ссылки.
Файл Robots.txt сообщает роботам поисковых систем, какие страницы вашего веб-сайта следует сканировать. Роботы проверяют текстовый файл, чтобы узнать, можно ли просканировать определенный URL-адрес. Если URL-адрес не указан в файле, он будет добавлен в список сканирования. Тем не менее, обратите внимание, что инструкции в файле robot.txt не являются обязательными для ботов, сканирующих веб-страницы. Это только предложение и рекомендация. В некоторых случаях URL-адрес все равно будет проиндексирован. Например, если ссылки указывают на него или перенаправляют на эту страницу в индексе, или любые другие сигналы, которые заставляют поисковый робот думать, что URL-адрес необходимо просканировать. В результате страница все равно будет просканирована и Google пришлет вам предупреждение «Проиндексировано, но заблокировано robots.txt».
В результате страница все равно будет просканирована и Google пришлет вам предупреждение «Проиндексировано, но заблокировано robots.txt».
Гэри Иллиес объяснил процесс сканирования ботами Google. Google генерирует список URL-адресов и сортирует их по приоритету. Сканирование выполняется сверху вниз по списку.
Как вы определяете приоритеты? – Во-первых, Google учитывает PageRank страницы. Среди прочих факторов — карта сайта, ссылки и многое другое.
Как только поисковый робот сканирует URL-адрес и анализирует его содержимое, он добавляет в список новые URL-адреса для их сканирования (немедленно или позже).
Не существует надежного способа составить список причин, по которым бот веб-краулера будет сканировать URL-адрес и почему он этого не сделает. Однако если он решит просканировать страницу, то обязательно это сделает. В конце концов. Когда именно это произойдет, частично зависит от вас.
Как определить проблему обхода бюджета?
Когда робот поисковой системы найдет много ссылок на вашем сайте и даст вам большой краулинговый бюджет, то у вас не возникнет проблем. Но что, если ваш сайт состоит из сотен тысяч страниц, а краулинговый бюджет невелик? В этом случае вам придется месяцами ждать, пока поисковая система заметит какие-либо изменения на вашем сайте.
Но что, если ваш сайт состоит из сотен тысяч страниц, а краулинговый бюджет невелик? В этом случае вам придется месяцами ждать, пока поисковая система заметит какие-либо изменения на вашем сайте.
Вот что вы можете сделать, чтобы выяснить, есть ли у вас проблемы с бюджетом на сканирование:
- Определите, сколько страниц на вашем веб-сайте следует проиндексировать (эти страницы не должны иметь метатег NOINDEX или быть перечислены в файле robots. .txt-файл).
- Сравните количество проиндексированных страниц с общим количеством страниц на вашем сайте с помощью инструментов Google и Яндекс для веб-мастеров.
- В зависимости от поисковой системы выберите инструмент «Статистика сканирования» или отчет «Статистика сканирования». Google работает методично и обычно просматривает страницу за страницей сайта. При этом явной системы у Яндекса нет (см. скриншот). Иногда вообще не сканирует сайт или сканирует только некоторые страницы.
- Разделите количество страниц на среднее количество просканированных страниц за день. Если результат в 10 раз превышает количество страниц, сканируемых поисковым роботом в день, вам необходимо оптимизировать краулинговый бюджет. Если ваше число меньше 3, все в порядке.
 Если результат в 10 раз превышает количество страниц, сканируемых поисковым роботом в день, вам необходимо оптимизировать краулинговый бюджет. Если ваше число меньше 3, все в порядке.
Если результат в 10 раз превышает количество страниц, сканируемых поисковым роботом в день, вам необходимо оптимизировать краулинговый бюджет. Если ваше число меньше 3, все в порядке.Полезно сравнить количество страниц в поисковых индексах Google и Яндекс. Обходные пути для этих систем разные, но разница должна быть незначительной. Кроме того, различия в наборе данных этих панелей для веб-мастеров помогут вам получить больше информации и идей.
Как улучшить краулинговый бюджет
Этот абзац содержит множество моментов, которые следует учитывать. Поэтому мы начнем от самых простых до самых сложных. Тем не менее, все эти методы эффективны.
Общий принцип, который необходимо усвоить, заключается в том, что любая ранее проиндексированная страница, которую бот-робот не может просканировать несколько раз подряд, удаляется из поискового индекса. Это касается как страниц, недоступных по техническим причинам (например, ошибка 500), так и страниц, которые намеренно заблокированы от индексации — например, тегом NOINDEX.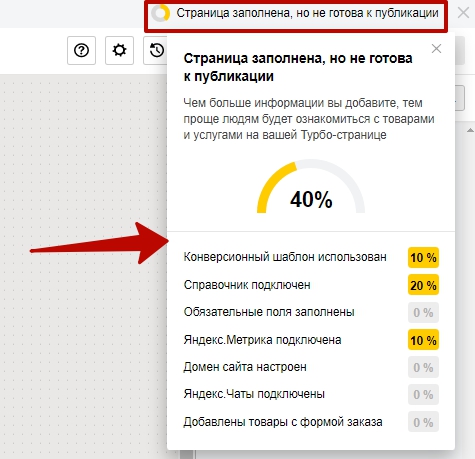
Google требует много времени для деиндексации страниц. Он длится месяц. В течение этого времени Google периодически проверяет, доступна ли страница. Яндекс быстрее деиндексирует «битую» страницу. Однако он будет продолжать многократно индексировать и деиндексировать его, пока вы не устраните проблемы.
Устранение неполадок
Для правильно настроенного веб-сайта существует только два типа действительных ответов сервера: 200 (ОК) и 301 (постоянная переадресация). Обратите внимание, что первое должно значительно превалировать над вторым. Все остальные ответы требуют тщательного рассмотрения и исправления, и вот почему.
- Если вы по какой-то причине использовали временные 302 редиректы вместо постоянных 301 редиректов, то поисковый бот будет вести себя соответствующим образом: поскольку контент временно недоступен, поисковая система его не удалит. Вместо этого он будет периодически перепроверять страницу. Таким образом, вы просто тратите свой краулинговый бюджет.
- Второй пример — использование ошибки 404 (не найдено) вместо ошибки 410 (ошибка пропала). Логика проста: если страницу удалить, система попытается деиндексировать и забыть о ней. В случае ошибки 404 сканеры сайта запланируют повторную проверку страницы позже.
- 500 ошибок — это самое худшее. Они являются явным признаком некачественного ресурса. Из-за этих ошибок ограничение скорости сканирования снижается. В результате роботы-сканеры сканируют ваш сайт все реже и реже.

Если вы видите это в своих логах или отчетах SiteAnalyzer, Screaming Frog SEO Spider или их аналогов, выясняйте причины и принимайте срочные меры.
Еще одним важным источником информации об ошибках являются инструменты для веб-мастеров. Используйте их для мониторинга самых важных страниц, чтобы получать уведомления об ошибках и быстро их исправлять.
Избавьтесь от ненужных файлов и дублированного контента
Индекс поисковой системы не должен включать страницы услуг, страницы клиентов, которые дублируют другие страницы, страницы фильтров, сравнения продуктов, страницы с параметрами UTM и черновые страницы.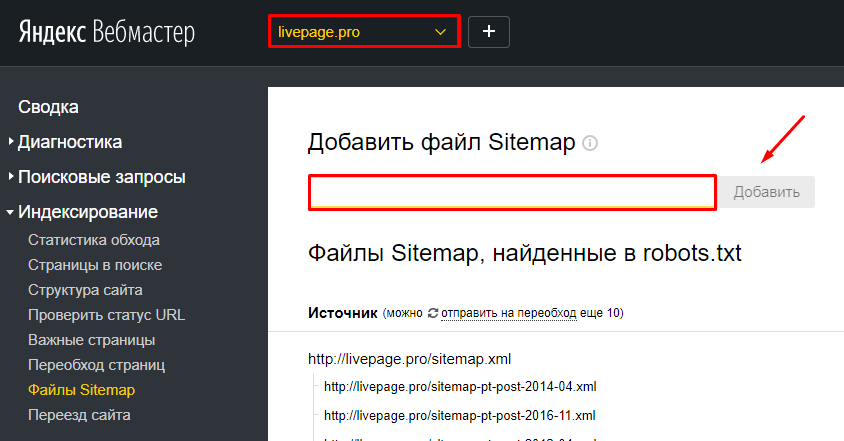 Остановите индексацию этих страниц с помощью файла robots.txt.
Остановите индексацию этих страниц с помощью файла robots.txt.
Интернет-магазины больше всего страдают от дублирования контента. Дублированный контент означает, что похожий контент доступен в нескольких местах (URL) в Интернете, и в результате поисковые системы не знают, какой URL показывать в результатах поиска. Иногда Google индексирует страницы продуктов и даже сеансы клиентов, включая продукты из корзины.
Главное правило — хранить только одну версию каждого URL!
Иногда удалить дублирующийся контент просто невозможно. В таких ситуациях вы можете использовать канонические теги, которые сообщают поисковым роботам, какие страницы следует проиндексировать, а какие страницы следует игнорировать. В этом случае канонический тег действует как мягкая переадресация 301.
Вот пример такого случая: карточка товара попадает в две разные категории товаров и отображается с разными URL. Похоже, у вас есть две одинаковые страницы с разными URL-адресами. Поисковые системы могут рассматривать одну из этих страниц как дубликат другой и индексировать только главную страницу. Однако затем они могут снова проиндексировать обе страницы. А затем удалить один из них из поискового индекса. Чтобы избежать этого и перестать тратить краулинговый бюджет впустую, используйте канонические теги, если система управления сайтом не предлагает лучшего решения.
Однако затем они могут снова проиндексировать обе страницы. А затем удалить один из них из поискового индекса. Чтобы избежать этого и перестать тратить краулинговый бюджет впустую, используйте канонические теги, если система управления сайтом не предлагает лучшего решения.
Другой возможный вариант — использовать метатег NOINDEX. Имейте в виду, однако, что такие страницы все равно сканируются, просто реже, чем обычно. Таким образом, краулинговый бюджет продолжает уменьшаться. Кстати, не забудьте добавить к тегу NOINDEX атрибут Follow. Таким образом вы предотвратите накопление PageRank такими страницами.
Если вы хотите раз и навсегда избавиться от дублированного контента, вам придется предпринять более кардинальные меры, чем использование метадиректив для поисковых роботов. Рассмотрите возможность удаления дублирующегося контента, если это возможно.
Например: вы можете использовать варианты одного и того же товара, которые немного отличаются друг от друга (цвет, размер и другие параметры).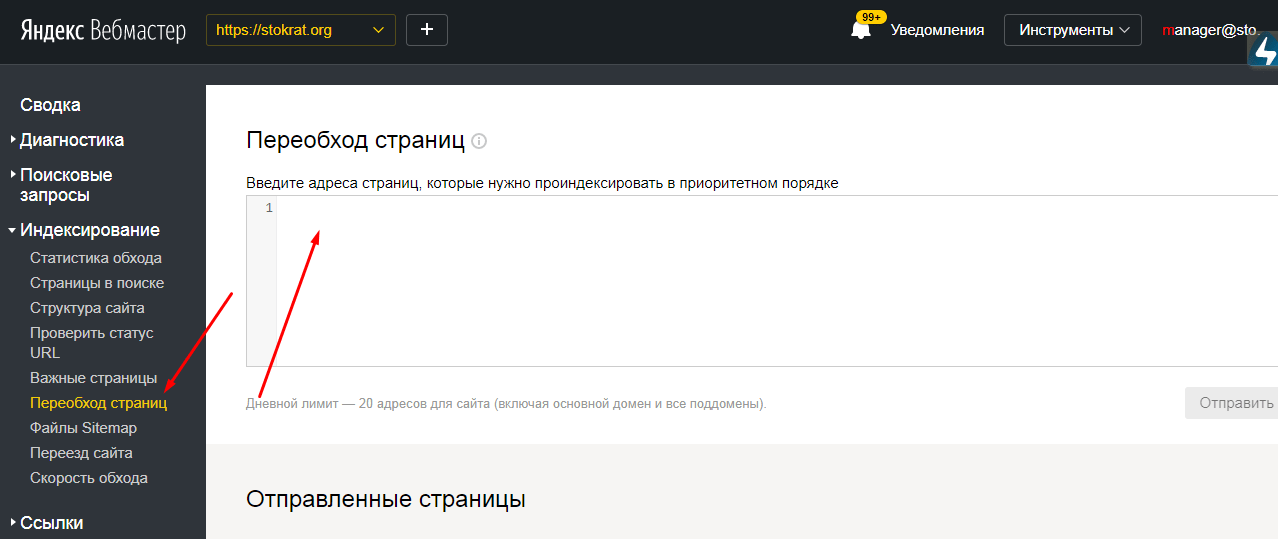
Минимизация редиректов
Первое, что необходимо сделать при проведении технического SEO-аудита сайта, — это проверить редиректы главной страницы. Он может быть доступен через HTTP или HTTPS, а также может иметь URL-адреса, отличные от WWW и WWW. Это дубликаты одной и той же домашней страницы. Поисковая система может выбрать любое перенаправление в качестве основного. Вы потеряете контроль и потратите свой краулинговый бюджет. Вот почему вы должны настроить переадресацию 301 (постоянную) на правильную версию.
Кроме того, вам нужно убедиться, что вы используете только одно перенаправление, которое используется между начальным URL-адресом и URL-адресом назначения. Неправильные настройки перенаправления могут привести к цепочке из двух или трех перенаправлений. Это плохо, и вот почему. Поисковый робот видит новые URL-адреса и добавляет их в свой список URL-адресов для сканирования. Тем не менее, это не означает, что он будет проверять эти URL-адреса немедленно. Чем длиннее цепочка редиректов, тем дольше процесс. В результате сканирование задерживается.
Чем длиннее цепочка редиректов, тем дольше процесс. В результате сканирование задерживается.
Вот типичный пример плохой переадресации HTTPS:
Уменьшение ссылочного веса — еще одна проблема, связанная с чрезмерными переадресациями. Ссылочный вес уменьшается с каждым перенаправлением, что снижает эффективность линкбилдинга.
Домашняя страница — не единственное место, где вы должны проверять наличие двойных перенаправлений. Если вы столкнулись с множеством проблем при анализе просмотров страниц, не забудьте выполнить тест редиректа.
Создание карты сайта в формате XML
Карта сайта должна содержать полный список страниц веб-сайта, которые должны быть проиндексированы. Только важное! Поисковые системы используют его как средство навигации и получают от него список URL-адресов для обхода. Файл sitemal.xml может содержать информацию о дате создания, дате последнего изменения, приоритете важности, скорости сканирования и многом другом.
Не думайте, что поисковый робот всегда учитывает ваши инструкции. Вы можете только надеяться, что робот увидит ваш список URL-адресов для сканирования и в конечном итоге использует его. Все остальное обычно игнорируется, чтобы избежать манипуляций. Однако это не означает, что вы не должны использовать эти директивы. Делайте то, что можете, но не ждите 100% эффекта.
Вы можете только надеяться, что робот увидит ваш список URL-адресов для сканирования и в конечном итоге использует его. Все остальное обычно игнорируется, чтобы избежать манипуляций. Однако это не означает, что вы не должны использовать эти директивы. Делайте то, что можете, но не ждите 100% эффекта.
Не каждая CMS позволяет создать карту сайта в соответствии с вашими планами. Он может включать в себя много нежелательных элементов. Что еще хуже, некоторые CMS даже не позволяют создавать карты сайта. В таких случаях вы можете использовать сторонний плагин или вручную отправить карту сайта, созданную с помощью программного обеспечения или внешней службы.
Некоторые эксперты рекомендуют удалять все URL-адреса из карты сайта, как только страницы будут проиндексированы. Не делайте этого, так как это может повредить вашему краулинговому бюджету.
Время от времени проверяйте файл sitemap.xml. В файле не должно быть удаленных страниц, перенаправлений и URL-адресов ошибок.
Создайте хорошую структуру веб-сайта
Это, вероятно, самый сложный шаг. Реструктуризация работающего веб-сайта будет непростой задачей. Создать правильную структуру сайта на стадии разработки намного проще.
Плоская структура сайта — это веб-сайт, все страницы которого находятся на расстоянии четырех или менее кликов от главной страницы. Глубинная иерархия сайтов имеет пять или более подуровней.
Общий принцип: глубокие и сложные структуры сайта сканировать труднее, чем плоские. Кроме того, они менее удобны для посетителей. Добавьте неэффективную навигацию и отсутствие мобильной оптимизации, и вы получите полный набор проблем с SEO.
Используйте передовой опыт плоской структуры сайта, чтобы сделать важные страницы доступными всего за несколько кликов. Плоская горизонтальная конструкция предпочтительнее вертикальной.
Однако обратите внимание, что плоская структура без категорий также неэффективна. Вам необходимо спроектировать структуру, которая сочетала бы в себе простоту и непротиворечивость иерархии. Впрочем, эта тема требует отдельного разговора.
Впрочем, эта тема требует отдельного разговора.
Вам нужно будет использовать нетривиальные методы, выходящие за рамки технического SEO, для оптимизации структуры вашего сайта. Начать следует с визуализации существующей структуры. Многие инструменты аудита веб-сайтов могут помочь вам в этом. На этом этапе можно приступать к небольшим корректировкам.
Если вы планируете вносить глобальные изменения, начните с семантики и группировки запросов. Определите, что можно соединить, объединить или поднять на уровень выше. Возможно, вы можете удалить некоторые страницы полностью.
Обратите внимание , что Google и Яндекс ранжируют сайты по-разному. Ваш рейтинг Google не будет высоким, если у вас будет куча спам-страниц. В то же время Яндекс ранжирует более крупные сайты выше, даже если их содержание не является первоклассным. Поэтому придется искать компромисс.
Используйте заголовок Last-Modified
Большинство разработчиков веб-сайтов и системных администраторов игнорируют этот важный технический параметр. К сожалению, даже некоторые SEO-специалисты не понимают важности последнего измененного заголовка ответа.
К сожалению, даже некоторые SEO-специалисты не понимают важности последнего измененного заголовка ответа.
Заголовок Last-Modified используется для:
- снижения нагрузки на сервер;
- ускорить индексацию сайта;
- улучшить скорость загрузки сайта.
Последний измененный заголовок ответа особенно важен, если ваш сайт большой и вы ежедневно его обновляете. Однако многие веб-мастера вообще его не используют.
Как работает заголовок Last-Modified
Поисковый робот или браузер обращается к определенному URL-адресу, запрашивая веб-страницу. Если он не изменился с момента последнего взаимодействия, сервер возвращает заголовок «304 Not Modified». В этом случае нет необходимости повторно загружать уже проиндексированный контент. Однако, если были изменения, то сервер отправит ответ «200 OK», и новый контент будет загружен.
Помимо повышения производительности поисковая система обновляет дату содержимого страницы. Это очень важно с точки зрения рейтинга, особенно для областей, связанных со здоровьем и финансами человека (YMYL).
Last-Modified позволяет сканеру удалить некоторые страницы из своего списка, которые не были обновлены. Он сканирует обновленные страницы, оптимизированные вами. Вы помогаете расставлять приоритеты и экономите краулинговый бюджет.
Примечание. Используйте заголовок Last-Modified на страницах с наиболее статичным содержимым. Сквозной блок с обновленным содержимым — это не то, чем является обновленное содержимое, и сканеру это может не понравиться. Как минимум сократите количество таких блоков на лендингах. То, что хорошо работает на главной странице, не требуется на других целевых страницах.
Вы можете использовать средство проверки ответа заголовка HTTP или аналогичные инструменты для проверки этого заголовка.
Улучшить ссылочный профиль
Если есть проблемы с индексацией веб-сайта, следует проверить ссылочный профиль. Улучшение ссылочного профиля — самый медленный и сложный способ оптимизации краулингового бюджета, но очень полезный.
Обратите внимание, что мы говорим не только о внешних ссылках. Внутренние ссылки также ускоряют индексацию. Когда сканер поисковой системы получает ссылку на часто просматриваемую страницу, новая страница будет проиндексирована быстрее.
То же самое относится и к ссылочному капиталу, который передается по внутренним ссылкам. Чем больше ссылок ведут на страницу — тем выше ее важность для бота. Разумно распределяйте ссылочный вес.
Страницы, ссылающиеся на самих себя, «висячие узлы» и страницы-сироты
Эти ошибки напрямую связаны с внутренними ссылками и вызывают проблемы с индексацией и сканированием. К счастью, эти проблемы легко решить.
Простейшим примером страницы, ссылающейся на саму себя, является хлебная крошка, которая указывает, где находится пользователь на сайте. Он не обязательно должен быть кликабельным — вы можете использовать его только для навигации посетителей. Впрочем, от «хлебных крошек» тоже можно просто избавиться — проблем с юзабилити это не вызовет.
«Висячий узел» — страница без исходящих ссылок. Он получает ссылочный вес, но не распределяет его. Это тупиковый путь для поискового робота, которому некуда идти со страницы. Обычно такие страницы не вызывают проблем, но вам нужно проанализировать это и внести коррективы, если это возможно.
Страницы-сироты представляют гораздо более серьезную проблему. Это страницы, которые не связаны ни с каким другим разделом сайта. К счастью, такие страницы в современных CMS встречаются очень редко. Например, страница не попадает в категории, не является частью навигации по сайту или, что еще хуже, сайт взломан и злоумышленники разместили свой контент по внешним ссылкам.
Заставьте сканеры сканировать ваш сайт
Вы можете вручную повлиять на процессы сканирования. Есть несколько способов сделать это.
Переиндексировать страницы в панелях веб-мастеров. И Google, и Яндекс позволяют вручную заставить сканеры сканировать измененные или новые URL-адреса. Самым большим недостатком процесса является длительное время выполнения (до 10 минут) в Google и ограничение в 20 URL-адресов в Яндексе.
Делайте репосты в социальных сетях. Да, это все еще работает. Выберите социальную сеть, которую отслеживают и сканируют поисковые роботы, и оставьте там свою ссылку. Не стесняйтесь использовать свой Twitter или ВКонтакте.
Проверка журналов
Проверка журналов сервера позволяет узнать все о расписании поисковых роботов. Однако в некоторых случаях вы не сможете получить к ним доступ. Если у вас такая проблема, лучше смените хостинг.
Если у вас нет навыков администратора сервера, лог вас наверняка напугает. Данных слишком много, и большая их часть бесполезна. Если ваш сайт небольшой, вы сможете работать с логами даже в Notepad++. Однако попытка открыть журнал крупного интернет-магазина может привести к сбою вашего ПК. В этом случае следует использовать профессиональное программное обеспечение для сортировки и фильтрации данных.
Для анализа данных можно использовать настольное программное обеспечение, такое как GamutLogViewer или Screaming Frog Log File Analyzer. Существуют также онлайн-сервисы, такие как splunk.com. Имейте в виду, что онлайн-сервисы дороги и рассчитаны на большие объемы данных.
Есть проблема: не каждый GoogleBot, который вы найдете в журналах, на самом деле является GoogleBot. Вот почему вы должны проверить IP-адрес бота и использовать WHOIS для фильтрации фейков.
Ваша цель — обработать данные за достаточно большой период (оптимально месяц) и найти закономерности. Вы должны проверить следующие факторы:
- Как часто сканер посещает ваш сайт?
- Какие URL чаще всего посещаются поисковыми роботами?
- Какие URL-адреса игнорируются поисковыми роботами?
- Обнаружены ли какие-либо ошибки веб-сайта?
- Сканирует ли он файл Sitemap?
- Какие категории требуют больше всего ресурсов?
Получив эти данные, вы узнаете, нравятся ли поисковым роботам ваши целевые страницы и почему. Например, вы можете обнаружить, что поисковый робот предпочитает информационный раздел вашего сайта.