Мониторинг игровых серверов Minecraft, CS 1.6, CSS, CS:GO, SAMP. Хостинг мониторинг
Сторожевой пёс следит за вами (мониторинг хостинга) / Хабр
Внимание! Данная статья для web-программистов — содержит исходники и техн. подробности.У Вас было такое – что простой вопрос повергал Вас в ступор и глубокие раздумья? У меня такое случается каждый раз, когда клиенты или друзья спрашивают меня:
— Андрей, какой хостинг порекомендуешь для нашего сайта?
И ответить нечего, потому что все (все!) наши замеры не в пользу хостинговых компаний, даже никого конкретно приводить не буду — сами сможете проверить, выполнив рекомендации в этой статье.Казалось бы, где зарыта собака? Ведь для нас хостинг – это одна из любимейших мозолей, на которую часто наступают, потому что мы – SEOнизаторы. Мы трудимся – чтобы выводить свои сайты и клиентов в топы, а плохой и нестабильный хостинг распугивает сканирующих роботов Яндекса, Гугла и иже с ними. Впрочем, часто хостинг валится и днём, особенно во время пиковых нагрузок около 18:00 из-за наплыва в Интернете зевак под вечер.
Вот самое простое, что бывает – сайт исправно работает днём, пока бдит саппорт хостера. А ночью иногда исправно «лежит» в нокдауне. Например, скрипты хостера делают бекапы и все перегружено. Клиенты спят, покупатели спят, сайт спит. Все довольны, кроме поисковых пауков.
Первое, что мы сделали – купили свой дорогой сервер и отвезли его к Каравану (спасибо ребятам за отличное качество колокейшн). Но сервер у нас не резиновый, и как услугу хостинг мы не предоставляем. Поэтому пустить всех наших и не можем.
Чтобы как-то контролировать ситуацию – я написал пару лет назад монитор стабильности хостинга. Сейчас, когда у нас уже много других конкурентных преимуществ – мы готовы выложить исходники и алгоритм работы для Хабраобщественности, чему и посвящен этот пост.
Итак, ближе к делу
Скрипт прост до безобразия, а исходники сырые и не причесанные, не смотря на помощь нашего хабрадруга Grox'a. Просим не пинать сильно за это.Итак, архив с сорцами (PHP + MySQL), 11 kb zip. Все открытое, без обфускаторов.
Быстрый старт
1. Распаковываем у себя архив, выкачиваем все к себе на сервер, например на мойсайт.ru/watchdog/ 2. Создаем БД для собаки (лучше отдельную), и выполняем sql-файл sql.txt (или закачиваем его в PHPMyAdmin) 3. Прописываем в файле dbconnect.php доступы в базу данных 4. Прописываем в grox_config_users.php себя как пользователя (логин, пароль) 5. Заходим на мойсайт.ru/watchdog/ и добавляем первый – эталонный* сайт 6. Прописываем крон, чтобы дёргал раз в 5 или 20 минут скрипт nip.php, например, так */10 * * * * /usr/bin/wget -q «вашсайт.ru/watchdog/nip.php» 7. Теперь можем добавлять другие сайты на мониторинг 8. Через неделю собираем первые сливки 9. ????? 10. PROFIT*Эталонный (тарировочный) сайт – это чей-то чужой сайт с заведомо качественным хостингом (например, у них много серверов в разных дата-центрах). Тот, который мы используем – специально называть не буду, а то заддосим нечаянно :) Он нужен для того, чтобы исключить погрешность из-за тормозов самого нашего проверяющего сервера. Как это работает? Читаем дальше.
Структура базы данных
bones – «кости», итог кусания сайтов. Самый главный лог-файл bones_back – куда же без бэкапов. Сюда переносим всё, что старше трёх месяцев. samples – синхронизация укусов, позволяющая сравнить задержки с тарировочным сайтом. watch_dogs — это список сайтов, которые сторожевые псы «кусают» для проверки
Как это работает?
Каждый заход крона на проверку хостинга имеет уникальный номер. Сайты опрашиваются в случайном порядке. Это гарантирует работу скрипта в условиях подвисания одного отдельного сайта. Если «тарировочный» сайт сбоит одновременно с проверяемым – делаем вывод, что глючил не проверяемый сайт, а сам наш сервер, и эту выборку отбраковываем. Сравнение выборок делаем по полю sample_id в базе bones.
Вот так выглядит список «собак»
Вот пример сбоев за последние 7 дней
Статистика достаточно хороша, утренние задержки – как раз запуск бэкапа.
Что можно улучшить/добавить?
1. На register_globals не ругайтесь, этот скрипт для локального доступа (не снаружи) 2. Интерфейс пользователя получше бы 3. Не хватает сведения воедино выборки сайта и торировочного сайта 4. Можно добавить слежение за ключевой фразой на странице, гарантирующей нормальную работу БД проверяемого сайта 5. Уведомлений о сбоях 6. Более «правильный» скрипт очистки от тегов смысловой части сайта 7. Кнопки общей приостановки скрипта watchdog’a в случаях, когда надо экстренно снизить нагрузку на основной серверСкрипт дарим всем, если напишите достойное продолжение, просим им также поделиться со всеми. Можно через нас (прислав исходники на [email protected]). Если он окажется полезным Вам – помните и про нас, не удаляйте упоминание авторов из подписей в комментариях и футере.
P.S. Модуль мониторинга назван сторожевым псом (watch dog) в честь замечательного свойства некоторых AMR-контроллеров. Изначально это было прерывание с внутренним счетчиком, которое монотонно уменьшает значение специального регистра. Как только значение достигает нуля – инициируется перезагрузка контроллера, и выполнение программы начинается «с нуля». В основной и надежной части программы происходит сброс в высокие значения контролирующего регистра. Если вдруг софт вашей стиральной машинки или телевизора зависнет из-за какой-то ошибки – сторожевой пёс сам выполнит перезагрузку.
habr.com
Лучший мониторинг серверов, хороший мониторинг хостингов
Все игры
Всего серверов заказано: loading...

Серверов заказано: loading...

Серверов заказано: loading...

Серверов заказано: loading...

CounterStrike: Source
Серверов заказано: loading...

Серверов заказано: loading...

Team Fortress 2
Серверов заказано: loading...
Серверов заказано: loading...

Day of Defeat: Source
Серверов заказано: loading...
Minecraft Pocket Edition
Серверов заказано: loading...

Multi Theft Auto
Серверов заказано: loading...

GTA: Criminal Russia
Серверов заказано: loading...
DS-HOST.RU - лучший игровой хостинг2012 - 2018 © Все права защищены
ds-host.ru
Рейтинг хостингов. SysLab.ru - 100% мониторинг сайтов, серверов.
Данный рейтинг основан на регулярном мониторинге доступности сайтов хостинговых компаний. Вы можете отсортировать результаты по любому из имеющихся столбцов с данными. Значение столбцов можете узнать просто наведя мышкой на заголовок столбца.
Последнее обновление рейтинга: *** (время по Москве)
Подробнее о рейтинге
Способность сайтов хостеров к бесперебойной работе является основой организации нашего рейтинг хостинг провайдеров, формирующегося в таком порядке. Используя точки мониторинга, размещенные в различных частях света, мы ведем в течении суток многократную проверку этих сайтов. Результатом такого мониторинга будет информация, указывающая на скоростные параметры загрузки и усредненной временной характеристики открытия основной страницы проверяемого сайта хостинга.При возникновении случая выявления отсутствия работоспособности сайта хостинга, его проверки учащаются до 15-ти минутной периодичности, пока он не начнет работать. При отсутствии его активации в течении нескольких недель подряд хостинг провайдер удаляется из пунктов рейтинга.
Используя вышеперечисленные критерии, направленные на отражение технических параметров работы хостинга, мы старались сделать объективный и беспристрастный рейтинг хостингов. Поэтому мы не проводили сравнения отзывов о сайтах их пользователей, комфортности использования интерфейсов, качество поддержки, ценовую политику. Мы проводим мониторинг только технических параметров работы сайтов, так как скорость и вседоступность сайта, а также его надежность, по нашему мнению – это главные составляющие в услуге хостинга. Анализируя рейтинг, необходимо принимать во внимание место расположения хостинга. К примеру, хостинговые услуги в Эфиопии, имеющей худшую связь, по сравнению с другими странами, займет одно из нижних мест в шкале нашего рейтинга. Хотя очевидно, что на территории Эфиопии страницы этого сайта для пользователей, находящихся в этой стране, будут загружаться быстро. Поэтому для них этот хостинг будет лучшим.
Если Вы в рейтинге не нашли какой-то хостинг, обратитесь в поддержку и он будет добавлен. Обратите внимание, что указываемый Вами хостинг должен быть не для одного клиента, то есть необходимыми условиями являются интерфейс на русском языке, поддержка сайта в круглосуточном режиме и контактный телефон.
Значение индикаторов в колонках таблицы с перечнем хостингов
Uptime, % - время работы сайта хостинга в процентах. 100% - указывает на исправную работу сайта за весь период проверки. 99,9% - по мнению наших специалистов, определяет работу сайта вполне в допустимых нормах. При этом 45 минут - составит за месяц суммарное остановочное время работы хостинга.Общее время, сек. – количество прошедшего времени с момента связи с DNS-сервером и получением от него ответа.
DNS, сек. – количество времени, потраченное на установление IP-адреса анализируемого ресурса.
Ожидание ответа, сек. – количество времени работы сервера для формирования ответа, которое указывает на скорость действия скриптов сайта для создания ответной посылки.
Скорость загрузки – временные характеристики, анализируемые при открытии главной страницы ресурса.
www.syslab.ru
Более 60 инструментов для мониторинга Windows / Блог компании ua-hosting.company / Хабр
В предыдущей статье был составлен список из 80 инструментов для мониторинга Linux системы. Был смысл также сделать подборку инструментов для системы Windows. Ниже будет приведен список, который служит всего лишь отправной точкой, здесь нет рейтинга.Всем известный диспетчер задач Windows — утилита для вывода на экран списка запущенных процессов и потребляемых ими ресурсов. Но знаете ли Вы, как использовать его весь потенциал? Как правило, с его помощью контролируют состояние процессора и памяти, но можно же пойти гораздо дальше. Это приложение предварительно на всех операционных системах компании Microsoft.
Task Manager
2. Resource Monitor
Великолепный инструмент, позволяющий оценить использование процессора, оперативной памяти, сети и дисков в Windows. Он позволяет быстро получить всю необходимую информацию о состоянии критически важных серверов.
Resource Monitor
3. Performance Monitor
Основной инструмент для управления счетчиками производительности в Windows. Performance Monitor, в более ранних версиях Windows известен нам как Системный монитор. Утилита имеет несколько режимов отображения, выводит показания счетчиков производительности в режиме реального времени, сохраняет данные в лог-файлы для последующего изучения.
Performance Monitor
4.Reliability Monitor
Reliability Monitor — Монитор стабильности системы, позволяет отслеживать любые изменения в производительности компьютера, найти монитор стабильности можно в Windows 7, в Windows 8: Control Panel > System and Security > Action Center. С помощью Reliability Monitor можно вести учет изменений и сбоев на компьютере, данные будут выводиться в удобном графическом виде, что позволит Вам отследить, какое приложение и когда вызвало ошибку или зависло, отследить появление синего экрана смерти Windows, причину его появления (очередное обновлением Windows или установка программы).
Reliability Monitor
5. Microsoft SysInternals
SysInternals — это полный набор программ для администрирования и мониторинга компьютеров под управлением ОС Windows. Вы можете скачать их себе бесплатно на сайте Microsoft. Сервисные программы Sysinternals помогают управлять, находить и устранять неисправности, выполнять диагностику приложений и операционных систем Windows.
SysInternals
6. SCOM (part of Microsoft System Center)
System Center — представляет собой полный набор инструментов для управления IT-инфраструктурой, c помощью которых Вы сможете управлять, развертывать, мониторить, производить настройку программного обеспечения Microsoft (Windows, IIS, SQLServer, Exchange, и так далее). Увы, MSC не является бесплатным. SCOM используется для проактивного мониторинга ключевых объектов IT-инфраструктуры.
SCOM
Мониторинг Windows серверов с помощью семейства Nagios
7. Nagios
Nagios является самым популярным инструментом мониторинга инфраструктуры в течение нескольких лет (для Linux и Windows). Если Вы рассматриваете Nagios для Windows, то установите и настройте агент NSClient ++ на Windows сервер. NSClient ++ мониторит систему в реальном времени и предоставляет выводы с удаленного сервера мониторинга и не только.
Nagios
8. Cacti
Обычно используется вместе с Nagios, предоставляет пользователю удобный веб-интерфейс к утилите RRDTool, предназначенной для работы с круговыми базами данных (Round Robin Database), которые используются для хранения информации об изменении одной или нескольких величин за определенный промежуток времени. Статистика в сетевых устройств, представлена в виде дерева, структура которого задается самим пользователем, можно строить график использования канала, использования разделов HDD, отображать латентость ресурсов и т.д.
Cacti
9. Shinken
Гибкая, масштабируемая система мониторинга с открытым исходным кодом, основанная на ядре Nagios, написанном на Python. Она в 5 раз быстрее чем Nagios. Shinken совместима с Nagios, возможно использование ее плагинов и конфигураций без внесения коррективов или дополнительной настройки.
Shinken
10. Icinga
Еще одна популярная открытая система мониторинга, которая проверяет хосты и сервисы и сообщает администратору их состояние. Являясь ответвлением Nagios, Icinga совместима с ней и у них много общего.
11. OpsView
OpsView изначально был бесплатен. Сейчас, увы, пользователям данной системой мониторинга приходится раскошеливаться.
OpsView
12. Op5
Op5 еще одна система мониторинга с открытым исходным кодом. Построение графиков, хранение и сбор данных.
Op5
Альтернативы Nagios
13. ZabbixОткрытое программное обеспечение для мониторинга и отслеживания статусов разнообразных сервисов компьютерной сети, серверов и сетевого оборудования, используется для получения данных о нагрузке процессора, использования сети, дисковом пространстве и тому подобного.
Zabbix
14. Munin
Неплохая система мониторинга, собирает данные с нескольких серверов одновременно и отображает все в виде графиков, с помощью которых можно отслеживать все прошедшие события на сервере.
Munin
15. Zenoss
Написан на языке Python с использованием сервера приложений Zope, данные хранятся в MySQL. С помощью Zenoss можно мониторить сетевые сервисы, системные ресурсы, производительность устройств, ядро Zenoss анализирует среду. Это дает возможность быстро разобраться с большим количеством специфических устройств.
Zenoss
16. Observium
Система мониторинга и наблюдения за сетевыми устройствами и серверами, правда список поддерживаемых устройств огромен и не ограничивается только сетевыми устройствами, устройство должно поддерживать работу SNMP.
Observium
17. Centreon
Комплексная система мониторинга, позволяет контролировать всю инфраструктуру и приложения, содержащие системную информацию. Бесплатная альтернатива Nagios.
Centreon
18. Ganglia
Ganglia — масштабируемая распределенная система мониторинга, используется в высокопроизводительных вычислительных системах, таких как кластеры и сетки. Отслеживает статистику и историю вычислений в реальном времени для каждого из наблюдаемых узлов.
Ganglia
19. Pandora FMS
Система мониторинга, неплохая продуктивность и масштабируемость, один сервер мониторинга может контролировать работу нескольких тысяч хостов.
Pandora FMS
20. NetXMS
Программное обеспечение с открытым кодом для мониторинга компьютерных систем и сетей.
NetXMS
21. OpenNMS
OpenNMS платформа мониторинга. В отличие от Nagios, поддерживает SNMP, WMI и JMX.
OpenNMS
22. HypericHQ
Компонент пакета VMware vRealize Operations, используется для мониторинга ОС, промежуточного ПО и приложений в физических, виртуальных и облачных средах. Отображает доступность, производительность, использование, события, записи журналов и изменений на каждом уровне стека виртуализации (от гипервизора vSphere до гостевых ОС).
HypericHQ
23. Bosun
Система мониторинга и оповещения (alert system) с открытым кодом от StackExchange. В Bosun продуманная схема данных, а также мощный язык их обработки.
Bosun
24. Sensu
Sensu система оповещения с открытым исходным кодом, похожа на Nagios. Имеется простенький dashboard, можно увидеть список клиентов, проверок и сработавших алертов. Фреймворк обеспечивает механизмы, которые нужны для сбора и накопления статистики работы серверов. На каждом сервере запускается агент (клиент) Sensu, использующий набор скриптов для проверки работоспособности сервисов, их состояния и сбора любой другой информации.
Sensu
25. CollectM
CollectM собирает статистику об использовании ресурсов системы каждые 10 секунд. Может собирать статистику для нескольких хостов и отсылать ее на сервер, информация выводится с помощью графиков.
CollectM
26. PerfTrap
PerfTrap собирает метрики с серверов, и с помощью Graphite производится визуализация собранных данных.
27. WMIagent
Если Вы фанат Python, WMIagent для Вас.
28. Performance Analysis of Logs (PAL) Tool
PAL — мощный инструмент, который мониторит производительность и анализирует ее.
29. PolyMon
PolyMon является инструментом мониторинга системы с открытым исходным кодом, на .NET Framework 2.0 и SQL Server 2005.
30. Cloud Ninja Metering Block
Cloud Ninja Metering Block производит анализ производительности и автоматическое масштабирование мультитенантных приложений в Windows Azure. Такой анализ включает в себя не только определение или проверку счетов за использование ресурсов от Windows Azure, но и оптимизацию ресурсов.
31. Enigma
Enigma — красивое приложение, которое поможет Вам следить за всеми важных показателями прямо с рабочего стола.
Платные решения
32. SSC ServSSC Serv платный инструмент мониторинга.
33. KS-HostMonitor
Инструменты для мониторинга сетевых ресурсов, позволяет проверять любые параметры серверов, гибкие профили действия позволяют действовать в зависимости от результатов тестов.
KS-HostMonitor
34. Total Network Monitor
Это программа для постоянного наблюдения за работой локальной сети отдельных компьютеров, сетевых и системных служб. Total Network Monitor формирует отчет и оповещает Вас о произошедших ошибках. Вы можете проверить любой аспект работы службы, сервера или файловой системы: FTP, POP/SMTP, HTTP, IMAP, Registry, Event Log, Service State и других.
Total Network Monitor
35. PRTG
PRTG — простая в использовании, условно-бесплатная программа для мониторинга сети, собирает различные статистические данные с компьютеров, программ и устройств, которые Вы указываете, поддерживает множество протоколов для сбора указанных сведений, таких как SNMP и WMI.
36. GroundWork
GroundWork, по сравнению с Nagios или Cacti, не требует значительных затрат времени для настройки. Для управления и вывода информации используется понятный веб-интерфейс, который построен на базе Monarch (MONitor ARCHitecture)и Fruity. Если возникает проблема, на указанный почтовый адрес приходит сообщение или SMS-сообщение. Предоставляемая система отчетов позволяет проанализировать все процессы во времени.
37. WhatsUpGold
Это мощное, простое в использовании программное средство для комплексного мониторинга приложений, сети и систем. Позволяет производить поиск и устранение проблем до того, как они повлияют на работу пользователей.
WhatsUpGold
38. Idera
Поддерживает несколько операционных систем и технологий виртуализации. Есть много бесплатных тулзов, с помощью которых можно мониторить систему.
Windows Health CheckWindows Capacity CheckWindows Process Heat Map
Idera
39. PowerAdmin
PowerAdmin является коммерческим решением для мониторинга.
PowerAdmin
40. ELM Enterprise Manager
ELM Enterprise Manager — полный мониторинг от «что случилось» до «что происходит» в режиме реального времени. Инструменты мониторинга в ELM включают — Event Collector, Performance Monitor, Service Monitor, Process Monitor, File Monitor, PING Monitor.
ELM Enterprise Manager
41. EventsEntry
EventsEntry
42. Veeam ONE
Эффективное решение для мониторинга, создания отчетов и планирования ресурсов в среде VMware, Hyper-V и инфраструктуре Veeam Backup & Replication, контролирует состояние IT-инфраструктуры и диагностирует проблемы до того, как они помешают работе пользователей.
Veeam ONE
43. CA Unified Infrastructure Management (ранее CA Nimsoft Monitor, Unicenter)
Мониторит производительность и доступность ресурсов Windows сервера.
CA
44. HP Operations Manager
Это программное обеспечение для мониторинга инфраструктуры, выполняет превентивный анализ первопричин, позволяет сократить время на восстановление и расходы на управление операциями. Решение идеально для автоматизированного мониторинга.
HP Operations Manager
45. Dell OpenManage
OpenManage (теперь Dell Enterprise Systems Management) «все-в-одном продукт» для мониторинга.
46. Halcyon Windows Server Manager
Halcyon Windows Server Manager
47. Topper Perfmon
Используется для мониторинга серверов, контролирует процессы, их производительность.
Topper Perfmon
48. BMC Patrol
Система мониторинга и управления управления IT — инфраструктурой.
Patrol
49. Max Management
Max Management
50. ScienceLogic
ScienceLogic еще одна система мониторинга.
51. VeraX
Менеджмент и мониторинг сетей, приложений и инфраструктуры.
VeraX
Ниже приведен список (наиболее популярных) инструментов для мониторинга сети
54. NtopNtop
55. NeDi
Nedi является инструментом мониторинга сети с открытым исходным кодом.
NeDi
54. The Dude
Система мониторинга Dude, хоть и бесплатна, но по мнению специалистов, ни в чем не уступает коммерческим продуктам, мониторит отдельные серверы, сети и сетевые сервисы.
The Dude
55. BandwidthD
Программа с открытым исходным кодом.
BandwidthD
56. NagVis
Расширение для Nagios, позволяет создавать карты инфраструктуры и отображать их статус. NagVis поддерживает большое количество различных виджетов, наборов иконок.
NagVis
57. Proc Net Monitor
Бесплатное приложение для мониторинга, позволяет отследить все активные процессы и при необходимости быстро остановить их, чтобы снизить нагрузку на процессор.
Proc Net Monitor
58. PingPlotter
Используется для диагностики IP-сетей, позволяет определить, где происходят потери и задержки сетевых пакетов.
PingPlotter
Маленькие, но полезные инструменты
Список не был бы полным без упоминания нескольких вариантов аппаратного мониторинга.59. IPMIutil
IPMIutil
60. Glint Computer Activity Monitor
Glint Computer Activity Monitor
61. RealTemp
Утилита для мониторинга температур процессоров Intel, она не требует инсталляции, отслеживает текущие, минимальные и максимальные значения температур для каждого ядра и старт троттлинга.
RealTemp
62. SpeedFan
Утилита, которая позволяет контролировать температуру и скорости вращения вентиляторов в системе, следит за показателями датчиков материнской платы, видеокарты и жестких дисков.
SpeedFan
63. OpenHardwareMonitor
OpenHardwareMonitor
Источник
habr.com
Мониторинг для VDS — Техническая поддержка — NetAngels
В данной статье рассмотрена настройка мониторинга Nagios для важных параметров Облачного VDS, чтобы всегда быть в курсе состояния сервера и иметь возможность оперативного вмешательства.
Важность наличия мониторинга за работой серверов сложно переоценить, поэтому для наших клиентов мы предлагаем услугу мониторинга облачных VDS. В этой статье рассматривается процесс подключения и настройки мониторинга облачной VDS на базе ОС Debian или Ubuntu, но аналогичный сервис может быть настроен на базе любой ОС, для которой есть nagios NRPE сервер.
В качестве объектов для мониторинга в этой услуге рассматриваются: наличие ответа от сервера по портам 80 (http) и 22 (ssh), а так же дополнительно 5 любых других метрик, задаваемых клиентом индивидуально. Поскольку конфигурация тестов для этих пяти метрик задается непосредственно на ваших VDS, вы можете полностью самостоятельно определять какие параметры сервера необходимо мониторить и какое состояние этих параметров считать нормальным, а какое - критическим.
Например, системные администраторы очень часто любят мониторить общую нагрузку на сервере (load average). Но большинству программистов-не-сисадминов не понятно что за цифры стоят за тем или иным значением load average и они предпочитают иные метрики, например скорость отдачи главной станицы сайта в секундах (скорее в долях секунд, конечно). Поэтому мы предлагаем вам самостоятельно решить какие пять сервисов на вашем сервере вы хотите мониторить, а в этой статье мы рассмотрим несколько примеров настройки тестов для разных метрик, которые помогут вам настроить мониторинг для собственных нужд.
Уведомления об изменении состояния метрик мониторинг отправляет на все адреса, числящиеся в вашей панели управления как "технические контактные e-mail".
Показать все разделы
Подключение
Подключение услуги крайне просто: в панели управления хостингом у любой облачной VDS в выпадающем меню выберите пункт "Включить мониторинг". В течение 5-10 минут мониторинг включится и вы получите первые уведомления о состоянии ваших сервисов на этом сервере.
Настройка nagios nrpe server
Для запуска тестов мониторинга на вашем сервере, вам потребуется установить пакет nagios-nrpe-server и прописать в конфигурационном файле адрес нашего сервера мониторинга, откуда будут приходить запросы на получение состояний метрик.
Показать раздел
Для этого от имени пользователя root необходимо выполнить: apt-get update apt-get install nagios-nrpe-server nano /etc/nagios/nrpe_local.cfgИ в открывшемся окне текстового редактора после комментария, находящегося в шапке файла /etc/nagios/nrpe_local.cfg, вписать строки:
allowed_hosts=91.201.52.92 command[check_1]=/bin/echo OK command[check_2]=/bin/echo OK command[check_3]=/bin/echo OK command[check_4]=/bin/echo OK command[check_5]=/bin/echo OKПосле этого потребуется сохранить изменения и выйти из текстового редактора. В случае с редактором nano для этого используются сочетания клавиш Ctrl + o и Ctrl + x соответственно. Чтобы применить изменения достаточно выполнить команду:
service nagios-nrpe-server restartТеперь в минимальном варианте мониторинг установлен и настроен, но ничего полезного не делает, ведь на все 5 тестов он всегда отвечает сообщением "OK". Если вы уже проделали все описанные действия, примерно к этому моменту к вам на почту уже должно придти уведомление о том, что все 5 метрик имеют статус OK.
Общее описание конфигурации метрик
Как вы наверняка уже догадались, метрики описываются в конфигурационном файле /etc/nagios/nrpe_local.cfg и представляют собой строки вида:
command[check_N]=/path/to/command -arg1 -arg2 ...Команда, вызываемая мониторингом, может быть любой программой или скриптом, размещенном на вашем сервере. В случае успешного прохождения теста, соответствующий скрипт должен завершаться с кодом 0 и выдавать в stdout строку, начинающуюся с "OK". Если скрипт хочет сообщить о проблеме со статусом WARNING, он должен завершиться кодом 1 и выдать строку, начинающуюся с "WARNING". Для статуса CRITICAL код завершения должен быть 2, а строка начинаться с "CRITICAL".
В Debian/Ubuntu nagios NRPE сервер поставляется с большим набором уже готовых тестов на многие случаи. Найти их вы можете в каталоге /usr/lib/nagios/plugins/.
Мониторинг нагрузки (load average)
LA (load average) - это условные единицы среднего значения нагрузка на сервер в определенный момент времени. Позволяют определить изменение состояния сервера.
Показать раздел
Мониторинг нагрузки на сервере (load average) проще всего осуществлять с помощью скрипта /usr/lib/nagios/plugins/check_load, входящего в набор стандартных плагинов nagios NRPE. Вызов этого скрипта выглядит следующим образом: # /usr/lib/nagios/plugins/check_load -w 3,2,2 -c 4,3,3 OK - load average: 0.00, 0.01, 0.05|load1=0.000;3.000;4.000;0; load5=0.010;2.000;3.000;0; load15=0.050;2.000;3.000;0;Ключ -w передает значения мгновенного la, la5 и la15, достижение которых будет считаться событием типа WARNING, а ключ -c - CRITICAL. Если вы хотите, чтобы одной из метрик мониторинга была нагрузка на сервере, замените одну из строк command[check_N] в файле /etc/nagios/nrpe_local.cfg на
command[check_N]=/usr/lib/nagios/plugins/check_load -w 3,2,2 -c 4,3,3Замените в этой строке N на требуемый номер сервиса из диапазона 1..5, а значения ключей -w и -c на требуемые вам пороговые значения load average. После внесения изменений в файл /etc/nagios/nrpe_local.cfg необходимо выполнить
service nagios-nrpe-server restartНапоминаем, что все приведенные здесь действия выполняются от имени пользователя root.
Мониторинг свободного места на диске(ах)
Наличие свободного места на диске критично для корректной работы сервера, так как в процессе создаются временные файлы, например MySQL, PHP, системных логов и т.д.
Показать раздел
Мониторинг свободного места на диске(ах) поможет осуществить скрипт /usr/lib/nagios/plugins/check_disk. Пример его использования: /usr/lib/nagios/plugins/check_disk -w 12% -c 8% -p /Здесь подразумевается, что 12% и менее свободного места на любом из разделов, перечисленных в ключах -p - это WARNING, а 8% и менее - это CRITICAL. Перечисляемые через -p разделы должны быть отдельными точками монтирования отдельных блочных устройств. В простейшем случае, когда у вашего сервера только один диск, нужно указать только корневой раздел -p /, как в примере выше. Если у вас несколько дисков и несколько точек монтирования, например основная система установлена на диск типа SAS, а базы MySQL (/var/lib/mysql) размещены на диске SSD, вы можете написать в команде: -p / -p /var/lib/mysql.
Мониторинг почтовой очереди
Всегда неприятно узнавать, что ваш сайт или сервер взломаны и через взлом злоумышленники распространяют спам. Но гораздо хуже узнать об этой проблеме тогда, когда ваш сервер уже попадет в черные списки (black list) и вашу почту перестанут принимать ваши респонденты.
Показать раздел
Чтобы быть на чеку, рекомендуется мониторить состояние почтовой очереди сервера. В обычной ситуации в почтовой очереди может находиться максимум несколько писем. В случае взломов, когда отправка спама идет на тысячи адресов, почтовая очередь разрастается довольно быстро. Контролировать ее можно с помощью еще одного готового скрипта из набора nagios NRPE: /usr/lib/nagios/plugins/check_mailq. Пример ее использования: /usr/lib/nagios/plugins/check_mailq -M postfix -w 20 -c 50здесь -M postfix означает, что нужно проверять почтовую очередь MTA postfix (именно postfix идет в составе большинства образов наших облачных VDS). Для exim этот параметр будет выглядеть как -M exim и так далее. Параметры -w и -c указывают скрипту какое количество писем в очереди является WARNING и CRITICAL соответственно.
Мониторинг веб-сервера apache, размещенного за nginx proxy
Веб-сервер apache отвечает за отображение сайта в сети Интернет, поэтому его доступность очень важный параметр.
Показать раздел
В случае большинства готовых LAMP образов, предоставляемых нами для облачных VDS, на сервер устанавливается nginx, работающий в режиме http proxy, а за ним устанавливается веб-сервер apache. Внешний мониторинг наличия ответа на порту tcp/80 (http) следит только за работой nginx и в случае, если по какой-то причине apache упадет (например из-за ошибки в конфигурационном файле), nginx все равно будет работать и мониторинг будет считать, что все в порядке. Разумеется, это не всегда приемлемо. Для таких конфигураций apache запускается на локальном ip-адресе 127.0.0.1, порт 80. Необходимо проверять наличие ответа от apache по этому адресу. Для этого воспользуемся еще одним готовым скриптом /usr/lib/nagios/plugins/check_http следующим образом: # /usr/lib/nagios/plugins/check_http -H 127.0.0.1 -e 'HTTP/1.1 404' HTTP OK: Status line output matched "HTTP/1.1 404" - 453 bytes in 0,001 second response time |time=0,000513s;;;0,000000 size=453B;;;0а в случае падения apache все будет выглядеть так:
# /usr/lib/nagios/plugins/check_http -H 127.0.0.1 -e 'HTTP/1.1 404' HTTP CRITICAL - Unable to open TCP socketМониторинг скорости отдачи страницы веб-сервером
Рассмотренный в предыдущем варианте скрипт /usr/lib/nagios/plugins/check_http умеет гораздо больше, чем просто проверять наличие ответа от веб-сервера. Его можно настроить на проверку наличия в ответе определенной подстроки, скорости отдачи ответа на запрос и еще ряда интересных вещей. Подробную справку о всех возможностях check_http можно получить так:
Показать раздел
/usr/lib/nagios/plugins/check_http --helpМы же в данном примере рассмотрим вариант как проверять скорость отдачи страницы с url http://www.yoursite.ru/page.html и сообщать статусом WARNING, если время ответа равно или превышает 0.5 секунды и CRITICAL при 1 секунде и более. Команда выглядит следующим образом:
/usr/lib/nagios/plugins/check_http -H 127.0.0.1 -u http://www.yoursite.ru/page.html -w 0.5 -c 1Обратите внимание, что обязательно нужно указать адрес сервера, у которого нужно запрашивать соответствующий url (ключ -H).
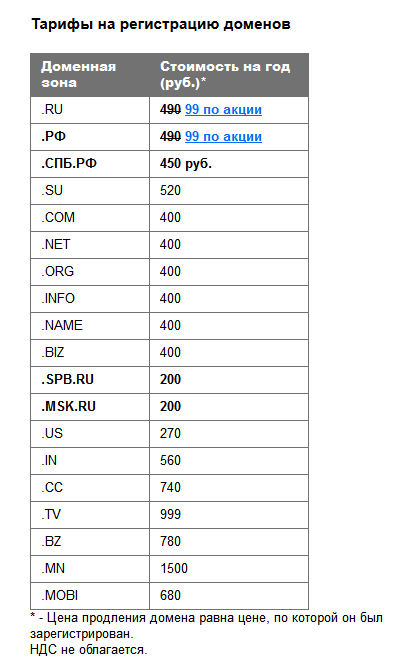
Тарифы на облачные VDS и VPS
www.netangels.ru