Методика чистки семантического ядра в Кей Коллекторе. Чистка ядра от поисковых подсказок яндекс директ от мусора
Чистим семантическое ядро от мусора в два клика
Все, кто собирает семантику, сталкивается с проблемой – не целевые (мусорные) слова, которые очень муторно вычищать, чтобы получить финальный список ключевых слов, пригодный для работы.Мы так же сталкиваемся с этим каждый день и надо сказать, что нам это порядком надоело. Мы решили на корню решить эту проблему раз и навсегда. Мы автоматизировали этот процесс.Сегодня мы расскажем о нашей новой разработке, которая с прошлой недели вошла в состав Rush Analytics.
Как обычно чистят семантическое ядро от мусора?
На практике обычно это происходит так: оптимизатор/специалист по контекстной рекламе идет в MS Excel, делает фильтр в столбце с ключевыми словами и поочередно вбивает туда стоп-слова: «бесплатно», «ВК», «вконтакте», «онлайн», «реферат» и прочие. Много стоп слов. И так по кругу долгие часы.

Гео-запросы - главная головная боль любого SEO-специалиста
Да-да у многих сейчас, наверное, вспотели ладошки т.к. вы вспомнили долгие часы очистки запросов вида «…спб», «…екб», «… в казани», «…самара». И когда вроде уже все готово – находятся все новые и новые городки, о которых даже не подозреваешь :)
Мы нашли решение – сделали готовые списки стоп-слов по гео-запросам.
Как это работает? Вам достаточно выбрать свой целевой город и все запросы, в которых содержится гео-указания (названия городов) отличные от целевого города будут автоматически удалены в отдельный список.
Выглядит это так:
 Просто выберите свой целевой город.Важный нюанс: мы заранее добавили в базу все устоявшиеся сокращения городов вида «екб», «спб», «Питер» и т.д. Все словоформы (склонения) городов так же учитываются автоматически.
Просто выберите свой целевой город.Важный нюанс: мы заранее добавили в базу все устоявшиеся сокращения городов вида «екб», «спб», «Питер» и т.д. Все словоформы (склонения) городов так же учитываются автоматически. Все самые популярные стоп-слова всегда под рукой - в 1 клик
Мы так же составили обширные списки популярных мусорных слов по различным тематикам – практически на все случаи жизни – теперь можно в один клик отсеять, например, все ключевые слова с интентом «бесплатно» или «отзывы» или «фотографии и изображения».
Выглядит это так:

Полный список тематик и направлений, стоп-слова по которым мы подготовили:
- УниверсальныйОбщий список стоп слов подходящий для всех тематик
- ХаляваВсе, что связано со словом "Бесплатно"
- ВизуализацияВсе, что связано с изображениям, видео, фотографии и рисованием
- Социальные сетиСписок названий популярных соц. сетей
- РемонтРемонт, инструменты, поломки, запчасти
- СофтКомпьютерные игры, софт, драйвера, ключи
- БУВсе связанное с «бу», старым, бывшим
- СамодеятельностьРабота на дому, "своими руками", - некоммерческий мусор
- Счет-калькуляцияСтоп-слова по расчетам, калькуляторам, коэффициентам
- Юмор-приколыЮмор, приколы, анекдоты
- ПорноРусские и английские стоп-слова по теме эротика, порно, секс
- ЛечениеСтоп-слова по лечению и самолечению, методологиям и болезням
- ТранзакцииСтоп-слова по продажам, покупкам, бронированию, заказам
- ОптовыеСтоп-слова по опту, рознице, закупкам
- Отзывы и смежноеСтоп-слова по отзывам, жалобам, мнениям
- Вопросы и инфо запросыСтоп-слова по вопросам: что, кто, какой, где
- АрендаСтоп-слова по аренде, посуточной аренде, прокату
- Крупные интернет магазиныНазвания интернет магазинов
- Авто (Beta)Названия марок и моделей автомобилей
- Животные (Beta)Список животных
- Женские именаБольшой список женских имен
- Районы МосквыСтоп-слова по районам Москвы
- Рецепты едыСтоп-слова по названиям блюд и рецептам
- ЦветаБольшой список названий цветов
- Материалы (ткань)Названия тканей
- ХарактеристикиХарактеристики предметов (размер, вес, большой, длина…)
Работаете с редкими тематиками? Не проблема – заточите все под себя
Конечно же, мы предусмотрели, чтобы вы могли добавить свои списки стоп-слов в сервис, чтобы они всегда были под рукой и не нужно было 1000 раз повторять операцию CTRL+C, CTRL+V.
Просто нажмите «Добавить свой список стоп-слов», введите запросы и пользуйтесь своим списком стоп-слов при сборе подсказок, Wordstat и в кластеризации.

Профессиональные опции для опытных специалистов
Теперь в функционале стоп-слов доступны эксперт-опции:
Символьное совпадение В данном случае если вы введете стоп-слово "бу" Будут удалены ключевые слова:- "бу холодильник"
- "холодильник бу"
- "купить бу холодильник"
- "бублик"
- "бумеранг"
- "бумага"
- "бу холодильник"
- "холодильник бу"
- "купить бу холодильник"
- "бублик"
- "бумеранг"
- "бумага"
Где работает функционал?
Поисковые подсказки – здесь стоп-слова работают как «фильтр на лету» - как только мы встречаем подсказку, содержащую стоп-слова – мы сразу же отбрасываем ее в отдельный список «удалено по стоп-словам» и дальше не собираем эту ветку подсказок, переходим к следующему слову.
Сбор Wordstat – здесь стоп-слова работают как пред-фильтр – мы ищем в веденных вами ключевых словах ненужные ключевые слова и удаляем их еще ДО сбора данных
Кластеризация – здесь стоп-слова работают аналогично модулю Wordstat – как пред-фильтр.
Уверены, что теперь, с помощью Rush Analytics, когда вы садитесь делать семантическое ядро у вас: А) Будет позитивный настрой на продуктивную работу без рутины Б) Будет в 10 раз меньше работы по очистке семантического ядра от мусора. Ждем ваши вопросы и предложения в комментариях. Уже завтра порадуем новым релизом ;)www.rush-analytics.ru
Чистка Семантического Ядра от мусорных запросов
Чистить семантику от мусорных запросов приходится после каждого сбора данных — базисов, запросов, подсказок. Очень важным в этом процессе является формирование списка минус-слов.

Что такое минус-слова
Это такие слова, с которыми поисковая фраза становится нецелевой для сайта.
Опыт показывает, что для каждого сайта желательно формировать свой список. Такой подход позволит сформировать наиболее полную и чистую семантику сайта. А это, в свою очередь, упростит дальнейшую работу над развитием нашего ресурса.
Начальный список минус-слов формируется уже на этапе подбора базовых запросов. Но основной улов будет после первого парсинга запросов по базе Вордстата Яндекса.
Полученный перечень поисковых фраз выгружаем и внимательно просматриваем. Все мусорные слова заносим в отдельный файл. На первых этапах этот процесс будет самым рутинным и трудоемким, поскольку выполняется вручную. Хотя более правильно было бы сказать вглазную, поскольку напрягаются, в первую очередь, глаза и мозги.
На первых этапах этот процесс будет самым рутинным и трудоемким, поскольку выполняется вручную. Хотя более правильно было бы сказать вглазную, поскольку напрягаются, в первую очередь, глаза и мозги.
В дальнейшем этот список используется для промежуточных чисток и попутно пополняется новыми словами.Чем тщательнее Вы будете работать над сбором минус-слов, тем качественнее будет Ваш итоговый результат.
Как правильно чистить
Существует довольно много рекомендаций по этому поводу. У каждого специалиста наработан свой подход. Но цель они преследуют одну – получение наиболее полной и очищенной от мусора Семантики сайта. В интернете распространяю различные списки стоп-слов. Есть даже сайты, заточенные именно на это. Например – minus-slova.ru. Но к сторонним спискам надо подходить творчески.
В интернете распространяю различные списки стоп-слов. Есть даже сайты, заточенные именно на это. Например – minus-slova.ru. Но к сторонним спискам надо подходить творчески.
Эту информацию необходимо внимательно проанализировать, иначе у Вас могут быть потеряны нужные ключи для работы.
Основные работы по чистке СЯ проделывают после сбора запросов и подсказок – перед этапом по кластеризации.
Вот примерный список операций по чистке полученных запросов:
- Запросы с нулевой частотностью “WC” = 0. Здесь следует обратить внимание на сезонность.
- Запросы, которые устраняют при помощи списка минус-слов или при просмотре:
- Товары и услуги, которых у Вас нет.
- Стоп-слова – бесплатно, реферат.
- Топонимы – слова привязки к местности, городу.
- Запросы для других регионов.
- Ошибки написания.
- Устаревшие данные.
- Очевидный мусор.
- Витальные запросы конкурентов.
- Информационные запросы для коммерческих сайтов. С ними придется работать отдельно. Эти фразы не удаляем бесследно, а переносим в отдельный список для применения на блоге или информационном разделе сайта.
- Слишком широкие запросы. Такие ключи нет смысла использовать для коммерческих сайтов.
- Подозрительные фразы (полнота запроса < 5%).
- Чистка списка в Кей Коллекторе:
- Неявные дубли (перестановка слов, другой падеж).
- Удаление запросов длиннее 7 слов
- Удаление по анализу групп
Полнота запросов
Этот показатель определяется по формуле:
Полнота = (“WC” / WC) * 100
Другими словами, фразовую частотность делим на общую и данные получаем в процентах.
Для работы удобно использовать таблицы Excel.
Собрав частотность любым удобным способом, просчитываем столбец «Полнота запроса» и сортируем таблицу по возрастанию этого показателя. Позиции с полнотой < 0.5% можно убирать из списка – это пустышки.
Затем внимательно просматриваем позиции с полнотой до 5%. Там могут встречаться как мусорные фразы, так и рабочие.
Чистка в KeyCollectore
Удалять записи с неявными дублями очень удобно в КейКоллекторе. Там есть такая функция – «Анализ неявных дублей». В видеоролике автор подробно рассказывает как это делается.
Удаление запросов по «Анализу групп», запросов длиннее 7 слов и другие полезные рекомендации Вы можете посмотреть в этом видеоролике.
В этом ролике приводятся основные способы чистки семантики в программе «Кей Коллекстор».
Полученный после очистки список ключевых фраз в дальнейшем используется для кластеризации.
Ключи с ошибками
Что делать с ключами с ошибками. Такие фразы в тексте и в тегах использовать не следует. Для принятия окончательного решения придется заняться проверкой реакции на них поисковых систем. И тут есть два решения.
Если поиск такие запросы исправляет и подставляет правильные слова, то эту фразу исключаем из СЯ.
Если слово не исправляется, то фразу можно оставить, но использовать во внешнем ссылочном – на форумах, в комментариях, в социальных сетях…
P.S. Итак, мы почистили свою семантику от мусора. Еще раз внимательно просматриваем полученный список. Все в норме? Теперь можно переходить к кластеризации, то есть группировке ключевых слов по потребностям пользователей. Или другими словами по интентам, что в переводе с буржуйского тоже означает потребность пользователя.С этим термином подробнее разберемся во время кластеризации.
Полезные Материалы:
inetmkt.ru
Чистка семантического ядра для информационного сайта
Мы спарсили запросы и у нас получился список различных слов. В нем конечно же присутствуют нужные слова, а так же и мусорные – пустые, не тематические, не актуальные и т.д. Поэтому их надо почистить.
Ненужные слова я не удаляю, а перемещаю их в группы, потому что:
- Они в дальнейшем могут стать пищей для размышления и приобрести актуальность.
- Исключаем вероятность случайного удаления слов.
- При парсинге или добавление новых фраз, они не будут добавляться, если поставить галочку.

Я иногда забывал её ставить, поэтому в предыдущей статье расписывал, что настраиваю парсинг в одной группе и парсю ключи только в ней, чтобы сбор не дублировался:

Вы можете работать так или так, кому как удобно.
Сбор частотностей
Собираем у всех слов через direct, базовую частотность [W] и точную [“!W”]. Не забываем выставить регион – Россия, если делаете сайт под российскую аудиторию.

Все что не собралось, дособираем через wordstat.

Чистка однословников и не формат
Фильтруем по однословникам, смотрим их и убираем не нужные. Есть такие однословники по которым нет смысла продвигаться, они не однозначные или дублируют другой однословный запрос.

Например, у нас тематика - болезни сердца. По слову “сердце” нет смысла продвигаться, не понятно, что человек имеет ввиду - это слишком широкий и неоднозначный запрос.
Так же смотрим, по каким словам не собралась частотность – это либо в словах содержатся спец символы, либо слов в запросе более 7. Переносим их в неформат. Малая вероятность что такие запросы вводят люди.
Чистка по общей и точной частотности
Все слова с общей частотностью [W] от 0 до 1 убираем.
Так же убираю и все от 0 до 1 по точной частотностью [”!W”].
Разношу их по разным группам.

В дальнейшем в этих словах можно найти нормальные логические ключевые слова. Если ядро маленькое, то можно сразу вручную все слова с нулевой частотностью пересмотреть и оставить, которые как вам кажется вводят люди. Это поможет охватить тематику полностью и возможно, по таким словам будут переходить люди. Но естественно эти слова надо использовать в последнюю очередь, потому что по ним большого трафика точно не будет.
Значение от 0 до 1 тоже берется исходя от тематики, если ключевых слов много, то можно фильтровать и от 0 до 10. То есть все зависит от широты вашей тематики и ваших предпочтений.
Чистка по полноте охвата
Теория здесь такова: например, есть слово – “форум”, его базовая частотность составляет 8 136 416, а точная частотность 24 377, как видим отличие более чем в 300 раз. Поэтому можно предположить, что данный запрос пустой, он включает очень много хвостов.
Поэтому, по всем словам, я рассчитываю, такое KEI:
Точная частотность / Базовая частотность * 100% = полнота охвата
Чем меньше процент, тем больше вероятность что слово пустое.
В KeyCollector эта формула выглядит вот так:
YandexWordstatQuotePointFreq / (YandexWordstatBaseFreq+0.01) * 100
Здесь тоже все зависит от тематики и количества фраз в ядре, поэтому можно убирать полноту охвата меньше 5%. А где ядро большое то можно не брать и 10-30%.
Чистка по неявным дублям
Чтобы почистить неявные дубли, нам необходимо по ним собрать частотность Adwords и ориентироваться по ней, потому что она учитывает порядок слов. Экономим ресурсы, поэтому будем собирать этот показатель не у всего ядра, а только у дублей.

Таким способом мы нашли и отметили все не явные дубли. Закрываем вкладку - Анализ неявных дублей. Они у нас отметились в рабочей группе. Теперь отобразим только их, потому что съем параметров происходит только тех фраз, которые у нас показаны в группе на данный момент. И только потом запускаем парсинг.

Ждем, когда Adwords снимет показатели и заходим в анализ неявных дублей.

Выставляем вот такие параметры умной групповой отметки и нажимаем – выполнить умную проверку. Таким способом у нас в группе дублей не отметятся только самые высокочастотные запросы по Adwords.
Все дубли лучше конечно еще пробежаться и глянуть вручную, вдруг там что-то выставилось не так. Особенно уделить внимание группам, где нет показателей частотности, там дубли отмечаются случайно.
Все что вы отмечаете в анализе неявных группах, это проставляется и в рабочей группе. Так что после завершения анализа, просто закрываете вкладку и переносите все отмеченные неявные дубли в соответствующую папку.
Чистка по стоп словам
Стоп слова я тоже делю на группы. Отдельно заношу города. Они могут пригодится в дальнейшем, если мы надумаем делать каталог организаций.
Отдельно заношу слова содержащие в себе слова фото, видео. Вдруг они когда-нибудь пригодятся.
А так же, “витальные запросы”, например википедия, отношу сюда и форум, а так же в мед теме сюда могут относится – малышева, комаров и т.д.
Все так же зависит от тематики. Можно еще делать отдельно и коммерческие запросы – цена, купить, магазин.

Получается вот такой список групп по стоп словам:

Чистка накрученных слов
Это касается конкурентных тематик, их частенько накручивают конкуренты, чтобы ввести вас в заблуждение. Поэтому необходимо собрать сезонность и отсеять все слова с медианой равной 0.
А так же, можно глянуть соотношение базовой частотности к средней, большая разница может тоже указывать на накрутку запроса.
Но надо понимать, что эти показатели могут говорить и о том, что это новые слова по которым только недавно появилась статистика или они просто сезонные.

Чистка по гео
Обычно проверка по гео для информационных сайтов не требуется, но на всякий случай распишу этот момент.
Если есть сомнения, что часть запросов геозависимые, то лучше это проверить через сбор Rookee, он хоть бывает и ошибается, но намного реже чем проверка этого параметра по Яндексу. Потом после сбора Rookee стоит проверить все слова вручную, которые указались как геозависимые.

Ручная чистка
Теперь наше ядро стало в несколько раз меньше. Пересматриваем его в ручную и убираем ненужные фразы.
На выходе получаем вот такие группы нашего ядра:

Желтый - стоит покапаться, можно найти слова на будущее.
Оранжевый - могут пригодится, если будем расширять сайт новыми сервисами.
Красный - не пригодятся.
internetmajor.ru
Методика правильного сбора данных в Кей Коллекторе
Парсинг ключевых слов для семантического ядра через Кей Коллектор на текущий день является одним из лучших решений в этой области. Программа представляет собой мощнейший инструмент для работы с СЯ и ключевыми фразами, начиная от их сбора, заканчивая группировкой. Сбор данных играет ключевую роль, так как именно от него зависит насколько полное семантическое ядро мы соберем. После настройки КК приступим к подготовке программы для сбора данных. Вся подготовка и настройка в данной статье производится без привязки к региону.
Выбор источников
Источников для сбора семантики существует немало и Кей Коллектор может похвастаться работой с большинством из них. Собирая ключевые фразы из разных баз и ресурсов мы имеем возможность получить максимально полное семантическое ядро. Однако в то же время есть возможность насобирать столько всего, что на одну чистку и обработку уйдет не один день. В идеале требуется соблюдать некий баланс между полнотой ядра и скоростью работы с ним. Основываясь на практике работы с разными ядрами, оптимальный список источников будет выглядеть так:
Пакетный сбор фраз из левой колонки Yandex.Wordstat.

Когда речь идет о сборе ключевых слов, первым в большинстве случаев вспоминается Яндекс.Вордстат. Добавление данного источника позволит нам спарсить левую колонку сервиса по маркерным словам, то есть не только само слово, но и все, что с ним упоминается.
Плюсы источника:
Большое количество реальных запросов от пользователей, которые пользуются поисковой системой.
Актуальные запросы, обновление раз в месяц.
Возможность на этапе отбора маркерных слов оценить объем семантики по фразе.
Минусы источника:
2. Пакетный сбор слов из Rambler.Adstat.

Этот источник скорее является дополнением к первому. Поисковая система Rambler не пользуется большой популярностью, но, как показывает практика и из нее есть возможность получить ряд интересных фраз для добавления в СЯ.
Плюсы источника:
Дополнение к фразам, собранным из Вордстата.
Независимая и уникальная база слов поисковой системы.
Минусы источника:
Небольшое количество слов в базе.
Большинство фраз не будет добавлено, так как они уже “приедут” из Вордстата.
3. Пакетный сбор поисковых подсказок.

Этот инструмент позволяет получать поисковые подсказки из ряда поисковых систем и ресурсов. То есть мы можем получить “предложения” поисковой системы к фразе, которые вбивает пользователь, основываясь на прошлых запросах и их частоте. Подсказки очень актуальны, так как их обновление происходит чаще, чем баз. Это обусловлено желанием предлагать пользователю только свежую и популярную информацию. Например, ПС Яндекс обновляет подсказки примерно раз в день.

Хороший результат показывают отмеченные на картинке источники подсказок: Yandex, Google (SAFE), YouTube (SAFE), Yandex.Direct (SAFE). В источниках Google, YouTube и Yandex.Direct необходимо установить режим SAFE (безопасный), так как в противном случае будут использоваться перебор подсказок, что может привести к санкциям от этих ресурсов.
Важно! Не советуем использовать подсказки Mail.ru в работе с большими ядрами. Система, использующая сбор подсказок работает по принципу перебора букв алфавита к каждой предложенной фразе. В Mail.ru, если подсказок не найдено, то парсится запрошенная системой буква, то есть сбор подсказок по фразе “окна” будет иметь вид “окна а”, “окна б” и так далее. На 1 000 фраз мы получим как минимум 5 000 таких мусорных запросов. Это потратит время и на парсинг и на их чистку.
Плюсы источника:
Актуальная информация, частое обновление.
Поисковая система сама подбирает нам самые популярные поисковые запросы.
Минусы источника:
Система работает по принципу перебора букв, в некоторых случаях по принципу перебора популярных окончаний к фразе. В итоге мы получаем неестественные фразы с одинаковыми окончаниями. В Яндексе часто попадается окончание “5 лучших моделей”. Да, можно найти рабочую фразу, но когда данная подсказка добавляется к “как вылечить простуду 5 лучших моделей”, то это не более, чем мусор. Еще одним вариантом является “отзывы сотрудников” и “N букв”, где N - цифра от 1 до 10 (решение кроссвордов). В больших проектах данные словосочетания можно заранее включить в список стоп-слов, так как их будет много, а ценности они практически не несут, разве что это наша тематика и найдется рабочая фраза.
4. Сбор расширений ключевых фраз.
Расширения ключевых фраз предлагают работу со статистикой сервисов Rookee. Инструмент на выходе дает неплохое количество фраз, которые не всегда есть возможность зацепить при парсинге из предыдущих источников.
Плюсы источника:
Уникальные фразы, которые не получить из парсинга ПС.
Довольно чистый итоговый результат, без мусора, так как сервис Rookee имеет хорошие базы и статистики.
Минусы источника:
5. Следующий источник, который используется для создания полного семантического ядра не входит в инструменты КК. Речь идет о базах ключевых слов. Хорошим вариантом будет бесплатная база Букварикс (www.bukvarix.com). В базе находится более 2 млрд слов и фраз, которые можно добавить в свое семантическое ядро.
Обратите внимание! Убедитесь, что у вас хватает памяти на жестком диске для скачивания базы, так как она занимает 170 гигабайт.
Плюсы инструмента:
Очень большое количество ключевых фраз.
Отдельным плюсом базы в целом является наличие больших списков минус-слов, которые можно позаимствовать для чистки СЯ.
Минусы инструмента:
Часто бывает, что многие фразы баз неактуальны, так как хранятся там долгое время, а обновление таких объемов может проводиться порой раз в 6 месяцев.
Большое количество фраз является и минусом баз, так как собраны все тематики и есть возможность зацепить много мусора при сборе. Поэтому всегда добавляйте стоп-слова как в самой базе, так и после добавления в КК, потому что система изменения словоформы базы работает хуже, чем та же система в КК.
Это основные источники, которые показывают хороший результат и позволяют сохранить баланс качество / скорость в сборе семантического ядра.
Подготовка папок
С источниками познакомились, теперь необходимо настроить рабочую область папок, с которыми мы будем работать на этапе сбора данных. Стандартный вариант при создании нового проекта в КК выглядит так:
В соответствии с нашей методикой сбора, которая будет описана далее, необходимо подготовить проект следующим образом.
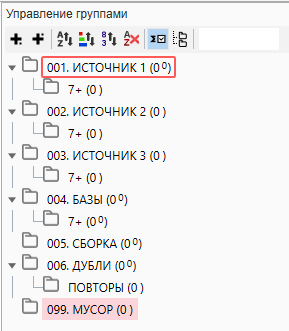
Немного комментариев к этому непонятному “дереву”. Для простоты использования мы пронумеровали папки по типу “001, 002” и так далее и отсортировали их в алфавитном и числовом порядке.
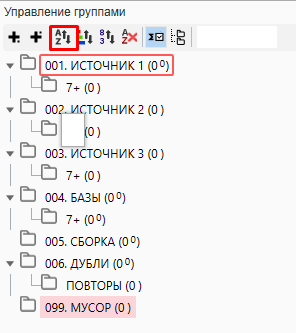
Такой запас чисел необходим в том случае, если группировка будет проходить в Кей Коллекторе, а в работе с большими ядрами количество папок может доходить до сотни.
Создание подпапки 7+ в каждом источнике необходимо для того, чтобы перенести полученные фразы которые состоят из более чем 7 слов. Дело в том, что при сборе частоты, сбор через Яндекс.Директ не может работать с фразами, которые состоят из более чем 7 слов и для получения точной частоты по ним необходимо проводить сбор через Вордстат. Чтобы ускорить процесс и проводить сбор параллельно, лучшим способом будет разделить все фразы на “до 8 слов” и “8 и более”. Это позволит Директу не “спотыкаться” при сборе об такие фразы, а Вордстату не обрабатывать то, что в разы быстрее сделает Директ.
Папка “ДУБЛИ” потребуется для чистки фраз по типу “купить квартиру”, “квартиру купить”. Те фразы, которые меньше употребляются пользователями отправятся сюда.
Итерации сбора
Итак, рабочая область готова, источники выбраны, теперь можно приступить к самому главному - сбору данных.
Сразу стоит отметить, что мы будем описывать сбор максимально полного семантического ядра, ведь именно такое ядро даст понять намерения пользователя и узнать все стороны вопроса, который его интересует.
Почему в подготовке папок мы указали 3 источника? Дело в следующем: в большинстве случаев сбор СЯ даже через Кей Коллектор происходит по сценарию - собрал фразы из левой колонки вордстата, почистил / обработал, пустил в работу. Этот вывод основан на анализе инструкций по сбору данных представленных в Рунете.
Некоторые используют бОльшее количество источников, однако все отталкиваются только от маркерных слов. Это абсолютно неправильно. Минусом такого подхода является то, что мы теряем большую часть ядра, если проводим сбор данных только по маркерным словам.
Представьте, что мы собрали фразы по ключевому слову “пластиковые окна”. Получили фразы по типу “купить пластиковые окна”, “пластиковые окна дешево” и другие популярные расширения ключевой фразы. Однако на этом ядро ни в коем случае не заканчивается, более того, основная его часть проявится только когда мы соберем данные по собранным фразам. То есть, если мы проведем сбор по фразам “купить пластиковые окна” и “пластиковые окна дешево”, мы увидим большое количество рабочих фраз, которые невозможно получить при сборе данных по маркерной фразе “пластиковые окна”. Одно это понимание уже может расширить наше семантическое ядро по отношению к конкурентам.
Именно исходя из этих соображений на этапе подготовки папок мы сделали 3 источника. Первый из них будет для сбора данных по подготовленным маркерным фразам. Во второй мы проведем сбор данных по фразам, которые получили на первом этапе. И в третий сбор данных по фразам второй итерации (лат. iteratio - повторяю).
Количество итераций выбрано исходя из практики. Как правило, самое большое количество фраз появляется в ходе второй итерации. Третья уже “выжимает соки” из наших фраз и является самой маленькой, но не менее ценной.
Теперь непосредственно к сбору данных. Рассмотрим настройку на примере фразы “кондиционеры”.
Первая итерация
Сбор
Рабочая область готова, выбираем ИСТОЧНИК 1 в правой части окна программы.

Нажимаем на первый источник “Пакетный сбор фраз из левой колонки Yandex.Wordstat”.

Настройки: “Добавить в текущую группу” (выделенная) и “Не добавлять фразу, если она уже есть в любой другой группе”. Вторая настройка требуется для избегания дублей, так как одна и та же фраза может прийти из разных источников. Чтобы не перебирать одинаковые фразы и ускорить процесс сбора данных выставляем эту настройку.
В программе есть функция “Распределить по группам”. Так мы можем сразу определить, в какую папку пойдут фразы по тому или иному маркерному запросу. С одной стороны, это очень удобно, так как упростит последующую группировку, с другой стороны, при работе с большими проектами нередки случаи, что в ходе итераций запросы одной тематики подмешиваются к запросам другой тематики. В этом время уйдет на сортировку запросов по нужным группам, если они попали не туда. Поэтому мы советуем загружать все данные в “Текущую папку”, а после проведения всех итераций производить группировку и распределение по группам. Инструменты КК помогут сделать это быстро и без лишних усилий.
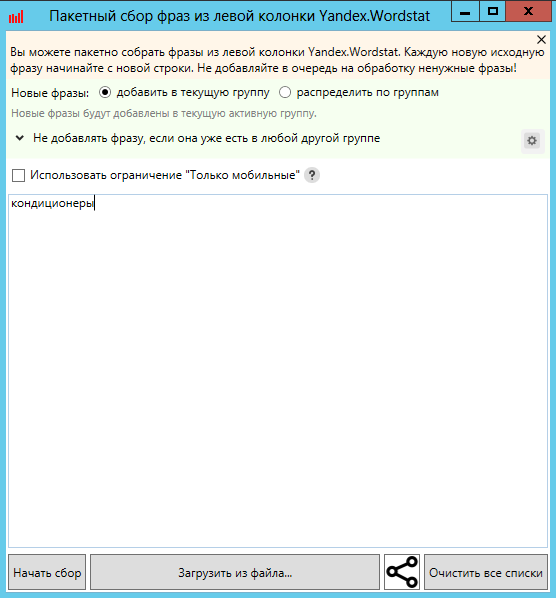
Запускаем "Начать сбор".
Пакетный сбор слов из Rambler.Adstat. Настройки идентичны настройкам в предыдущем источнике.

Пакетный сбор поисковых подсказок. Настраиваем сбор в текущую группу, “Не добавлять фразу если она есть в любой другой группе”.

Сбор расширений ключевых фраз сервиса Roostat. Для данного источника требуется указать регион сбора, глубину сбора (ТОП) и для какой поисковой системы стоит собирать данные. Если нас интересуют информационные запросы без привязки к региону, то лучшим решением будет оставить регион “Москва”.

После окончания сбора по всем итерациям нам необходимо очистить группу от мусорных запросов.
Чистка
Эффективная чистка подробно рассмотрена в отдельной статье, так как заслуживает особого внимания. В данном примере можно отметить несколько быстрых способов:
Используем фильтрацию фраз.

Выбираем “содержит прочие символы”.
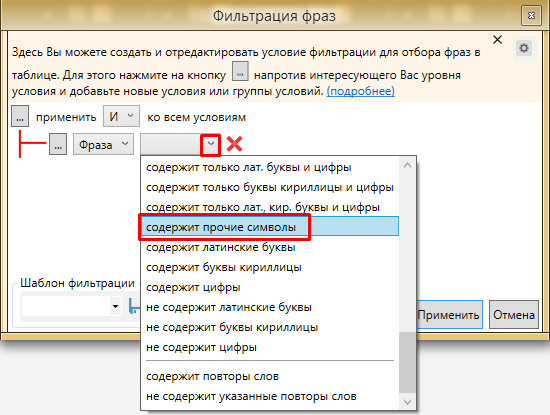
Жмем “Применить”. Кей Коллектор отфильтрует все фразы, которые содержат какие-либо спец символы или символы, которые не были указаны в настройках КК на замену или удаление. В 99% случаев это мусор, который не сыграет роли.
Выделяем все отфильтрованные фразы и переносим их в папку МУСОР.

Настройки переноса следующие
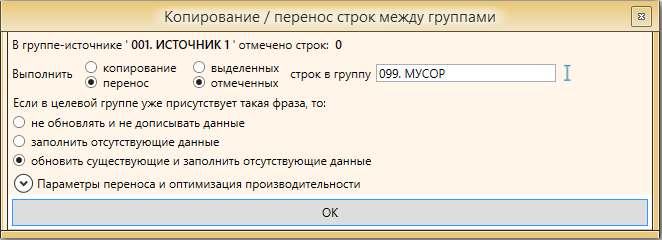
Есть возможность настроить параметры оптимизации, но по опыту работы с большими проектами это не столь необходимо и лучше оставим настройки стандартными.
Важно! Не удаляйте фразы, которые считаете мусорными! Переносите их в папку “МУСОР”. Так как предложенная методика предлагает несколько повторений сбора, в случае если мы удалим фразы они снова будут собраны. Если перенести их в папку “МУСОР”, сработает настройка “Не добавлять фразу, если она есть в любой другой группе” и мы сэкономим много времени, сил и финансов.
Вторым вариантом быстрой чистки является “содержит латинские символы”. Однако в этом случае все зависит исключительно от тематики. Если мы готовим ядро для интернет магазина, то данная настройка вычеркнет 30% ядра, а то и больше.
Следующий кропотливый, но эффективный способ. Переходим во вкладку “Данные”, жмем “Анализ групп”.

Этот инструмент полезен тем, что позволяет быстро выделить необходимые слова и все схожие с ним словоформы. Допустим, нам не нужны фразы “ремонт кондиционера”, которые мы получили в ходе сбора. Мы используем быстрый фильтр и вбиваем фразу “ремонт”

Выделяем все полученные результаты и сразу переносим их в МУСОР.
Третий способ - использование стоп-слов.

Если часто работать с СЯ, то постепенно наберется свой постоянный список стоп-слов, которые применяются в различных случаях. В любом случае можно легко найти готовые списки стоп-слов (или еще их называют минус слова) в интернете и добавить их в свой список, если они подходят по тематике. С помощью стоп-слов можно вычистить большое количество мусорных фраз сразу после сбора.
Сбор частот
После чистки собранных фраз от мусора можно запускать сбор частот для наших фраз. Выгодно изначально почистить фразы от мусора, а затем запускать сбор, так как это позволит сэкономить бюджет на антикапче и ускорить процесс сбора.
Сбор частот нужен нам для определения того, насколько часто пользователи вводят в поисковую систему тот или иной запрос и для определения их типа запроса. Соответственно, этим будет определяться приоритетность использования той или иной фразы.
Прежде чем запускать сбор необходимо разделить фразы на состоящие из 7 слов и фразы, состоящие из более чем 7 слов. Как описывалось ранее, это необходимо из-за того, что Директ не может обрабатывать запросы более 7 слов.
Используем фильтрацию по фразам.

Можно сохранить настройки фильтрации в шаблоны, чтобы иметь быстрый доступ к нужным настройкам.
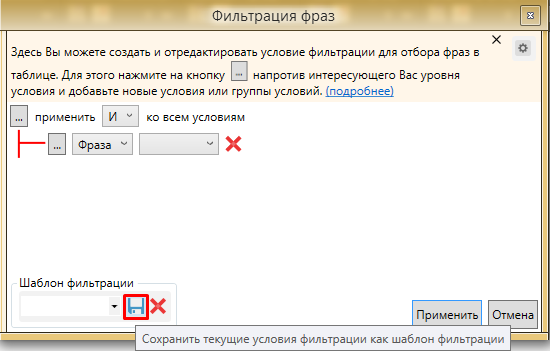
Переносим полученные фразы в подготовленную папку 7+
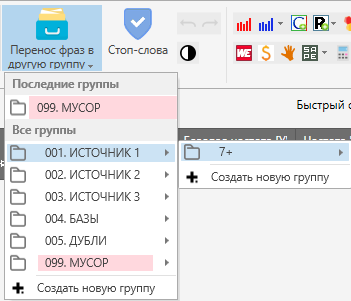
Теперь всё готово для сбора частот. В папке ИСТОЧНИК 1 (не 7+), запускаем сбор данных из Яндекс.Директ.

Рекомендуемые настройки:
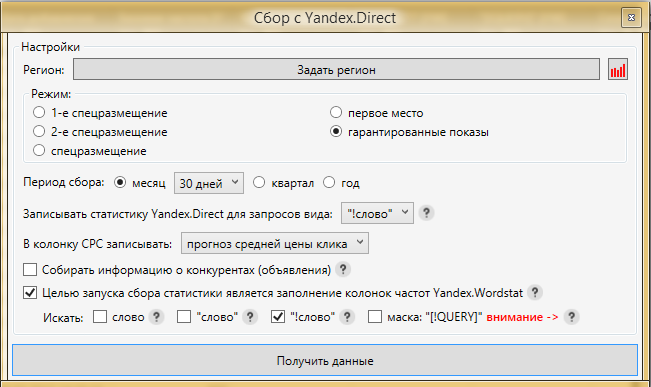
В последующем, после сбора всех итераций мы можем собрать информацию о конкурентах в Директе, если это необходимо для проекта.
Обратите внимание! В ходе обработки следите за сбором частот, так как на 1 аккаунт Яндекс.Директ приходится 100 капч, после чего необходимо перезапустить сбор. Также следите за общим количеством капч, если они достигли порога в 5 000 (выставленного в настройках) необходимо перезапустить Кей Коллектор.
В папке 7+, в которой находятся фразы из 8 слов и более запускаем сбор частот через Яндекс.Вордстат.
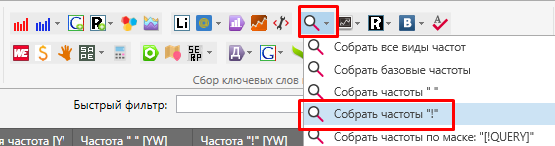
Яндекс.Директ обрабатывает частоты в разы быстрее “лупы” (Вордстата).
После того, как оба процесса закончатся переносим обратно фразы из папки 7+ в папку ИСТОЧНИК 1, так как теперь ничего не помешает работе с данными фразами в одной папке.
Для того, чтобы использовать только актуальные фразы с потенциальным трафиком необходимо провести чистку по частотностям. Порог, который можно оставить зависит от объема проекта. Если есть возможность и желание работать для каждого пользователя, то порог можно ставить и в 1 запрос в месяц. Однако в большинстве случаев порога частоты равным 5 более чем хватает. Для уточнения - речь идет не о СЯ для Директа, где в некоторых случаях используются и так называемые “пустышки”.
Для фильтрации по частоте используем инструмент фильтрация фраз, но в этот раз запускаем его в колонке “!” WS (или Частота “!” [YW], если вы не меняли стандартное название).


Выставляем порог “меньше 5” (или другое значение, в зависимости от предпочтений).
Отмечаем полученные фразы и переносим их в “МУСОР”.
Первая итерация очищена и готова к дальнейшей работе.
Вторая и третья итерации
Вторая итерация ничем не отличается от первой по последовательности действий. Но для сбора данных мы используем фразы, которые получили в ходе первой итерации. Для этого мы берем и выделяем все фразы в папке ИСТОЧНИК 1: выделили первую фразу, перешли в конец списка, с зажатым SHIFT’ом выделили последнюю фразу. Копируем: CTRL + C или правой кнопкой и “Копировать” (последний пункт выпадающего окна). После этого выделяем папку ИСТОЧНИК 2 и по очереди запускаем сбор из источников, как это проводилось в первой итерации.
Таким образом мы повторяем все пункты: Сбор, Чистка, Сбор частот, но используем фразы с первой итерации.
Третья итерация как понятно из логики - это сбор по фразам второй итерации.
Выделяем, копируем фразы, переходим на ИСТОЧНИК 3 и повторяем пункты: Сбор, Чистка, Сбор частот для фраз второй итерации.
В итоге, у нас должно получиться 3 папки с фразами, где следующая дополняет предыдущую. Практика показывает, что по объему от большего к меньшему чаще всего бывает так: ИСТОЧНИК 2, ИСТОЧНИК 1, ИСТОЧНИК 3. Если вдруг получилась друга ситуация, ничего страшного в этом нет, главное, чтобы все фразы соответствовали нашему ядру и тематике.
Работа с базами
На следующем этапе необходимо подключить базы. Как и описывали, мы используем базы Букварикс.
Интерфейс программы выглядит достаточно просто и не составит труда в нем разобраться. Берем нашу маркерную фразу “кондиционер” и добавляем её в левый столбец программы и жмем кнопку “Найти”.

Пример того, что показывает база изначально:

Цифра очень большая, 729 тысяч, но как видно из результатов кондиционер в данном случае рассматривается и как средство для волос, поэтому необходимо добавить в стоп слова такие запросы как: волос, орифлейм, питание, увлажнение и другие, которые не связаны с кондиционером как прибором. Постепенно выйдет адекватное количество фраз, а для баз это может быть порядка 80-120 тысяч.
Данные можно экспортировать в двух вариантах: текстовый файл и excel, это указывается в настройках.
После экспорта необходимо добавить полученные фразы в КК. Для этого необходимо нажать кнопку “Добавить фразы”
Можно добавить фразы обычным копированием, либо же загрузить их из файла
После добавления фраз необходимо провести для них такие пункты как: Чистка и Сбор частот.
При работе с базами часто бывает, что порядок действий выстраивается так: быстрая чистка по анализу групп, затем сбор частот и повторная чистка. Так как базы собираются за долгое время, при сборе частот большинство из запросов будет иметь месячную частоту 0 и их можно будет быстро отсеять фильтрацией по “!” WS, не тратя времени (но тратя деньги на антикапчу) вручную разбирая эти 80-120 или более фраз.
Этап сбора по базам дает как правило небольшой прирост в количестве фраз нашего СЯ, однако базы содержат большое количество запросов из 8 и более слов, которые редко встретишь в других источниках семантики.
Совмещение итераций
После того, как мы собрали все итерации, почистили их на мусор, собрали для них частоту и почистили фразы с частотой менее 5 необходимо совместить все полученные итерации и базы в одну группу. Это необходимо для последующей очистки на дубли, которые как правило разбросаны по итерациям.
Чтобы правильно сделать сборку необходимо копировать, не перемещать фразы из папки в папку. Копирование поможет нам восстановить прежний вариант, если вдруг мы случайно удалим фразы или сделаем что-то не так.
Для того, чтобы копировать фразы необходимо выполнить следующее:
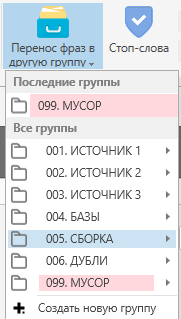
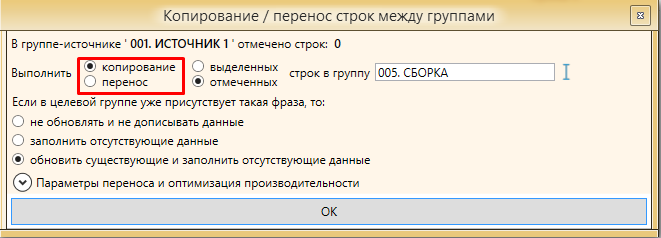
Данную процедуру необходимо повторить для других итераций и баз, чтобы в папке “СБОРКА” мы получили все фразы нашего проекта (кроме мусорных).
Чистка на дубли
Чистка на дубли представляет собой очищение наших фраз от дубликатов, которые отличаются лишь перестановкой слов, например “купить кондиционер”, “кондиционер купить”. Частота у них будет показана одна и та же, однако в проекте будет использоваться только более правильная формулировка с точки зрения русского языка и восприятия человека. Кей Коллектор берет этот анализ на себя и делает это вполне качественно.
Для того, чтобы почистить фразы на дубли нам необходимо собрать частоту по маске “[!QUERY]” WS. Эта частота показывает маску фразы, а именно, то как пользователи вбивали данный запрос в зависимости от постановки слов. Допустим, после сбора этих частот фразы “гель для душа” и “для душа гель” будут иметь примерное соотношение 145 к 5, то есть первая фраза употребляется гораздо чаще второй. Нередко бывает, что частота QUERY по значению больше, чем “!” WS, однако это обуславливается тем, что она включает в себя сумму частот “!” WS разных формулировок фразы. Например, если фраза одинаково часто используется в обоих вариантах, а их точная частота (“!”) выглядит как 150 и 10, то их частота QUERY будет выглядеть как 80 и 80. Этот пример редко можно встретить, но он “на пальцах” и четко описывает отображаемые в программе данные.
Как же программа чистит подобные дубли? Система собирает данные по маске QUERY и делает “умную отметку”, а именно выделяет и предлагает оставить фразы с наиболее высоким показателем QUERY.
Для того, чтобы собрать частоту QUERY необходимо сделать следующее:
Выделяем папку СБОРКА.
На панели инструментов выбираем “лупу” и функцию “Собрать частоты по маске “[!QUERY]””.
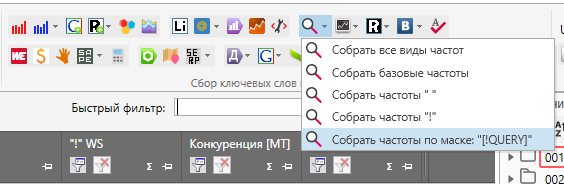
После окончания сбора проведем саму чистку дублей.
Переходим во вкладку Данные и включаем инструмент “Анализ неявных дублей”

После подсчета перед нами откроется окно с предложенными неявными дублями.
Проводим следующую настройку

Такая настройка, как “Не учитывать словоформы при поиске неявных дублей” отвечает за то, что дублями будут признаваться формулировки с разными окончаниями и словоформами. Например, при включенной опции программа посчитает фразы “купить кондиционер” и “купить кондиционеры” дублями. В целом, эта опция оправдывает себя, так как в большинстве случаев, склонения которые предлагаются как дубли таковыми и являются, поскольку поисковые системы самостоятельно меняют словоформы запроса и сопоставляют с заголовками страниц. Поэтому, после ряда тестов мы посчитали, что эта функция полезна и стоит ее включать.
После того, как система обработала дубли в нашем проекте необходимо выполнить “умную отметку”.

Кей Коллектор отметит в таблице все фразы, которые он считает дублями. В зависимости от объема рекомендуется проверить взглядом предложенную отметку. Если вдруг нам кажется, что какая-то фраза звучит неестественно, но показатель QUERY выше, чем у более “правильной” фразы, то стоит посмотреть источник фразы, так как в большинстве случаев такие варианты возникают при подсказках поисковых систем. То есть пользователь вбил “шины”, Яндкс предложил ему “купить” и он выбрал, соответственно будет подсчитано, что эта формулировка используется часто. Такие фразы стоит оставлять, так как они не меняют семантического смысла, а переставить слова в заголовке в будущем не составить труда.
Отмеченные фразы переносим (не забудьте поменять настройки с копирования) в папку дубли.
Нередко бывает так, что при сборе попадаются фразы с повторением слов, допустим “как приготовить кашу как”. При этом у них есть точная частота и они не определяются как дубли системой КК. Для этого есть следующее решение, настраиваем фильрацию фраз следующим образом:
Фраза содержит повторы слов
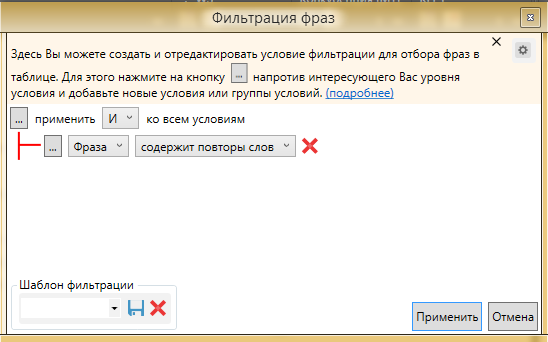
Добавляем второе условие - QUERY равно 0. Для того, чтобы добавить условие жмем на “…” на верхнем уровне.
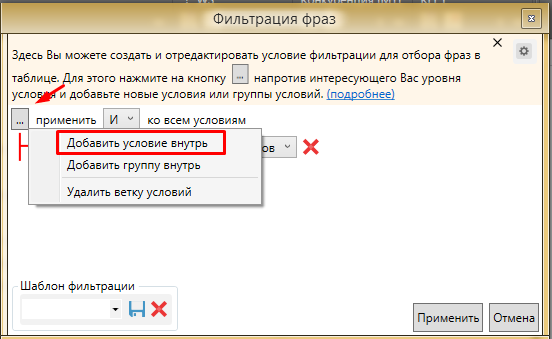
И добавляем второе условие

Нажимаем применить. При данном фильтре мы задаем условие: во фразе содержатся повторы слов и частота написания пользователями фразы в таком варианте равняется 0. Таким образом мы исключаем фильтрацию слов с повторением предлогов, которые могут попасться если мы просто оставим фильтр “содержит повторы слов”. Для более тщательной чистки, QUERY можно поставить не равным 0, а меньше 5 или меньше 10. Чтобы не получилось так, что мы выделим фразу с точной частотой 5 и QUERY 4, можно добавить третье условие, что “!” WS более 10. С помощью этих фильтров можно максимально очистить семантическое ядро от подобного мусора.
Полученные фразы переносим в подпапку дублей “ПОВТОРЫ”.
На этом этапе можно сказать, что наше ядро готово к работе и группировке.
Итоги
Предложенный вариант сбора семантического ядра в Кей Коллекторе подходит для проектов любого масштаба. Разве что для мелких проектов возможно не использовать базы, если количество фраз оттуда будет слишком большим.
Мы рассмотрели сбор максимально полного семантического ядра. Этот способ заключается в нескольких итерациях, которые собирают все варианты и тематики связанные с нашими маркерными словами. В данной методике не использовалась привязка к региону, что часто требуется для локальных коммерческих проектов и практически не рассматривались особенности сбора СЯ для контекстной рекламы.
Если обобщить преимущества и недостатки такой методики, то выйдет примерно следующее:
Плюсы методики:
Максимально полное ядро. Мы на голову обойдем конкурентов, которые не используют несколько итераций в сборе СЯ.
Эффективная чистка на дубли и повторы слов.
Эффективная чистка на мусор (основные моменты), которая также является частью этой методики.
Использование баз, как дополнительного источника семантики.
Минусы методики:
Возможно, продолжительный по времени анализ и ход всех итераций. Однако результат того стоит.
Сложность в первоначальном следовании “инструкции” и понимании всех методик.
Необходимость бОльшего бюджета на антикапчу, так как объем фраз для обработки больше, чем в сборе данных с одной итерацией.
semyadro.pro
Методика чистки семантического ядра в Кей Коллекторе
В ходе парсинга через Кей Коллектор неизбежно приезжает большое количество мусорных запросов, которые либо не подходят к нашей тематике, либо содержат различные спец. Символы, частотность которых в итоге окажется равной 0. Кей Коллектор обладает очень универсальным и гибким функционалом для чистки поисковых запросов и может справиться с любым их количеством достаточно быстро. Рассмотрим большинство из них и разберемся как ими управлять.
Чистка с помощью фильтров
В Кей Коллекторе присутствует возможность так называемой “быстрой фильтрации” и более широкой фильтрации, которая подойдет абсолютно любому пользователю КК.
Быстрый фильтр позволяет нам отфильтровать слова, которые содержат заданные параметры. Сам фильтр находится над рабочей областью поисковых фраз.
 Фото 1: Вид строки быстрого фильтра в Кей Коллекторе.
Фото 1: Вид строки быстрого фильтра в Кей Коллекторе.Рассмотрим на примере: допустим, у нас коммерческий сайт по продаже различной техники и мы собираем семантику для страницы кондиционеров. Собрав поисковые запросы с помощью КК обнаружили, что часть из них содержит слова “бесплатно”, “бесплатный” и другие словоформы этого запроса. Чтобы быстро отсеять ненужные нам запросы можно использовать быстрый фильтр, для этого необходимо вбить в строку “бесплат” и нажать Enter.
 Фото 2: Использование значимой части слова для поиска всех морфологических форм.
Фото 2: Использование значимой части слова для поиска всех морфологических форм.Необходимо использовать именно вариант “бесплат” для того, чтобы охватить все словоформы и чтобы нам не пришлось искать каждое склонение вручную.
После этого система выдаст нам все запросы из группы, которые содержат именно эту последовательность букв в любой части фразы.
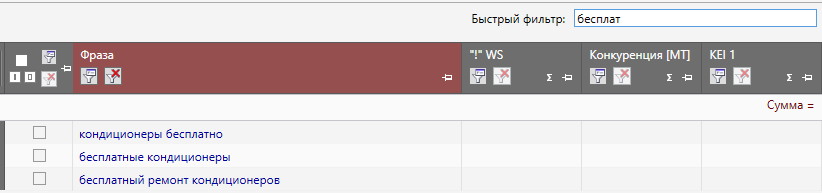 Фото 3: Результат фильтрации с разными окончаниями слова. Можно разом очистить все.
Фото 3: Результат фильтрации с разными окончаниями слова. Можно разом очистить все.Остается лишь выделить все фразы.
 Фото 4: Кнопка, выделяющая все наши фразы под фильтром.
Фото 4: Кнопка, выделяющая все наши фразы под фильтром.И перенести их в папку “МУСОР”, согласно нашей методике сбора, в которой фразы не удаляются, а остаются для упрощения следующих итераций.
С этим инструментом желательно быть аккуратными, так как он имеет свои недостатки и просто фильтрует по набору и очередности букв (учитывая пробелы). Допустим, если мы работаем с коммерцией и хотим найти какую-либо компанию с названием-аббревиатурой ЕСК, то при использовании быстрого фильтра КК выдаст нам все слова, содержащие этот набор букв, а их будет немало. В тоже время он поддерживает регулярные выражения. Если вы столкнулись с ситуацией, когда быстрый фильтр уже не подходит - переходим к более широкой фильтрации.
Чтобы фильтровать фразы в многоуровневом режиме жмем на данную кнопку.
 Фото 5: Кнопка перехода в расширенное меню фильтрации.
Фото 5: Кнопка перехода в расширенное меню фильтрации.Перечень возможных фильтров достаточно широк
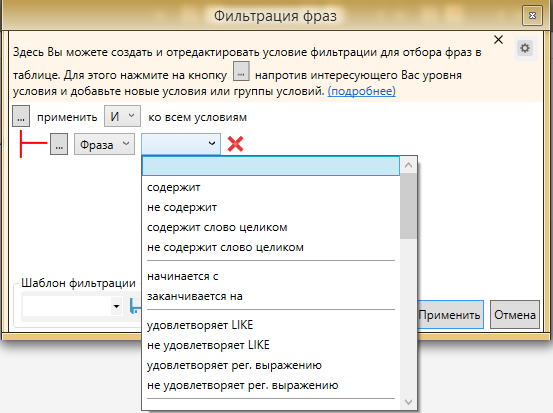
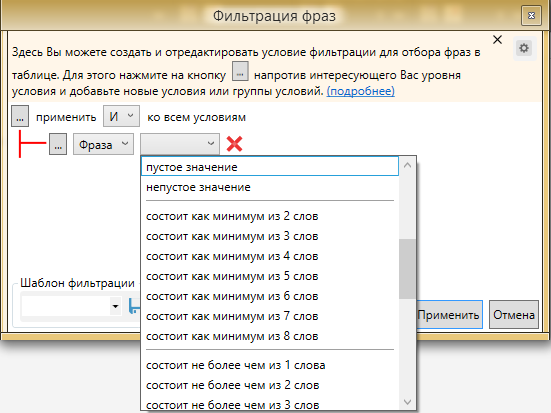
 Фото 6: Варианты фильтрации фраз в Кей Коллекторе.
Фото 6: Варианты фильтрации фраз в Кей Коллекторе.Уже этого набора фильтров будет достаточно даже самому привередливому пользователю.
Увеличивает возможности этого фильтра многоуровневая фильтрация, то есть возможность задать несколько фильтров одновременно. Для этого необходимо нажать на кнопку “...” и добавить “Условие внутрь”. Так же можно сразу добавить несколько групп фильтраций (“Добавить группу внутрь”) и настроить уже в них свои правила.
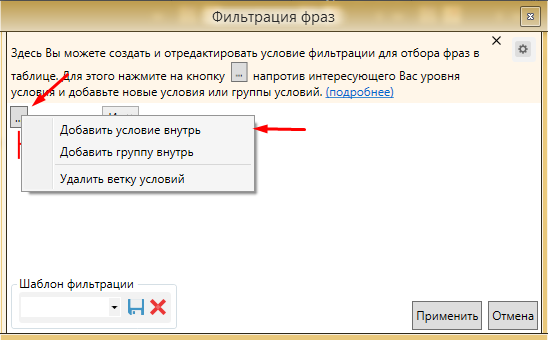 Фото 7: Включаем дополнительные условия фильтрации.
Фото 7: Включаем дополнительные условия фильтрации.Таким образом мы можем отфильтровать фразы по всем параметрам сразу. При переключении опции “И” на “ИЛИ” система будет рассматривать несколько вариантов фильтрации, а не связывать их. Это позволит задать сразу все фильтры в один проход.
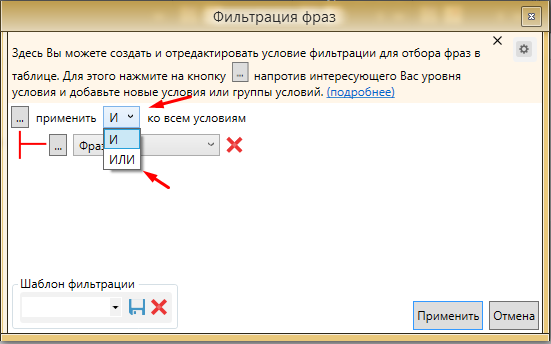 Фото 8: Доступно два условия: "И" и "ИЛИ".
Фото 8: Доступно два условия: "И" и "ИЛИ".Для сброса фильтрации используем эту кнопку
 Фото 9: Кнопка сброса всех установленных фильтров группы.
Фото 9: Кнопка сброса всех установленных фильтров группы.Рассмотрим наиболее часто применяемые фильтры.
Прочие символы
 Фото 10: Фильтр для чистки от специальных символов.
Фото 10: Фильтр для чистки от специальных символов.Этот фильтр поможет нам отсеять все фразы, содержащие специальные символы, которые по какой-то причине не отфильтровали на этапе сбора. Под прочими символами КК понимает следующие: \ / ? ( ) ; , ” и другие более специфические (остальные удаляются через настройки, если добавлены в них). Как показывает практика, подобные запросы часто имеют низкую, а в некоторых случаях и нулевую частоту. Если нам надо, чтобы фразы которые содержат , или ? оставались в списке, но не отображались символы - это можно изменить в настройках КК выставив опцию для автоматической замены или удаления этих знаков.
Латинские буквы
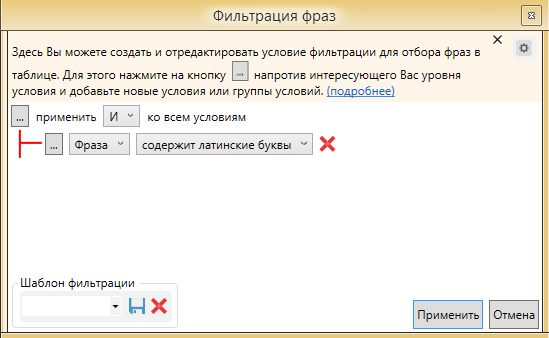 Фото 11: Фильтр для чистки от латинских букв в любой части слова.
Фото 11: Фильтр для чистки от латинских букв в любой части слова. Этот фильтр будет полезен в большей степени для информационных сайтов, не связанных с названием каких-либо продуктов или товаров. Для коммерческих сайтов очень часто используются официальные названия на латинице и данный фильтр может существенно порезать семантическое ядро проекта.
Важно! Рекомендуем его использовать только в проектах, в которых латиница не встречается в “рабочих” фразах. Именно в этом случае этот фильтр оказывается очень удобным и быстрым в использовании.
Запросы с одной буквой в конце
Нередко в ходе парсинга через КК нам приезжают запросы по типу “как сделать прическу из”, “ловля рыбы в”, “купить компьютер за” и подобные выражения, которые либо являются неоконченными, либо имеют повторяющиеся слова. Про повторы поговорим чуть позже, в этом случае фильтр подойдет больше для одиночных букв в конце.
Делаем следующие настройки:
 Фото 12: Настройки для чистки запросов от одиночной буквы в конце.
Фото 12: Настройки для чистки запросов от одиночной буквы в конце.Условие оставляем “И”, так как эти параметры должны быть связаны. Фраза “заканчивается на”, перед нужной буквой обязательно ставим пробел. Иначе нам приедут запросы по типу “в Ростов”.
Данный способ очень удобен. Можно сохранить этот шаблон и применять его во всех проектах. Для сохранения шаблона проводим следующую операцию.
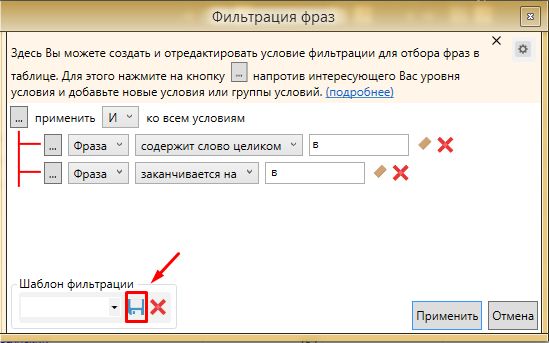
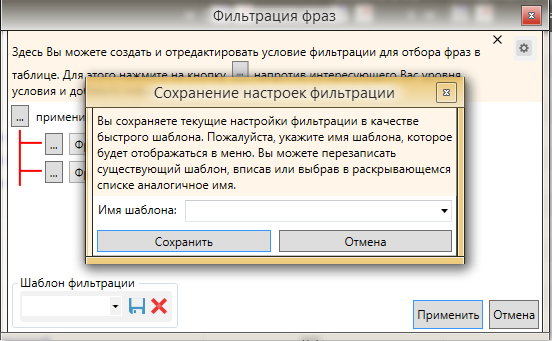 Фото 13: Сохранение настроек в шаблон для будущего использования.
Фото 13: Сохранение настроек в шаблон для будущего использования.Вводим название и сохраняем шаблон. Теперь во всех проектах можно использовать этот фильтр, остается только менять букву в конце.
Если менять букву не хочется и хочется всё разом, можно добавить более объемный и жесткий вариант. Будет выглядеть он примерно так:
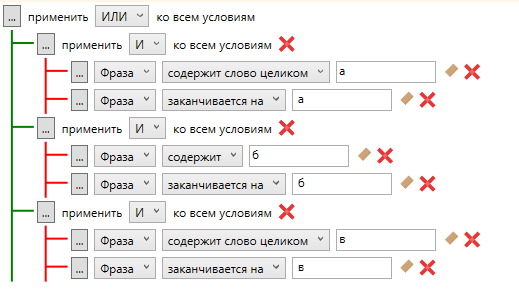 Фото 14: Вариант формирования универсального шаблона.
Фото 14: Вариант формирования универсального шаблона.Этот способ из разряда - все и сразу и подойдет для тех, кто работает с большими ядрами в поточном режиме. Либо для тех, кто ненароком добавил подсказки Mail.ru как источник парсинга. Можно подобным методом пройтись по всему алфавиту и сохранить это в шаблон. Один раз помучившись мы сможем применять его в любом проекте и разом вычищать большой пласт мусора.
Обратите внимание! Вместо одиночной буквы можно поставить любой предлог или слово, которое подходит под ваш случай.
Чистка на повторы слов
Еще одной проблемой при парсинге являются фразы с повторяющимися словами, например такие как “как почистить картошку как”, “чистим историю браузера историю” и другие нелепые фразы, которые приезжают в основном из подсказок. В некоторых случаях они могут доходить до 10% запросов итерации. Чтобы почистить ядро от подобного мусора нам помогут опять же фильтры в связке с еще одним инструментом Кей Коллектора.
Не рекомендуем использовать только фильтрацию “содержит повторы слов”, так как в этом случае мы получим запросы, которые могут содержать повторы предлогов, что не всегда коверкает ключевую фразу. Лучше использовать связку “содержит повторы слов” и маску запросов QUERY. QUERY - метрика вордстата, которая, грубо говоря, определяет последовательность слов в запросе пользователя и отображает информацию, какой из вариантов наиболее часто используется пользователем. К сожалению, точная частота !WS не может похвастаться этим и показывает нормальную частоту несмотря на повторы слов.
Итак, для начала нам необходимо собрать QUERY для наших запросов, эта информация потребуется нам также для чистки дублей.
 Фото 15: Нужно собрать порядок слов по маске [QUERY] для анализа повторов.
Фото 15: Нужно собрать порядок слов по маске [QUERY] для анализа повторов.После того, как собрали данные, задаем следующий фильтр:
 Фото 16: Настройки для поиска фраз с повторением слов, исключая предлоги.
Фото 16: Настройки для поиска фраз с повторением слов, исключая предлоги.Подобный способ поможет отсечь самых ярких представителей повторов, которые довольно сложно найти другими способами. Чтобы очистить более широко, так как не всегда QUERY может равняться 0, порой это значение может быть в рамках 1-15, в зависимости от точной частоты фразы !WS. Но, чтобы не фильтровать фразы с точной частотой в пределах 5-15, также потребуется добавление параметра. Выглядеть это будет следующим образом.
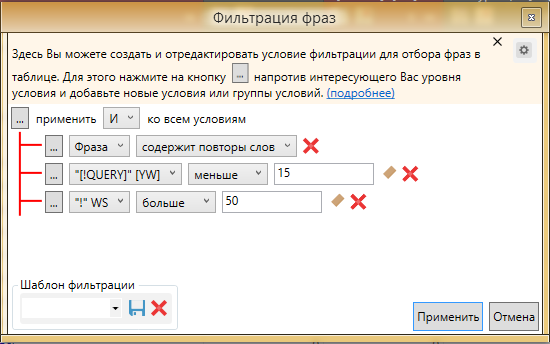 Фото 17: Вариант с более грубой фильтрацией ключевых слов на повторы.
Фото 17: Вариант с более грубой фильтрацией ключевых слов на повторы.В этом случае мы выделим большинство фраз, в которых есть повторы и при этом не зацепим фразы с повторяющимися предлогами. Добавлять частоту !WS лучше после чистки со значением QUERY = 0. Вы можете настроить оптимальные параметры связки QUERY + WS после пары экспериментов и тестов в своем проекте.
Как видно из всех возможных применений - широкая фильтрация невероятно гибкий инструмент в Кей Коллекторе, который позволяет выстраивать многоуровневую фильтрацию. Еще один плюс - это возможность сохранения всех шаблонов в настройке программы независимо от проекта. Таким образом, один раз создав все необходимые шаблоны, мы можем очистить любое собранное ядро.
Стоп слова
Следующий популярный и достаточно удобный способ чистки фраз в КК - стоп слова.
Стоп слова в данном случае список фраз и слов, которые не подходят нам и мы хотим их вычистить из нашего проекта. По сравнению с фильтрами имеет свои достоинства и ограничения.
Чтобы перейти в раздел стоп слов необходимо нажать на иконку во вкладке “Сбор данных”
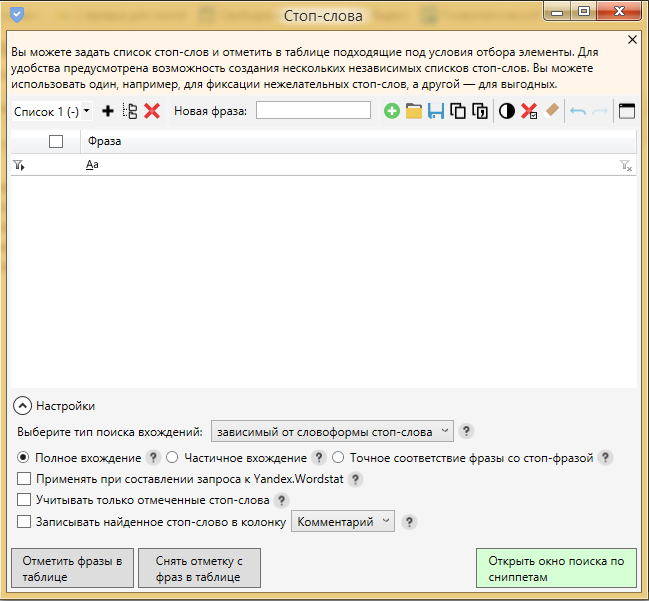 Фото 18: Рабочее окно стоп-слов в Кей Коллекторе.
Фото 18: Рабочее окно стоп-слов в Кей Коллекторе.Для добавления стоп слов мы можем использовать импорт из готового файла или вписать фразы вручную.
Допустим, у нас коммерческий проект и нас не интересуют информационные направления запросов. В этом случае мы можем добавить слова по типу “бесплатно”, “своими руками”, “в домашних условиях” и прочие в список стоп слов.

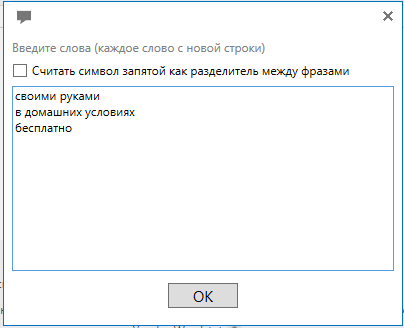 Фото 19: Ручное добавление фраз в инструмент стоп-слова.
Фото 19: Ручное добавление фраз в инструмент стоп-слова.После добавления нужных нам слов жмем “Отметить фразы в таблице”
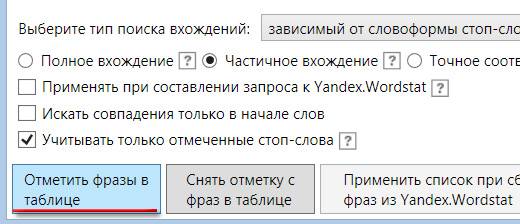
 Фото 20: Настройки словоформ для правильного поиска стоп-слов.
Фото 20: Настройки словоформ для правильного поиска стоп-слов.Система отметит нам нужные слова и мы можем перенести их в папку “МУСОР”. Минусом именно этой стандартной настройки является то, что фразы не изменяются по словоформе и вариант “бесплатный” уже не будет найден. Чтобы избежать этого необходимо изменить настройку “зависимый от словоформы стоп-слова” на независимый и добавить полную форму слова, а именно “бесплатный”.
 Фото 21: Варианты типа вхождений для уточнения поиска.
Фото 21: Варианты типа вхождений для уточнения поиска.Включение данной опции позволяет КК самому определять и менять словоформу стоп-слов. В большинстве случаев данный способ помогает найти всевозможные варианты. Однако есть одно большое НО! Кей Коллектор “слишком хорошо” меняет словоформы и бывают случаи, когда при добавлении одного слова в итоге могут быть отмечены слова с похожим корнем или набором букв. Например: при добавлении города Зеленоград в список стоп слов, независимая от словоформы фильтрация выделит слова “зеленый” и его производные. Выходом из ситуации может послужить создание двух разных списков минус слов: один, который подходит под изменение словоформы, второй, который требует только зависимой от словоформы отметки.
Важно! Если используете не проверенный и подготовленный список стоп-слов - проверяйте какие слова захватывает инструмент “Стоп-слова” при включенной опции “независимый от словоформы”. Вы можете потерять важные фразы, если система неправильно определит словоформу!
В любом случае, стоп-слова являются оперативным способом чистки, если у нас наготове есть необходимые списки минус слов.
Еще одним удобным способом добавления стоп-слов в список является кнопка в рабочей области фраз
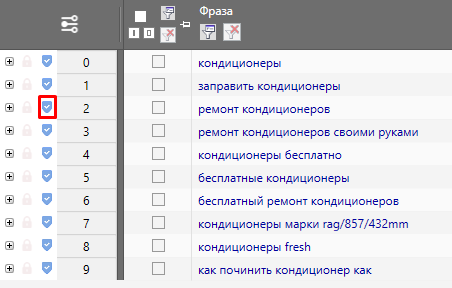
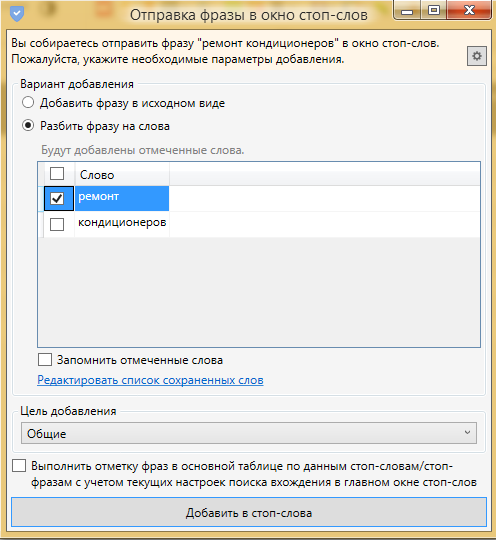 Фото 22: Добавление в стоп-слова из списка основных фраз.
Фото 22: Добавление в стоп-слова из списка основных фраз.Таким образом мы можем добавить слово в стоп слова и сразу же выделить все фразы, которые включают это слово.
Анализ групп
Анализ групп довольно удобный инструмент для работы с семантическим ядром и для его чистки. Для доступа к этому инструменту необходимо перейти на вкладку “Данные”.

Сам из себя инструмент представляет разбивку всех фраз проекта на слова и совмещенный по группам и словоформам.
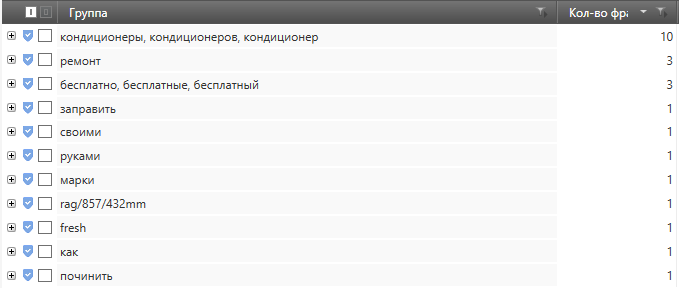
При раскрытии группы мы можем посмотреть все фразы, которые в ней содержаться и убрать отметку с тех, которые могут нам пригодиться.

С помощью инструмента мы можем выделить сразу весь блок фраз и словоформ в нем. Способ достаточно быстрый и эффективный. Разве что следует обращать внимание на словоформы в списке, так как порой туда попадают совсем не те слова и с них приходится снимать отметку вручную. После выделения нужных слов переходим в основное окно и переносим фразы в “МУСОР”. Чтобы удалить перенесенные фразы из анализа групп выполняем перерасчет группы.

Здесь же можно использовать быстрый фильтр по фразам, чтобы найти нужную группу.
Данный метод больше подойдет для работы с маленькими ядрами, так как в больших нередки случаи, что список из анализа групп может быть очень большим и при этом разбит по 1 фразе. Либо же для быстрой отметки 100% ненужных направлений, которые мы знаем и можем вбить в быстрый фильтр.
Анализ неявных дублей
Анализ дублей - это один из способов чистки семантического ядра в Кей Коллекторе. Заключается он в том, чтобы отсечь поисковые запросы, которые отличаются только очередностью слов в них и оставить наиболее часто встречающиеся формулировки.
Например, этот инструмент подскажет, какую фразу оставить “как купить квартиру” или “купить квартиру как” и более сложные варианты в автоматическом режиме.
Анализ дублей лучше всего проводить в конце всех итераций сбора перед непосредственным запуском ядра в работу.
Для того, чтобы использовать инструмент необходимо собрать такой показатель как QUERY.

Он наиболее хорошо подходит для данной задачи и определяет частоту определенной маски запроса пользователя. Хотя в самом Кей Коллекторе рекомендуется использование частоты Google Adwords.
Чтобы запустить анализ неявных дублей перейдем на вкладку “Данные”

Устанавливаем следующие настройки
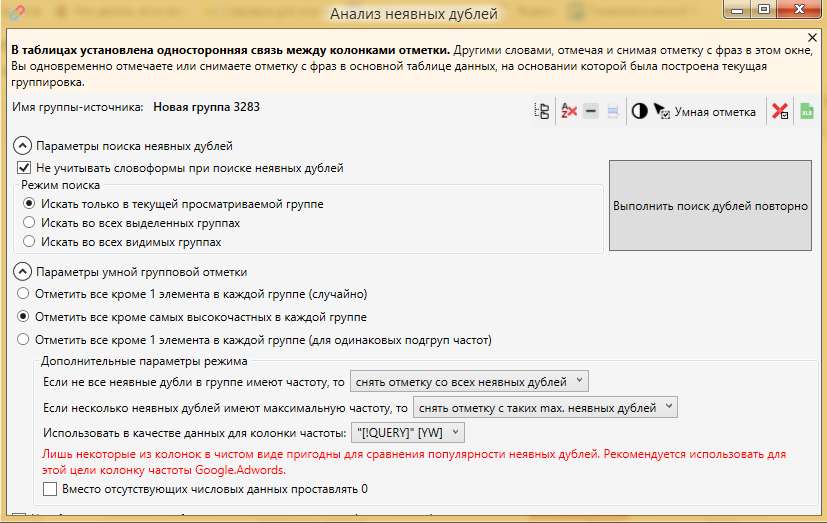 Фото 23: Настройки для анализа неявных дублей.
Фото 23: Настройки для анализа неявных дублей.В этом инструменте такая опция как “не учитывать словоформы” работает в другом режиме за счет использования QUERY как критерия отбора. По факту мы можем отключить эту опцию и тогда у нас останутся запросы “какая стиральная машина лучше” и “какие стиральные машины лучше”. Семантического смысла это не меняет, а поисковые системы сами неплохо учитывают словоформы, поэтому нагружать ядро практически одинаковыми фразами с разной частотой нет смысла, достаточно оставить самую частотную из них.
После этого запускаем “Умную отметку”. Инструмент выделит нам фразы, которые сразу можно оценить в этом же окне. В целом, очень редко бывают случаи, когда умная отметка работает плохо либо пропускает какие-то дубли. Переносим получившиеся фразы в папку “ДУБЛИ”. О подготовке папок речь шла в статье о методике сбора в КК.
Анализ дублей позволяет вычистить тот пласт “мусора”, с которым не справятся другие фильтры и инструменты, поэтому стоит всегда использовать его в ходе чистки СЯ.
Чистка фраз по частоте
Еще одним способом чистки поисковых запросов можно назвать фильтр фраз по точной частотности. После сбора частоты !WS необходимо отсеять малочастотные направления. В нашей методике используются запросы с частотой 5 и выше. Эта цифра может быть другой в вашем случае. Стоит отметить, что этот показатель взят не для контекстной рекламы.
Для чистки по частоте подойдут уже рассмотренные фильтры. Для быстрой настройки используем фильтрацию сразу на !WS, а не на фразе.

 Фото 24: Фильтруем фразы по точной частоте в Кей Коллекторе.
Фото 24: Фильтруем фразы по точной частоте в Кей Коллекторе.Этот фильтр используется практически всеми и везде, единственное что подлежит изменению - точная частота, которая необходима под каждый проект.
Итоги
Мы постарались рассмотреть наиболее часто встречающиеся методы чистки семантического ядра в Кей Коллекторе. Все эти методы используем мы сами и проверили на множестве проектов. Порядок чистки вы можете выбрать сами, однако наиболее эффективный и быстрый вариант выглядит таким образом:
- Прочие символы.
- Латинские буквы (если позволяет проект).
- Одиночная буква в конце.
- Чистка через стоп-слова.
- Анализ групп.
- Чистка по частоте (можно и раньше, если ядро большое и не жалко денег на антикапчу).
- Повторы слов по QUERY + фильтр “повторы слов”.
- Анализ неявных дублей.
Пройдя по своему семантическому ядру подобным образом в каждой итерации мы сможем получить качественный набор поисковых запросов (при условии, что вручную вычистили ненужные направления через анализ групп).
semyadro.pro
Убрать минус-слова. Формирование семантического ядра и чистка поисковых запросов от мусора. Подготовка ключевых слов из Вордстата Яндекса для Директа. Автор скрипта: вебмастер Солтык Алексей
Применение. Очистка списка ключевых слов (запросов) после сбора из вордстат Яндекса по заданным регулярным выражениям. Облегчает фильтрацию фраз и помогает определить наиболее популярные слова. SEO программа работает построчно.
Минус-слова (можно ред./добавлять свои):
- Вкл./Выкл. коммерч. правила
авито avito недорог(.){0,4} дешев(.){0,4} опт(.){0,4} цен(.){0,4} купит(.){0,2} где в(.){0,2} куплю магазин(.){0,2} интернет(.){0,2} заказ(.){0,2} стоимост(.){0,2} скачать- Вкл./Выкл. гео правила
алтай(.){0,8} алматы архангельск(.){0,2} астан(.){0,2} астрахан(.){0,2} баку барнаул(.){0,2} беларус(.){0,2} белгород(.){0,2} братск(.){0,2} брест(.){0,2} брянск(.){0,2} будапешт(.){0,2} велик(.){2,4} витебск(.){0,4} владивосток(.){0,2} владикавказ(.){0,2} владимир(.){0,2} волгоград(.){0,2} вологд(.){2,8} волгодонск(.){0,2} воронеж(.){0,2} германи(.){2} гомел(.){2} город гродно(.){0,2} деревн(.){0,2} днепропетровск(.){0,2} дон(.){0,2} донецк(.){0,2} домодедово(.){0,2} днепродзержинск(.){0,2} дзержинск(.){0,2} екатеринбург(.){0,2} запорожь(.){0,2} иванов(.){0,2} івано(.){0,2} ижевск(.){0,2} иркутск(.){0,2} йошкар(.){0,2} кавказ(.){0,2} казан(.){0,2} казахстан(.){0,2} калининград(.){0,2} калуг(.){0,2} каменогорск(.){0,2} кемеров(.){0,2} киев(.){0,2} киров(.){0,2} кита(.){0,2} китайск(.){0,2} краснодар(.){0,2} красноярск(.){0,2} красногорск(.){0,2} крив(.){0,2} крым(.){0,2} курган(.){0,2} курск(.){0,2} кисловодск(.){0,2} колпино(.){0,2} липецк(.){0,2} люберц(.){0,2} луганск(.){0,2} лубянк(.){0,2} магнитогорск(.){0,2} махачкал(.){0,2} мариупол(.){0,2} минск(.){0,2} могилев(.){0,2} москв(.){0,2} московск(.){2,4} мск мурманск(.){0,2} нижневартовск(.){0,2} нижн(.){2,4} николаев(.){0,2} новгород(.){0,2} новомосковск(.){0,2} новокузнецк(.){0,2} новосибирск(.){0,2} област(.){0,2} одесс(.){0,2} омск(.){0,2} оренбург(.){0,2} орле(.){0,2} пенз(.){0,2} перм(.){0,2} петропавловск(.){0,2} петербург(.){0,2} питер(.){0,2} подмосковь(.){0,2} подольск(.){0,2} полтав(.){0,2} польш(.){0,2} пушкин(.){0,2} покровк(.){0,2} район(.){0,2} рог(.){0,2} росси(.){0,2} ростов(.){0,2} рязан(.){0,2} реутов(.){0,2} самар(.){0,2} санкт саратов(.){0,2} севастопол(.){0,2} симферопол(.){0,2} смоленск(.){0,2} сочи(.){0,2} спб ставропол(.){0,2} сургут(.){0,2} сша сыктывкар(.){0,2} таганрог(.){0,2} тамбов(.){0,2} твер(.){0,2} тольятти(.){0,2} томск(.){0,2} тул(.){0,2} тюмен(.){0,2} тернопол(.){0,2} тернопіл(.){0,2} украин(.){0,2} україн(.){0,2} улан(.){0,2} ульяновск(.){0,2} усть(.){0,2} уф(.){0,2} хабаровск(.){0,2} харьков(.){0,2} чебоксар(.){0,2} черкасс(.){0,2} челн(.){0,2} челябинск(.){0,2} чернівців(.){0,2} франківськ(.){0,2} ярославл(.){0,2} ялт(.){0,2}Каждое слово (фраза) для исключения должно начинаться с новой строки!
Памятка к регулярным выражениям (PHP):
(.){0,2} - максимальное количество искомых букв надо умножить на 2. Т.е. {0,2} - это от 0 до 1 буквы. {2,4} - это от 1 до 2 букв..*слово.* - исключаем полностью все строки содержащие "слово".слово - таким выражением можно исключить предлог, местоимение или четкое совпадение по слову.- Удалить цифры в начале строк? (к примеру, если скопировали ключи с AdWords)
Вставить свой текст для анализа:
Памятка. Программа отчищает от фраз "статистика по словам","показов в месяц", убираем "+" (плюсики) и количество запросов - если производилось копирование запросов методом выделения из wordstat Яндекса.
Также в списках минус-слов есть уже готовые правила для исключений - это коммерческие слова, упоминание городов... - На практике всё это считается мусором, если нам нужно получить готовые названия страниц товаров, разделов и услуг. Благодаря чему создается правильное семантическое ядро.
Вы можете создать свой набор правил - они сохраняются после применения (выполнения программы) в памяти браузера до закрытия вкладки.
Данная программа является бесплатной. Для более профессиональной обработки запросов рекомендую использовать Key Collector.
Результат (по частоте)
Памятка. Фразы отображаются в том же порядке что и были загружены в анализатор запросов, но уже в отфильтрованном виде - т.е. по количеству показов в месяц.К примеру, для того чтобы собрать информацию по разным группам запросов, надо в вордстате Яндекса ввести в скобках, через вертикальную черту, разные запросы в виде:
(домовой купить | домовенок купить)Результат алфавитной сортировки (бета версия)
Бета. Попытка сделать кластеризацию запросов - сгруппировать по группам и логическому смыслу фраз.
P.S. Лучше использовать мой бесплатный группировщик и анализатор позиций в Яндексе. А еще лучше КейКоллектор :))
Грамотное распределение запросов по страницам (разделам, товарам...) требует много времени. Этот способ немного облегчает этот процесс.
Популярность слов
Памятка. Слова отсортированы по частоте встречаемости (количество упоминаний) в перечне ключевых фраз. Это поможет понять на что делать акцент в первую очередь, о чем писать в тексте на странице, а также какие группы фраз и слов наиболее популярнее. Учитываются только уже отфильтрованные результаты. Слова, цифры и другие значения считаются отдельными, если разделяются пробелом. Можно использовать не нужные слова для фильтрации. Красным подсвечены слова встречаемые более 2 раз в обработанном списке запросов.
LSI
Моя методика состоит в использовании LSI-копирайтинга, как метода повышающего релевантность текстов при упоминании наиболее встречаемых слов. Чем больше используется в тексте синонимов, антонимов, и других тематических слов - тем больше шансов занять ТОП по текстовой составляющей. Не надо спамить. Главное хотябы раз упомянуть естественным языком данные слова. Проверяйте тексты в сервисе Тургенев.
СЯ - Семантическое ядро запросов
Без более полного семантического ядра отвечающего на многие вопросы посетителей (они же запросы) - не будет правильной структуры сайта (интернет-магазина), не будет понятно что именно хотят купить люди и что соответственно всё-таки закупать.
Сематические взаимосвязи по тексту и постраничной структуры - должны быть также выделены и связаны семантической разметкой (Микроразметка Schema.org, Open Graph и др.)
Смотрите раздел Школа SEO.
Как пользоваться программой?
1.) ввести запрос в ворстате и путем выделения запросов начиная со фразы "Статистика по словам" копировать в поле для анализа и так все страницы.
2.) по умолчанию стоит фильтр коммерческих и гео-приставок к запросам. Вы можете исключить строки или вырезать отдельные слова с помощью языка условных выражений из PHP.
3.) "Удалить цифры в начале строк?" - этот параметр можно использовать если вы сначала очистили запросы с помощью моей программы, а потом прогнали через группировщик Кулакова - использующий кластеризацию по ТОП-у. Таким методом можно сгруппировать слова. Если хотите очистить от слов "Показать/скрыть" и цифр при копировании с помощью выделения - укажите данный параметр.
Автор программы не несет ответственность за полученный результат. Скрипт был создан исключительно для своих целей, такие как: фильтрация, отчистка ключевых слов и фраз для последующего составления из них семантического ядра запросов. Предоставляется на бесплатной основе. Буду признателен за идеи, найденные ошибки и рекомендации сделать софт лучше - об этом вы можете написать в комментариях ВКонтакте или зайти на мою страницу и написать личное сообщение.
Версия SEO анализатора ключевых фраз: 01022016-20042018 - автор Солтык А.М.
soltyk.ru
9 способов чистить поисковые запросы в Key Collector
Дорогие друзья, сегодня я хочу рассказать о том, как эффективно чистить поисковые запросы в программе Key Collector http://www.key-collector.ru/.
Чтобы почистить семантическое ядро, я использую следующие способы:
- Чистка семантического ядра с помощью регулярных выражений.
- Удаление с помощью списка стоп-слов.
- Удаление с помощью групп слов.
- Чистка по фильтру.
- Массовое выделение.
- Анализ неявных дублей.
- Быстрый фильтр.
- Просмотр источника.
- Простое удаление.
Их использование позволит вам быстро и эффективно почистить список собранных ключевых слов и удалить все фразы, которые не подходят для вашего сайта.

Чтобы все наглядно показать, я решил записать видеоурок:
Обзор лучше смотреть в полноэкранном режиме в качестве 720 HD. Также не забывайте подписываться на мой канал на Youtube, чтобы не пропустить новые видео.
Я покажу несколько способов это сделать. Если вы знаете еще способы – черкните в комментариях. Все описанные методы я сам использую. Они экономят мне массу времени.
Итак, поехали.
1. Чистка запросов с помощью регулярных выражений
Регулярные выражения значительно расширяют возможности по выборке запросов и экономят время.
Допустим, нам нужно выбрать все поисковые запросы, которые содержат цифры.
Для этого кликаем на указанной иконке в колонке "Фраза":
Выбираем опцию "удовлетворяет рег. выражению" и вставляем в поле такое регулярное выражение:
\d+
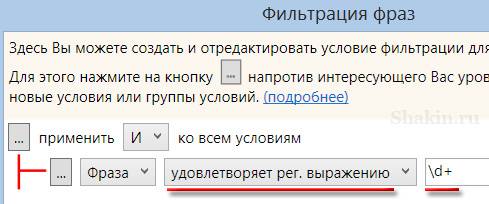
Остается нажать кнопку "Применить", и вы получите список всех запросов, которые содержат цифры.
Я люблю применять регулярные выражения для поиска поисковых запросов, которые представляют собой вопросы.
Например, если указать такое регулярное выражение:
^как
То получим список всех запросов, которые начинаются со слова "как" (а также со слов "какой", "какие", "какая"):
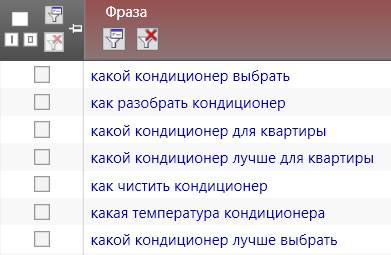
Такие запросы отлично подходят для информационных статей, даже если сайт коммерческий.
Если задействовать такое выражение:
бесплатно$
То получим все запросы, которые заканчиваются на слово "бесплатно":

Таким образом, можно сразу избавиться от любителей халявы 🙂 . Нет, как можно набирать запрос "кондиционер бесплатно"? Жажда халявы не имеет границ. Это как в том анекдоте "Приму Бентли в дар" 😉 . Ладно, надо серьезнее.
Если нам нужно найти все фразы, которые содержат буквы латинского алфавита, то пригодится такое выражение:
[a-z]+
Приведу примеры других регулярных выражений, которые я использую:
^(\S+?\s\S+?)$ - все запросы, состоящие из 2 слов
^(\S+?\s\S+?\s\S+?)$ - состоящие из 3 слов
^(\S+?\s\S+?\s\S+?\s\S+?)$ - состоящие из 4 слов
^(\S+?\s\S+?\s\S+?\s\S+?\s\S+?)$ - из 5 слов
^(\S+?\s\S+?\s\S+?\s\S+?\s\S+?\s\S+?)$ - из 6 слов
^(\S+?\s\S+?\s\S+?\s\S+?\s\S+?\s\S+?\s\S+?)$ - из 7 слов
^(\S+?\s\S+?\s\S+?\s\S+?\s\S+?\s\S+?\s\S+?\s\S+?)$ - из 8 слов
Поиск по запросам, состоящих из 6 и более слов полезен, так как часто они содержат много мусорных фраз.
В программе имеется и другая возможность найти такие запросы – просто выберите в выпадающем меню нужный пункт ниже:
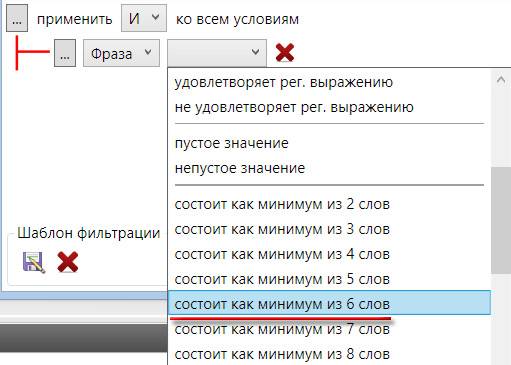
Если вы хотите углубиться в тему регулярных выражений и постигнуть дзен проникнуться ею 🙂 , то рекомендую подробную статью от Сергея Кокшарова Регулярные выражения для SEO.
2. Список стоп-слов
Для чистки поисковых запросов имеет смысл создать список нежелательных слов, которые вы хотите удалить в собранных запросах.
Например, если у вас коммерческий сайт, то можно использовать такие стоп-слова:
бесплат
качат
реферат
Я специально пишу некоторые слова только частично, чтобы охватить все возможные варианты. Например, использование стоп-слова "бесплат" позволит не собирать запросы, содержащие:
бесплатно
бесплатный
Стоп-слово "качат" даст возможность не собирать запросы, которые включают в себя:
скачать
качать
В программе Кей Коллектор во вкладке "Сбор данных" переходим в пункт "Стоп-слова":
И добавляем нежелательные слова через опции "Добавить списком" или "Загрузить из файла":
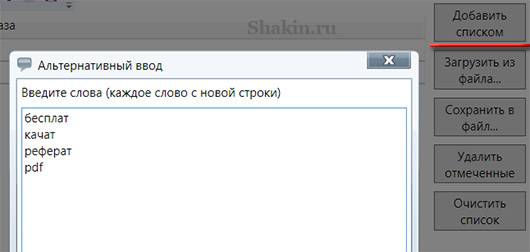
Отмечаем галочками стоп-слова:
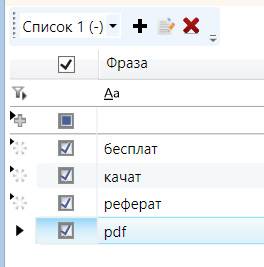
Далее жмем ОК и кликаем на указанную кнопку "Отметить фразы в таблице":
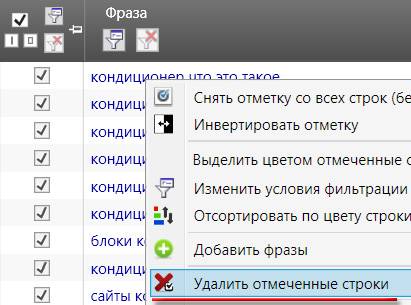
Перейдя в основное окно программы, мы увидим, сколько запросов отмечено по указанным стоп-словам:

Останется только найти отмеченные запросы, кликнуть по ним правой мышкой и выбрать "Удалить отмеченные строки":
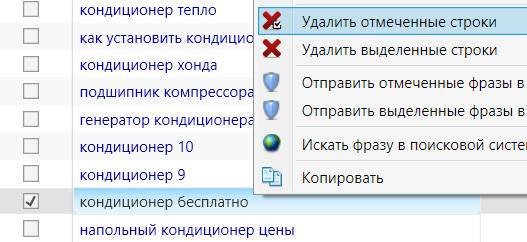
Товарищи, которые хотят кондиционеры бесплатно, нас не интересуют 🙂 .
Можно даже не искать пример отмеченного запроса, а сразу кликнуть правой мышкой на любом запросе, даже который не отмечен, и выбрать "Удалить отмеченные строки".
Я также активно использую в качестве стоп-слов названия городов. Например, мне нужно собрать запросы только для Москвы. Поэтому использование стоп-слов с названиями городов позволит не собирать запросы, которые содержат в себе названия других городов.
Приведу примеры таких стоп-слов:
санкт
петер
питер
спб
Все эти слова позволят не собирать запросы, содержащие различные варианты названия Санкт-Петербурга. Как и в предыдущем примере, я использую сокращенные варианты названий городов.
Также советую использовать в качестве стоп-слов цифры предыдущих годов, так как запросы с ними практически никто набирать не будет:
2010
2011
2012
2013
2014
Поделюсь с вами своим списком стоп-слов, который содержит:
- города России
- города Украины
- города Белоруссии
- города Казахстана
А также мой список общих стоп-слов (бесплат, качат, реферат, pdf и т.д.).
Полный список стоп-слов может получить любой желающий абсолютно бесплатно, нужно лишь нажать на одну из кнопок соцсетей. Это как маленькое спасибо старику Глобатору за его скорбный труд 🙂 . И он сможет увидеть, скольких посетителей заинтересовал его список.
Рекомендую просматривать список стоп-слов перед использованием на предмет того, чтобы случайно не удалить нужные запросы.
Кроме этого, в Кей Коллекторе есть еще один способ работы со стоп-словами. При просмотре списка запросов встречаете слово, которое не подходит для вашего сайта, например, "заправка кондиционера". Кликаете по указанной иконке слева от этой фразы:
![]()
Отмечаете галочкой то слово, которое вам не подходит, и кликаете по кнопке "Добавить в стоп-слова":
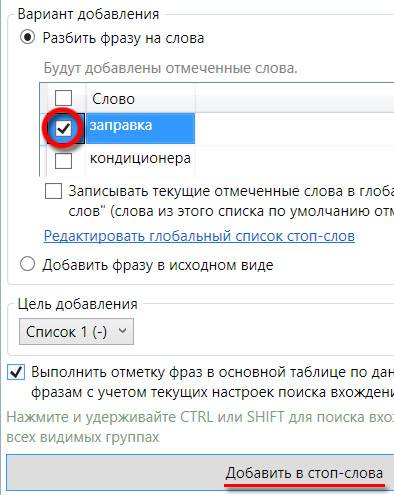
В результате будут отмечены все запросы, которые содержат данное слово.
3. Группы слов
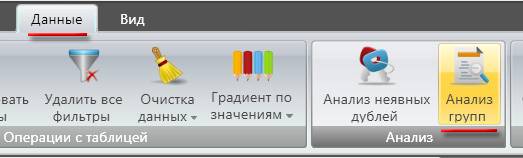
Этот метод я активно использую. Он позволяет удалить большое количество ненужных запросов за короткое время.
В программе Key Collector переходим во вкладку "Данные" в пункт "Анализ групп":
Далее отмечаем те группы, которые содержат слова, которые нам не подходят:
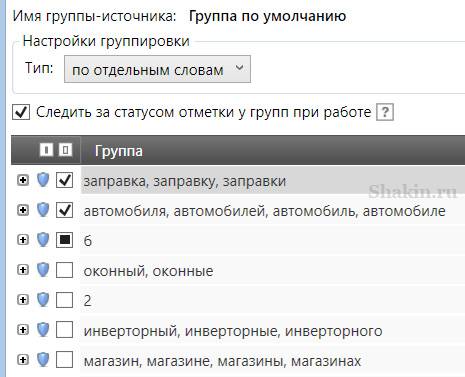
Подробно этот момент я показал в видеоуроке.
4. Чистка запросов по фильтру
Этот способ дает возможность сначала сделать выборку по нужному параметру, а затем удалить все запросы, которые не подходят по фильтру.
Например, можно быстро удалить все ключевые слова с частотой показов по Яндексу менее 10. Хотя я лично все запросы оставляю, даже с нулевой частотой показов. Использование их на продвигаемых страницах в качестве дополнительных фраз позволяет разнообразить текст.
Для фильтрации запросов кликаем по указанному значку в колонке "Частотность "!"":

В появившемся окне в выпадающем меню выбираем пункт "Меньше":
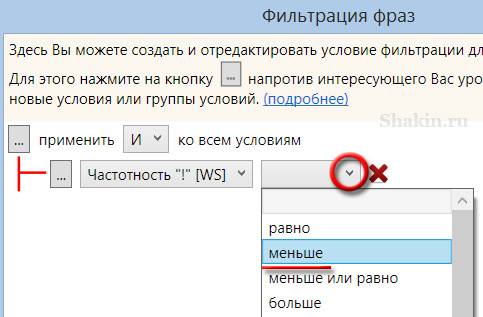
Далее указываем нужное значение 10:
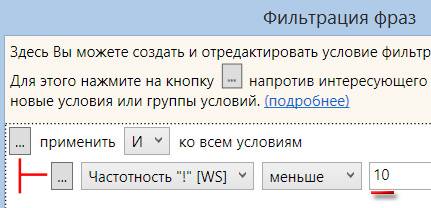
И жмем кнопку "Применить".
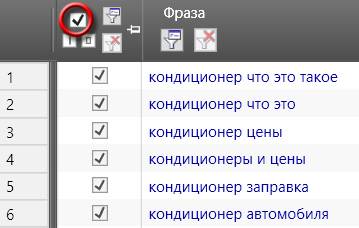
В результате получим список всех запросов, у которых частота показов по Яндексу меньше 10.
Можно будет их все выделить:
И после этого кликнуть по запросам правой мышкой и выбрать пункт "Удалить отмеченные строки":
После этого не забудьте в колонке "Частотность "!"" кликнуть по указанной галочке "Удалить колонку из текущих условий фильтрации", иначе оставшиеся запросы не будут отображаться:

Поделюсь с вами еще одной своей наработкой. При сборе больших семантических ядер бывает, что часть поисковых запросов содержат символы / и \. Чтобы быстро найти и удалить такие запросы, воспользуйтесь таким фильтром:
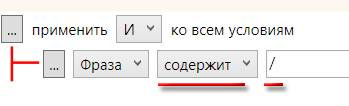
После клика на кнопке "Применить" увидим все запросы, которые содержат искомый символ:
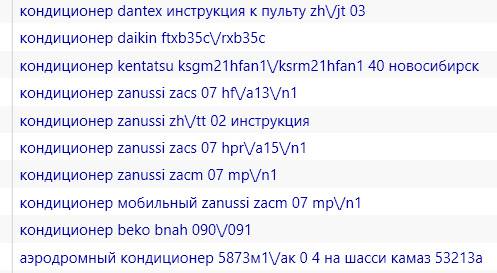
5. Массовое выделение
Этот способ подходит, когда в списке есть фразы с одинаковыми словами, которые вам нужно удалить.
Этот метод можно использовать следующим образом. Кликаем по верхней части колонки с поисковыми запросами, чтобы упорядочить их по алфавиту (аналогично можно кликнуть по любой другой колонке). Затем наводим курсор на подходящие для удаления фразы и, зажав левую кнопку мышки, тянем вниз:
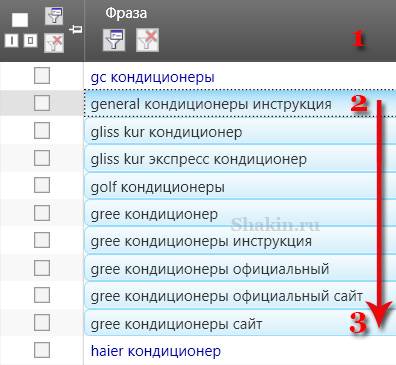
Затем кликаем правой кнопкой мышки на выделенных запросах и выбираем опцию "Удалить выделенные строки":
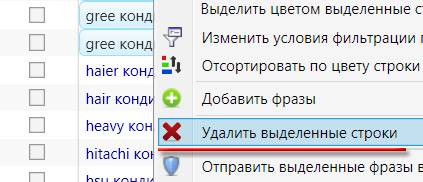
6. Анализ неявных дублей
Неявные дубли – это поисковые запросы, которые состоят из одних и тех же слов, но при этом некоторые слова у них размещены в разном порядке. Например, "LG кондиционер" и "кондиционер LG".
Перед использованием данного метода рекомендую предварительно собрать частотность запросов по Google Adwords с помощью указанной кнопки:

Этот показатель сослужит нам верную службу, какую – увидите дальше 🙂 . После того, как частотность собрана, во вкладке "Данные" переходим в пункт "Анализ неявных дублей":

Далее кликаем по указанному пункту "Параметры умной групповой отметки":
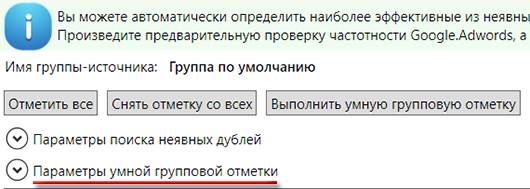
И выставляем такие настройки:
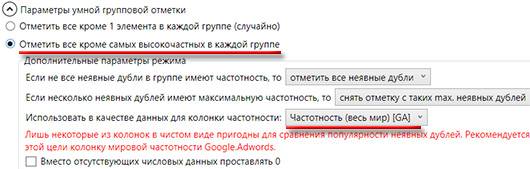
После этого нажимаем на кнопку "Выполнить умную групповую отметку":
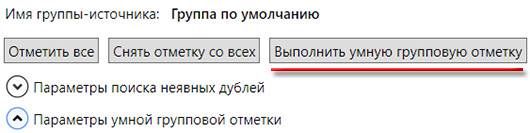
Программа отметит те неявные дубли запросов, у которых меньше частота по Google Adwords (весь мир). Они будут отмечены в таблице. Просмотрите их на всякий случай, после чего большинство отмеченных неявных дублей можно будет удалить.
Update: отлично рассказал про работу с неявными дублями Игорь Бакалов, автор блога http://bakalov.info/:
7. Быстрый фильтр
Этот метод я использую очень активно. В любой тематике будут запросы, которые не получится удалить с помощью тех же стоп-слов или групп слов.
Например, стоп-слова не учитывают всего разнообразия словоформ, которые могут быть.
Допустим, ваша компания занимается продажей кондиционеров. При этом такие услуги, как заправка и ремонт не предоставляет.
Можно при просмотре запросов отправлять неподходящие слова в список стоп-слов с помощью указанной иконки:
![]()
Но при этом не будут охвачены запросы, которые содержат слова "заправить", "заправки" и т.д.
Для того, чтобы задействовать весь спектр подобных запросов, которые вы хотите удалить, и избавить себя от ненужной работы, делаем следующее.
При просмотре списка запросов часть слов не будет охвачена, как в примере выше.
Я открываю текстовый файл и вписываю в него только часть от слова "заправка", чтобы охватить все возможные словоформы на его основе:
заправ
Далее я вставляю слово "заправ" в поле быстрого фильтра и нажимаю Enter:
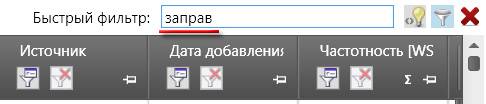
В результате получу список поисковых запросов со всеми возможными вариантами слова "заправка":

Для сброса быстрого фильтра нажмите на указанную галочку:

Данный метод позволяет прямо в процессе работы удалять все словоформы тех запросов, которые вам не подходят. Главное – использовать сокращенные варианты слов для максимального охвата.
8. Просмотр источника
Во многих тематиках некоторые методы сбора ключевых слов с таких источников, как, например, поисковые подсказки, в итоге дают много мусорных запросов. Подсказки тоже нужно использовать, в них попадаются отличные ключевые слова, но и чистить их тоже необходимо.
Для быстрой очистки таких запросов имеет смысл воспользоваться данным способом.
Кликаем по указанной иконке в верхней части колонки "Источник":

После этого выбираете нужный источник. Я обычно работаю с подсказками разных поисковых систем:

Можно работать с подсказками каждого поисковика по отдельности, а можно добавить условие:
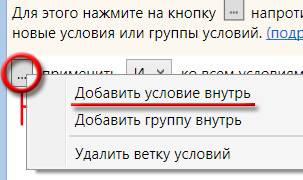
Применить "ИЛИ" вместо "И" и выбрать сразу несколько источников подсказок:
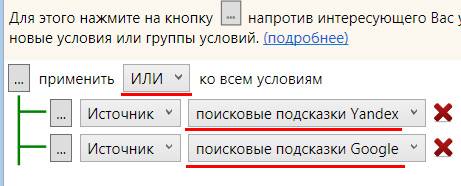
В итоге получите список запросов из поисковых подсказок сразу из нескольких источников – Яндекса, Гугла и т.д.
По своему опыту могу сказать, что чистить запросы по такому списку на основе источников намного быстрее и эффективнее.
9. Простое удаление
Этот способ знают все. Он заключается в обычном выделении одного или нескольких запросов галочкой, клике правой мышкой и выборе пункта "Удалить отмеченные строки":
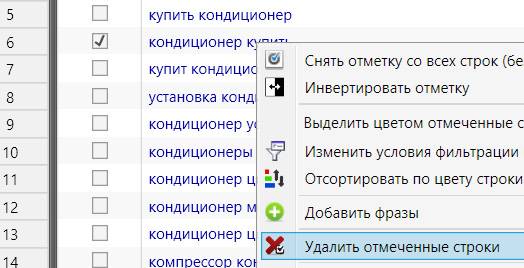
Этот метод я использую на заключительной стадии. После всех чисток нужно еще раз просмотреть все запросы и вручную удалить те, которые не подходят, но прошли все предыдущие фильтры.
Так сказать, это финальная "полировка" семантического ядра 🙂 .
Для работы с Key Collector я использую прокси с этого русскоязычного сервиса.
Можете почитать и другие мои материалы, например:
Как быстрее вывести в топ новую страницу сайта
42 сервиса и программы для проверки позиций сайта
Как проверить наличие ссылок на сайт – 14 способов
Желаю вам успешного увеличения посещаемости на ваших сайтах!
Михаил Шакин
Десерт на сегодня - видео о военном роботе:
Подпишитесь на рассылку блога с полезными материалами по SEO
Оцените, пожалуйста, статью, я старался :) :
 Загрузка...
Загрузка...shakin.ru






